rust学习笔记
文章目录
- 1.0 rustup
-
- 1.1 简介
- 1.2 安装
- 2.0 cargo
-
- 2.1 简介
- 2.2 安装
- 2.3 构建项目
- 3.0 一个小项目
-
- 3.1添加依赖crate
- 3.2 match分支
- 3.3 循环
- 4.0 rust编程基本概念
-
- 4.1 变量的可变性
- 4.2 常量变量区别
- 4.3 隐藏
- 4.4 数据类型
-
- 4.4.1 标量(scalar)
- 4.4.2 复合(compound)
- 4.5 函数工作流程
-
- 4.5.1 函数参数
- 4.5.2 具有返回值的函数
- 4.6 控制流
-
- 4.6.1 if表达式
- 4.6.2 循环
- 4.7 所有权
-
- 4.7.1 堆和栈
- 4.7.2 rust所有权的规则
- 5.0 结构体
-
- 5.1方法使用
-
- 5.2.1带有更多参数的方法
- 5.3 关联函数
- 6.0枚举和模式匹配
-
- 6.1 Option枚举
- 6.2 match控制流
- 6.3匹配Option< T>
- 6.4 if let控制流
- 7.0 包,crate ,项目管理
-
- 7.1 包和crate
- 7.2 定义模块来控制作用域的私有性
- 7.3引用模块树的路径
- 7.4 使用use将名称引入作用域
- 7.5 将模块放入不同的文件内
- 8.0 常见集合
-
- 8.1 vector向量
- 8.2 字符串
- 8.3 hashmap
- 9.0 错误处理
-
- 9.1 panic! 与不可恢复的错误
- 9.2 Result 与可恢复的错误
1.0 rustup
1.1 简介
rustup是一个管理 Rust 版本和相关工具的命令行工具。下载时需要联网。
1.2 安装
我们使用的系统是debian8
首先我们查看远程的脚本并且运行
root@elvis:~# curl https://sh.rustup.rs | sh
选择1安装
Current installation options:
$<2> $<2>default host triple: $<2>x86_64-unknown-linux-gnu$<2>
$<2> $<2>default toolchain: $<2>stable$<2>
$<2> $<2>profile: $<2>default$<2>
modify PATH variable: $<2>yes$<2>
1) Proceed with installation (default)
2) Customize installation
3) Cancel installation
>1
>$<2>info: $<2>profile set to 'default'
$<2>info: $<2>syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
$<2>info: $<2>latest update on 2019-11-07, rust version 1.39.0 (4560ea788 2019-11-04)
$<2>info: $<2>downloading component 'cargo'
$<2>info: $<2>downloading component 'clippy'
$<2>info: $<2>downloading component 'rust-docs'
$<2>info: $<2>downloading component 'rust-std'
176.4 MiB / 176.4 MiB (100 %) 9.2 MiB/s in 22s ETA: 0s
$<2>info: $<2>downloading component 'rustc'
66.3 MiB / 66.3 MiB (100 %) 8.8 MiB/s in 8s ETA: 0s
$<2>info: $<2>downloading component 'rustfmt'
$<2>info: $<2>installing component 'cargo'
$<2>info: $<2>installing component 'clippy'
$<2>info: $<2>installing component 'rust-docs'
11.8 MiB / 11.8 MiB (100 %) 881.6 KiB/s in 12s ETA: 0s
$<2>info: $<2>installing component 'rust-std'
176.4 MiB / 176.4 MiB (100 %) 8.3 MiB/s in 28s ETA: 0s
3 iops / 3 iops (100 %) 1 iops/s in 2s ETA: 0s
$<2>info: $<2>installing component 'rustc'
66.3 MiB / 66.3 MiB (100 %) 6.7 MiB/s in 21s ETA: 0s
6 iops / 6 iops (100 %) 5 iops/s in 1s ETA: 0s
$<2>info: $<2>installing component 'rustfmt'
$<2>info: $<2>default toolchain set to 'stable'
$<2>stable installed$<2> - rustc 1.39.0 (4560ea788 2019-11-04)
$<2>
Rust is installed now. Great!
$<2>
To get started you need Cargo's bin directory ($HOME/.cargo/bin) in your $<2>PATH$<2>
environment variable. Next time you log in this will be done
automatically.
To configure your current shell run $<2>source $HOME/.cargo/env$<2>
2.0 cargo
2.1 简介
Cargo 是 Rust 的构建系统和包管理器,cargo可以处理很多任务,比如构建代码,下载依赖库,并且编译这个库,如果我们写一个最简单的hello world程序
fn main() {
printfln!("hello world!");
}
将只会用到 Cargo 构建代码的那部分功能。在编写更复杂的 Rust 程序时,你将添加依赖项,如果使用 Cargo 启动项目,则添加依赖项将更容易。
2.2 安装
在我们安装rustup的时候cargo已经被顺带安装
2.3 构建项目
我们尝试使用cargo构建项目
root@elvis:~/rust/project# cargo new hello_cargo_project #创建一个project
我们输完上述命令后会在此目录下创建一个hello_cargo_project的目录 ,我们进入此目录看一下
root@elvis:~/rust/project# cd hello_cargo_project/
root@elvis:~/rust/project/hello_cargo_project# ls -al
total 24
drwxr-xr-x 4 root root 4096 Dec 3 10:00 .
drwxr-xr-x 3 root root 4096 Dec 3 10:00 ..
-rw-r--r-- 1 root root 207 Dec 3 10:00 Cargo.toml
drwxr-xr-x 6 root root 4096 Dec 3 10:00 .git
-rw-r--r-- 1 root root 19 Dec 3 10:00 .gitignore
drwxr-xr-x 2 root root 4096 Dec 3 10:00 src
此时发现有git初始文件,还有cargo.toml文件(这是 Cargo 配置文件的格式,使用的是Tom’s Obvious, Minimal Language)格式),src目录是放我们源码的目录,我们先看cargo的配置文件cargo.homl
root@elvis:~/rust/project/hello_cargo_project# cat Cargo.toml
[package]
name = "hello_cargo_project"
version = "0.1.0"
authors = ["root"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
root@elvis:~/rust/project/hello_cargo_project#
第一行,[package],是一个片段(section)标题,表明下面的语句用来配置一个包。随着我们在这个文件增加更多的信息,还将增加其他片段(section)。接下来的四行设置了 Cargo 编译程序所需的配置:项目的名称、版本、作者以及要使用的 Rust 版本。Cargo 从环境中获取你的名字和 email 信息,所以如果这些信息不正确,请修改并保存此文件。附录 E 会介绍 edition 的值。
最后一行,[dependencies],是罗列项目依赖的片段的开始。在 Rust 中,代码包被称为 crates。这个项目并不需要其他的 crate(因为就是一个hello world),后面我们其他的项目有可能依赖其他的包会在dependencies下写相应的配置
此时我们可以再src/下写一个最简单的程序hello world
root@elvis:~/rust/project/hello_cargo_project# cd src/
root@elvis:~/rust/project/hello_cargo_project/src# vim.tiny hello.rs
fn main(){
println!("hello,world");
}
此时cargo为我们生成了一个hello world的程序
Cargo 期望源文件存放在 src 目录中。项目根目录只存放 README、license 信息、配置文件和其他跟代码无关的文件。使用 Cargo 帮助你保持项目干净整洁,一切井井有条。
开始构建项目
我们输入以下的命令开始构建cargo项目,在相应的project目录下,因为他要读取toml文件 ,注意一定要装gcc
root@elvis:~/rust/project/hello_cargo_project# cargo build
上述的命令cargo build会创建一个可执行文件hello_cargo_project(于项目同名),他在PROJECT/targer/debug下 ,我们可以直接执行他打印hello world
root@elvis:~/rust/project/hello_cargo_project/target/debug# ./hello_cargo_project
Hello, world!
首次运行 cargo build 时,也会使 Cargo 在项目根目录创建一个新文件:Cargo.lock。这个文件记录项目依赖的实际版本。这个项目并没有依赖,所以其内容比较少。你自己永远也不需要碰这个文件,让 Cargo 处理它就行了。
我们刚刚使用 cargo build 构建了项目,并使用 ./target/debug/hello_cargo 运行了程序,也可以使用 cargo run 在一个命令中同时编译并运行生成的可执行文件:
root@elvis:~/rust/project/hello_cargo_project# cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/hello_cargo_project`
Hello, world!
root@elvis:~/rust/project/hello_cargo_project#
如果修改了源文件的话,Cargo 会在运行之前重新构建项目,并会出现像这样的输出
Cargo 还提供了一个叫 cargo check 的命令。该命令快速检查代码确保其可以编译,但并不产生可执行文件:
root@elvis:~/rust/project/hello_cargo_project# cargo check
Checking hello_cargo_project v0.1.0 (/root/rust/project/hello_cargo_project)
Finished dev [unoptimized + debuginfo] target(s) in 0.40s
通常 cargo check 要比 cargo build 快得多,因为它省略了生成可执行文件的步骤。如果你在编写代码时持续的进行检查,cargo check 会加速开发!为此很多 Rustaceans 编写代码时定期运行 cargo check 确保它们可以编译。当准备好使用可执行文件时才运行 cargo build。
当项目最终准备好发布时,可以使用 cargo build --release 来优化编译项目。这会在 target/release 而不是 target/debug 下生成可执行文件。这些优化可以让 Rust 代码运行的更快,不过启用这些优化也需要消耗更长的编译时间。这也就是为什么会有两种不同的配置:一种是为了开发,你需要经常快速重新构建;另一种是为用户构建最终程序,它们不会经常重新构建,并且希望程序运行得越快越好。如果你在测试代码的运行时间,请确保运行 cargo build --release 并使用 target/release 下的可执行文件进行测试。
cargo文档手册如下
cargo 文档
3.0 一个小项目
我们新建一个项目叫做猜字谜
root@elvis:~/rust/project#cargo new guessing_game
root@elvis:~/rust/project#guessing_game/src
在该项目的src下添加mian.rs源代码,源文件如下
use std::io;
fn main() {
println!("guess the number!");
println!("please input your guess~");
let mut guess = String::new(); //必须要加上后面的new初始化
io::stdin().read_line(&mut guess).expect("failed to read line");
println!("you guessed: {}",guess);
}
我们来解读以上代码
首先是use std::io
这个风格和c++很想,这段代码的意思就是将IO库引入到当前作用域,而IO库来自于std库
默认情况下,Rust 将 prelude 模块中少量的类型引入到每个程序的作用域中。如果需要的类型不在 prelude 中,你必须使用 use 语句显式地将其引入作用域。std::io 库提供很多有用的功能,包括接收用户输入的功能。
fn main() {
这就是声明主调函数,第一个执行的函数就是main主调函数,fn 语法声明了一个新函数,() 表明没有参数,{ 作为函数体的开始
let mut guess = String::new();
let 语句,用来创建 变量,但是我们一般创建变量像就是这样let foo = 5;一个叫做 foo 的变量并把它绑定到常量 5 上,并且foo不可变,而我们之前加上mut就是让guess这个变量可变。我们上述的代码绑定的值是String::new 的结果,这个函数会返回一个 String 的新实例。String 是一个标准库提供的字符串类型,它是 UTF-8 编码的可增长文本块。
::new 那一行的 :: 语法表明 new 是 String 类型的一个 关联函数,关联函数是针对类型实现的,在这个例子中是 String,而不是 String 的某个特定实例
new 函数创建了一个新的空字符串,你会发现很多类型上有 new 函数,因为它是创建类型实例的惯用函数名。
总结一下,let mut guess = String::new(); 这一行创建了一个可变变量,当前它绑定到一个新的 String 空实例上。
io::stdin().read_line(&mut guess).expect(“Failed to read line”);
如果程序的开头没有 use std::io 这一行,可以把函数调用写成 std::io::stdin。stdin 函数返回一个 std::io::Stdin 的实例,这代表终端标准输入句柄的类型。
代码的下一部分,.read_line(&mut guess),调用 read_line 方法从标准输入句柄获取用户输入。我们还向 read_line() 传递了一个参数:&mut guess。
read_line 的工作是,无论用户在标准输入中键入什么内容,都将其存入一个字符串中,因此它需要字符串作为参数。这个字符串参数应该是可变的,以便 read_line 将用户输入附加上去。
& 表示这个参数是一个 引用(reference),它允许多处代码访问同一处数据,而无需在内存中多次拷贝。引用是一个复杂的特性,Rust 的一个主要优势就是安全而简单的操纵引用。完成当前程序并不需要了解如此多细节。现在,我们只需知道它像变量一样,默认是不可变的。因此,需要写成 &mut guess 来使其可变,而不是 &guess。
上面read_line()方法返回一个类型叫做Result,这个类型是枚举,里面的成员就是Ok,Err ok代表成功,err代表错误,而expect是io::result的方法,如果io::result返回的结果为err那么expect会导致程序崩溃,并显示当做参数传递给 expect 的信息,如果 io::Result 实例的值是 Ok,expect 会获取 Ok 中的值并原样返回。在本例中,这个值是用户输入到标准输入中的字节数。
然后我们输入cargo run执行这个项目
root@elvis:~/rust/project/guessing_game# cargo run
Compiling guessing_game v0.1.0 (/root/rust/project/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.57s
Running `target/debug/guessing_game`
guess the number!
