2019独角兽企业重金招聘Python工程师标准>>> 
【一】本文内容综述
1. keras使用流程分析(模型搭建、模型保存、模型加载、模型使用、训练过程可视化、模型可视化等)
2. 利用keras做文本数据预处理
【二】环境准备
1. 数据集下载:http://ai.stanford.edu/~amaas/data/sentiment/
2.安装Graphviz ,keras进行模型可视化时,会用到该组件: https://graphviz.gitlab.io/_pages/Download/Download_windows.html
【三】数据预处理
将imdb压缩包解压后,进行数据预处理。
1. 将每条影评中的部分词去掉
2. 将影评与label对应起来
3. 将影评映射为int id,同时将每条影评的长度固定,好作为定长输入数据
# -*- coding:utf-8 -*-
import keras
import os
import numpy as np
import re
from keras.preprocessing import text
from keras.preprocessing import sequence
from keras.utils import plot_model
import matplotlib.pyplot as plt
Reg = re.compile(r'[A-Za-z]*')
stop_words = ['is','the','a']
max_features = 5000
word_embedding_size = 50
maxlen = 400
filters = 250
kernel_size = 3
hidden_dims = 250
def prepross(file):
with open(file,encoding='utf-8') as f:
data = f.readlines()
data = Reg.findall(data[0])
# 将句子中的每个单词转化为小写
data = [x.lower() for x in data]
# 将句子中的部分词从停用词表中剔除
data = [x for x in data if x!='' and x not in stop_words]
# 返回值必须是个句子,不能是单词列表
return ' '.join(data)
def imdb_load(type):
root_path = "E:/nlp_data/aclImdb_v1/aclImdb/"
# 遍历所有文件
file_lists = []
pos_path = root_path + type + "/pos/"
for f in os.listdir(pos_path):
file_lists.append(pos_path + f)
neg_path = root_path + type + "/neg/"
for f in os.listdir(neg_path):
file_lists.append(neg_path + f)
# file_lists中前12500个为pos,后面为neg,labels与其保持一致
labels = [1 for i in range(12500)]
labels.extend([0 for i in range(12500)])
# 将文件随机打乱,注意file与label打乱后依旧要通过下标一一对应。
# 否则会导致 file与label不一致
index = np.arange(len(labels))
np.random.shuffle(index)
# 转化为numpy格式
labels = np.array(labels)
file_lists = np.array(file_lists)
labels[index]
file_lists[index]
# 逐个处理文件
sentenses = []
for file in file_lists:
#print(file)
sentenses.append(prepross(file))
return sentenses,labels
def imdb_load_data():
x_train,y_train = imdb_load("train")
x_test,y_test = imdb_load("test")
# 建立单词和数字映射的词典
token = text.Tokenizer(num_words=max_features)
token.fit_on_texts(x_train)
# 将影评映射到数字
x_train = token.texts_to_sequences(x_train)
x_test = token.texts_to_sequences(x_test)
# 让所有影评保持固定长度的词数目
x_train = sequence.pad_sequences(x_train,maxlen=maxlen)
x_test = sequence.pad_sequences(x_test,maxlen=maxlen)
return (x_train,y_train),(x_test,y_test)【四】模型搭建与训练
def train():
(x_train, y_train), (x_test, y_test) = imdb_load_data()
model = keras.Sequential()
# 构造词嵌入层
model.add(keras.layers.Embedding(input_dim=max_features,output_dim=word_embedding_size,name="embedding"))
# 通过layer名字获取layer的信息
print(model.get_layer(name="embedding").input_shape)
