覆盖率验证——代码覆盖率+功能覆盖率
文章目录
- 一、基于覆盖率驱动的验证技术
- 二、代码覆盖率与功能覆盖率
- 三、功能覆盖率建模
-
- 3.1.覆盖组——covergroup
- 3.2.覆盖点——coverpoint
- 3.3.覆盖点元素——隐式bin与显式bins
- 3.4.覆盖点之间的交叉覆盖率——cross
- 3.5.覆盖点之间的状态跳转
- 3.6.覆盖率的选项与方法
- 四、代码code——约束与覆盖率的运用
-
- 4.1.通过修改随机化次数——提高覆盖率(覆盖点变量取值范围小)
- 4.2.通过添加约束constraint、自定义bins——提高覆盖率(覆盖点变量取值范围大)
- 4.3.通过权重dist——调整hit次数分布
一、基于覆盖率驱动的验证技术
采用覆盖率驱动的验证方式可以量化验证进度,保证验证的完备性。一般在验证计划中会指定具体的覆盖率目标。通过覆盖率验证可以确定验证是否达到要求。当然,达到目标覆盖率并不意味着验证就通过了,因为功能覆盖率是由人为定义的,有时候即便达到100%,也未必将所有的功能场景全部覆盖了,因为人为主观定义的功能场景有时候可能存在遗漏,所以还需要对测试用例进行迭代。
二、代码覆盖率与功能覆盖率
- 代码覆盖率:
工具会自动搜集已经编写好的代码,常见的代码覆盖率如下:
- 行覆盖率(line coverage):记录程序的各行代码被执行的情况。
- 条件覆盖率(condition coverage):记录各个条件中的逻辑操作数被覆盖的情况。
- 跳转覆盖率(toggle coverage):记录单bit信号变量的值为0/1跳转情况,如从0到1,或者从1到0的跳转。
- 分支覆盖率(branch coverage):又称路径覆盖率(path coverage),指在if,case,for,forever,while等语句中各个分支的执行情况。
- 状态机覆盖率(FSM coverage):用来记录状态机的各种状态被进入的次数以及状态之间的跳转情况。
- 功能覆盖率:`是一种用户定义的度量,主要是衡量设计所实现的各项功能,是否按预想的行为执行,即是否符合设计说明书的功能点要求,功能覆盖率主要有两种如下所示:
- 面向数据的覆盖率(Data-oriented Coverage)-对已进行的数据组合检查.我们可以通过编写覆盖组(coverage groups)、覆盖点(coverage points)和交叉覆盖(cross coverage)获得面向数据的覆盖率.
- 面向控制的覆盖率(Control-oriented Coverage)-检查行为序列(sequences of behaviors)是否已经发生.通过编写SVA来获得断言覆盖率(assertion coverage).
需要指出的是: 代码覆盖率达到要求并不意味着功能覆盖率也达到要求,二者无必然的联系。而为了保证验证的完备性,在收集覆盖率时,要求代码覆盖率和功能覆盖率同时达到要求。
三、功能覆盖率建模
功能覆盖率主要关注设计的输入、输出和内部状态,通常以如下方式描述信号的采样要求;
- 对于输入,它检测数据端的输入和命令组合类型,以及控制信号与数据传输的组合情况。
- 对于输出,它检测是否有完整的数据传输类别,以及各种情况的反馈时序。
- 对于内部设计,需要检查的信号与验证计划中需要覆盖的功能点相对应。通过对信号的单一覆盖、交叉覆盖或时序覆盖来检查功能是否被触发,以及执行是否正确。
3.1.覆盖组——covergroup
使用覆盖组结构(covergroup)定义覆盖模型,覆盖组结构(covergroup construct)是一种用户自定义的结构类型,一旦被定义就可以创建多个实例就像类(class)一样,也是通过new()来创建实例的。覆盖组可以定义在module、program、interface以及class中。
每一个覆盖组(covergroup)都必须明确一下内容:
- 一个时钟事件以用来同步对覆盖点的采样;
- 一组覆盖点(coverage points),也就是需要测试的变量;
- 覆盖点之间的交叉覆盖;
- 可选的形式参数;
- 覆盖率选项;
covergroup cov_grp @(posedge clk); //用时钟明确了覆盖点的采样时间,上升沿采样覆盖点,也可省略clk,在收集覆盖率时在根据情况注明
cov_p1: coverpoint a;//定义覆盖点,cov_p1为覆盖点名,a为覆盖点中的变量名,也就是模块中的变量名
endgroup
cov_grp cov_inst = new();//实例化覆盖组
上述例子用时钟明确了覆盖点的采样时间,上升沿采样覆盖点,也可省略clk,在收集覆盖率时在根据情况注明,如下示例:
covergroup cov_grp;
cov_p1: coverpoint a;//cov_p1为覆盖点名,a为覆盖点中的变量名,也就是模块中的变量名
endgroup
cov_grp cov_inst = new();
cov_inst.sample(); //sample函数收集覆盖率
上面的例子通过内建的sample()方法来触发覆盖点的采样.
