实战:简书爬取之多线程爬取(二)速度提升何止10倍
一、程序结构
既然要使用多线程,那么关于多线程的使用的模型我们也要了解一下。
许多新手在写多线程的代码时总是喜欢把代码一股脑全部塞在一个类中。
这样的写法其实是对多线程的错误使用
首先就程序设计来说,这样不符合模块化的设计
其次就是这样的代码往往会有很严重的竞争问题,需要很多的资源锁来保证线程安全,这样就拉低了程序执行的速度。
实际上,多线程往往是和生产—消费模型挂钩的,以我们的简书文章信息爬虫为例,它的多线程结构示意图如下:
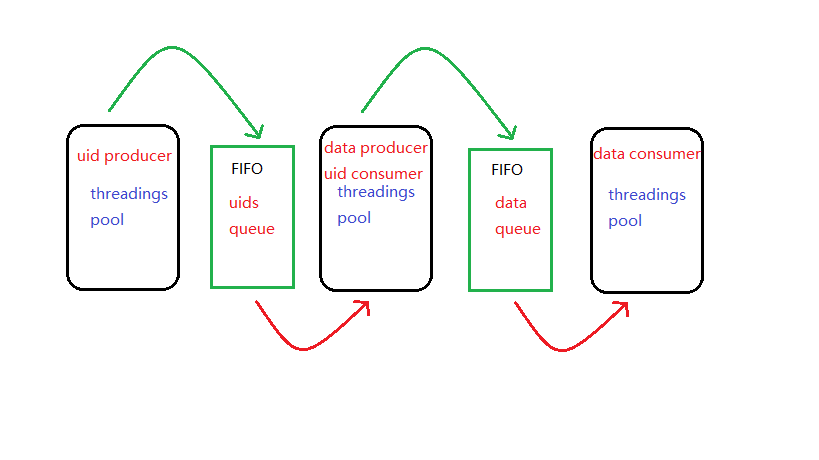
对于这个结构,第一个线程池里是生产 uid的线程,这些线程把生产出来的线程放入 uids queue队列中。
第二个线程池里的线程就通过 uids queue来获取 uid,他们就是 uid producer的消费者。
同时,他们也是 data的生产者。
第二个线程池与第三个线程池的交互和前面两个线程池的交互类似,如下图:

中间的 uids queue是一个先入先出而且线程安全的队列。
使用生产—消费者模型后,我们还需要的就是一个线程安全的 FIFO队列,和恰当的生产者与消费者比例(以生产者的产出刚好被消费者消费完为最佳)
二、代码实现
首先我们先把原来的模块封装到一个单独的文件里去,这样更加方便调用
文件 GitHub:jianshu_models.py
文件里面我们需要用到的有:
- simplifiedCsv 类,将数据写入文件
- userUidsGenerator userUid生成器
- getArticleInfo 获取文章信息
然后就是我们的生产者和消费者类:
这里我们使用 python自带的 queue模块里的 Queue队列
Queue队列有 put和 get两个方法,这两个方法都接受一个整数作为最大队列长度。
当队列长度达到最大队列长度时,put方法就会阻塞,直到队列长度再次小于最大队列长度。
按从左到右的顺序,第一个类是 uid生产线程类:
class UidGenerateThread(threading.Thread):
def __init__(self, uid_queue):
threading.Thread.__init__(self)
self.uid_queue = uid_queue
def run(self):
start_users = [{'uid': 'a3ea268aeb60', 'follow_num': 525, 'fans_num': 2521, 'article_num': 118}]
user_generator = jianshu_models.userUidsGenerator(start_users)
while True:
user = user_generator.__next__()
self.uid_queue.put(user)
UidGenerateThread类接受一个 uid_queue队列作为初始化参数。
在 run方法中,我们先获取一个 uid生成器,然后无限调用生成器的 __next__()方法,并将获得的结果通过 uid_queue的 put方法放到 uid_queue队列里去。
第二个类是,uid消费者类同时也是 data生产者类:
class DataCollectorThread(threading.Thread):
def __init__(self, uid_queue, data_queue):
threading.Thread.__init__(self)
self.uid_queue = uid_queue
self.data_queue = data_queue
def run(self):
while True:
user = self.uid_queue.get()
datas = jianshu_models.getArticleInfo(user)
self.data_queue.put(datas)
DataCollectorThread类接受两个队列 uid_queue和 data_queue作为初始化参数。
run方法里,我们先通过 uid_queue的 get方法获取 userUid,然后把返回结果作为参数传递给 getArticleInfo来获取对应用户的文章信息。
获取到文章信息后,我们再把文章信息放到 data_queue里
第三个类是 data消费者类,作用是将 data写入 csv文件:
class DataWriterThread(threading.Thread):
def __init__(self, data_queue):
threading.Thread.__init__(self)
self.data_queue = data_queue
self.writer = jianshu_models.simplifiedCsv(f'test/{self.name}.txt')
def run(self):
while True:
data_list = self.data_queue.get()
self.writer.writerows(data_list)
与上面两个类相似,DataWriterThread类也接受一个 data_queue作为初始化参数。
在 run方法中不断从 adta_queue里取出数据写入到文件里。
这里为了避免使用资源锁,我们让每个线程都有一个 simplifiedCsv类,将数据写入不同的文件中。
当爬取完成后再将数据整合到一个文件中去。
根据不同线程的生产和消费能力,在程序中我们使用 1个 uid生产线程(而且只能使用一个),10个DataCollectorThread和 10个DataWriterThread。
并且设置 uid_queue的长度为 100,data_queue的长度为 50.
threads = []
uid_queue = queue.Queue(100)
data_queue = queue.Queue(50)
t1 = UidGenerateThread(uid_queue)
threads.append(t1)
for i in range(10):
t1 = DataWriterThread(data_queue)
t2 = DataCollectorThread(uid_queue, data_queue)
threads.append(t1)
threads.append(t2)
for t in threads:
t.start()
for t in threads:
t.join()
运行十分钟看看:
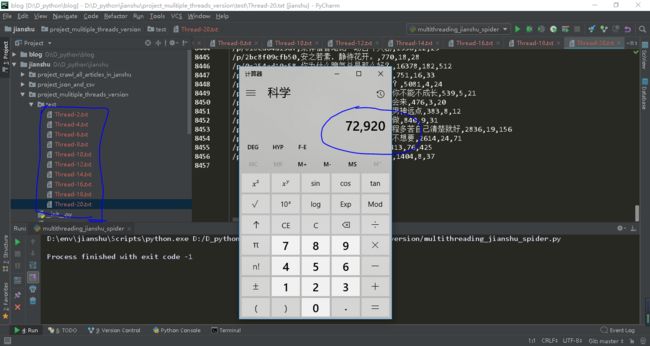
十分钟爬取了 72920条数据,再看看单线程的:
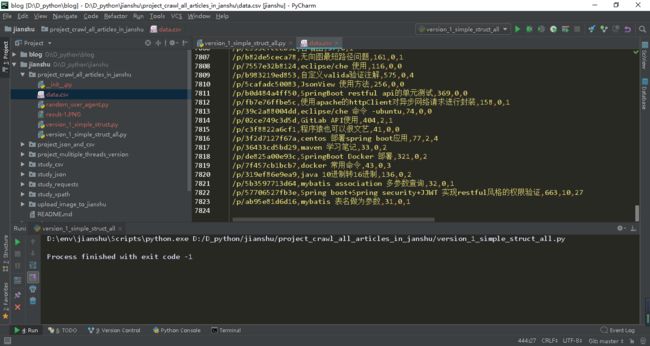
单线程十分钟爬取了 7823条。
多线程是单线程的 9倍多一点,不过如果我们增加 DataCollectorThread和
DataWriterThread的数量,速度还可以更快。
当 cpu的利用率达到 80%时可以达到 30倍的速度。
这次代码版本为:v2.0
代码在 GitHub上的链接:project_mulitiple_threads_version
大家可能觉得现在已经很快了,但这还不是最快的方式,比多线程更快更节省资源的是------>协程,也被称作异步
下一篇就让我们来讲一讲异步
觉得我写的不错的话,记得关注、点赞、评论(。・∀・)ノ
上一篇:实战:爬取简书之多线程爬取(一)