# 基于词向量的堆叠方式做卷积
model.add(keras.layers.Conv1D(filters=filters,kernel_size=kernel_size,strides=1
,activation=keras.activations.relu,name="conv1d"))
# 对每一个卷积出的特征向量做最大池化
model.add(keras.layers.GlobalAvgPool1D(name="maxpool1d"))
# fc,输入是250维,输出是hidden_dims
model.add(keras.layers.Dense(units=hidden_dims,name="dense1"))
# 添加激活层
model.add(keras.layers.Activation(activation=keras.activations.relu,name="relu1"))
# fc,二分类问题,输出维度为1
model.add(keras.layers.Dense(units=1,name="dense2"))
# 二分类问题,使用sigmod函数做分类器
model.add(keras.layers.Activation(activation=keras.activations.sigmoid,name="sigmoe"))
# 打印模型各层layer信息
model.summary()
# 模型编译,配置loss,optimization
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.binary_crossentropy,
metrics=['accuracy'])
# 模型训练
'''
# 如果想保存每一个batch的loss等数据,需要传递一个callback
history = LossHistory()
train_history = model.fit(x=x_train,
y=y_train,
batch_size=128,
epochs=1,
validation_data=(x_test,y_test),
callbacks=[history])
show_train_history2(history)
# 结果可视化
'''
# fit 返回的log中,有 epochs 组数据,即只保存每个epoch的最后一次的loss等值
train_history = model.fit(x=x_train,
y=y_train,
batch_size=128,
epochs=1,
validation_data=(x_test,y_test))
show_train_history(train_history)
# 模型保存
model.save(filepath="./models/demo_imdb_rnn.h5")
# 模型保存一份图片
plot_model(model=model,to_file="./models/demo_imdb_rnn.png",
show_layer_names=True,show_shapes=True)
【五】模型训练过程中loss的曲线绘制
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
def on_batch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
def show_train_history2(history):
plt.plot(history.losses)
plt.title("model losses")
plt.xlabel('batch')
plt.ylabel('losses')
plt.legend()
# 先保存图片,后显示,不然保存的图片是空白
plt.savefig("./models/demo_imdb_rnn_train.png")
plt.show()
def show_train_history(train_history):
print(train_history.history.keys())
print(train_history.epoch)
plt.plot(train_history.history['acc'])
plt.plot(train_history.history['val_acc'])
plt.title("model accuracy")
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.legend()
plt.show()
plt.plot(train_history.history['loss'])
plt.plot(train_history.history['val_loss'])
plt.title("model loss")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()【六】基于训练好的模型做预测
def gen_predict_data(path):
sent = prepross(path)
x_train,t_train = imdb_load("train")
token = text.Tokenizer(num_words=max_features)
token.fit_on_texts(x_train)
x = token.texts_to_sequences([sent])
x = sequence.pad_sequences(x,maxlen=maxlen)
return x
RESULT = {1:'pos',0:'neg'}
def predict(path):
x = gen_predict_data(path)
model = keras.models.load_model("./models/demo_imdb_rnn.h5")
y = model.predict(x)