please input your guess~
1
you guessed: 1
3.1添加依赖crate
我们需要生产一个随机数,我们可以添加一个crate来解决,这个crate就是rend,rend专门用来生成随机数,此时我们在项目的Cargo.toml的[dependencies]中加上rend这个create
[dependencies]
rend = "0.5.5"
0.5.5就是rend的版本号,在我们build的时候Cargo 会先跟新 registry,然后从其 上获取dependencies下crate的包,并且cargo会自己去解决依赖,比如我们rend就依赖libc等包,cargo都会自己帮你下好,这个仓库就是Crates.io,Crates.io 是 Rust 生态环境中的开发者们向他人贡献 Rust 开源项目的地方,现在我们在src的main.rs下添加几行代码
use std::io;
use rand::Rng;
fn main() {
println!("guess the number!");
let secret_number = rand::thread_rng().gen_range(1,101);
println!("secret_number is {}",secret_number);
println!("please input your guess~");
let mut guess = String::new();
io::stdin().read_line(&mut guess).expect("failed to read line");
println!("you guessed: {}",guess);
}
首先use rand::Rng;
Rng 是一个 trait,它定义了随机数生成器应实现的方法,想使用这些方法的话,此 trait 必须在作用域中
let secret_number = rand::thread_rng().gen_range(1, 101);
rand::thread_rng 函数提供实际使用的随机数生成器:它位于当前执行线程的本地环境中,并从操作系统获取 seed,接下来,调用随机数生成器的 gen_range 方法。这个方法由刚才引入到作用域的 Rng trait 定义gen_range 方法获取两个数字作为参数,并生成一个范围在两者之间的随机数。它包含下限但不包含上限,所以需要指定 1 和 101 来请求一个 1 和 100 之间的数。
然后我们再build
3.2 match分支
此时我们再加几行,
use std::cmp::Ordering;
let guess:u32 = guess.trim().parse().expect("please type a number!");
match guess.cmp(&secret_number){
Ordering::Less => println!("Too small"),
Ordering::Greater => println!("Too big"),
Ordering::Equal => println!("equal,you win!"),
}
首先我们得明白我们之前io::stdin::read_line(&mut guess).expect(“faile…”);输入的是一个字符,所以我们let guess:u32 = guess.trim().parse().expect(“please type a number!”);就是将guess转换成u32位的数字(u代表unsigned无符号,32代表32位,i32代表有符号32位),
这里创建了一个叫做 guess 的变量。不过等等,不是已经有了一个叫做 guess 的变量了吗?确实如此,不过 Rust 允许用一个新值来 隐藏 (shadow) guess 之前的值。这个功能常用在需要转换值类型之类的场景。它允许我们复用 guess 变量的名字,而不是被迫创建两个不同变量
我们将 guess 绑定到 guess.trim().parse() 表达式上。表达式中的 guess 是包含输入的原始 String 类型。String 实例的 trim 方法会去除字符串开头和结尾的空白字符还有换行,因为我们之前输入的时候敲了回车,所有有一个\n,
字符串的 parse 方法 将字符串解析成数字。因为这个方法可以解析多种数字类型,因此需要告诉 Rust 具体的数字类型,这里通过 let guess: u32 指定。guess 后面的冒号(:)告诉 Rust 我们指定了变量的类型。
一个 match 表达式由 分支(arms) 构成。一个分支包含一个 模式(pattern)和表达式开头的值与分支模式相匹配时应该执行的代码。Rust 获取提供给 match 的值并挨个检查每个分支的模式。match 结构和模式是 Rust 中强大的功能,它体现了代码可能遇到的多种情形,并帮助你确保没有遗漏处理
让我们看看使用 match 表达式的例子。假设用户猜了 50,这时随机生成的秘密数字是 38。比较 50 与 38 时,因为 50 比 38 要大,cmp 方法会返回 Ordering::Greater。Ordering::Greater 是 match 表达式得到的值。它检查第一个分支的模式,Ordering::Less 与 Ordering::Greater并不匹配,所以它忽略了这个分支的代码并来到下一个分支。下一个分支的模式是 Ordering::Greater,正确 匹配!这个分支关联的代码被执行,在屏幕打印出 Too big!。match 表达式就此终止,因为该场景下没有检查最后一个分支的必要。
3.3 循环
loop关键字可以创建一个无限循环可以让用户无限的输入
此时我们完善我们的程序,让其可以读取用户的错误输入,并且不报错推出只是推出当前循环,重新输入
use std::io;
use rand::Rng;
use std::cmp::Ordering;
fn main() {
println!("guess the number!");
let secret_number = rand::thread_rng().gen_range(1,101);
println!("secret_number is {}",secret_number);
loop{
let mut guess = String::new();
println!("please input your guess~");
io::stdin().read_line(&mut guess).expect("input error");
let guess:u32 = match guess.trim().parse(){
Ok(num) => num,
Err(_) => continue,
};
println!{"your guest is {} ",guess};
match guess.cmp(&secret_number){
Ordering::Less => println!("Too small"),
Ordering::Greater => println!("Too big"),
Ordering::Equal => {
println!("equal,you win!");
break;
}
}
}
}
这些代码其他还好只是有一些需要注意
第13行的let就是在把字符串数字转换成u32数字的时候加一个match,如果match后面转换操作错我,就到第二行err,将错误赋予_,这个_是一个通配符,这里代表所有错误,然后将执行后面的continue推出此次循环执行下一次循环,而如果转换正确,那么就执行第一个分支ok,并且将转换后结果赋予OK后面的num(转换如果是ok都会返回一个返还后的结果),然后执行num,也就是将num赋给guess,
最后的match如果相等就和最后一个分支的条件Ordering::Equal一样,就会跳转到这个分支,打印成功,并且break跳出死循环,
总结,我们在match的时候后面式子的返回类型最好是枚举,和我们上面的Result,Ordering类型一样
4.0 rust编程基本概念
4.1 变量的可变性
之前我们提到let a = 1;创建并且初始化了一个变量(将1绑定到a上),此变量默认不可变,因为这个是绑定,如果改变了a的值岂不是也改变了1这个常量?,比如以下的代码就会出错
fn main() {
let x = 5;
println!("The value of x is: {}", x);
x = 6;
println!("The value of x is: {}", x);
}
如果一部分代码假设一个值永远也不会改变,而另一部分代码改变了这个值,第一部分代码就有可能以不可预料的方式运行。不得不承认这种 bug 的起因难以跟踪,尤其是第二部分代码只是 有时 会改变值。
我们可以在let后面加上mut来声明x可以被更改,就是可以解绑,再去由其他的变量绑定到他上面,以下就不会报错
fn main (){
let mut a = 1;
println!{"a is {}",a};
a = 6;
println!{"a is {}",a};
}
这样就不会报错
除了防止出现 bug 外,还有很多地方需要权衡取舍。例如,使用大型数据结构时,适当地使用可变变量,可能比复制和返回新分配的实例更快。对于较小的数据结构,总是创建新实例,采用更偏向函数式的编程风格,可能会使代码更易理解,为可读性而牺牲性能或许是值得的。
4.2 常量变量区别
不允许改变值的变量,可能会使你想起另一个大部分编程语言都有的概念:常量(constants)。类似于不可变变量,常量是绑定到一个名称的不允许改变的值,不过常量与变量还是有一些区别。
- 首先,不允许对常量使用 mut。常量不光默认不能变,它总是不能变。
- 声明常量使用 const 关键字而不是 let,并且 必须 注明值的类型。
- 常量可以在任何作用域中声明,包括全局作用域,这在一个值需要被很多部分的代码用到时很有用。
- 最后一个区别是,常量只能被设置为常量表达式,而不能是函数调用的结果,或任何其他只能在运行时计算出的值。
这是一个声明常量的例子,它的名称是 MAX_POINTS,值是 100,000。(Rust 常量的命名规范是使用下划线分隔的大写字母单词,并且可以在数字字面值中插入下划线来提升可读性):
const MAX_POINTS : u32 = 100_000
4.3 隐藏
在一个作用域内我们如果使用let又定义了一个同名的变量,那么前一个同名变量就被隐藏了,意味着使用这个同名变量其绑定的值是第二个此同名变量,let也可以多次隐藏,比如下方代码
fn main(){
let a = 1;
let a = a+5;
let a = a+1;
println!{"a is {}",a};
}
首先程序将a绑定到1上,接着获取第一个a的初值加5,再使用let a隐藏上一个a,并且绑定到等号右边的值(上一个a绑定的值+5),以此类推
隐藏与将变量标记为 mut 是有区别的。当不小心尝试对变量重新赋值时,如果没有使用 let 关键字,就会导致编译时错误。通过使用 let,我们可以用这个值进行一些计算,不过计算完之后变量仍然是不变的。
mut 与隐藏的另一个区别是,当再次使用 let 时,实际上创建了一个新变量,我们可以改变值的类型,但复用这个名字。
4.4 数据类型
首先我们的rust是静态类型语言,也就是说在编译的时候必须知道所有变量的类型根据值及其使用方式,编译器通常可以推断出我们想要用的类型。
但是,像我们之前的猜字谜游戏,使用 parse 将 String 转换为数字时,必须增加类型注解,像这样
let guess:u32 = "42".trim().parse().expect("input a number");
这里如果不添加类型注解,Rust 会显示如下错误,这说明编译器需要我们提供更多信息,来了解我们想要的类型:
error[E0282]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".trim().parse().expect("Not a number!");
| ^^^^^
| |
| cannot infer type for `_`
| consider giving `guess` a type
我们这里讲rust的2类数据类型的子集,标量(scalar)和复合(compound)
4.4.1 标量(scalar)
标量(scalar)类型代表一个单独的值。Rust 有四种基本的标量类型:整型、浮点型、布尔类型和字符类型。你可能在其他语言中见过它们。让我们深入了解它们在 Rust 中是如何工作的。
整型
整数 是一个没有小数部分的数字。我们在第二章使用过 u32 整数类型。该类型声明表明,它关联的值应该是一个占据 32 比特位的无符号整数(有符号整数类型以 i 开头而不是 u)。表格展示了 Rust 内建的整数类型。在有符号列和无符号列中的每一个变体(例如,i16)都可以用来声明整数值的类型。
| 长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
每一个变体都可以是有符号或无符号的,并有一个明确的大小。有符号 和 无符号 代表数字能否为负值有符号数以补码形式(two’s complement representation) 存储。
每一个有符号的变体可以储存包含从 -[2^(n - 1)] 到 2^(n - 1) - 1 在内的数字,这里 n 是变体使用的位数。
另外,isize 和 usize 类型依赖运行程序的计算机架构:64 位架构上它们是 64 位的, 32 位架构上它们是 32 位的。
rust默认数字类型是i32
rust也可以通过以下的表格表达各个进制的字面值
| 数字字面值位数 | 例子 |
|---|---|
| 10进制 | 98_222 |
| 16进制 | 0xff |
| 8进制 | 0o77 |
| 二进制 | 0b1111_0000 |
| Byte (u8 only) | b’A’ |
当我们的整型溢出了怎么办? 关于这一行为 Rust 有一些有趣的规则。当在 debug 模式编译时,Rust 检查这类问题并使程序 panic,这个术语被 Rust 用来表明程序因错误而退出。
在 release 构建中,Rust 不检测溢出,相反会进行一种被称为二进制补码包装(two’s complement wrapping)的操作。简而言之,256 变成 0,257 变成 1,依此类推。依赖整型溢出被认为是一种错误,即便可能出现这种行为。如果你确实需要这种行为,标准库中有一个类型显式提供此功能,Wrapping。
浮点型(floating-point numbers)
Rust 也有两个原生的 浮点数(floating-point numbers)类型,它们是带小数点的数字。Rust 的浮点数类型是 f32 和 f64,分别占 32 位和 64 位。默认类型是 f64,因为在现代 CPU 中,它与 f32 速度几乎一样,不过精度更高。
fn main () {
let mut a = 2.0; //f64
a:f32 = 3.0; //f32
}
浮点数采用 IEEE-754 标准表示。f32 是单精度浮点数,f64 是双精度浮点数。
算数运算
Rust 中的所有数字类型都支持基本数学运算:加法、减法、乘法、除法和取余。下面的代码展示了如何在 let 语句中使用它们:
fn main() {
// 加法
let sum = 5 + 10;
// 减法
let difference = 95.5 - 4.3;
// 乘法
let product = 4 * 30;
// 除法
let quotient = 56.7 / 32.2;
// 取余
let remainder = 43 % 5;
}
bool类型
正如其他大部分编程语言一样,Rust 中的布尔类型有两个可能的值:true 和 false。Rust 中的布尔类型使用 bool 表示。例如:
fn main () {
let t = true;
let f:bool = false; //显示的定义bool
}
使用布尔值的主要场景是条件表达式,例如 if 表达式类的 “控制流”(“Control Flow”)
字符类型
目前为止只使用到了数字,不过 Rust 也支持字母。Rust 的 char 类型是语言中最原生的字母类型,如下代码展示了如何使用它。(注意 char 由单引号指定,不同于字符串使用双引号。)
fn main() {
let c = 'z';
let z = 'ℤ';
let heart_eyed_cat = '';
}
Rust 的 char 类型的大小为四个字节(four bytes),并代表了一个 Unicode 标量值(Unicode Scalar Value),这意味着它可以比 ASCII 表示更多内容。在 Rust 中,拼音字母(Accented letters),中文、日文、韩文等字符,emoji(绘文字)以及零长度的空白字符都是有效的 char 值。Unicode 标量值包含从 U+0000 到 U+D7FF 和 U+E000 到 U+10FFFF 在内的值。不过,“字符” 并不是一个 Unicode 中的概念,所以人直觉上的 “字符” 可能与 Rust 中的 char 并不符合。第八章的 “使用字符串存储 UTF-8 编码的文本” 中将详细讨论这个主题。
4.4.2 复合(compound)
rust的复合类型中有2个原生的复合类型,元组(tuple),数组(array)
元组(tuple)类型
元组是一个将多个其他类型的值组合进一个复合类型的主要方式。元组长度固定:一旦声明,其长度不会增大或缩小。
我们使用包含在圆括号中的逗号分隔的值列表来创建一个元组。元组中的每一个位置都有一个类型,而且这些不同值的类型也不必是相同的,但是要加类型的注解,或者不加,表示哪一个元素是什么类型
fn main (){
let tup = (500,6.4,1);
let (x,y,z) = tup;
println!("y is {}",y);
}
程序首先创建了一个元组并绑定到 tup 变量上。接着使用了 let 和一个模式将 tup 分成了三个不同的变量,x、y 和 z。这叫做** 解构(destructuring)**,因为它将一个元组拆成了三个部分。最后,程序打印出了 y 的值,也就是 6.4。
除了使用模式匹配解构外,也可以使用点号(.)后跟值的索引来直接访问它们。例如:
fn main () {
let x:(i32,f64,u8) = (500,6.4,1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}
上面的例子看到元组的索引也是从0开始
数组(array)类型
另一个包含多个值的方式是 数组(array)。与元组不同,数组中的每个元素的类型必须相同。Rust 中的数组与一些其他语言中的数组不同,因为 Rust 中的数组是固定长度的:一旦声明,它们的长度不能增长或缩小。
Rust 中,数组中的值位于中括号内的逗号分隔的列表中:
fn main (){
let a = [1,2,3,4,5];
}
当你想要在栈(stack)而不是在堆(heap)上为数据分配空间,或者是想要确保总是有固定数量的元素时,数组非常有用。但是数组并不如 vector 类型灵活
vector 类型是标准库提供的一个 允许 增长和缩小长度的类似数组的集合类型。
当不确定是应该使用数组还是 vector 的时候,你可能应该使用 vector
当程序需要知道一年中月份的名字时。程序不大可能会去增加或减少月份。这时你可以使用数组,因为我们知道它总是包含 12 个元素:
let month = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
可以像这样编写数组的类型:在方括号中包含每个元素的类型,后跟分号,再后跟数组元素的数量。
let a:[i32;5] = [1,2,3,4,5];
这里,i32 是每个元素的类型。分号之后,数字 5 表明该数组包含五个元素。
这样编写数组的类型类似于另一个初始化数组的语法:如果你希望创建一个每个元素都相同的数组,可以在中括号内指定其初始值,后跟分号,再后跟数组的长度,如下所示:
let a = [3;5]; //这样创建了5个元素,每个元素都是3,3还是i32的,因为i32是默认类型
数组是一整块分配在栈上的内存
fn main (){
let a = [1,2,3,4,5];
let first = a[0];
let second = a[1];
}
当我们访问的数组下标超过了数组元素的个数怎么办,
fn main() {
let a = [1, 2, 3, 4, 5];
let index = 10;
let element = a[index];
println!("The value of element is: {}", element);
}
使用 cargo run 运行代码后会产生如下结果
$ cargo run
Compiling arrays v0.1.0 (file:///projects/arrays)
Finished dev [unoptimized + debuginfo] target(s) in 0.31 secs
Running `target/debug/arrays`
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is
10', src/main.rs:5:19
note: Run with `RUST_BACKTRACE=1` for a backtrace.
编译并没有产生任何错误,不过程序会出现一个 运行时(runtime)错误并且不会成功退出。当尝试用索引访问一个元素时,Rust 会检查指定的索引是否小于数组的长度。如果索引超出了数组长度,Rust 会 panic,这是 Rust 术语,它用于程序因为错误而退出的情况。
这是第一个在实战中遇到的 Rust 安全原则的例子。在很多底层语言中,并没有进行这类检查,这样当提供了一个不正确的索引时,就会访问无效的内存。通过立即退出而不是允许内存访问并继续执行,Rust 让你避开此类错误。第九章会讨论更多 Rust 的错误处理。
4.5 函数工作流程
在我们上面写的代码中我们用的最多的main函数是很多程序的入口,fn关键字代表声明一个新的函数
Rust 代码中的函数和变量名使用 snake case 规范风格。在 snake case 中,所有字母都是小写并使用下划线分隔单词。这是一个包含函数定义示例的程序:
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Another function.");
}
注意程序中已定义 another_function 函数,所以可以在 main 函数中调用它,源码中 another_function 定义在 main 函数 之后;也可以定义在之前。Rust 不关心函数定义于何处,只要定义了就行。
main 函数中的代码会按顺序执行。首先,打印 “Hello, world!” 信息,然后调用 another_function 函数并打印它的信息。
4.5.1 函数参数
函数也可以被定义为拥有 参数(parameters),当函数拥有参数(形参)时,可以为这些参数提供具体的值(实参),以下代码main函数中传递了一个实参进去
fn main(){
another_functions(5);
}
fn another_functions(x:i32){
println!("x is {}",x);
}
another_function 的声明中有一个命名为 x 的参数。x 的类型被指定为 i32。当将 5 传给 another_function 时,println! 宏将 5 放入格式化字符串中大括号的位置。
在函数签名中,必须声明每个参数的类型。
当一个函数有多个参数时,使用逗号分隔,像这样
fn main(){
another_function(5,6);
}
fn another_function(x:i32,y:i32){
println!("x is {}",x);
println!("y is {}",y);
}
我们知道函数是由一系列语句和一个可选的结尾表达式构成,目前为止,我们只介绍了没有结尾表达式的函数,因为 Rust 是一门基于表达式(expression-based的语言,这是一个需要理解的(不同于其他语言)重要区别。其他语言并没有这样的区别,所以让我们看看语句与表达式有什么区别以及这些区别是如何影响函数体的。
实际上,我们已经使用过语句和表达式。
语句
是执行一些操作但不返回值的指令
表达式
计算并产生一个值
fn main(){
let y = 6 ;
}
使y绑定到6是一个语句.