logic [7:0] address;
covergroup address_cov (ref logic [7:0] address, //添加形式参数
input int low, int high) @ (posedge ce);
ADDRESS : coverpoint address {
bins low = {
0,low};
bins med = {
low,high};
}
endgroup
address_cov acov_low = new(addr,0,10);
address_cov acov_med = new(addr,11,20);
address_cov acov_high = new(addr,21,30);
覆盖组中允许带形式参数,外部在引用覆盖组时可以通过传递参数,从而对该覆盖组进行复用。
3.2.覆盖点——coverpoint
一个覆盖组可以包含多个覆盖点,每个覆盖点有一组显式bins值,bins值可由用户自己定义,每个bins值与采样的变量或者变量的转换有关。一个覆盖点可以是一个整型变量也可以是一个整型表达式。覆盖点为整形表达式的示例如下:注意覆盖点表达式写法。
class Transaction();
rand bit[2:0] hdr_len; //取值:0~7
rand bit[3:0] payload_len; //取值:0~15
...
endclass
Transaction tr;
covergroup Cov;
len16: coverpoint(tr.hdr_len + tr.payload_len); //注:取值范围为0~15
len32:coverpoint(tr.hdr_len + tr.payload_len + 5'b0); //注:取值范围为0~31
endgroup
当进行仿真后,len16的覆盖点覆盖率最高可达100%,而覆盖点len32的覆盖率最高只能达到23/32=71.87%。由于总的bins数量为32个,而实际最多只能产生产生len_0,len_1,len2,…,len22共23个bins,所以覆盖率永远不可能达到100%。
如果要使覆盖点len32达到100%的覆盖率,可以手动添加自定义bins,代码如下:
covergroup Cov;
len32:coverpoint(tr.hdr_len + tr.payload_len + 5'b0); //注:取值范围为0~31
{
bins len[] = {
[0:22]};}
此时将覆盖点的范围限定在0~22之间,符合覆盖点的实际取值范围,故覆盖率可以达到100%。
3.3.覆盖点元素——隐式bin与显式bins
- 隐式或自动bin:覆盖点变量,其取值范围内的每一个值都会有一个对应的bin,这种称为自动或隐式的bin。例如,对于一个位宽为nbit的覆盖点变量,若不指定bin个数,2^n个bin将会由系统自动创建,需要注意的是 自动创建bin的最大数目由auto_bin_max内置参数决定,默认值64。
program automatic test(busifc.TB ifc); //接口例化
class Transaction;
rand bit [3:0] data;
rand bit [2:0] port;
endclass
covergroup Cov; //定义覆盖组,未添加时钟信号,此时需要使用sample()函数采集覆盖率
coverpoint tr.port; //设置覆盖点
endgroup
initial begin
Transaction tr=new(); //例化数据包
Cov ck=new(); //例化覆盖组
repeat(32) begin
tr.randomize();
ifc.cb.port <= tr.port;
ifc.cb.data <= tr.data;
ck.sample(); //采集覆盖率
@ifc.cb;
end
end
endprogram
对于覆盖点tr.port,如果覆盖率达到100%,那么将会有auto[0],auto[1],auto[2] … auto[7]等8个bin被自动创建。其实际功能覆盖率报告如下:
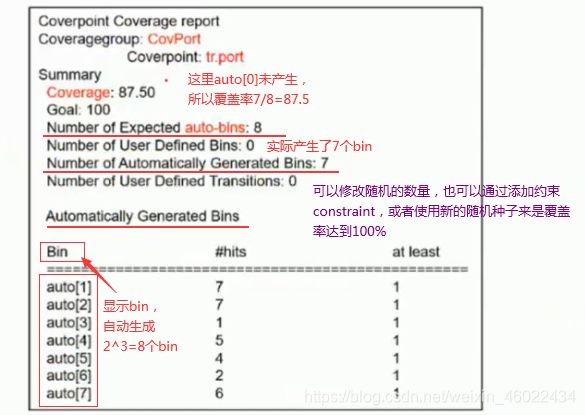
- 显式bins:"bins"关键字被用来显示定义一个变量的bin,用户自定义bin可以增加覆盖的准确度,它属于功能覆盖率的一个衡量单位。在每次采样结束时,生成的数据库中会包含采样后的所有bins,显示其收集到的具体覆盖率值。最终的覆盖率等于采样的bins值除以总的bins值。
covergroup 覆盖组名 @(posedge clk);//时钟可以没有
覆盖点名1: coverpoint 变量名1{
bins bin名1 = {
覆盖点取值范围}(iff(expression)); //iff结构可以指定采样条件
bins bin名2 = {
覆盖点取值范围};
bins bin名3 = {
覆盖点取值范围};
.......