print(y)
y= model.predict_classes(x)
print(y)
print(RESULT[y[0][0]])
predict(r"E:\nlp_data\aclImdb_v1\aclImdb\test\neg\0_2.txt")
predict(r"E:\nlp_data\aclImdb_v1\aclImdb\test\pos\0_10.txt")预测结果如下:
[[0.16223338]]
[[0]]
neg
[[0.8812848]]
[[1]]
pos【七】整体代码如下
# -*- coding:utf-8 -*-
import keras
import os
import numpy as np
import re
from keras.preprocessing import text
from keras.preprocessing import sequence
from keras.utils import plot_model
import matplotlib.pyplot as plt
Reg = re.compile(r'[A-Za-z]*')
stop_words = ['is','the','a']
max_features = 5000
word_embedding_size = 50
maxlen = 400
filters = 250
kernel_size = 3
hidden_dims = 250
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
def on_batch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
def prepross(file):
with open(file,encoding='utf-8') as f:
data = f.readlines()
data = Reg.findall(data[0])
# 将句子中的每个单词转化为小写
data = [x.lower() for x in data]
# 将句子中的部分词从停用词表中剔除
data = [x for x in data if x!='' and x not in stop_words]
# 返回值必须是个句子,不能是单词列表
return ' '.join(data)
def imdb_load(type):
root_path = "E:/nlp_data/aclImdb_v1/aclImdb/"
# 遍历所有文件
file_lists = []
pos_path = root_path + type + "/pos/"
for f in os.listdir(pos_path):
file_lists.append(pos_path + f)
neg_path = root_path + type + "/neg/"
for f in os.listdir(neg_path):
file_lists.append(neg_path + f)
# file_lists中前12500个为pos,后面为neg,labels与其保持一致
labels = [1 for i in range(12500)]
labels.extend([0 for i in range(12500)])
# 将文件随机打乱,注意file与label打乱后依旧要通过下标一一对应。
# 否则会导致 file与label不一致
index = np.arange(len(labels))
np.random.shuffle(index)
# 转化为numpy格式
labels = np.array(labels)
file_lists = np.array(file_lists)
labels[index]
file_lists[index]
# 逐个处理文件
sentenses = []
for file in file_lists:
#print(file)
sentenses.append(prepross(file))
return sentenses,labels
def imdb_load_data():
x_train,y_train = imdb_load("train")
x_test,y_test = imdb_load("test")
# 建立单词和数字映射的词典
token = text.Tokenizer(num_words=max_features)
token.fit_on_texts(x_train)
# 将影评映射到数字
x_train = token.texts_to_sequences(x_train)
x_test = token.texts_to_sequences(x_test)
# 让所有影评保持固定长度的词数目
x_train = sequence.pad_sequences(x_train,maxlen=maxlen)
x_test = sequence.pad_sequences(x_test,maxlen=maxlen)
return (x_train,y_train),(x_test,y_test)
def train():
(x_train, y_train), (x_test, y_test) = imdb_load_data()
model = keras.Sequential()
# 构造词嵌入层
model.add(keras.layers.Embedding(input_dim=max_features,output_dim=word_embedding_size,name="embedding"))
# 通过layer名字获取layer的信息
print(model.get_layer(name="embedding").input_shape)