函数定义也是语句,上面整个例子本身就是一个语句。
语句不返回值。因此,不能把 let 语句赋值给另一个变量,比如下面的例子尝试做的,会产生一个错误:
fn main(){
let x = (let y =6);
}
let y = 6 语句并不返回值,所以没有可以绑定到 x 上的值
这与其他语言不同,例如 C 和 Ruby,它们的赋值语句会返回所赋的值。在这些语言中,可以这么写 x = y = 6,这样 x 和 y 的值都是 6;Rust 中不能这样写。
表达式会计算出一些值,并且你将编写的大部分 Rust 代码是由表达式组成的。考虑一个简单的数学运算,比如 5 + 6,这是一个表达式并计算出值 11。表达式可以是语句的一部分,在语句let y = 6;中6就是一个表达式,其返回值为6
函数调用是一个表达式。宏调用是一个表达式。我们用来创建新作用域的大括号(代码块),{},也是一个表达式,我们看下面的代码
fn main(){
let x = 5;
let y = {
let x = 3;
x+1
};
println!("y is {}",y);
}
上述代码中有一个代码块{lex x = 3;x+1}其实是一个表达式,他返回4给y绑定,注意我们这个代码快最后x+1后面没有分号;如果我们加了分号他就变成语句,语句不会返回值,所以y就不会绑定
4.5.2 具有返回值的函数
函数可以向调用它的代码返回值。我们并不对返回值命名,但要在箭头(->)后声明它的类型,如下
fn five->i32{
5
}
fn main(){
let x = five;
println!{"x is {}",x};
}
上面的例子中我们指定了函数5的返回类型为i32,并不用给返回值取名字,而函数5后面没有分号就是一个表达式,具有返回值,其值就是5,->后指定5的类型为i32,这个函数也是一个表达式,如果我们在5后面加上一个分号那么这个式子就会报错,因为他变成了一个语句,语句不会由返回值,而five函数又定义了返回值的类型。
4.6 控制流
4.6.1 if表达式
if 表达式允许根据条件执行不同的代码分支。 如下
fn main(){
let number = 3;
if number < 5{
println!("contition was true");
}else{
println!("condition was false");
}
}
所有的 if 表达式都以 if 关键字开头,其后跟一个条件,if 表达式中与条件关联的代码块有时被叫做 arms,也可以包含一个可选的 else 表达式来提供一个在条件为假时应当执行的代码块,如果不提供 else 表达式并且条件为假时,程序会直接忽略 if 代码块并继续执行下面的代码。
另外值得注意的是代码中的条件必须是 bool 值,如果条件不是 bool 值,我们将得到一个错误,例如
fn main(){
let number = 3 ;
if number {
println!("number was tree");
}
}
不像 Ruby 或 JavaScript 这样的语言,Rust 并不会尝试自动地将非布尔值转换为布尔值。必须总是显式地使用布尔值作为 if 的条件
可以将 else if 表达式与 if 和 else 组合来实现多重条件。例如:
fn main(){
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
}else if number % 3 == 0 {
println!("number is divisible by 3");
}else if number % 2 == 0{
println!("number is divisible by 2");
}else{
println!("numbrt is not divisible by 4,3,2");
}
}
当执行这个程序时,它按顺序检查每个 if 表达式并执行第一个条件为真的代码块。注意即使 6 可以被 2 整除,也不会输出 number is divisible by 2,更不会输出 else 块中的 number is not divisible by 4, 3, or 2。原因是 Rust 只会执行第一个条件为真的代码块,并且一旦它找到一个以后,甚至都不会检查剩下的条件了。
使用过多的 else if 表达式会使代码显得杂乱无章,所以如果有多于一个 else if 表达式,最好重构代码。为此,我们会介绍一个更为强大的 Rust 分支结构(branching construct),叫做 match。
因为 if 是一个表达式,我们可以在 let 语句的右侧使用它,我们知道表达式会返回值,如果在块中最后一个返回值不能加分号;看以下的例子
fn main (){
let condition = true;
let number = if condition {
5
}else {
6
};
println!("number is {}",number);
}
下面还有一个错误的代码
fn main (){
let condition = true;
let number = if {
5
}else{
”six“
}
println!("number is {}",number);
}
这个代码是错误的,因为我们的if后的语句在充当表达式要给number赋值,而我们的rust声明变量的时候,变量类型可由绑定的类型去判断,但是后面的if语句有2个类型的值,一个是int还有一个是string,编译器需要知道确切的类型好给number复制,所以为了安全考虑会报错,不允许这样执行
4.6.2 循环
loop
loop循环我们之前用到了,他就是要叫rust不断的循环,直到用户声明要退出(break,continue),比如如下的代码就会不断的运行
fn mian(){
loop{
println!("this is loop!!!");
}
}
当运行这个程序时,我们会看到连续的反复打印this is loop!!!,直到我们手动停止程序。大部分终端都支持一个快捷键,ctrl-c,来终止一个陷入无限循环的程序
当然我们也可以通过break退出
let loop和返回的妙用
看以下的代码
fn main(){
let mut counter = 0;
let result = loop{
counter += 1;
if counter == 10 {
break counter *2;
}
};
println!("result was {}",result);
}
在循环之前,我们声明了一个名为 counter 的变量并初始化为 0。接着声明了一个名为 result 来存放循环的返回值。在循环的每一次迭代中,我们将 counter 变量加 1,接着检查计数是否等于 10。当相等时,使用 break 关键字返回值 counter * 2。循环之后,我们通过分号结束赋值给 result 的语句。最后打印出 result 的值,也就是 20。
while条件循环
while循环的作用大家都知道,注意的是他和if一样只接受bool,它可以简化loop,if else ,break,例子如下
fn main (){
let mut number = 3;
while number != 0 {
println!("{}",number);
number = number - 1 ;
}
println!("LIFTOFF!!!");
}
for循环
我们可以用while写一个循环,遍历数组
fn main (){
let a = [1,2,3,4,5,6];
lex mut index = 0;
while index < 6{
println!("{}",a[0]);
index = index + 1;
}
}
我们用for循环写更快
rust的for循环是for i in格式的
fn main(){
let a = [10,20,30,40,50];
for i in a.iter(){
println!("{}",i);
}
}
如果还是while代码,我们从代码中减少一个元素那么程序就会报错而for这个并不会,iter是迭代器,后面会提到,他就是遍历容器用的,我们的数组,元组都是容器
我们也可以用for计时,而且非常的方便
fn main (){
for number in (1..4) {
println!("{}",number);
}
println!("LIFTOFF!!!");
}
(1…4)是rust内置的一个数据类型Range,它是标准库提供的类型,用来生成从一个数字开始到另一个数字之前结束的所有数字的序列。我们还可以在range后面加上rev方法使其反转,比如(1…4).rev()
4.7 所有权
一些语言中具有垃圾回收机制,在程序运行时不断地寻找不再使用的内存;在另一些语言中,程序员必须亲自分配和释放内存。Rust 则选择了第三种方式:通过所有权系统管理内存,学习rust的所有权之前先复习一下堆和栈
4.7.1 堆和栈
栈和堆都是代码在运行时可供使用的内存,但是它们的结构不同。栈以放入值的顺序存储值并以相反顺序取出值。这也被称作 后进先出(last in, first out)。想象一下一叠盘子:当增加更多盘子时,把它们放在盘子堆的顶部,当需要盘子时,也从顶部拿走。不能从中间也不能从底部增加或拿走盘子!增加数据叫做 进栈(pushing onto the stack),而移出数据叫做 出栈(popping off the stack)。
栈中的所有数据都必须占用已知且固定的大小。在编译时大小未知或大小可能变化的数据,要改为存储在堆上。堆是缺乏组织的:当向堆放入数据时,你要请求一定大小的空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer)。这个过程称作 在堆上分配内存(allocating on the heap),有时简称为 “分配”(allocating)。将数据推入栈中并不被认为是分配。因为指针的大小是已知并且固定的,你可以将指针存储在栈上,不过当需要实际数据时,必须访问指针。
访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。继续类比,假设有一个服务员在餐厅里处理多个桌子的点菜。在一个桌子报完所有菜后再移动到下一个桌子是最有效率的。从桌子 A 听一个菜,接着桌子 B 听一个菜,然后再桌子 A,然后再桌子 B 这样的流程会更加缓慢。出于同样原因,处理器在处理的数据彼此较近的时候(比如在栈上)比较远的时候(比如可能在堆上)能更好的工作。在堆上分配大量的空间也可能消耗时间。
跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上的重复数据的数量,以及清理堆上不再使用的数据确保不会耗尽空间,这些问题正是所有权系统要处理的。一旦理解了所有权,你就不需要经常考虑栈和堆了,不过明白了所有权的存在就是为了管理堆数据,能够帮助解释为什么所有权要以这种方式工作。
4.7.2 rust所有权的规则
- Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。
- 值有且只有一个所有者。
- 当所有者(变量)离开作用域,这个值将被丢弃。
作用域
作用域是一个项(item)在程序中有效的范围。假设有这样一个变量:
{ // s 在这里无效, 它尚未声明
let s = "String"; // 从此处起,s 是有效的
} // 此作用域已结束,s 不再有效
string类型
前面介绍的类型都是存储在栈上的并且当离开作用域时被移出栈,不过我们需要寻找一个存储在堆上的数据来探索 Rust 是如何知道该在何时清理数据的。
我们已经见过字符串字面值,字符串值被硬编码进程序里。字符串字面值是很方便的,不过他们并不适合使用文本的每一种场景。原因之一就是他们是不可变的。另一个原因是并不是所有字符串的值都能在编写代码时就知道:例如,要是想获取用户输入并存储该怎么办呢?为此,Rust 有第二个字符串类型,String。这个类型被分配到堆上,所以能够存储在编译时未知大小的文本
内存与分配
就字符串字面值来说,我们在编译时就知道其内容,所以文本被直接硬编码进最终的可执行文件中。这使得字符串字面值快速且高效。不过这些特性都只得益于字符串字面值的不可变性。不幸的是,我们不能为了每一个在编译时大小未知的文本而将一块内存放入二进制文件中,并且它的大小还可能随着程序运行而改变。所以上述的变量s其实还是存储在栈中的,因为字符串的字面量大小我们已经知晓,而s又是绑定在一个字符串字面值上,不是绑定在字符串上,但是又说string是存储在堆上的是什么意思了? 看以下代码,以下代码就是存储在堆上
fn main (){
let mut s = String::from("hello"); //这个s就是存储在堆上,因为他绑定在字符串变量上
s.pust_str(",world"); //在堆中为s追加字符,在栈中无法实现,因为大小都已经在编译的时候定义死了
println!("{}",s);
}
string::from(“hello”);就是根据这个字符串字面值创建一个字符串变量
首先我们在调用string::from(“hello”);的时候它的实现 (implementation) 请求其所需的内存。这在编程语言中是非常通用的。
然后回收的机制很多语言都有所不同,垃圾回收(garbage collector,GC)的语言中, GC 记录并清除不再使用的内存,而我们并不需要关心它。没有 GC 的话,识别出不再使用的内存并调用代码显式释放就是我们的责任了,跟请求内存的时候一样。从历史的角度上说正确处理内存回收曾经是一个困难的编程问题。如果忘记回收了会浪费内存。如果过早回收了,将会出现无效变量。如果重复回收,这也是个 bug。我们需要精确的为一个 allocate 配对一个 free。
rust采用了一个不同的策略,内存在拥有他的变量离开作用域后就被自动的释放
{
let s = String::from("hello"); // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,
// s 不再有效
这个模式对编写 Rust 代码的方式有着深远的影响。现在它看起来很简单,不过在更复杂的场景下代码的行为可能是不可预测的,比如当有多个变量使用在堆上分配的内存时。现在让我们探索一些这样的场景。
let x = 5 ;
let y =x;
我们大致可以猜到这在干什么:“将 5绑定到 x;接着生成一个值 x 的拷贝 并绑定到 y”。现在有了两个变量,x 和 y,都等于 5。这也正是事实上发生了的,因为整数是有已知固定大小的简单值,所以这两个 5 被放入了栈中。
string版本
let s1 = String.from("hello");
let s2 = s1;
这看起来与上面的代码非常类似,所以我们可能会假设他们的运行方式也是类似的:也就是说,第二行可能会生成一个 s1 的拷贝并绑定到 s2 上。不过,事实上并不完全是这样。
String 由三部分组成
- 一个指向存放字符串内容内存的指针
- 一个长度(String 的内容当前使用了多少字节的内存)
- 一个容量(String 从操作系统总共获取了多少字节的内存)
如下图
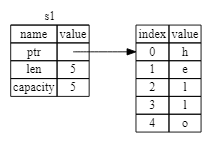
当我们将 s1 赋值给 s2,String 的数据被复制了
这意味着我们从栈上拷贝了它的指针、长度和容量。我们并没有复制指针指向的堆上数据。换句话说,内存中数据的表现如下图
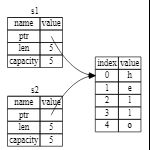
这样就有一个问题,如果s1或者s2推出作用域后会清空堆上的空间,如果另一个被赋值的变量又离开了作用域,又会第二次清空堆上的空间,这个叫做二次释放,他是内存安全bug之一,两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
为了确保内存安全,这种场景下 Rust 的处理有另一个细节值得注意。与其尝试拷贝被分配的内存,Rust 则认为** s1 不再有效**,因此 Rust 不需要在 s1 离开作用域后清理任何东西。看看在 s2 被创建之后尝试使用 s1 会发生什么;这段代码则会运行错误
{
let s1 =String::from("hello");
let s2 = s1;
println!("{}",s1);
}
以上的代码会运行错误,因为S1不生效了
如果你在其他语言中听说过术语 浅拷贝(shallow copy)和 深拷贝(deep copy),那么拷贝指针、长度和容量而不拷贝数据可能听起来像浅拷贝,不过因为 Rust 同时使第一个变量无效了,这个操作被称为 移动(move),而不是浅拷贝。上面的例子可以解读为 s1 被 移动 到了 s2 中。那么具体发生了什么,如下图
这样就解决了我们的问题!因为只有 s2 是有效的,当其离开作用域,它就释放自己的内存,完毕。
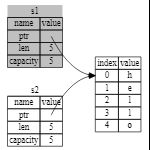
另外,这里还隐含了一个设计选择:Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何自动的复制可以被认为对运行时性能影响较小。如果我们真的想实现深拷贝,也就是移动指针,长度,容量的同时也会移动堆上的数据可以使用string的clone函数,如下图
let s1 = String:from("hello");
let s2 = s1::clone();
println!("s1 = {},s2 = {}",s1,s2);
这样就会拷贝堆上的数据,当然会资源的消耗会比s2=s1高
这里还有一个小知识
let x = 5 ;
let y = x;
println!("{},{}",x,y);
这里的代码竟然可以运行,为什么了?因为x和y存储在栈上,并没有存在堆上,数据都是已知的大小,所以拷贝其实际的值是快速的。这意味着没有理由在创建变量 y 后使 x 无效。换句话说,这里没有深浅拷贝的区别,所以这里调用 clone 并不会与通常的浅拷贝有什么不同,我们可以不用管它。
Rust 有一个叫做 Copy trait 的特殊注解,可以用在类似整型这样的存储在栈上的类型上
那么什么类型是可以直接copy而不用clone的勒?一般存储在栈上的都可以直接copy,所有的简单标量都可以copy,而复合类型都为普通标量的时候也可以copy,但是其中有一个元素为string就不行,要copy必须要clone
那么所有权在函数上是什么样的勒?
