Python数据预处理之异常值的处理——【自定义的three_sigma()函数、boxplot()方法】
文章目录
- 基于3σ原则检测异常值
-
- 代码实现
- 测试
- 基于箱型图检测异常值
- 异常值的处理
基于3σ原则检测异常值
3σ原则,又称拉依达准则。是指假设一组检测数据只含有随机误差。对其进行计算处理得到标准偏差,按一定概率确定一个区间,凡是超过这个区间的误差都是粗大误差,在此误差范围内的数据应予以剔除。
正态分布概率公式中,σ表示标准差,μ表示平均数,f(x)表示正态分布函数。
正态分布公式
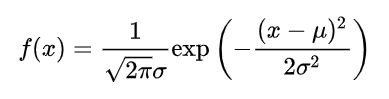
正态曲线下,
横轴区间(μ-σ,μ+σ)内的面积为68.268949%。
P{|X-μ|<σ}=2Φ(1)-1=0.6826
横轴区间(μ-2σ,μ+2σ)内的面积为95.449974%。
P{|X-μ|<2σ}=2Φ(2)-1=0.9544
横轴区间(μ-3σ,μ+3σ)内的面积99.730020%。
P{|X-μ|<3σ}=2Φ(3)-1=0.9974
由于“小概率事件”和假设检验的基本思想 “小概率事件”通常指发生的概率小于5%的事件,认为在一次试验中该事件是几乎不可能发生的。
由上可知,X落在(μ-3σ,μ+3σ)以外的概率小于千分之三,在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,超过这个区间的就属于异常值,应予以剔除。
代码实现
import numpy as np
import pandas as pd
def three_sigma(ser1): # ser1表示传入DataFrame的某一列
mean_value = ser1.mean() # 求平均值
std_value = ser1.std() # 求标准差
rule = (mean_value - 3 * std_value > ser1) | (ser1.mean() + 3 * ser1.std() < ser1)
# 位于(u-3std,u+3std)区间的数据是正常的,不在这个区间的数据为异常的
# 一旦发现有异常值,就标注为True,否则标注为False
index = np.arange(ser1.shape[0])[rule] # 返回异常值的位置索引
outrange = ser1.iloc[index] # 获取异常数据
return outrange
测试
将符合正态分布的包含异常值的测试数据保存在D:\数据分析\data.xlsx中。使用Pandas的read_excel()函数从文件中读取数据,并转换为DataFrame对象。之后分别对data中的A列数据和B列数据进行检测。
data = pd.read_excel(r'D:\数据分析\data.xlsx')
print(data)
print(three_sigma(data['A']))
print(three_sigma(data['B']))
输出结果:
Unnamed: 0 A B
0 0 1 2
1 1 2 3
2 2 3 8
3 3 4 5
4 4 5 6
5 5 560 7
6 6 2 8
7 7 3 9
8 8 4 0
9 9 5 3
10 10 3 4
11 11 2 5
12 12 4 6
13 13 5 7
14 14 5 2
15 15 23 4
16 16 2 5
5 560
Name: A, dtype: int64
Series([], Name: B, dtype: int64)
基于箱型图检测异常值
箱型图是一种用作显示一组数据分散情况的统计图。在箱型图中,异常值通常被定义为小于QL-1.5QR或大于QU+1.5IQR的值。其中:
QL:下四分位数,表示全部观察值中有四分之一的数据取值比它大。
QU:上四分位数,表示全部观察值中有四分之一的数据取值比它小。
IQR:四分位数间距,是QU与QL之差,其间包含了全部观察值的一半。
箱型图是根据实际数据进行绘制,对数据没有任何要求(3σ原则要求数据服从正态分布或近似正态分布)。箱型图判断异常值的标准是以四分位数和四分位距为基础的。
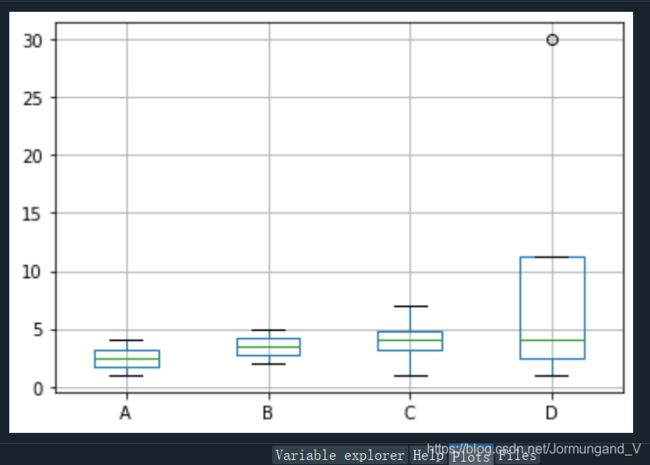
Pandas中提供了一个专门用来绘制箱型图的boxplot()方法。
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [2, 3, 4, 5],
'C': [1, 4, 7, 4],
'D': [1, 5, 30, 3]})
print(df.boxplot(column=['A', 'B', 'C', 'D']))
输出结果:
异常值的处理
检测出异常值后,通常会才用如下四种方式处理这些异常值:
1、直接将含有异常值的记录删除
2、用具体的值来进行替换,可用前后两个观测值的平均值修正该异常值
3、不处理,直接在具有异常值的数据集上进行统计分析
4、视为缺失值,利用缺失值的处理方法修正该异常值
异常数据被检测出来之后,需要进一步确认他们是否为真正的异常值,等确认完以后再决定选用哪种方法进行解决。
如果希望对异常值进行修改(执行操作2),则可以使用Pandas中replace()方法进行替换,该方法不仅可以对单个数据进行替换,也可以多个数据执行批量替换操作。
replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method=‘pad’)
部分参数:
to_replace:表示查找被替换值的方式
value:用来替换任何匹配to_replace的值,默认值为None
limit:表示前向或后向填充的最大尺寸间隙
regex:接收布尔值或与to_replace相同的类型,默认为False,表示是否将to_replace和value解释为正则表达式
method:替换时使用的方法,pad/ffill表示前向填充,bfill表示后向填充
replace()方法的使用
print(df.replace(to_replace=30, value=3))
print(data.replace(to_replace=data.loc[5, ['A']], value=6))
输出结果:
AxesSubplot(0.125,0.11;0.775x0.77)
A B C D
0 1 2 1 1
1 2 3 4 5
2 3 4 7 3
3 4 5 4 3
Unnamed: 0 A B
0 0 1 2
1 1 2 3
2 2 3 8
3 3 4 5
4 4 5 6
5 5 6 7
6 6 2 8
7 7 3 9
8 8 4 0
9 9 5 3
10 10 3 4
11 11 2 5
12 12 4 6
13 13 5 7
14 14 5 2
15 15 23 4
16 16 2 5