}//一般会将bin的数目限制在8或16
。。。。。。
endgroup : 覆盖组名
iff结构的运用实例如下:
bit[1:0] s0;
covergroup g4;
cover1: coverpoint s0 iff(!reset) ; //当reset=0时,表达式为真开始采样
endgroup
//注意对coverpoint的bin的声明使用的是{},这是因为bin是声明语句而非程序语句,而且{}后也没有加分号
针对某一变量,我们关心的可能只是某些区域的值或者跳转点,因此我们可以在显示定义的bins中指定一组数值(如3,5,6)或者跳转序列(如3->5->6)。 显示定义bins时,可通过关键字default将未分配到的数值进行分配。
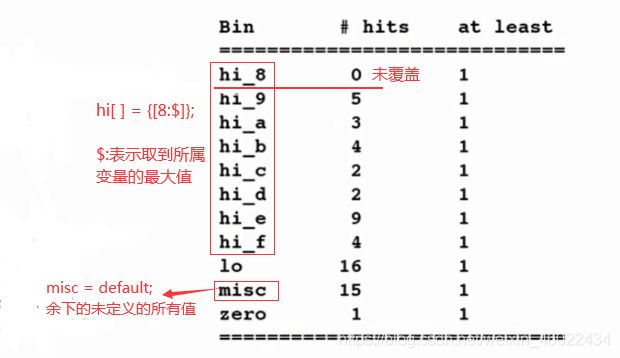
covergroup Cov;
coverpoint tr.data{
//data变量的取值范围为0~15,不设置显示bins时,理论上会有16个bin
bins zero = {
0}; //取值:0
bins lo = {
[1:3],5}; //取值:1,2,3,5
bins hi[] = {
[8:$]}; //取值:8~15,使用动态数组方法时相当于创建了hi[0],hi[1],...,hi[7]一共8个bins
bins misc = default; //余下的所有值:4,6,7
}
其部分覆盖率报告如下:
除了在bins中定义数值,还可以定义数值之间的跳转,操作符(=>),如下所示:
bit[2:0] v;
covergroup sg@(posedge clk);
coverpoint v{
bins b2=(3 => 4 => 5); //3 to 5
bins b3=(1,5 => 6=>7); //(1=>6)、(1=>7)、(5=>6)、(5=>7)
bins b5=(5[*3]); //3 consecutive 5's(连续重复,数值5的3次重复连续)
bins b6=(3[*3:5]); //(3=>3=>3)、(3=>3=>3=>3)、(3=>3=>3=>3=>3)
bins b7=(4[->3]=>5); //...=>4...=>4...=>4=>5(跟随重复,4出现3次,可以不连续,但在最后一个4出现后,下一个数值为5)
bins b8=(2[=3]=>5); //...=>2...=>2...=>2...=>5(非连续重复,数值2出现3次)
bins anothers=default_sequence;
}
endgroup
3.4.覆盖点之间的交叉覆盖率——cross
交叉覆盖是在覆盖点或变量之间指定的,必须先指定覆盖点,然后通过关键字cross定义覆盖点之间的交叉覆盖。
//通过覆盖点来定义交叉覆盖
bit [3:0] a, b;
covergroup cg @(posedge clk);
c1: coverpoint a;
c2: coverpoint b;
c1Xc2: cross c1,c2; //1. 定义交叉覆盖使用关键字cross,利用**覆盖点名字**定义交叉覆盖
endgroup : cg
//通过变量名来定义交叉覆盖
bit [3:0] a, b;
covergroup cov @(posedge clk);
aXb : cross a, b; //2. 定义交叉覆盖使用关键字cross,直接利用**变量名字**定义交叉覆盖
endgroup
//交叉覆盖的通用定义格式:
交叉覆盖名:cross 交叉覆盖点名1,交叉覆盖点名2;
由于上面每个覆盖点都有16个bin,所以它们的交叉覆盖总共有256(16*16)个交叉积(cross product),也就对应256个bin。
bit [3:0] a, b, c;
covergroup cov @(posedge clk);
BC : coverpoint b+c;
aXb : cross a, BC;
endgroup
上例的交叉覆盖总共有256个交叉积(cross product),也对应256个bin.