规则非常的简单,栈中的数据被copy后面还可以继续用(在此作用域中),而堆中的数据被移动,后面将不会生效
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里 ...
// ... 所以到这里不再有效
let x = 5; // x 进入作用域
makes_copy(x); // x 应该移动函数里,
// 但 i32 是 Copy 的,所以在后面可继续使用 x
} // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走,
// 所以不会有特殊操作
fn takes_ownership(some_string: String) { // some_string 进入作用域
println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法。占用的内存被释放
fn makes_copy(some_integer: i32) { // some_integer 进入作用域
println!("{}", some_integer);
} // 这里,some_integer 移出作用域。不会有特殊操作
如果我们指向获得其值并不像获得其使用权勒?我们可以用引用(&),看如下代码
fn main (){
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("the length of {} is {}",si,len);
}
fn calculate_length (s : &String) -> usize{
s.len();
}
这些 & 符号就是 引用,它们允许你使用值但不获取其所有权 ,如下图

看这个函数引用
let len = calculate_length(&s1);
&s1 语法让我们创建一个 指向 值 s1 的引用,但是并不拥有它。因为并不拥有这个值,当引用离开作用域时其指向的值也不会被丢弃。
fn calculate_length(s: &String) -> usize { // s 是对 String 的引用
s.len()
} // 这里,s 离开了作用域。但因为它并不拥有引用值的所有权,
// 所以什么也不会发生
变量 s 有效的作用域与函数参数的作用域一样,不过当引用离开作用域后并不丢弃它指向的数据,因为我们没有所有权。当函数使用引用而不是实际值作为参数,无需返回值来交还所有权,因为就不曾拥有所有权。
我们将获取引用作为函数参数称为 借用(borrowing)。正如现实生活中,如果一个人拥有某样东西,你可以从他那里借来。当你使用完毕,必须还回去。
如果我们尝试修改借用的变量呢?这行不通,因为借用一个东西后你要原物返回,不要损坏,这样比喻非常的形象 ,看如下代码,这样运行会报错
fn main(){
let s = String::from("hello");
change ("s");
}
fn change(some_string:&String){
some_string.push_char(",world);
}
正如变量默认是不可变的,引用也一样。(默认)不允许修改引用的值。
我们的应用默认可以修改其应用的值,我们还有一个引用,可以修改其引用的值,这个引用叫做可变引用
可变引用就是在引用的类型前面加上一个mut表示可变即可,看如下的代码
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
不过可变引用有一个很大的限制:在特定作用域中的特定数据有且只有一个可变引用,如下的代码就会报错
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{},{}",r1,r2);
这个限制的好处是 Rust 可以在编译时就避免数据竞争。数据竞争(data race)类似于竞态条件,它可由这三个行为造成:
- 两个或更多指针同时访问同一数据。
- 至少有一个指针被用来写入数据。
- 没有同步数据访问的机制。
数据竞争会导致未定义行为,难以在运行时追踪,并且难以诊断和修复;Rust 避免了这种情况的发生,因为它甚至不会编译存在数据竞争的代码!以下的代码就不会报错
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 在这里离开了作用域,所以我们完全可以创建一个新的引用
let r2 = &mut s;
我们 也 不能在拥有不可变引用的同时拥有可变引用。不可变引用的用户可不希望在他们的眼皮底下值就被意外的改变了!然而,多个不可变引用是可以的,因为没有哪个只能读取数据的人有能力影响其他人读取到的数据,例如下面的程序,运行会出错
let mut s = String::from("hello");
let r1 = &s; // 没问题,虽然s可变,但是此处不可变
let r2 = &s; // 没问题,虽然s可变,但是此处不可变
let r3 = &mut s; // 大问题,虽然s可变,但是上面引用都是不可变
println!("{}, {}, and {}", r1, r2, r3);
注意一个引用的作用域从声明的地方开始一直持续到最后一次使用为止,下面的代码就不会报错
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
println("{} and {}",r1,r2);
// 此位置之后 r1 和 r2 不再使用
let r3 = &mut s; // 没问题
println("{}",r3);
不可变引用 r1 和 r2 的作用域在 println! 最后一次使用之后结束,这也是创建可变引用 r3 的地方。它们的作用域没有重叠,所以代码是可以编译的。
在具有指针的语言中,很容易通过释放内存时保留指向它的指针而错误地生成一个 悬垂指针,所谓悬垂指针是其指向的内存可能已经被分配给其它持有者。相比之下,在 Rust 中编译器确保引用永远也不会变成悬垂状态:当你拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域。
我们在此处创建一个垂直引用,编译器会报错
fn main(){
let reference_to_nothing = dangle();
}
fn dangle()->&String{
let s = String::from("hello");
&s
}
为什么勒?
fn dangle() -> &String { // dangle 返回一个字符串的引用
let s = String::from("hello"); // s 是一个新字符串
&s // 返回字符串 s 的引用
} // 这里 s 离开作用域并被丢弃。其内存被释放。
// 危险!
字符串slice
字符串slice是 String 中一部分值的引用,如下所示
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
可以使用一个由中括号中的 [starting_index…ending_index] 指定的 range 创建一个 slice,其中 starting_index 是 slice 的第一个位置,ending_index 则是 slice 最后一个位置的后一个值。在其内部,slice 的数据结构存储了 slice 的开始位置和长度,长度对应于 ending_index 减去 starting_index 的值。所以对于 let world = &s[6…11]; 的情况,world 将是一个包含指向 s 第 7 个字节(从 1 开始)的指针和长度值 5 的 slice。他的存储结构如图所示

如果你就是从0开始可以不写staring_index如下
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
相同的如果slice包含最后一个字节,那么我们也可以省略,如果starting_index和ending_index都省略,那么代表整个字符串
5.0 结构体
rust的结构体和c语言的结构体大部分都差不多,有一些细微的差别,还有使用方法上rust有一些简洁操作
首先他和我们开始讲的元组有一些相似,和元组一样,结构体的每一部分可以是不同类型。但不同于元组,结构体需要命名各部分数据以便能清楚的表明其值的意义。由于有了这些名字,结构体比元组更灵活:不需要依赖顺序来指定或访问实例中的值。
rust结构体也是用struct关键字,struct定义实例如下
struct User{
username:String,
email:String,
sign_in_count:u64,
active:bool,
}
struct的初始化就是这样变量名字:变量类型(和c语言是反着的),中间都好隔开,注意最后一个成员还有逗号,如果我们使用这个变量中间也是用的:,使用初始化实例如下
let user1 = User{
email:String::from("[email protected]"),
username:String::from("elvis.zhang"),
active:true,
sign_in_count:1,
};
使用这个结构也是这样:左边是结构成员名,:右边是数据,我们也可以初始化特定的成员
user1.email = String::from("[email protected]");
注意整个实例必须是可变的;Rust 并不允许只将某个字段标记为可变
同其他任何表达式一样,我们可以在函数体的最后一个表达式中构造一个结构体的新实例,来隐式地返回这个实例
以下显示了一个 build_user 函数,它返回一个带有给定的 email 和用户名的 User 结构体实例。active 字段的值为 true,并且 sign_in_count 的值为 1。
fn build_user(email:String,username:String) ->User{
User{
email:email,
username:username,
active:true,
sign_in_count:1,
}
}
这个函数的参数和user的成员的值有重合,我们可以用跟为简洁的方法去写他
fn build_user(email:String,username:String) ->User{
User{
email,
username,
active:true,
sign_in_count:1,
}
}
这里省略勒User结构的email成员和username成员的值
如果我们还是上述结构User,不过已经初始化勒一个user1,并且已经赋值,然后我们再用结构User初始化一个user2,但是我们的user2的一些值想用user1的值可以这样写
let user1 = User{
email:String::("[email protected]"),
username:elvis.zhang,
active:true,
sign_in_count:1,
},
let user2 = User{
email:String::("[email protected]"),
username:wenhua.chen,
..user1
};
//user2的active值和sign_in_count的值和user1相同
sruct结构体所有权
在示例中的 User 结构体的定义中,我们使用了自身拥有所有权的 String 类型而不是 &str 字符串 slice 类型。这是一个有意而为之的选择,因为我们想要这个结构体拥有它所有的数据,为此只要整个结构体是有效的话其数据也是有效的。
可以使结构体存储被其他对象拥有的数据的引用,不过这么做的话需要用上 生命周期(lifetimes),这是一个第十章会讨论的 Rust 功能。生命周期确保结构体引用的数据有效性跟结构体本身保持一致。如果你尝试在结构体中存储一个引用而不指定生命周期将是无效的,比如这样:
struct User {
username: &str,
email: &str,
sign_in_count: u64,
active: bool,
}
fn main() {
let user1 = User {
email: "[email protected]",
username: "someusername123",
active: true,
sign_in_count: 1,
};
}
此处我们用结构体写一个计算正方体面积的式子
struct Rectangle{
length:u32,
weight:u32,
}
fn main(){
let rectangle = Rectangle{
weight:50,
length:30
};
println!("squra is {}",area(&rectangle));
}
fn area(rectangle:&Rectangle)->u32{
rectangle.length*rectangle.weight
}
注意这里函数 area 现在被定义为接收一个名叫 rectangle 的参数,其类型是一个结构体 Rectangle 实例的不可变借用。前面到过,我们希望借用结构体而不是获取它的所有权,这样 main 函数就可以保持 rect1 的所有权并继续使用它,所以这就是为什么在函数签名和调用的地方会有 &。
如果我们想打印出rectangle这个结构体的实例可以麻,看一下代码,会报错
struct Rectangle{
weight:u32,
length:u32,
}
fn main(){
let rectangle = Rectangle{
weight:30,
length:50
};
println!("rectangle is {}",rectangle);
}
以上的代码会报错,因为println!宏不能处理struct,不能将其显示出来,println! 宏能处理很多类型的格式,不过,{} 默认告诉 println! 使用被称为Display的格式:意在提供给直接终端用户查看的输出。目前为止见过的基本类型都默认实现了 Display,因为它就是向用户展示 1 或其他任何基本类型的唯一方式。不过对于结构体,println! 应该用来输出的格式是不明确的,因为这有更多显示的可能性:是否需要逗号?需要打印出大括号吗?所有字段都应该显示吗?由于这种不确定性,Rust 不会尝试猜测我们的意图,所以结构体并没有提供一个 Display 实现。
其实结构体在这里被println!宏看作是debug输出,也就是在println!中的{}里加上类型:?也就是println("{:?}");,它可以将结构体rectangle全部输出,但是编译器并不知道我们的结构体rectangle在debug这个trait里面,所以我们要在结构体前面加上注释表示debug输出变成这样
#[derive(Debug)]
struct Rectangle{
weight:u32,
length:u32,
}
fn main(){
let rectangle = Rectangle{
weight:30,
length:50
};
println!("rectangle is {}",rectangle);
}
如果我们的println!里面不用{:?}而是{:#?}的话可以列的显示结构体所有成员,{:?}是将所有成员在一行打印出来
5.1方法使用
方法 与函数类似:它们使用 fn 关键字和名称声明,可以拥有参数和返回值,同时包含在某处调用该方法时会执行的代码
方法与函数不同的是,因为它们在结构体的上下文中被定义(或者是枚举或 trait 对象的上下文),并且它们第一个参数总是 self,它代表调用该方法的结构体实例(就是为了方便不用重新再写一遍结构体名字就用self代替)。
看下列代码
#[derive(debug)]
struct Rectangle {
weight:u32,
length:u32,
}
impl Rectangle{ //定义Rectangle结构的方法
fn area(&self)->u32{ //具体方法
self.weight*self.length
}
}
fn main(){
let rectangle = Rectangle{
weight:30,
length:20
};
println!("squar is {}",rectangle.area);
}
注意&self代替了rectangle: &Rectangle,因为该方法位于 impl Rectangle 上下文中所以 Rust 知道 self 的类型是 Rectangle。注意仍然需要在 self 前面加上 &,就像 &Rectangle 一样。方法可以选择获取 self 的所有权,或者像我们这里一样不可变地借用 self,或者可变地借用 self,就跟其他参数一样。
这里选择 &self 的理由是我们并不想获取所有权,只希望能够读取结构体中的数据,而不是写入。如果想要在方法中改变调用方法的实例,需要将第一个参数改为 &mut self
使用方法替代函数,除了可使用方法语法和不需要在每个函数签名中重复 self 的类型之外,其主要好处在于组织性。我们将某个类型实例能做的所有事情都一起放入 impl 块中,而不是让将来的用户在我们的库中到处寻找 Rectangle 的功能。
在 C/C++ 语言中,有两个不同的运算符来调用方法:. 直接在对象上调用方法,而 -> 在一个对象的指针上调用方法,这时需要先解引用(dereference)指针。换句话说,如果 object 是一个指针,那么 object->something() 就像 (*object).something() 一样。
Rust 并没有一个与 -> 等效的运算符;相反,Rust 有一个叫 自动引用和解引用(automatic referencing and dereferencing)的功能。方法调用是 Rust 中少数几个拥有这种行为的地方。
他是这样工作的:当使用 object.something() 调用方法时,Rust 会自动为 object 添加 &、&mut 或 * 以便使 object 与方法签名匹配。也就是说,这些代码是等价的:p1.distance(&p2); (&p1).distance(&p2);第一行看起来简洁的多。这种自动引用的行为之所以有效,是因为方法有一个明确的接收者———— self 的类型。在给出接收者和方法名的前提下,Rust 可以明确地计算出方法是仅仅读取(&self),做出修改(&mut self)或者是获取所有权(self)。事实上,Rust 对方法接收者的隐式借用让所有权在实践中更友好。
5.2.1带有更多参数的方法
我们这里再写一个方法,此方法,再接收一个参数(此前一个参数是self,代表具体实例化后的结构)
#[derive(debug)]
struct Rectangle {
weight:u32,
length:u32,
}
impl Rectangle{ //定义Rectangle结构的方法
fn area(&self)->u32{ //具体方法
self.weight*self.length
}
fn can_hold(&self,other:&Rectangle)->bool{
self.weight > other.length && self.length > other.length
}
}
fn main(){
let rec1 = Rectangle{
weight:30,
length:20
};
let rec2 = Rectangle{
weight:50,
length:90
};
println!("rec1 can hold rec2 is {}",rec1.can_hold(&rec2));
println!("rec2 can hold rec1 is {}",rec2.can_hold(&rec2));
}
rect1.can_hold(&rect2) 传入了 &rect2,它是一个 Rectangle 的实例 rect2 的不可变借用。这是可以理解的,因为我们只需要读取 rect2(而不是写入,这意味着我们需要一个不可变借用),而且希望 main 保持 rect2 的所有权,这样就可以在调用这个方法后继续使用它。
5.3 关联函数
ipml块里面不光可以定义方法,也可以定义关联函数(是函数不是方法),关联函数作用与结构(未初始化的结构,我们之前就用string的关联函数from创建一个string变量,string::from() ),而我们的方法是作用与具体的结构比如上面Reactangle结构的具体实现rec1,或者rec2,而且关联函数用::调用,而方法用.调用
关联函数和方法在定义上的区别很小,方法调用了self关键字代表某个已经具体实例化后的结构,而关联函数不用self,比如我们下面的关联函数输入一个值使我们的结构长宽都使一样的
impl Rectangle{
fn square(size:u32)->Rectangle{
Rectangle{weight:size,length:size}
}
}
我们就这样使用let sq = Rectangle::square(3);这样初始化了一个长宽都为3的正方形。
6.0枚举和模式匹配
枚举使啥就不需要具体介绍了,我们这里直接说rust的枚举 ,我们假设要处理ip地址数据,我们知道ip地址有可能有ipv4或者ipv6所以枚举只用列举2类,v4或者v6,例子如下
enum IpAddrKind{
v4,
v6,
}
rust是这样使用枚举的成员的
let four = IpAddrKind::v4;
let six = IpAddrKind::v6;
注意枚举的成员位于其标识符的命名空间中,并使用两个冒号分开。这么设计的益处是现在 IpAddrKind::V4 和 IpAddrKind::V6 都是 IpAddrKind 类型的。例如,接着可以定义一个函数来获取任何 IpAddrKind:
fn route (ip_type:IpAddrKind)
{
...