# 基于词向量的堆叠方式做卷积
model.add(keras.layers.Conv1D(filters=filters,kernel_size=kernel_size,strides=1
,activation=keras.activations.relu,name="conv1d"))
# 对每一个卷积出的特征向量做最大池化
model.add(keras.layers.GlobalAvgPool1D(name="maxpool1d"))
# fc,输入是250维,输出是hidden_dims
model.add(keras.layers.Dense(units=hidden_dims,name="dense1"))
# 添加激活层
model.add(keras.layers.Activation(activation=keras.activations.relu,name="relu1"))
# fc,二分类问题,输出维度为1
model.add(keras.layers.Dense(units=1,name="dense2"))
# 二分类问题,使用sigmod函数做分类器
model.add(keras.layers.Activation(activation=keras.activations.sigmoid,name="sigmoe"))
# 打印模型各层layer信息
model.summary()
# 模型编译,配置loss,optimization
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.binary_crossentropy,
metrics=['accuracy'])
# 模型训练
'''
# 如果想保存每一个batch的loss等数据,需要传递一个callback
history = LossHistory()
train_history = model.fit(x=x_train,
y=y_train,
batch_size=128,
epochs=1,
validation_data=(x_test,y_test),
callbacks=[history])
show_train_history2(history)
# 结果可视化
'''
# fit 返回的log中,有 epochs 组数据,即只保存每个epoch的最后一次的loss等值
train_history = model.fit(x=x_train,
y=y_train,
batch_size=128,
epochs=10,
validation_data=(x_test,y_test))
show_train_history(train_history)
# 模型保存
model.save(filepath="./models/demo_imdb_rnn.h5")
# 模型保存一份图片
plot_model(model=model,to_file="./models/demo_imdb_rnn.png",
show_layer_names=True,show_shapes=True)
def show_train_history2(history):
plt.plot(history.losses)
plt.title("model losses")
plt.xlabel('batch')
plt.ylabel('losses')
plt.legend()
# 先保存图片,后显示,不然保存的图片是空白
plt.savefig("./models/demo_imdb_rnn_train.png")
plt.show()
def show_train_history(train_history):
print(train_history.history.keys())
print(train_history.epoch)
plt.plot(train_history.history['acc'])
plt.plot(train_history.history['val_acc'])
plt.title("model accuracy")
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.legend()
plt.show()
plt.plot(train_history.history['loss'])
plt.plot(train_history.history['val_loss'])
plt.title("model loss")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()
def gen_predict_data(path):
sent = prepross(path)
x_train,t_train = imdb_load("train")
token = text.Tokenizer(num_words=max_features)
token.fit_on_texts(x_train)
x = token.texts_to_sequences([sent])
x = sequence.pad_sequences(x,maxlen=maxlen)
return x
RESULT = {1:'pos',0:'neg'}
def predict(path):
x = gen_predict_data(path)
model = keras.models.load_model("./models/demo_imdb_rnn.h5")
y = model.predict(x)
print(y)
y= model.predict_classes(x)
print(y)
print(RESULT[y[0][0]])
#train()
predict(r"E:\nlp_data\aclImdb_v1\aclImdb\test\neg\0_2.txt")