3.5.覆盖点之间的状态跳转
3.6.覆盖率的选项与方法
- at_least——覆盖阈值,定义一个bin在执行代码过程中至少触发的次数,低于这个触发次数的话,这个bin不算覆盖,默认值是1;
- auto_bin_max——当没有bin为显示创建时,定义一个覆盖点的自动bin的最大数量,默认值为64;
- cross_auto_bin_max——定义一个交叉覆盖的交叉积(cross product)的自动bin的最大数量,没有默认值;
covergroup cg @(posedge clk);
c1: coverpoint addr {
option.auto_bin_max = 128;}//addr自动bin的数目最大为128
c2: coverpoint wr_rd {
option.at_least = 2;}//wr_rd的每个bin至少要触发两次,否则不算覆盖
c1Xc2: cross c1, c2 {
option.cross_auto_bin_max = 128;}//交叉积的自动bin数目最大为128
endgroup : cg
//覆盖选项如果是在某个coverpoint中定义的,那么其作用范围仅限于该coverpoint;
//如果是在covergroup中定义的,那么其作用范围是整个covergroup;
四、代码code——约束与覆盖率的运用
- void sample() : Triggers the sampling of covergroup 触发覆盖组的采样
- real get_coverage() : Calculate coverage number, return value will be 0 to 100 返回覆盖组覆盖率
- real get_inst_coverage() :Calculate coverage number for given instance, return value will be 0 to 100 返回覆盖组实例的覆盖率
- void set_inst_name(string) :Set name of the instance with given string 设置实例名
- void start() :Start collecting coverage 开启覆盖率收集
- void stop() :Stop collecting coverage 结束收集覆盖率
module test();
logic [2:0] addr;
wire [2:0] addr2;
assign addr2 = addr + 1;
covergroup address_cov;
ADDRESS : coverpoint addr {
option.auto_bin_max = 10;
}
ADDRESS2 : coverpoint addr2 {
option.auto_bin_max = 10;
}
endgroup
address_cov my_cov = new;
initial begin
my_cov.ADDRESS.option.at_least = 1;
my_cov.ADDRESS2.option.at_least = 2;
// start the coverage collection
my_cov.start();
// Set the coverage group name
my_cov.set_inst_name("ASIC-WORLD");
$monitor("addr 8'h%x addr2 8'h%x",addr,addr2);
repeat (10) begin
addr = $urandom_range(0,7);
// Sample the covergroup
my_cov.sample();
#10;
end
// Stop the coverage collection
my_cov.stop();
// Display the coverage
$display("Instance coverage is %e",my_cov.get_coverage());
end
endmodule
4.1.通过修改随机化次数——提高覆盖率(覆盖点变量取值范围小)
1)、在不添加约束constraint、不使用自定义bins,的情况下:
module cov_demo();
class transaction;
rand bit[31:0] data; //2^32种可能
rand bit[2:0] port; //0~7,一共8种可能
endclass
covergroup cov_port;
port_bin : coverpoint tr.port;
data_bin : coverpoint tr.data;
endgroup
transaction tr=new; //声明类的句柄,创建对象
cov_port ck=new; //声明覆盖组的句柄,创建对象; covergroup和class类似
initial begin