}
现在我们可以使用任一成员调用这个函数
route(IpAddrKind::v4);
route(IpAddrKind::v6);
我们还可以联合struct和枚举去表示我们的ip地址和类型
enum IpAddrKind{
v4,
v6,
} //定义ip类型
struct IpAddr{
kind:IpAddrKind, //这里使用kind去表示类型
address:string, //表示具体的ip地址,地址是string
}
let home = IpAddr{
kind:IpAddrKind::v4,
address:string::from("127.0.0.1"),
};
let loopback = IpAddr{
kind:IpAddrKind::v6,
address::string::from("::1"),
};
这里我们定义了一个有两个字段的结构体 IpAddr:IpAddrKind(之前定义的枚举)类型的 kind 字段和 String 类型 address 字段。我们有这个结构体的两个实例。第一个,home,它的 kind 的值是 IpAddrKind::V4 与之相关联的地址数据是 127.0.0.1。第二个实例,loopback,kind 的值是 IpAddrKind 的另一个成员,V6,关联的地址是 ::1。我们使用了一个结构体来将 kind 和 address 打包在一起,现在枚举成员就与值相关联了。
我们可以有更为简洁的方法去实现,那就是将数据直接附加到我们的枚举成员中去,如下
enum IpAddrKind{
v4(String),
v6(String),
}
我们这样使用它
let home = IpAddrKind::v4(String::from("127.0.0.1"));
let loopback = IpAddrKind::v6(String::from("::1"));
这样就不需要一个额外的结构体了。用枚举替代结构体还有另一个优势:每个成员可以处理不同类型和数量的数据。IPv4 版本的 IP 地址总是含有四个值在 0 和 255 之间的数字部分。如果我们想要将 V4 地址存储为四个 u8 值而 V6 地址仍然表现为一个 String,这就不能使用结构体了。枚举则可以轻易处理的这个情况:
enum IpAddrKind{
v4(u8,u8,u8,u8),
v6(String),
}
let home = IpAddrKind::v4(127,0,0,1);
let home = IpaddrKind::V6("::1");
每一个枚举都可以存储不同数量类型的值比如我们下面的message枚举
enum message{
Quit,
Move {x:i32,y:i32};
Write(String),
ChangeColor(i32,i32,i32),
}
//Move 包含一个匿名结构体。
枚举也可以使用方法和结构一样,如下
enum message{
Quit,
Move {x:i32,y:i32};
Write(String),
ChangeColor(i32,i32,i32),
}
impl message{
fn call(&self){
...
}
}
let m = message::Write(String::from("hello")); //实例化message,这里使用的Write成员
m.call; //调用方法
6.1 Option枚举
Option枚举位于标准库中
Option 是标准库定义的另一个枚举。Option 类型应用广泛因为它编码了一个非常普遍的场景,即一个值要么有值要么没值。从类型系统的角度来表达这个概念就意味着编译器需要检查是否处理了所有应该处理的情况,这样就可以避免在其他编程语言中非常常见的 bug。
编程语言的设计经常要考虑包含哪些功能,但考虑排除哪些功能也很重要。Rust 并没有很多其他语言中有的空值功能,
空值的问题在于当你尝试像一个非空值那样使用一个空值,会出现某种形式的错误。因为空和非空的属性无处不在,非常容易出现这类错误。
然而,空值尝试表达的概念仍然是有意义的:空值是一个因为某种原因目前无效或缺失的值。
Rust 并没有空值,不过它确实拥有一个可以编码存在或不存在概念的枚举。这个枚举是 Option,而且它定义于标准库中,如下
enum Option{
Some(T),
None,
}
Option 枚举是如此有用以至于它甚至被包含在了 prelude 之中,你不需要将其显式引入作用域,它的成员也是如此,可以不需要 Option:: 前缀来直接使用 Some 和 None,即便如此 Option 也仍是常规的枚举,Some(T) 和 None 仍是 Option 的成员。 语法是一个我们还未讲到的 Rust 功能。它是一个泛型类型参数,我们后面会提到,目前,所有你需要知道的就是 < T > 意味着 Option 枚举的 Some 成员可以包含任意类型的数据,一下是我们使用nothing的例子
let some_number = Some(5);
let some_string = Some("a string");
let absent_number:Option = None;
如果使用 None 而不是 Some,需要告诉 Rust Option 是什么类型的,因为编译器只通过 None 值无法推断出 Some 成员保存的值的类型。
我们看以下的代码
let x: i8 = 5;
let y: Option = Some(5);
let sum = x + y;
以上的代码会报错,因为 Rust 不知道该如何将 Option< i8> 与 i8 相加,因为它们的类型不同
当在 Rust 中拥有一个像 i8 这样类型的值时,编译器确保它总是有一个有效的值我们可以自信使用而无需做空值检查
只有当使用 Option< i8>(或者任何用到的类型)的时候需要担心可能没有值,而编译器会确保我们在使用值之前处理了为空的情况。
换句话说,在对 Option< T> 进行 T 的运算之前必须将其转换为 T。通常这能帮助我们捕获到空值最常见的问题之一:假设某值不为空但实际上为空的情况。
那么当有一个 Option< T> 的值时,如何从 Some 成员中取出 T 的值来使用它呢?Option< T> 枚举拥有大量用于各种情况的方法:你可以查看它的文档。熟悉 Option< T> 的方法将对你的 Rust 之旅非常有用
6.2 match控制流
match它允许我们将一个值与一系列的模式相比较,并根据相匹配的模式执行相应代码,这个模式可以由字面值,变量,通配符和其他的内容构成,我们之前用到过match,我们再写一个例子
enum Coin{
Penny,
Nickel,
Dime,
Quarter,
}
fn vaulue_in_cents(coin:Coin)->u8{
match coin{
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
首先,我们列出 match 关键字后跟一个表达式,在这个例子中是 coin 的值,coin是我们传进来枚举的某个成员
这看起来非常像 if 使用的表达式,不过这里有一个非常大的区别:对于 if,表达式必须返回一个布尔值而这里它可以是任何类型的
match后面的一行行是分支,每一个分支有2个部分,一个模式和一些代码,第一个分支模式的值是Coin::Penny,而之后的 => 运算符将模式和将要运行的代码分开。这里的代码就仅仅是值 1。每一个分支之间使用逗号分隔。当 match 表达式执行时,它将结果值按顺序与每一个分支的模式相比较。如果模式匹配了这个值,这个模式相关联的代码将被执行。如果模式并不匹配这个值,将继续执行下一个分支,非常类似一个硬币分类器。可以拥有任意多的分支
如果想要在分支中运行多行代码,可以使用大括号
匹配分支的另一个有用的功能是可以绑定匹配的模式的部分值,比如下面的程序,
程序背景
1999 年到 2008 年间,美帝在 25 美分的硬币的一侧为 50 个州的每一个都印刷了不同的设计。其他的硬币都没有这种区分州的设计,所以只有这些 25 美分硬币有特殊的价值。可以将这些信息加入我们的 enum,通过改变 Quarter 成员来包含一个 State
#[derive(Debug)] //因为州是用枚举表示println!宏里面的display没有枚举类型
enum USstate{
alabama,
alaska,
...
}
enum Coin{
Penny,
Nickel,
Dime,
Quarter(USstate),
}
fn value_in_cents(coin:Coin)-> u8 {
match coin{
coin::Penny => 1,
coin::Nickel => 5,
coin::Dime => 10,
coin::Quarter(state) => {
println!("{}",state); //这里传进来Coin::Quarter(USstate)类型已经绑定到state上
25
},
}
}
我们调用这个函数
value_in_cents(Coin::Quarter(USstate::alabama));
当我们的上面穿的参数与match里面最后一个分支比较的时候USstate::alabama这个类型已经传递给state了
6.3匹配Option< T>
我们可以想之前的那样匹配,如下代码
fn plus_one(x:Option) -> Option{
match x{
None => None,
Some(i) => i+1,
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
当调用 plus_one(five) 时,plus_one 函数体中的 x 将会是值 Some(5)。接着将其与每个分支比较。
None => None,
值 Some(5) 并不匹配模式 None,所以继续进行下一个分支。
Some(i) => Some(i + 1),
Some(5) 与 Some(i) 匹配吗?当然匹配!它们是相同的成员。i 绑定了 Some 中包含的值,所以 i 的值是 5。接着匹配分支的代码被执行,所以我们将 i 的值加一并返回一个含有值 6 的新 Some。
plus_one 的第二个调用,这里 x 是 None。我们进入 match 并与第一个分支相比较。
None => None,
匹配上了!这里没有值来加一,所以程序结束并返回 => 右侧的值 None,因为第一个分支就匹配到了,其他的分支将不再比较。
将 match 与枚举相结合在很多场景中都是有用的。你会在 Rust 代码中看到很多这样的模式:match 一个枚举,绑定其中的值到一个变量,接着根据其值执行代码。这在一开始有点复杂,不过一旦习惯了,你会希望所有语言都拥有它!这一直是用户的最爱。
Rust 也提供了一个模式用于不想列举出所有可能值的场景。例如,u8 可以拥有 0 到 255 的有效的值,如果我们只关心 1、3、5 和 7 这几个值,就并不想必须列出 0、2、4、6、8、9 一直到 255 的值。所幸我们不必这么做:可以使用特殊的模式 _ 替代:
let some_u8_value = 0u8;
match some_u8_value{
1 => println!("one");
3 => println!("three");
5 => println!("five");
7 => println!("seven");
_ => println!("other"); //_代表匹配所有,这里也是匹配所有但是在最后,也就是说没有匹配到前面的几种情况就匹配这个分支
}
match 还有另一方面需要讨论。考虑一下 plus_one 函数的这个版本,它有一个 bug 并不能编译:
fn plus_one(x: Option) -> Option {
match x {
Some(i) => Some(i + 1),
}
}
Rust 知道我们没有覆盖所有可能的情况甚至知道哪些模式被忘记了!Rust 中的匹配是 穷尽的(exhaustive):必须穷举到最后的可能性来使代码有效。特别的在这个 Option 的例子中,Rust 防止我们忘记明确的处理 None 的情况,这使我们免于假设拥有一个实际上为空的值,这造成了之前提到过的价值亿万的错误。
6.4 if let控制流
如果我们之前的match只想匹配一项,可以这样写
let some_u8_value = Some(0u8);
match some_u8_value(){
Some(3) => println!("three");
_ => (),
}
这样我们只想匹配Some(3)的分支,我们还要写通配符_很麻烦,这时我们用if let来表达更为简洁
if let Some(3) = some_u8_value{
println!("three");
}
if let 获取通过等号分隔的一个模式和一个表达式。它的工作方式与 match 相同,这里的表达式对应 match 而模式则对应第一个分支
使用 if let 意味着编写更少代码,更少的缩进和更少的样板代码。然而,这样会失去 match 强制要求的穷尽性检查,if let 也可以加else
我们进一步的扩展上面的货币检查程序,统计其非25美分的硬币
let mut counter = 0; //设置计数器
if let Coin::Quarter(state) = coin{ // 如果coin这个枚举的具体值等于Coin枚举的Quarter成员就执行后面的步骤,并且将coin的附加值传入state中
println!("{}",state);
}else{
counter += 1; //计数器加一
}
所以我们的if let就是检查这个枚举的实例是否是我们的枚举中某一个成员,是的话(如果被比较的枚举实例有附加值,就传入这个比较的枚举成员附加向量中去)就执行后面的步骤如果不是也可以执行else
总结就是match就是用来匹配枚举实例是不是我们枚举类型的某一个成员,是的话就执行这个分支,不是就往下走,(必须将枚举所有的成员可能都写出来,不然编译器就会报错),if let就是match的简化版,可以只匹配某一个成员。
7.0 包,crate ,项目管理
7.1 包和crate
crate 是一个二进制项或者库。crate root 是一个源文件,Rust 编译器以它为起始点,并构成你的 crate 的根模块
包(package) 是提供一系列功能的一个或者多个crate
个包会包含有一个 Cargo.toml 文件,阐述如何去构建这些 crate。
包中所包含的内容由几条规则来确立。一个包中至多只能包含一个库 crate(library crate);包中可以包含任意多个二进制 crate(binary crate);包中至少包含一个 crate,无论是库的还是二进制的。
当我们输入cargo new NRW_PROJECT后新建一个工程,Cargo 会给我们的包创建一个 Cargo.toml 文件。查看 Cargo.toml 的内容,会发现并没有提到 src/main.rs,因为 Cargo 遵循的一个约定:src/main.rs 就是一个与包同名的二进制 crate 的 crate 根
同样的,Cargo 知道如果包目录中包含 src/lib.rs,则包带有与其同名的库 crate,且 src/lib.rs 是 crate 根。crate 根文件将由 Cargo 传递给 rustc 来实际构建库或者二进制项目。
在此,我们有了一个只包含 src/main.rs 的包,意味着它只含有一个名为 my-project 的二进制 crate。如果一个包同时含有 src/main.rs 和 src/lib.rs,则它有两个 crate:一个库和一个二进制项,且名字都与包相同。通过将文件放在 src/bin 目录下,一个包可以享有多个二进制 crate:每个文件都是一个分离出来的二进制 crate。
一个 crate 会将一个作用域内的相关功能分组到一起,使得该功能可以很方便地在多个项目之间共享。
我们在之前使用的 rand crate 提供了生成随机数的功能。通过将 rand crate 加入到我们项目的作用域中,我们就可以在自己的项目中使用该功能。rand crate 提供的所有功能都可以通过该 crate 的名字:rand 进行访问。
将一个 crate 的功能保持在其自身的作用域中,可以知晓一些特定的功能是在我们的 crate 中定义的还是在 rand crate 中定义的,这可以防止潜在的冲突。例如,rand crate 提供了一个名为 Rng 的特性(trait)。我们还可以在我们自己的 crate 中定义一个名为 Rng 的 struct。因为一个 crate 的功能是在自身的作用域进行命名的,当我们将 rand 作为一个依赖,编译器不会混淆 Rng 这个名字的指向。在我们的 crate 中,它指向的是我们自己定义的 struct Rng。我们可以通过 rand::Rng 这一方式来访问 rand crate 中的 Rng 特性(trait)。
7.2 定义模块来控制作用域的私有性
模块 让我们可以将一个 crate 中的代码进行分组,以提高可读性与重用性
模块还可以控制项的 私有性,即项是可以被外部代码使用的(public),还是作为一个内部实现的内容,不能被外部代码使用(private)。
餐馆中会有一些地方被称之为 前台(front of house),还有另外一些地方被称之为 后台(back of house)。前台是招待顾客的地方,在这里,店主可以为顾客安排座位,服务员接受顾客下单和付款,调酒师会制作饮品。后台则是由厨师工作的厨房,洗碗工的工作地点,以及经理做行政工作的地方组成
我们可以将函数放置到嵌套的模块中,来使我们的 crate 结构与实际的餐厅结构相同。通过执行
cargo new --lib restaurant
来创建一个新的名为 restaurant 的库,代码如下
mod front_house{
mod hosting{
fn add_to_waitlist(){
...
