python—树模型部署加速工具Treelite(支持XGBoost、LightGBM和Sklearn)
文章目录
-
-
- 引言
- 一、Treelite原理
-
- 1.逻辑分支
- 2.逻辑比较
- 三、Treelite使用
-
- 1. XGBoost模型
- 2.LightGBM
- 3.随机森林
- 总结
-
引言
Treelite能够将树模型编译优化为单独库,可以很方便的用于模型部署。经过优化后可以将XGBoost模型的预测速度提高2-6倍。
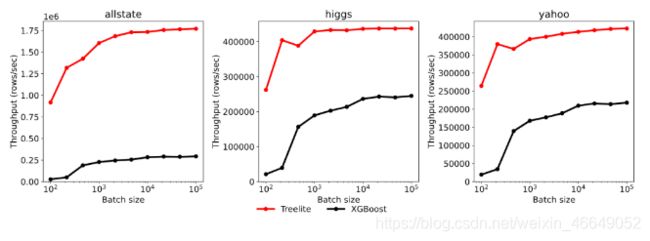
如上图,黑色曲线为XGBoost在不同batch size下的吞吐量,红色曲线为XGBoost经过TreeLite编译后的吞吐量。
Treelite支持众多的树模型,特别是随机森林和GBDT。同时Treelite可以很好的支持XGBoost, LightGBM和 scikit-learn,也可以将自定义模型根据要求完成编译。
一、Treelite原理
Treelite主要在两方面完成了改进
1.逻辑分支
对于树模型而言,节点的分类本质使用if语句完成,而CPU在执行if语句时会等待条件逻辑的计算。
if ( [conditional expression] ) {
foo();
} else {
bar();
}
如果在构建树模型时候,提前计算好每个分支下面样本的个数,则可以提前预知哪一个叶子节点被执行的可能性更大,进而可以提前执行子节点逻辑。

借助于编译命令,可以完成逻辑计算加速。
/* expected to be false */
if( __builtin_expect([condition],0)){
...
} else {
...
}
2.逻辑比较
原始的分支比较可能会有浮点数比较逻辑,可以量化为数值比较逻辑。
if (data[3].fvalue < 1.5) {
/* floating-point comparison */
...
}
if (data[3].qvalue < 3) {
/* integer comparison */
...
}
三、Treelite使用
Treelite模型打包后,加载和之后的预测代码一样,也就说所有树模型在TreeLite打包后之后的语法都是一样的。
1. XGBoost模型
import time
import numpy as np
from sklearn.datasets import make_classification
import treelite
import xgboost as xgb
import treelite_runtime
# 自定义数据集
X,y = make_classification(n_samples=10000,n_features=1000)
# XGBoost模型训练
dtrain = xgb.DMatrix(X,label=y)
params = {
'max_depth':3, 'eta':1, 'objective':'reg:squarederror', 'eval_metric':'rmse'}
bst = xgb.train(params, dtrain, num_boost_round=20, evals=[(dtrain, 'train')])
# XGBoost模型打包
model = treelite.Model.from_xgboost(bst)
toolchain = 'gcc' # change this value as necessary
model.export_lib(toolchain=toolchain, libpath='./mymodel.so',verbose=True)
# Treelite模型加载
predictor = treelite_runtime.Predictor('./mymodel.so', verbose=True)
# XGBoost不同Batch大小预测速度对比
nrows = [1000, 10000, 100000, 200000]
xgb_time = []
tree_lite = []
for nrow in nrows:
data = np.random.random((nrow, 1000))
dtrain = xgb.DMatrix(data)
start = time.time()
_ = bst.predict(dtrain)
xgb_time.append(time.time() - start)
batch = treelite_runtime.Batch.from_npy2d(data)
start = time.time()
_ = predictor.predict(batch)
tree_lite.append(time.time() - start)

2.LightGBM
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: 1.py
@time: 2021/01/26
@desc:
"""
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: TreeLite.py
@time: 2021/01/26
@desc:
"""
import time
import numpy as np
from sklearn.datasets import make_classification
import treelite
import lightgbm as lgb
import treelite_runtime
# 自定义数据集
X,y = make_classification(n_samples=10000,n_features=1000)
# XGBoost模型训练
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'max_depth':3,
'metric': 'binary_logloss',
'bagging_freq': 5,
'verbose': 0
}
lgb_train = lgb.Dataset(X, y)
gbm = lgb.train(params,
lgb_train,
num_boost_round=10)
gbm.save_model('model.txt')
# XGBoost模型打包
model = treelite.Model.load('model.txt', model_format='lightgbm')
toolchain = 'gcc' # change this value as necessary
model.export_lib(toolchain=toolchain, libpath='./mymodel.so', verbose=True)
# Treelite模型加载
predictor = treelite_runtime.Predictor('./mymodel.so', verbose=True)
# XGBoost不同Batch大小预测速度对比
nrows = [1000, 10000, 100000, 200000]
lgb_time = []
tree_lite = []
for nrow in nrows:
data = np.random.random((nrow, 1000))
dtrain = lgb.Dataset(data)
start = time.time()
_ = lgb.predict(dtrain)
lgb_time.append(time.time() - start)
batch = treelite_runtime.Batch.from_npy2d(data)
start = time.time()
_ = predictor.predict(batch)
tree_lite.append(time.time() - start)
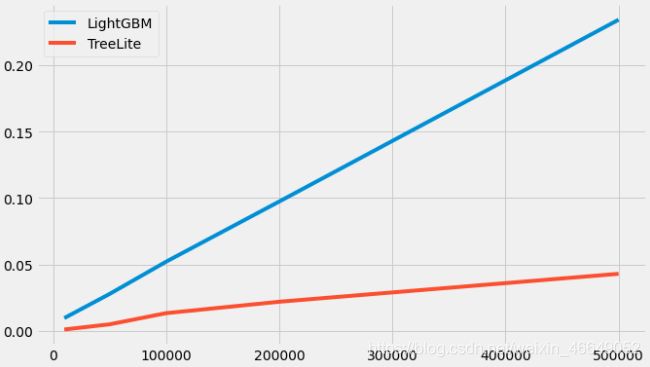
3.随机森林
import time
import numpy as np
from sklearn.datasets import make_classification
import treelite
from sklearn.ensemble import RandomForestClassifier
import treelite_runtime
# 自定义数据集
X,y = make_classification(n_samples=10000,n_features=1000)
# XGBoost模型训练
rf = RandomForestClassifier(n_estimators=1).fit(X, y)
# XGBoost模型打包
model = treelite.sklearn.import_model(rf)
toolchain = 'gcc' # change this value as necessary
model.export_lib(toolchain=toolchain, libpath='./mymodel.so', verbose=True)
# Treelite模型加载
predictor = treelite_runtime.Predictor('./mymodel.so', verbose=True)
# XGBoost不同Batch大小预测速度对比
nrows = [1000, 10000, 100000, 200000]
rf_time = []
tree_lite = []
for nrow in nrows:
data = np.random.random((nrow, 1000))
start = time.time()
_ = rf.predict(data)
rf_time.append(time.time() - start)
batch = treelite_runtime.Batch.from_npy2d(data)
start = time.time()
_ = predictor.predict(batch)
tree_lite.append(time.time() - start)

总结
- Treelite是不错的树模型加速部署工具;
- Treelite支持将模型部署为.so文件,方便其他语言调用,也可以避免模型参数泄露;