repeat(4)begin //生成得数据包的数量会影响覆盖率,也可以通过添加约束constraint来提升覆盖率,或者自定义bins。
tr.randomize; //随机化生成数据
ck.sample(); //搜集覆盖率
end
end
endmodule
覆盖率如下:使用Makefile实例三即可。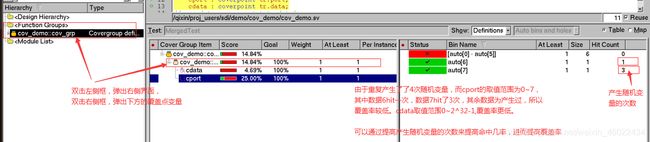
可以看出,两个覆盖点cport和cdata的覆盖率都较低,这是由于产生的随机化数据次数太少, 可以通过提高产生随机化的重复次数进一步提高覆盖率
2)、在不添加约束constraint、不使用自定义bins,**改变随机化次数**的情况下:
repeat(32)begin //生成得数据包的数量会影响覆盖率,也可以通过添加约束constraint来提升覆盖率,或者自定义bins。
在将repeat(4)改为repeat(32)后:覆盖率如下:
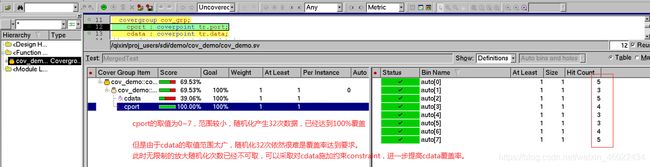
需要指出的是,提高随机化次数来提高覆盖率的方法只适用于,覆盖点的变量本身取值范围不大(如cport)的情况,如cdata自身取值范围太大,此方法便不再适用。此时可以通过添加约束constraint提高覆盖率。

4.2.通过添加约束constraint、自定义bins——提高覆盖率(覆盖点变量取值范围大)
1)、在自定义bins,而不添加约束constraint的情况下:
module cov_demo();
class transaction;
rand bit[31:0] data; //2^32种可能
rand bit[2:0] port; //0~7,一共8种可能
endclass
covergroup cov_port;
port_bin : coverpoint tr.port;
data_bin : covergroup tr.data{
bins min={
[0:100]}; //此时,随机化生成该范围内任意一个数,该bins便被覆盖
bins mid={
[101:9999]};
bins max={
[10000:$]}; //$—-表示最大的边界
}
endgroup
transaction tr=new; //声明类的句柄,创建对象
cov_port ck=new; //声明覆盖组的句柄,创建对象; covergroup和class类似
initial begin
repeat(32)begin //生成得数据包的数量会影响覆盖率,也可以通过添加约束constraint来提升覆盖率,或者自定义bins。
tr.randomize; //随机化生成数据
ck.sample(); //搜集覆盖率
end
end
endmodule
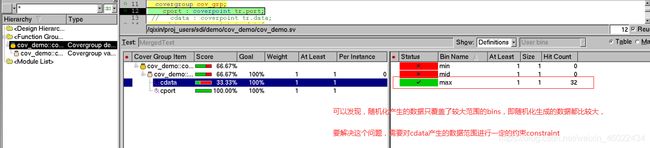
2)、在自定义bins,添加约束constraint的情况下:
module cov_demo();
class transaction;
rand bit[31:0] data; //2^32种可能
rand bit[2:0] port; //0~7,一共8种可能
constraint data_c1{
data inside {
[0:100],[101:9999],[10000:12000]}; //由于data的可能性太多,故对其施加约束
}
endclass
covergroup cov_port;
port_bin : coverpoint tr.port;
data_bin : covergroup tr.data{
bins min={
[0:100]}; //此时,随机化生成该范围内任意一个数,该bins便被覆盖
bins mid={
[101:9999]};
bins max={
[10000:$]}; //$—-表示最大的边界
}
endgroup
transaction tr=new; //声明类的句柄,创建对象
cov_port ck=new; //声明覆盖组的句柄,创建对象; covergroup和class类似
initial begin
repeat(32)begin //生成得数据包的数量会影响覆盖率,也可以通过添加约束constraint来提升覆盖率,或者自定义bins。
tr.randomize; //随机化生成数据
ck.sample(); //搜集覆盖率
end
end
endmodule
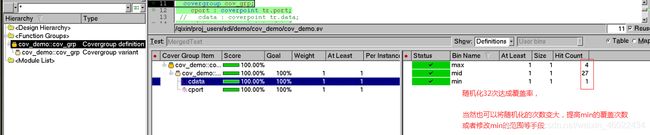
将随机化的次数改为320次后,repeat(320):覆盖率的hit次数变化分布不明显,如下图:可以通过施加权重调整hit的次数分布.

4.3.通过权重dist——调整hit次数分布
将代码中的constraint约束调整为权重dist处理后,其各个bins的hit次数分布更加均匀,如下所示:
constraint data_c1{
data dist {
[0:100]:/ 100, [101:9999]:/ 100, [10000:12000]:/ 120};
}