}
fn seat_at_table() {
..
}
}
mod serving(){
fn take_order(){
...
}
fn server_order(){
...
}
fn take_payment(){
...
}
}
}
将这个代码放在src/lib.rs中来定义一些模块和函数
我们定义一个模块,是以 mod 关键字为起始,然后指定模块的名字(本例中叫做 front_of_house),并且用花括号包围模块的主体。在模块内,我们还可以定义其他的模块,就像本例中的 hosting 和 serving 模块。模块还可以保存一些定义的其他项,比如结构体、枚举、常量、特性、或者函数。
通过使用模块,我们可以将相关的定义分组到一起,并指出他们为什么相关。程序员可以通过使用这段代码,更加容易地找到他们想要的定义,因为他们可以基于分组来对代码进行导航,而不需要阅读所有的定义。程序员向这段代码中添加一个新的功能时,他们也会知道代码应该放置在何处,可以保持程序的组织性。
在前面我们提到了,src/main.rs 和 src/lib.rs 叫做 crate 根。之所以这样叫它们的原因是,这两个文件的内容都是一个从名为 crate 的模块作为根的 crate 模块结构,称为 模块树(module tree),下方是模块树
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
这个树展示了一些模块是如何被嵌入到另一个模块的(例如,hosting 嵌套在 front_of_house 中)。这个树还展示了一些模块是互为 兄弟(siblings) 的,这意味着它们定义在同一模块中(hosting 和 serving 被一起定义在 front_of_house 中)。继续沿用家庭关系的比喻,如果一个模块 A 被包含在模块 B 中,我们将模块 A 称为模块 B 的 子(child),模块 B 则是模块 A 的 父(parent)。注意,整个模块树都植根于名为 crate 的隐式模块下。
7.3引用模块树的路径
路径有两种形式:
- 绝对路径(absolute path)从 crate 根开始,以 crate 名或者字面值 crate 开头。
- 相对路径(relative path)从当前模块开始,以 self、super 或当前模块的标识符开头。
绝对路径和相对路径都后跟一个或多个由双冒号(::)分割的标识符。
回看之前的例子,我们如何调用add_to_waitlist函数?
还是同样的问题,add_to_waitlist 函数的路径是什么?
在我们下面的代码中对我们上面的代码做了一些精简,如下
mod front_of_house {
mod hosting{
fn add_to_waitlist(){}
}
}
pub fn eat_at_restaurant(){
crate::front_of_house::hosting::add_to_waitlist();
front_of_house::hosting::add_to_waitlist();
}
pub 的那个代码块中第一句是用绝对路径去调用add_to_waitlist,第二句是用相对路径去调用add_to_waitlist
以上的代码是不能编译的
我们拥有 hosting 模块和 add_to_waitlist 函数的的正确路径,但是 Rust 不让我们使用,因为它不能访问私有片段。
模块不仅对于你组织代码很有用。他们还定义了 Rust 的 私有性边界(privacy boundary):这条界线不允许外部代码了解、调用和依赖被封装的实现细节所以,如果你希望创建一个私有函数或结构体,你可以将其放入模块。
Rust 中默认所有项(函数、方法、结构体、枚举、模块和常量)都是私有的,但是子模块中的项可以使用他们父模块中的项,这是因为子模块封装并隐藏了他们的实现详情,但是子模块可以看到他们定义的上下文。继续拿餐馆作比喻,把私有性规则想象成餐馆的后台办公室:餐馆内的事务对餐厅顾客来说是不可知的,但办公室经理可以洞悉其经营的餐厅并在其中做任何事情。
Rust 选择以这种方式来实现模块系统功能,因此默认隐藏内部实现细节。这样一来,你就知道可以更改内部代码的哪些部分而不会破坏外部代码。你还可以通过使用 pub 关键字来创建公共项,使子模块的内部部分暴露给上级模块。
使用pub关键字暴露路径
我们改进上面的代码,使用pub关键字暴露hosting模块
mod front_of_house {
pub mod hosting{
fn add_to_waitlist(){}
}
}
pub fn eat_at_restaurant(){
crate::front_of_house::hosting::add_to_waitlist();
front_of_house::hosting::add_to_waitlist();
}
还是会报错
因为在 mod hosting 前添加了 pub 关键字,使其变成公有的。伴随着这种变化,如果我们可以访问 front_of_house,那我们也可以访问 hosting。但是 hosting 的 内容(contents) 仍然是私有的;这表明使模块公有并不使其内容也是公有的。模块上的 pub 关键字只允许其父模块引用它。
让我们继续将 pub 关键字放置在 add_to_waitlist 函数的定义之前,使其变成公有。
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}
示例为 mod hosting 和 fn add_to_waitlist 添加 pub 关键字使他们可以在 eat_at_restaurant 函数中被调用,这样就可以编译成功,为什么?我们先来看发生了什么
在绝对路径,我们从 crate,也就是 crate 根开始。然后 crate 根中定义了 front_of_house 模块。front_of_house 模块不是公有的,不过因为 eat_at_restaurant 函数与 front_of_house 定义于同一模块中(即,eat_at_restaurant 和 front_of_house 是兄弟),我们可以从 eat_at_restaurant 中引用 front_of_house。接下来是使用 pub 标记的 hosting 模块。我们可以访问 hosting 的父模块,所以可以访问 hosting。最后,add_to_waitlist 函数被标记为 pub ,我们可以访问其父模块,所以这个函数调用是有效的!
在相对路径,其逻辑与绝对路径相同,除了第一步:不同于从 crate 根开始,路径从 front_of_house 开始。front_of_house 模块与 eat_at_restaurant 定义于同一模块,所以从 eat_at_restaurant 中开始定义的该模块相对路径是有效的。接下来因为 hosting 和 add_to_waitlist 被标记为 pub,路径其余的部分也是有效的,因此函数调用也是有效的!
使用spuer起始的相对路径
我们还可以使用 super 开头来构建从父模块开始的相对路径。这么做类似于文件系统中以 … (上一级目录)开头的语法。看我们以下的代码,如何使用super表示上一级目录
fn serve_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::serve_order();
}
fn cook_order() {}
}
fix_incorrect_order 函数在 back_of_house 模块中,所以我们可以使用 super 进入 back_of_house 父模块,也就是本例中的 crate 根。在这里,我们可以找到 serve_order。成功!我们认为 back_of_house 模块和 server_order 函数之间可能具有某种关联关系,并且,如果我们要重新组织这个 crate 的模块树,需要一起移动它们。因此,我们使用 super,这样一来,如果这些代码被移动到了其他模块,我们只需要更新很少的代码。
创建共有类型和枚举
我们还可以使用 pub 来设计公有的结构体和枚举,不过有一些额外的细节需要注意。如果我们在一个结构体定义的前面使用了 pub ,这个结构体会变成公有的,但是这个结构体的字段仍然是私有的
我们可以根据情况决定每个字段是否公有。看下方代码
mod back_of_house{
pub struct Breakfast{
pub toast:String,
seasonal_fruit:String,
}
impl Breakfast{
pub fn summer(toast:&str)->Breakfast{
Breakfast{
toast:String.from(toast),
seasonal_fruit:String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant(){
let mut meal = back_of_house::Breakfast::summer("rye");
meal.toast = String::from("Wheat");
println! ("i`d like {} toast please",meal.toast);
}
我们定义了一个公有结构体 back_of_hous:Breakfast,其中有一个公有字段 toast 和私有字段 seasonal_fruit
因为 back_of_house::Breakfast 结构体的 toast 字段是公有的,所以我们可以在 eat_at_restaurant 中使用点号来随意的读写 toast 字段。注意,我们不能在 eat_at_restaurant 中使用 seasonal_fruit 字段,因为 seasonal_fruit 是私有的
还请注意一点,因为 back_of_house::Breakfast 具有私有字段,所以这个结构体需要提供一个公共的关联函数来构造示例 Breakfast (这里我们命名为 summer)。如果 Breakfast 没有这样的函数,我们将无法在 eat_at_restaurant 中创建 Breakfast 实例,因为我们不能在 eat_at_restaurant 中设置私有字段 seasonal_fruit 的值。
如果我们将枚举设为公有,则它的所有成员都将变为公有,我们只需要在 enum 关键字前面加上pub
mod back_of_house{
pub enum Appetizer{
soup,
salad;
}
}
pub fn eat_at_resturant(){
let order1 = back_to_house::Appetizer::soup;
let order2 = back_to_house::Appetizer::salad;
}
因为我们创建了名为 Appetizer 的公有枚举,所以我们可以在 eat_at_restaurant 中使用 Soup 和 Salad 成员。如果枚举成员不是公有的,那么枚举会显得用处不大;给枚举的所有成员挨个添加 pub 是很令人恼火的,因此枚举成员默认就是公有的。结构体通常使用时,不必将它们的字段公有化,因此结构体遵循常规,内容全部是私有的,除非使用 pub 关键字。
7.4 使用use将名称引入作用域
mod front_of_house{
pub mod hosting{
pub fn add_to_waitlist(){}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_resturant(){
hosting::add_to_waitlist();
}
我们之前写的代码太长了,每一次调用模块都要写上绝对路径或者相对路径,我们可以使用use关键字直接引入这个路径,就如同他是在本地一样
我们将 crate::front_of_house::hosting 模块引入了 eat_at_restaurant 函数的作用域,而我们只需要指定 hosting::add_to_waitlist 即可在 eat_at_restaurant 中调用 add_to_waitlist 函数。
在作用域中增加 use 和路径类似于在文件系统中创建软连接
通过在 crate 根增加 use crate::front_of_house::hosting,现在 hosting 在作用域中就是有效的名称了,如同 hosting 模块被定义于 crate 根一样。通过 use 引入作用域的路径也会检查私有性,同其它路径一样
你还可以使用 use 和相对路径来将一个项引入作用域。如下
mod front_to_back{
pub mod hosting{
pub fn add_to_waitlist(){
}
}
}
use front_of_house::hosting;
pub fn eat_at_restaurant(){
hosting::add_to_waitlist();
}
我们还可以创建惯用的use路径
你可能会比较疑惑,为什么我们是指定 use crate::front_of_house::hosting ,然后在 eat_at_restaurant 中调用 hosting::add_to_waitlist ,而不是通过指定一直到 add_to_waitlist 函数的 use 路径来得到相同的结果
mod front_to_house{
pub mod hosting{
pub fn add_waitlist(){}
}
}
use front_to_house::hosting::add_waitlist; //直接将路径指到函数
pub fn eat_at_resturant(){
add_waitlist();
}
这样写当然可以,但是不符合我们的习惯
以上是使用 use 将函数引入作用域的习惯用法,要想使用 use 将函数的父模块引入作用域,我们必须在调用函数时指定父模块,这样可以清晰地表明函数不是在本地定义的,同时使完整路径的重复度最小化,以上的代码不清楚 add_to_waitlist 是在哪里被定义的。如果不看上面,我们有可能觉得他是在本地定义的,不是use进来的。
相反我们在引入结构体,枚举等其他的项时,我们一般就use全部(包含结构名字,函数是不包含),因为他是惯例,
use std::collections::HashMap;
fn main(){
let mut = HashMap::new();
map.insert(1,2);
}
这个习惯用法有一个例外,那就是我们想使用 use 语句将两个具有相同名称的项带入作用域,因为 Rust 不允许这样做
use std::fmt;
use std::io;
fn function1()->fmt::Result{
//skip
}
fn function2()->io::Result{
//skip
}
如你所见,使用父模块可以区分这两个 Result 类型。如果我们是指定 use std::fmt::Result 和 use std::io::Result,我们将在同一作用域拥有了两个 Result 类型,当我们使用 Result 时,Rust 则不知道我们要用的是哪个。
如果名字太复杂,我们也可以使用as关键字来提供新的名称 ,如下
use std::fmt::Result as fmtResult;
use std::io;
fn function1()->fmtResult{
//skip
}
fn function2()->Result{
//skip
}
现在我们有这种情况,我们use的时候想要外部的代码也可以使用,那么就用pub use关键字来引用
mod front_of_house{
pub mod hosting{
pub fn add_to_waitlist(){}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant(){
hosting::add_to_waitlist();
}
通过 pub use,现在可以通过新路径 hosting::add_to_waitlist 来调用 add_to_waitlist 函数。如果没有指定 pub use,eat_at_restaurant 函数可以在其作用域中调用 hosting::add_to_waitlist,但外部代码则不允许使用这个新路径。
使用外部包
在我们之前的猜猜看游戏中,我们再cargo.toml文件中的[dependencies]项中加上勒rand项,为了告诉cargo我们要下载这个包,好让我在程序中使用
[dependencies]
rand = "0.0.5"
然后我们在程序的第一行使用use将rand引入到我们的作用域中
,use以包名开始,然后是引入Rng这个trait到作用域中
use rand::Rng;
fn main(){
let secret_number = rand::thread_rng().gen_range(1,101);
}
将 Rng trait 引入作用域并调用了 rand::thread_rng 函数
crates.io 上有很多 Rust 社区成员发布的包,将其引入你自己的项目都需要一道相同的步骤:在 Cargo.toml 列出它们并通过 use 将其中定义的项引入项目包的作用域中。
注意标准库(std)对于你的包来说也是外部 crate,因为标准库随 Rust 语言一同分发,无需修改 Cargo.toml 来引入 std,不过需要通过use将标准库中定义的项引入项目包的作用域中来引用它们,比如我们使用的 HashMap
use std::collections::HashMap;
这是一个以标准库crate名std开头的绝对路径
如果我们引用多个包,模块,这个包都是属于一个库比如std,那么我们不用都一个一行列出来,可以这样
use std::cmp::Ordering;
use std::io;
//....
以上是一行一行列出来非常麻烦,可以这样
use std::{cmp::Ordering,io};
我们可以在路径的任何层级使用嵌套路径,这在组合两个共享子路径的 use 语句时非常有用,如下程序
use std::io;
use std::io::Write;
这样共享了这2个路径的子路径,我们可以更方便的调用,然后我们还有更为简洁的方法去写这段话
use std::io{self,Write};
和上面的式子一样不过这里的self是代表std::io自己,这一行便将 std::io 和 std::io::Write 同时引入作用域。
如果我们像将io下的所有项都引入作用域,我们可以用 * 表示如下,这个 * 叫做glob
use std::io::*
使用 glob 运算符时请多加小心!Glob 会使得我们难以推导作用域中有什么名称和它们是在何处定义的,打比方io下有一个函数,我们使用了以上的glob后可以直接写这个函数名,但是我们不知道这个函数定义在std::io中还是定义在我们本地。
7.5 将模块放入不同的文件内
到目前为止,本章所有的例子都在一个文件中定义多个模块,当模块变得更大时,你可能想要将它们的定义移动到单独的文件中,从而使代码更容易阅读。
比如我们src/front_of_house.rs文件里面的代码如下
pub mod hosting{
pub fn add_to_waitlist(){}
}
我们像在这个create跟文件src/lib.rs里面调用它,或者以 src/main.rs 为 crate 根文件的二进制 crate 项中调用它如下
mod front_of_house ;
use crate::front_of_house::hosting;
pub fn eat_at_restaurant(){
hosting::add_to_waitlist();
}
在 mod front_of_house 后使用分号,而不是代码块,这将告诉 Rust 在另一个与模块同名的文件中加载模块的内容.