predict(r"E:\nlp_data\aclImdb_v1\aclImdb\test\pos\0_10.txt")
【八】结果对比与分析
本文主要参考keras example示例(https://github.com/keras-team/keras/blob/master/examples/imdb_cnn.py),该示例的imdb数据已经预处理好了。所以尝试重新对数据进行预处理,和keras示例相比,精度基本一致。
keras模型png图片如下:
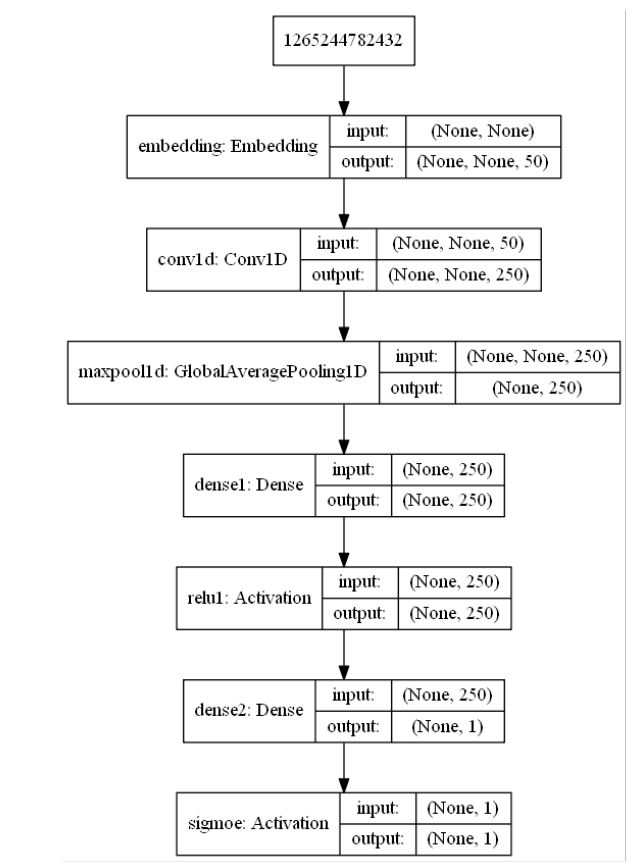
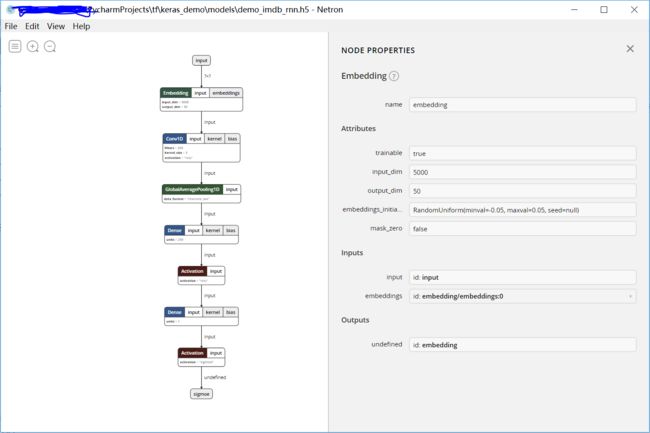
也可以使用工具Netron(https://github.com/lutzroeder/Netron)打开keras保存的.h5格式的模型
Netron是个可视化模型的神器,可以可视化caffe/tensorflow/keras等模型
【九】可视化
上面提到了三种可视化,一是利用callback回调,记录单个epoch下逐个batch的loss等数据,然后绘制曲线图,或者利用history绘制多个epoch下的loss等变化曲线图,二是将模型保存为图片,三是利用Netron查看.h5模型。现在介绍第四种可视化方式,即 利用tensorboard来显示训练过程与模型参数
使用方式比较简单,给fit函数传递一个keras.callbacks.TensorBoard 作为callback对象即可。
tensorboard = keras.callbacks.TensorBoard(log_dir="./logs/")
train_history = model.fit(x=x_train,
y=y_train,
batch_size=128,
epochs=1,
validation_data=(x_test,y_test),
callbacks=[tensorboard])
启动tensorboard(tensorboard --logdir=./logs/)之后,然后在浏览器输入:http://localhost:6006 ,即可看到各种信息
【十】关于其中的Embedding层
前面介绍过,可以使用word2vec或者fasttext或者gensim训练出词向量,而这里的Embedding好像也没有使用训练好的词向量啊?原因是这里的embedding也是参与训练的,他是整个流程的一部分。所以,embedding的参数解释如下:
# 构造词嵌入层
# input_dim ----> 词典的最大词数目,即V
# output_dim ---->词向量的维度大小,即m
# input_length---->数据数据x的大小,即句子长度。也就是一个句子有多少个词。由于句子长度不一,这也是前面为什么需要
# 将句子截断或者填充
model.add(keras.layers.Embedding(input_dim=max_features,output_dim=word_embedding_size,name="embedding"))
那如果需要使用fasttext训练好的词向量,怎么办呢?其实这个好办,也就是一个fine-tuning的过程,不过针对上述网络而言,仅仅对embedding层进行fine-tuning。
分为如下三个步骤:
1. 获取预训练的词向量,将其解析出来,可以解析到一个map或者dict中,其中key=token,value=word vector。 V*M
2. 将训练的语料(如imdb)预处理后,通过查表方式,从上述map中得到对应词的向量,然后得到当前语料库的词向量(V1*M)。注意,这里词向量的size依旧为M,只是词典的大小换成了V1。如果当前语料库中的某个词不再预训练的词典中,则可以将该词的词向量随机初始化。
3. 将当前语料库的word embedding,填充到Embeeding layer的参数中。
代码如下:
这里以斯坦福大学通过glove训练好的word embedding为例
下载网址:https://nlp.stanford.edu/projects/glove/
# 初始化词典
embedding_matrix = np.zeros(shape=(V,m))
word_index = {}
embedding_index = {}
# 选择m=50的预训练数据,将预训练的词与vector提取到embedding_index中存储起来
with open("glove.6B.50d.txt") as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:],dtype=np.float32)
embedding_index[word] = coefs
'''
x_train,t_train = imdb_load("train")
token = text.Tokenizer(num_words=max_features)
token.fit_on_texts(x_train)
'''
# 获取当前语料(imdb)的词
word_index = token.word_index
not_find = 0
for word,i in word_index.items():
if i < V:
# 查预训练的词表
embedding_vec = embedding_index.get(word)
if embedding_vec is not None:
embedding_matrix[i] = embedding_vec
else:
not_find += 1
# 将权值设置到embedding layer中
model.layers[0].set_weigth([embedding_matrix])
# frozen embedding layer,也可以不冻结。不冻结的话就可以fine-tuning该层
model.layers[0].trainable = False