猫狗大战——pytorch+resnet18
cats vs dogs——resnet18
- 数据
- Net
- train+test
数据
这是一个在kaggle上的竞赛,原数据提供了25000张图片,本文所使用的数据集来自其中train的8000张,包括4000张猫和4000张狗
#将数据导入
data_dir = 'E:\\code\\Python\\catanddog\\train'
test_dir = 'E:\\code\\Python\\catanddog\\test'
class Data(data.Dataset):
def __init__(self, path, transform = None, train = True, test = False):
self.test = test
self.train = train
self.transform = transform
#imgs = [os.path.join(path, img) for img in os.listdir(path)]
imgs = [os.path.join(data_dir, img) for img in path]#imgs存的是每张图片的总路径
if self.test:#test模式
self.imgs = imgs
else:#train模式
random.shuffle(imgs)#数据打乱
self.imgs = imgs
def __getitem__(self, index):
img = self.imgs[index]
if self.test:
label = 2
else:
label = 0 if 'cat' in img.split('\\')[-1] else 1#cat = 0, dog = 1
image = Image.open(img)
image = self.transform(image)
return image, label
def __len__(self):
return len(self.imgs)
#train和val的transform处理
#对train进行了随机裁剪翻转的操作
transform_train = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2225))
])
transform_val = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_dirs, valid_dirs = train_test_split(os.listdir(data_dir), test_size = 0.2, random_state = 2021)
trainset = Data(train_dirs, transform = transform_train)
valset = Data(valid_dirs, transform = transform_val)
trainloader = torch.utils.data.DataLoader(trainset, batch_size = 20, shuffle = True, num_workers = 0)
valloader = torch.utils.data.DataLoader(valset, batch_size = 20, shuffle = False, num_workers = 0)
Net
model = resnet18(pretrained=True)
model.fc = nn.Linear(512, 2,bias=True)
model = model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=5e-4) # 设置训练细节
scheduler = StepLR(optimizer, step_size=3)
criterion = nn.CrossEntropyLoss()
train+test
#训练并保存模型
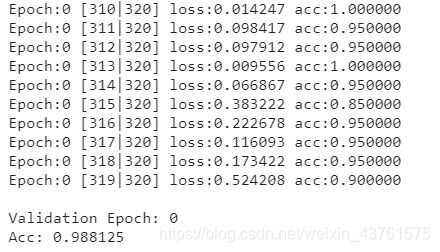
for epoch in range(1):
train(epoch)
val(epoch)
torch.save(model, 'catvsdog_model.pth') # 保存模型
#一次epoch在验证集上准确度有0.988
#对图片进行预测
classes = ['cat', 'dog']
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('catvsdog_model.pth') # 加载模型
model = model.to(device)
model.eval() # 把模型转为test模式
img = cv2.imread("E:\\code\\Python\\catanddog\\test\\dog.3886.jpg") # 读取要预测的图片
cv2.imshow("img", img)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
trans = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) # 图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
output = model(img)
prob = F.softmax(output, dim=1) # prob是2个分类的概率
value, predicted = torch.max(output.data, 1)
pred_class = classes[predicted.item()]
print(pred_class)