继续重构我们例子,将 hosting 模块也提取到其自己的文件中,仅对 src/front_of_house.rs 包含 hosting 模块的声明进行修改:
// src/front_of_house.rs
pub mod hosting;
接着我们创建一个 src/front_of_house 目录和一个包含 hosting 模块定义的 src/front_of_house/hosting.rs 文件:
// src/front_of_house/hosting.rs
pub fn add_to_waitlist() {}
模块树依然保持相同,eat_at_restaurant 中的函数调用也无需修改继续保持有效
即便其定义存在于不同的文件中。这个技巧让你可以在模块代码增长时,将它们移动到新文件中。
8.0 常见集合
Rust 标准库中包含一系列被称为 集合(collections)的非常有用的数据结构。大部分其他数据类型都代表一个特定的值,不过集合可以包含多个值。不同于内建的数组和元组类型,这些集合指向的数据是储存在堆上的,这意味着数据的数量不必在编译时就已知,并且还可以随着程序的运行增长或缩小。
8.1 vector向量
vector 允许我们在一个单独的数据结构中储存多于一个的值,它在内存中彼此相邻地排列所有的值。vector 只能储存相同类型的值
我们可以调用Vec::new()来创建一个空的vector,如下
let v:Vec = Vec::new();
以上新建一个空的 vector 来储存 i32 类型的值
因为没有向这个 vector 中插入任何值,Rust 并不知道我们想要储存什么类型的元素。这是一个非常重要的点。vector 是用泛型实现的,后面会涉及到如何对你自己的类型使用它们。现在,所有你需要知道的就是 Vec 是一个由标准库提供的类型,它可以存放任何类型,而当 Vec 存放某个特定类型时,那个类型位于尖括号中
在更实际的代码中,一旦插入值 Rust 就可以推断出想要存放的类型,所以你很少会需要这些类型注解,如下
let v = vec![1,2,3];
以上使用了vec!宏,这个宏会根据我们提供的值来创建一个新的vec,以上创建了一个拥有值1,2,3的vec< i32>
我们可以向vec增加元素,使用put方法
let mut v = Vec::new();
v.push(5);
v.push(6);
...
...
如果想要能够改变它的值,必须使用 mut 关键字使其可变。放入其中的所有值都是 i32 类型的,而且 Rust 也根据数据做出如此判断,所以不需要 Vec< i32> 注解。
vector 在其离开作用域时会被释放
{
let v = vec![1, 2, 3, 4];
// 处理变量 v
} // <- 这里 v 离开作用域并被丢弃
当 vector 被丢弃时,所有其内容也会被丢弃,这意味着这里它包含的整数将被清理。这可能看起来非常直观,不过一旦开始使用 vector 元素的引用,情况就变得有些复杂了。下面让我们处理这种情况!
现在你知道如何创建、更新和销毁 vector 了,接下来的一步最好了解一下如何读取它们的内容。
有两种方法引用 vector 中储存的值。为了更加清楚的说明这个例子,我们标注这些函数返回的值的类型,看下面程序
let v = vec![1,2,3,4,5];
let third:&i32 = &v[2];
println!("the third part is {}",third);
match v.get(2){
Some(third) => println!("the third part is {}",third);
None => println!("there is no third part");
}
这里我们用了下标和get方法这2种方式去获取值,
这里有两个需要注意的地方。首先,我们使用索引值 2 来获取第三个元素,索引是从 0 开始的。其次,这两个不同的获取第三个元素的方式分别为:使用 & 和 [] 返回一个引用
或者使用 get 方法以索引作为参数来返回一个 Option<&T>。
Rust 有两个引用元素的方法的原因是程序可以选择如何处理当索引值在 vector 中没有对应值的情况。比如我们第二种使用一个Option枚举
对于访问一个元素下标个数之外的元素,get和下标获取结果截然不同
let v = vec![1,2,3,4,5];
let three = v[30];
这样会直接报panic!错误让程序执行不下去,如果我们使用get勒
let v = vec![1,2,3,4,5];
let three = v.get(30);
此时three是一个None类型(Option枚举内),不会报错,会继续执行,所以说我们该如何处理越界访问可以采取这2种方式
一旦程序获取了一个有效的引用,借用检查器将会执行所有权和借用规则
来确保 vector 内容的这个引用和任何其他引用保持有效。当我们借用一个元素后如果像再在此元素后面加上新值就会报错
let mut v = vec![1,2,3,4,5];
let first = &v[0];
v.push(6);
println!("{}",first);
以上的代码就会报错
为什么第一个元素的引用会关心 vector 结尾的变化?不能这么做的原因是由于 vector 的工作方式:在 vector 的结尾增加新元素时,在没有足够空间将所有所有元素依次相邻存放的情况下,可能会要求分配新内存并将老的元素拷贝到新的空间中。这时,第一个元素的引用就指向了被释放的内存。借用规则阻止程序陷入这种状况。
遍历vector的元素
如果想要依次访问 vector 中的每一个元素,我们可以遍历其所有的元素而无需通过索引一次一个的访问,下图展示勒如何用for循环来获取i32值的vector中每一个元素的不可变引用,并将其打印
let v = vec![100,32,57];
for i in &v{
println!{"{}",i};
}
我们也可以遍历可变 vector 的每一个元素的可变引用以便能改变他们。
let mut v = vec!["100,32,57"];
for i in &mut v{
*i += 50;
}
*就是解引用和c++一样
这里我们还有一个问题vector的成员必须要求类型一样,那么我们如果想让他不一样怎么办?我们可以使用枚举,让vector的每个成员变成枚举类型,枚举类型的每个成员可以是不同的变量 ,如下
enum SpreadsheetCell{
Int(i32),
Float(f64),
Text(String),
}
let v = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Float(1.2),
SpreadsheetCell::Text(String::from("hello")),
];
Rust 在编译时就必须准确的知道 vector 中类型的原因在于它需要知道储存每个元素到底需要多少内存。第二个好处是可以准确的知道这个 vector 中允许什么类型。如果 Rust 允许 vector 存放任意类型,那么当对 vector 元素执行操作时一个或多个类型的值就有可能会造成错误。使用枚举外加 match 意味着 Rust 能在编译时就保证总是会处理所有可能的情况
8.2 字符串
我们之前学过字符串,现在我们需要讨论一下字符串具体的意义,rust只有一种字符串类型str,我们之前说的字符串 slice,它通常以被借用的形式出现, slice它们是一些储存在别处的 UTF-8 编码字符串数据的引用。比如字符串字面值被储存在程序的二进制输出中,字符串 slice 也是如此。
称作 String 的类型是由标准库提供的,而没有写进核心语言部分,它是可增长的、可变的、有所有权的、UTF-8 编码的字符串类型
String 和字符串 slice 都是 UTF-8 编码的。
Rust 标准库中还包含一系列其他字符串类型比如 OsString、OsStr、CString 和 CStr。相关库 crate 甚至会提供更多储存字符串数据的选择。看到这些由 String 或是 Str 结尾的名字了吗?这对应着它们提供的所有权和可借用的字符串变体,就像是你之前看到的 String 和 str。举例而言,这些字符串类型能够以不同的编码,或者内存表现形式上以不同的形式,来存储文本内容。本章将不会讨论其他这些字符串类型,更多有关如何使用它们以及各自适合的场景,请参见其API文档。
许多vec的操作都可以在String中使用
创建一个空的字符串
let mut s = String::new();
这新建了一个叫做 s 的空的字符串,接着我们可以向其中装载数据。通常字符串会有初始数据,因为我们希望一开始就有这个字符串。为此,可以使用 to_string 方法,它能用于任何实现了 Display trait 的类型,字符串字面值也实现了它。
let data = "init";
let mut s = data.to_string();
//也可以不用变量data这个变量,直接用字符字面量
let mut s = "init".to_string;
也可以使用 String::from 函数来从字符串字面值创建 String。(我们之前常用的)
let s = String::from("init");
记住字符串是 UTF-8 编码的,所以可以包含任何可以正确编码的数据
let s = String::from("你好");
let s = String::from("");
所有这些都是有效的 String 值
可以通过 push_str 方法来附加字符串 slice,从而使 String 变长
let mut s = String::from("foo");
s.push_str("bar");
使用 push_str 方法向 String 附加字符串 slice
push_str 方法采用字符串 slice,因为我们并不需要获取参数的所有权,下面的例子表明我们push_str并没有获得字符的所有权
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("{}",s2);
可以使用说明没有获取s2所有权
如果 push_str 方法获取了 s2 的所有权,就不能在最后一行打印出其值了
push 方法被定义为获取一个单独的字符作为参数,并附加到 String 中
let mut s = String::from("lo");
s.push('l');
这样使用push将字符l添加到lo后面组成lol
我们也可以使用+运算符和format!宏去进行字符拼接
let s1 = String::from("hello,");
let s1 = String::from("friend");
let s3 = s1 + &s2;
注意这里的s1,已经被移动了,所以s1不能继续的被使用,s2可以,因为s2没有移动而是引用
执行完这些代码之后,字符串 s3 将会包含 Hello, friend
+ 运算符使用了 add 函数,这个函数签名看起来像这样
fn add(self,s:&str) -> String{}
这并不是标准库中实际的签名;标准库中的 add 使用泛型定义。这里我们看到的 add 的签名使用具体类型代替了泛型,这也正是当使用 String 值调用这个方法会发生的,后面会细讲
但是我们仔细的看一下add函方法原型,这个方法后面第二个参数是&str,而我们传入的参数是&String为毛它可以编过?这里我们回顾一下String和Str,&String和&Str
根本上来讲str是常量,我们无法调整str的大小,而String存储在堆上是变量,可以动态分配其大小,String并没有包含任何str,因为他直接指向一块内存,而str是包含一个固定的str,&str就是单纯的指向一个不可变的常量字符,&string也就是一个指针指向String,没有其所有权
之所以能够在 add 调用中使用 &s2 是因为 &String 可以被 强转(coerced)成 &str。当add函数被调用时,Rust 使用了一个被称为 解引用强制多态(deref coercion)的技术,你可以将其理解为它把 &s2 变成了 &s2[…]
我们上面的方法原型add中第一个参数self没有用&,那么说明获取了s1的所有权,并且s1将不再生效
所以虽然 let s3 = s1 + &s2; 看起来就像它会复制两个字符串并创建一个新的字符串,而实际上这个语句会获取 s1 的所有权,附加上从 s2 中拷贝的内容,并返回结果的所有权。换句话说,它看起来好像生成了很多拷贝,不过实际上并没有:这个实现比拷贝要更高效。
在比较复杂的字符串拼接上,比如我们有字符串变量,有字符串,而且量非常的大,比如下面
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "_" + &s2 + "_" + &s3;
这样非常复杂难看,我们可以用format!宏
这样更改
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{}_{}_{}",s1,s2,s3);
有点像prinln!宏
在很多语言中可以用索引下标去获取字符串中某个字符是常规操作,但是rust不行比如下面代码就会报错
let s = String::from("hello");
let s1 =s[1];
说明Rust 的字符串不支持索引。那么接下来的问题是,为什么不支持呢?为了回答这个问题,我们必须先聊一聊 Rust 是如何在内存中储存字符串的。
首先String 是一个 Vec< u8> 的封装
看如下的例子
let len = String::from("hola").len();
输出的是4,因为一个拉丁文占一个字节,再看下面俄语,我们知道俄语是由西里尔字母构成,而不是拉丁字母构成,西里尔字母却不是一个字母一个字节,如下
let len = String::from("Здравствуйте").len();
rust返回是24,但是这一共有12个西里尔字母,说明一个西里尔字母占2个字节,说明一个字符串字节值的索引并不总是对应的一个有效的unicode(一个索引指向一个字节),所以rust不支持string索引
answer 的值应该是什么呢?它应该是第一个字符 З 吗?当使用 UTF-8 编码时,З 的第一个字节 208,第二个是 151,所以 answer 实际上应该是 208,不过 208 自身并不是一个有效的字母。返回 208 可不是一个请求字符串第一个字母的人所希望看到的,不过它是 Rust 在字节索引 0 位置所能提供的唯一数据。
最后一个 Rust 不允许使用索引获取 String 字符的原因是,索引操作预期总是需要常数时间 (O(1))。但是对于 String 不可能保证这样的性能,因为 Rust 必须从开头到索引位置遍历来确定有多少有效的字符。
索引字符串通常是一个坏点子,因为字符串索引应该返回的类型是不明确的:字节值、字符、字形簇或者字符串 slice。因此,如果你真的希望使用索引创建字符串 slice 时,Rust 会要求你更明确一些。为了更明确索引并表明你需要一个字符串 slice,相比使用 [] 和单个值的索引,可以使用 [] 和一个 range 来创建含特定字节的字符串 slice,比如下方代码是可以的
let hello = "Здравствуйте";
let s = &hello[0..4];
这代表s是一个&str,但是&hello[0…1]就不行
如果你需要操作单独的 Unicode 标量值(每一个字符),最好的选择是使用 chars 方法
for i in "नमस्ते".chars(){
println!("{}",i);
}
显示以下结果
न
म
स
्
त
े
bytes 方法返回每一个原始字节
for b in "नमस्ते".bytes() {
println!("{}", b);
}
显示如下结果
224
164
// --snip--
165
135
8.3 hashmap
HashMap
哈希 map 可以用于需要任何类型作为键来寻找数据的情况,而不是像 vector 那样通过索引。例如,在一个游戏中,你可以将每个团队的分数记录到哈希 map 中,其中键是队伍的名字而值是每个队伍的分数。给出一个队名,就能得到他们的得分。
首先我们使用new方法创建一个空的hashmap,并且使用insert插入元素
use std::collections::Hashmap;
let mut scores = Hashmap.new();
scores.insert(String::from("blue"),10);
scores.insert(String::from("yellow"),50); //元素要一对一对插入
首先 use 标准库中集合部分的 HashMap。在这三个常用集合中,HashMap 是最不常用的,所以并没有被 prelude 自动引用,所以他也并没有内建的宏
像 vector 一样,哈希 map 将它们的数据储存在堆上,我们上面的例子的键类型是string,值类型是i32,和vector一样,所有的键必须是相同类型,值也必须都是相同类型
我们还有别的方法创建hashmap
use std::collections::Hashmap;
let teams = vec![String:from("blue"),String:from("yellow")];
let init_scores = vec![10,50];
let scores:Hashmap< _,_> = teams.iter().zip(init_scores.iter()).collect();
以上的方法非常巧妙首先创建2个vec分别存储2个建和2个值,然后最后一行先调用teams的迭代器取出第一个元素,然后再调用zip方法,并且向里面传参init_score的迭代器也就是init_score的第一个元素,将这2个元素组成一个元组vector,此vector第一个元素就是元组,元组的成员就是开始2个vector的第一个值,最后调用collect方法将元组vector转变Hashmap
这里 HashMap<_, _> 类型注解是必要的,因为可能 collect 很多不同的数据结构,而除非显式指定否则 Rust 无从得知你需要的类型。
hashmap所有权
hashmap也遵循所有权规则,如果一个值拷贝给别的值后这个值将不生效,如下
use std::collections::Hashmap;
let field_name = String::from("favorite color");
let field_value = String::from("yellow") ;
let mut map = Hashmap.new();
map.insert(field_name,field_value);
//这里 field_name 和 field_value 不再有效,
如果将值的引用插入哈希 map,这些值本身将不会被移动进哈希 map。但是这些引用指向的值必须至少在哈希 map 有效时也是有效的
我们可以通过get方法通过建获取hashmap的值
use std::collections::Hashmap;
let mut scores = Hashmap::new();
scores.insert(String::from("blue"),10);
scores.insert(String::("yellow"),50);
let team_name = String::from("blue");
let score = scores.get(&team_name);
score 是与蓝队分数相关的值,应为 Some(10)。因为 get 返回 Option < V>,所以结果被装进 Some;如果某个键在哈希 map 中没有对应的值,get 会返回 None
我们也可以使用for遍历hashmap的每一个键值对
use std::collections::Hashmap;
let mut scores = Hashmap.new();
scores.insert(String::from("blue"),10);
scores.insert(String::from("yellow"),50);
for (key,value) in &scores{
println!("{}:{}",key,value);
}
这会以任意顺序打印出每一个键值对:
如果我对一个建连续插入一个值,那么后插入的就会把前插入的覆盖,比如下面的代码对blue连续插2此值前一个10会被覆盖
use std::collections::Hashmap;
let mut scores = Hashmap.new();
scores.insert(String::from("blue"),10);
scores.insert(String::from("blue"),20);
println!("{:?}", scores);
我们也可以使用hashmap的entry方法检查这个建是否存在,或者建对应的值是否存在,如果建不存在,或者建对应的值不存在那么可以再调用enter方法的or_insert()方法插入,并返回修改过的 Entry,如果都存在就返回这个值的 Entry,不插入
以下代码第一个entry检查blue建存在,而且值存在,就不修改这个hashmap,并且返回entry(没有意义因为没有绑定),第二个entry检测到yellow建没有,然后在hashmap中创建建,并且调用or_insert插入值50.
use std::collections::Hashmap;
let mut scores = Hashmap::new();
scores.insert(String::from("blue"),10);
scores.entry(String::from("blue")).or_insert(50);
scores.entry(String::from("yellow")).or_insert(10);
println!("{:?}",scores);
entry和其or_insert还有很多妙用,我们要先知道就算entry匹配里面的建和值都存在,只要是entry调用了or_insert都会返回一个这个建所对应的值的可变引用,我们可以解引用然后改变这个值,意味着引用指向的值(建所对应的值也更改了),看如下代码
use std::collections::Hashmap;
let txt = "hello world wonderful world";
let mut map = Hashmap::new();
for word in text.split_withspace{ // text的关联函数split_withspace将text以空格为界限分开,然我们好进行每一次迭代
let count = map.entry(word).or_insert(0); //插入值0,不管word建存不存在,只要调用了or_insert就会返回值0的可变引用给count
*count += 1; //解引用count并且自身+1,那么hashmap里面所对应的值也会改变
}
println!("{:?}",map);
9.0 错误处理
很多高级语言都有错误处理的功能,rust也不例外,rust分可恢复错误(recoverable)和 不可恢复错误(unrecoverable)
- 可恢复错误(recoverable)
可恢复错误通常代表向用户报告错误和重试操作是合理的情况,比如未找到文件 - 不可恢复错误(unrecoverable)
不可恢复错误通常是 bug 的同义词,比如尝试访问超过数组结尾的位置。
9.1 panic! 与不可恢复的错误
我们rust有panic!宏 当执行这个宏时,程序会打印出一个错误信息,展开并清理栈数据,然后接着退出,出现这种情况的场景通常是检测到一些类型的 bug,而且程序员并不清楚该如何处理它。
当出现 panic 时,程序默认会开始 展开(unwinding),这意味着 Rust 会回溯栈并清理它遇到的每一个函数的数据,不过这个回溯并清理的过程有很多工作。另一种选择是直接终止(abort),这会不清理数据就退出程序。那么程序所使用的内存需要由操作系统来清理。如果你需要项目的最终二进制文件越小越好,panic 时通过在 Cargo.toml 的 [profile] 部分增加 panic = ‘abort’,可以由展开切换为终止。例如,如果你想要在release模式中 panic 时直接终止:
[profile.release] panic = 'abort'
假设我们在上述的cargo.homl文件中定义了panic并且其为abort,那么我们可以在程序中调用panic宏去使用
fn main (){
panic!("crash and burn");
}
程序会这样输出
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at 'crash and burn', src/main.rs:2:5
note: Run with `RUST_BACKTRACE=1` for a backtrace.
倒数第二行就是我们代码中panic后的信息,行和列数,当然也有可能这个panic不在我们的代码中,而是指向别的代码,看如下的代码
fn main (){
let v = vec![1,2,3];
v[99];
}
这个缓冲区溢出会报panic,Rust 会停止执行并拒绝继续 ,这个panic报的错并没有在我们的代码中定义,因为这是标准库中 Vec 的实现。这是当对 vector v 使用 [] 时 vec.rs 中会执行的代码,也是真正出现 panic! 的地方。这时候我们可以介绍最后一个重要的变量RUST_BACKTRACE
我们可以设置 RUST_BACKTRACE 环境变量来得到一个 backtrace。backtrace 是一个执行到目前位置所有被调用的函数的列表。
阅读 backtrace 的关键是从头开始读直到发现你编写的文件。这就是问题的发源地,这一行往上是你的代码所调用的代码;往下则是调用你的代码的代码
让我们将 RUST_BACKTRACE 环境变量设置为任何不是 0 的值来获取 backtrace 看看
RUST_BACKTRACE=1 cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/panic`
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', libcore/slice/mod.rs:2448:10
stack backtrace:
0: std::sys::unix::backtrace::tracing::imp::unwind_backtrace
at libstd/sys/unix/backtrace/tracing/gcc_s.rs:49
1: std::sys_common::backtrace::print
at libstd/sys_common/backtrace.rs:71
at libstd/sys_common/backtrace.rs:59
2: std::panicking::default_hook::{
{closure}}
at libstd/panicking.rs:211
3: std::panicking::default_hook
at libstd/panicking.rs:227
4: as core::panic::BoxMeUp>::get
at libstd/panicking.rs:476
5: std::panicking::continue_panic_fmt
at libstd/panicking.rs:390
6: std::panicking::try::do_call
at libstd/panicking.rs:325
7: core::ptr::drop_in_place
at libcore/panicking.rs:77
8: core::ptr::drop_in_place
at libcore/panicking.rs:59
9: >::index
at libcore/slice/mod.rs:2448
10: core::slice:: for [T]>::index
at libcore/slice/mod.rs:2316
11: as core::ops::index::Index>::index
at liballoc/vec.rs:1653
12: panic::main
at src/main.rs:4
13: std::rt::lang_start::{
{closure}}
at libstd/rt.rs:74
14: std::panicking::try::do_call
at libstd/rt.rs:59
at libstd/panicking.rs:310
15: macho_symbol_search
at libpanic_unwind/lib.rs:102
16: std::alloc::default_alloc_error_hook
at libstd/panicking.rs:289
at libstd/panic.rs:392
at libstd/rt.rs:58
17: std::rt::lang_start
at libstd/rt.rs:74
18: panic::main
输出中,backtrace 的 12 行指向了我们项目中造成问题的行:src/main.rs 的第 4 行,如果你不希望程序 panic,第一个提到我们编写的代码行的位置是你应该开始调查的,以便查明是什么值如何在这个地方引起了 panic
我们故意编写会 panic 的代码来演示如何使用 backtrace,修复这个 panic 的方法就是不要尝试在一个只包含三个项的 vector 中请求索引是 100 的元素。当将来你的代码出现了 panic,你需要搞清楚在这特定的场景下代码中执行了什么操作和什么值导致了 panic,以及应当如何处理才能避免这个问题。
9.2 Result 与可恢复的错误
首先我们要明白大部分错误并没有严重到需要程序完全停止执行。有时,一个函数会因为一个容易理解并做出反应的原因失败。例如,如果因为打开一个并不存在的文件而失败,此时我们可能想要创建这个文件,而不是终止进程。
回忆我们之前学到的Result 枚举,用它来处理潜在错误,他的枚举原型如下
enum Result {
Ok(T),
Err(E),
}
T 和 E 是泛型类型参数后面会讲,现在你需要知道的就是 T 代表成功时返回的 Ok 成员中的数据的类型,而 E 代表失败时返回的 Err 成员中的错误的类型
让我们调用一个返回 Result 的函数,因为它可能会失败
fn main (){
let f = File::open("hello.txt");
}
如果hello.txt文件不存在就会报错,我们如果将f指向一个错误的类型也会报错
fn main(){
let f:u32 = File::open("hello.txt");
}
我们知道File::open函数返回的是Result
这里T放了成功值的类型 std::fs::File它是一个文件句柄。E 被用在失败值上时 E 的类型是 std::io::Error
当 File::open 成功的情况下,变量 f 的值将会是一个包含文件句柄的 Ok 实例。在失败的情况下,f 的值会是一个包含更多关于出现了何种错误信息的 Err 实例。我们如何使用勒?当然是我们的match
use std::fs::File;
fn main(){
let f = File::open("hello.txt");
let f = match f {
Ok(file) => file,
Err(error) => println("Problem opening the file{:?}",error);
};
}
注意与 Option 枚举一样,Result 枚举和其成员也被导入到了 prelude 中,所以就不需要在 match 分支中的 Ok 和 Err 之前指定 Result::。
这里我们告诉 Rust 当结果是 Ok 时,返回 Ok 成员中的 file 值,然后将这个文件句柄赋值给变量 f。match 之后,我们可以利用这个文件句柄来进行读写。
match 的另一个分支处理从 File::open 得到 Err 值的情况。在这种情况下,我们选择调用 panic! 宏。如果当前目录没有一个叫做 hello.txt 的文件,当运行这段代码时会看到如下来自 panic! 宏的输出:
我们再将上述的代码进行改进,如果我们的error是找不到文件error我们就创建一个新的句柄返回(创建新文件),如果是因为文件权限问题那么我们就panic
use std::fs::File;
use std::io::ErrorKind;
fn main (){
f = File::open("hello.txt");
let f = match f {
Ok(file) => file,
Err(error) => match error.kind(){
ErrorKind::Notfound => macth File::Create("hello.txt"){
OK(fs) => fs,
Err(e) => panic(""Problem creating the file: {:?}",e),
},
other_error => panic("Problem opening the file: {:?}"other_error),
},
};
}
File::open 返回的 Err 成员中的值类型 io::Error,它是一个标准库中提供的结构体。这个结构体有一个返回 io::ErrorKind 值的 kind 方法可供调用。io::ErrorKind 是一个标准库提供的枚举,它的成员对应 io 操作可能导致的不同错误类型。我们感兴趣的成员是 ErrorKind::NotFound,它代表尝试打开的文件并不存在。所以 match 的 f 匹配,不过对于 error.kind() 还有一个内部 match。
我们希望在匹配守卫中检查的条件是 error.kind() 的返回值是 ErrorKind的 NotFound 成员。如果是,则尝试通过 File::create 创建文件。然而因为 File::create 也可能会失败,还需要增加一个内部 match 语句。当文件不能被打开,会打印出一个不同的错误信息。外部 match 的最后一个分支保持不变,这样对任何除了文件不存在的错误会使程序 panic。
match 确实很强大,不过也非常的基础,后面我们会介绍闭包(closure)。Result
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let f = File::open("hello.txt").unwrap_or_else(|error| {
if error.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|error| {
panic!("Problem creating the file: {:?}", error);
})
} else {
panic!("Problem opening the file: {:?}", error);
}
});
}
match 能够胜任它的工作,不过它可能有点冗长并且不总是能很好的表明其意图。Result
其中之一叫做 unwrap
如果 Result 值是成员 Ok,unwrap 会返回 Ok 中的值。如果 Result 是成员 Err,unwrap 会为我们调用 panic!,例子如下
use std::fs::File;
fn main(){
let f = File::open("hello.txt").unwrap();
}
如果hello.txt不在那么就panic,当然panic内容不是自定义的,如果想自定义可以用expect方法代替unwrap方法,它可以自定义panic
use std::fs::File;
fn main(){
let f = File::open("hello.txt").expect("Failed to open hello.txt");
}
expect 与 unwrap 的使用方式一样:返回文件句柄或调用 panic! 宏。expect 用来调用 panic! 的错误信息将会作为参数传递给 expect ,而不像unwrap 那样使用默认的 panic! 信息
当编写一个其实现会调用一些可能会失败的操作的函数时,除了在这个函数中处理错误外,还可以选择让调用者知道这个错误并决定该如何处理。这被称为 传播(propagating)错误
以下代码展示了一个从文件中读取用户名的函数。如果文件不存在或不能读取,这个函数会将这些错误返回给调用它的代码:
use std::io;
use std::io::Read;
use std::fs::File;
fn read_username_from_file()->Result< String,io::Error >{
let f = File::open("hello.txt");
let mut f = match f {
Ok(file)=>file,
Err(e) => return Err(e),
};
let mut s = String::new();
match f.read_to_string(&mut s){
Ok(_) => Ok(s),
Err(e) => Err(e)
}
}
首先让我们看看函数的返回值:Result
函数从文件中读取到的用户名。如果函数遇到任何错误,函数的调用者会收到一个 Err 值,它储存了一个包含更多这个问题相关信息的 io::Error 实例,这里选择 io::Error 作为函数的返回值是因为它正好是函数体中那两个可能会失败的操作的错误返回值:File::open 函数和 read_to_string 方法。
函数体以 File::open 函数开头。接着使用 match 处理返回值 Result,类似于上上个示例 中的 match,唯一的区别是当 Err 时不再调用 panic!,而是提早返回并将 File::open 返回的错误值作为函数的错误返回值传递给调用者。如果 File::open 成功了,我们将文件句柄储存在变量 f 中并继续。
变量 s 中创建了一个新 String 并调用文件句柄 f 的 read_to_string 方法来将文件的内容读取到 s 中,read_to_string 方法也返回一个 Result 因为它也可能会失败:哪怕是 File::open 已经成功了。所以我们需要另一个 match 来处理这个 Result,如果 read_to_string 成功了,那么这个函数就成功了,并返回文件中的用户名,它现在位于被封装进 Ok 的 s 中。如果read_to_string 失败了,则像之前处理 File::open 的返回值的 match 那样返回错误值。不过并不需要显式的调用 return,因为这是函数的最后一个表达式。
调用这个函数的代码最终会得到一个包含用户名的 Ok 值,或者一个包含 io::Error 的 Err 值。我们无从得知调用者会如何处理这些值。例如,如果他们得到了一个 Err 值,他们可能会选择 panic! 并使程序崩溃、使用一个默认的用户名或者从文件之外的地方寻找用户名。我们没有足够的信息知晓调用者具体会如何尝试,所以将所有的成功或失败信息向上传播,让他们选择合适的处理方法。
这种传播错误的模式在 Rust 是如此的常见,以至于 Rust 提供了 ? 问号运算符来使其更易于处理。
?运算符专门用来传递错误(不是成功),上述的代码完全可以写成下面这样
use std::io;
use std::io::Read;
use std::fs::File;
fn read_username_from_file()->Result{
let mut f = File::open("hello.txt")?; //调用?运算符只传递错误出去
let mut s = String::new();
f.read_to_string(& mut s)?; //调用?运算符只传递错误出去
Ok(s) //如果都ok就传递ok成功出去其值是s
}
? 被定义为与上上示例中定义的处理 Result 值的 match 表达式有着完全相同的工作方式。如果 Result 的值是 Ok,这个表达式将会返回 Ok 中的值而程序将继续执行。如果值是 Err,Err 中的值将作为整个函数的返回值,就好像使用了 return 关键字一样,这样错误值就被传播给了调用者。
match 表达式与问号运算符所做的有一点不同:? 运算符所使用的错误值被传递给了 from 函数,它定义于标准库的 From trait 中,其用来将错误从一种类型转换为另一种类型。当 ? 运算符调用 from 函数时,收到的错误类型被转换为定义为当前函数返回的错误类型。这在当一个函数返回一个错误类型来代表所有可能失败的方式时很有用,即使其可能会因很多种原因失败。只要每一个错误类型都实现了 from 函数来定义如将其转换为返回的错误类型,? 运算符会自动处理这些转换
我们还有更简单的方法表示
use std::io;
use std::io::Read;
use std::fs::File;
fn read_username_from_file()->Result
{
let mut s = String::new();
File::open("hello.txt")?.read_to_string(& mut s)?;
Ok(s)
}