第7章 操作字符串
第7章 操作字符串
字符串是有限字符的序列,主要包括字母、数字、特殊字符(如空格等),在程序设计中,它也是经常使用的一种数据类型。在JavaScript中,字符串只有一种类型,没有字符、字符串或文本等子类型。
字符串操作常用在表单处理、HTML文本解析、异步响应文本解析中,与正则表达式配合使用,以提升字符串操作的灵活性。字符串操作包括字符匹配、查找、替换、截取编码/解码、连接等。本章将详细讲解各种String方法的使用和应用技巧。
【学习重点】
▲ 定义字符串
▲ 字符串查找、连接和截取
▲ 编辑字符串
▲ 比较字符串
▲ 字符串检测
▲ 字符串加解密
7.1 定义字符串
定义字符串有多种方式,如字符串直接量、构造字符串和使用字符编码设计字符串,下面分别进行介绍。
7.1.1 字符串直接量
定义字符串直接量的方法很简单,使用双引号或单引号包含字符文本即可。例如:
【示例1】任何字符被引号包含,都会被转换为字符串类型数据。

由于一些字符包含双重或多重语义,把它们包含在字符串中,会破坏字符串的值,甚至破坏字符串的类型,因此需要转义特殊字符,避免产生歧义。
【示例2】单引号和双引号配合使用,以应对特殊形式的字符串需要。
var s =“alert(‘Hello,World’)”;
可以这样写:
var s=‘alert(“Hello,World”)’;
单引号可以包含双引号,或者双引号包含单引号。但是不能够在单引号中包含单引号,或者在双引号中包含双引号。下面写法都是错误的:
【示例3】如果要表示引号字符,需要使用转义序列来表示。
【示例4】对于字符串类型的语句或表达式,可以调用静态方法eval()来执行。
7.1.2 构造字符串
String是JavaScript内置对象,调用String()构造函数可以构造字符串,该函数可以接收一个参数,并把它作为初始值来初始化字符串。
【示例1】下面的代码使用了new运算符调用String()构造函数,将创建一个字符串型对象。
注意:通过String构造函数构造的字符串与字符串直接量的类型是不同的。前者为引用型对象,后者为值类型的字符串。
【示例2】下面的代码比较了构造字符串和字符串直接量的数据类型的不同。

从上面示例可以看到,String构造函数实际上是字符串的包装类,利用它可以把值类型字符串包装为引用型对象,以适应各种字符串的特殊处理。
【示例3】String()也可以作为普通函数使用,把参数转换为字符串类型的值返回,此时它就不是构造函数了。

【示例4】String()可以带有多个参数,但是它仅处理第一个参数,并把它转换为字符串返回。

String构造函数也可以附带多个参数,它仅负责构造第一个参数,并返回它的字符串。但是,所附带的多个参数是会被JavaScript执行计算的。
【示例5】下面的变量n在构造函数内经过多次计算之后,最后值递增为5。如下:

7.1.3 使用字符编码
String对象预定义了fromCharCode()方法,该方法能够根据字符编码创建字符串,这对于希望通过数字动态生成字符串来说,是非常有用的。
fromCharCode()方法可以包含多个整数参数,每个参数代表字符的Unicode编码。返回值含有指定编码的字符的新字符串。
【示例】下面的代码演示了如何将一组字符串编码转换为字符串。

可以把所有字符串按顺序传递给fromCharCode()方法。
var b=String.fromCharCode(35835, 32773, 24744, 22909) ; //传递多个参数,返回字符串"读者您好"
可以使用Function的apply()方法动态调用数组参数:

fromCharCode()方法是String对象的静态方法,不能在字符串中直接调用。
提示:fromCharCode()方法可以与String对象的charCodeAt()配合使用,执行相反操作。charCodeAt()可以把字符串转换为编码,而fromCharCode()方法能够把编码转换为字符串。
7.2 使用字符串
String对象预定义了很多方法,利用这些方法可以灵活处理字符串。字符串操作主要包括:
☑ 查找字符,如是否包含数字、字母还是其他特定字符。
☑ 查找字符串长度和字符格式,如数组、日期等。
☑ 字符串基本操作,如截取子字符串、插入字符、删除字符、置换字符、字符串比较、字符串连接和拆分等。
☑ 字符串高级操作,如模糊匹配、字符加密等。
7.2.1 案例:计算字符串长度
String对象预定义了length属性,该属性存储着当前字符串的长度。它可以显示字符串的字符个数。
【示例1】下面的代码使用了字符串的length属性获取字符串的字符长度。
字符包括单字节、双字节两种类型,为了精确计算字符串的字节长度,可以采用以下两个方法。
【示例2】利用循环结构枚举每个字符,并根据字符的字符编码,判断当前字符是单字节还是双字节,然后递加字符串的字节数。

测试:
【拓展】在检测字符是否为双字节或单字节时,方法也是有多种的,这里再提供两种思路:

或者使用正则表达式进行字符编码验证:

【示例3】利用正则表达式把字符串中双字节字符临时替换为两个字符,然后调用length属性获取临时字符串的长度:

上述方法比较简洁,但是执行效率相对要慢,因为它需要两次遍历字符串,即调用replace()方法一次,使用length属性时一次。而第一种方法中只进行一次字符串遍历。
注意:String对象的length属性是只读属性,这与Array的length属性不同(即数组的长度是可以动态改变的)。不过,又与数组一样,字符串可以使用下标来定位单个字符在字符串中的位置,其中第一个字符的下标值为0,最后一个字符的下标值为length-1。但是字符串中的字符是不能够被for/in循环枚举的。运算符delete也不能删除字符串中指定位置的字符。
7.2.2 案例:连接字符串
为一个字符串添加字符串的方法也很多。最简单的是使用加号运算符,把多个字符串或字符连接在一起。
【示例1】下面的代码使用了加号运算符连接两个字符串。

String对象定义了concat()方法,该方法可以把多个参数添加到指定字符串的尾部。不过,在实际开发中,直接使用加号运算符执行字符串连接操作通常更简便一些。
【示例2】下面的代码使用了字符串的concat()方法将多个字符串连接在一起。

concat()方法的参数是没有限制的,参数类型也没有限制。如果需要,在执行连接操作时,它会把所有参数都转换为字符串,然后按顺序连接到当前字符串的尾部,最后返回连接后的字符串。当然,concat()方法不会修改原字符串的值。这与数组的concat()非常相似,操作也一样。
7.2.3 案例:查找字符串
检索字符串、查找特定字符串是字符串操作中的基本技能,实际开发中大量工作也是与此有关的,如表单验证、查找指定字符等。为此,String对象定义了很多功能强大的方法,详细说明如表7-1所示。
表7-1 String对象的查找字符串方法

1.获取指定位置的字符
使用String的charAt()和charCodeAt()方法,可以根据参数返回指定下标位置的字符或字符的编码。
【示例1】使用charAt()把字符串中每个字符都装入一个数组中,从而可以为String对象扩展一个原型方法,用来把字符串转换为数组。

然后就可以实现对字符串的所有字符进行遍历。

对于charAt()方法来说,字符串中第一个字符的下标值为0。如果参数n不在0和length-1之间,则返回空字符串。
字符实际上也是字符串,即长度为1的字符串。JavaScript没有定义字符类型的数据,而在其他强类型语言中,是把字符和字符串分为两种不同类型的数据。
charCodeAt()与charAt()方法操作一样,不过它返回的是指定位置的字符编码。如果指定下标值为负数,或者大于等于字符串的长度,则该方法将返回NaN,而不再是0。
2.查找子字符串的位置
charAt()和charCodeAt()方法是根据下标查找字符,而indexOf()和lastIndexOf()方法则是根据指定字符串查找它的下标位置。
indexOf()方法有两个参数,第一个参数为一个子字符串,是指将要查找的对象。第二个参数为一个整数值,用来指定查找的起始位置,其取值范围是0~length-1,对于该参数来说:
☑ 如果值为负数,则视为0,就相当于从第一个字符开始查找。
☑ 如果省略了这个参数,也将从字符串的第一个字符开始查找。
☑ 如果值大于等于length属性值,则视为当前字符串中没有指定的子字符串,即返回-1。不过在JavaScript 1.0和JavaScript 1.1中会返回一个空字符串(这是一个Bug)。
【示例2】下面的代码查询了字符串中首个字母a的下标位置。

indexOf()方法只返回查找到的第一个子字符串的起始下标值,如果没有找到将返回-1。
【示例3】下面的代码查询了URL字符串中首个字母w的下标位置。
如果要想查找下一个子字符串,则可以使用第二个参数来限定范围。
【示例4】下面的代码分别查询了URL字符串中两个点号字符的下标位置。

注意:indexOf()方法是按着从左到右的顺序进行查找的。如果希望从右到左来进行查找,则可以使用lastIndexOf()方法来查找。
【示例5】下面的代码以从后往前的方式查询URL字符串中最后一个点号字符的下标位置。
提示:使用lastIndexOf()方法时,需要注意下面几个问题。
(1)lastIndexOf()方法的查找顺序是从右到左,但是其参数和返回值都是根据字符串的下标从左到右的顺序来计算的,而不是反着来计算字符串的下标值。即字符串的左侧第一个字符下标值始终都是0,而最后一个字符的下标值始终都是length-1。
(2)第二个参数指定起始查找的下标位置,这个起始是指指定下标位置左侧开始查找,因为它是按从右到左的顺序执行的。例如:
var s=“http://www.mysite.cn/index.html”;
var n=s.lastIndexOf("." , 11); //返回值为10,而不是15
其中第二个参数值11表示字符c(第一个)的下标位置,然后从其左侧开始向左查找,所以就返回第一个点号的位置。
(3)如果查找到,则返回第一次查找的子字符串的起始下标值,这个起始位置是最左侧的意思,而不是最右侧位置。例如:
var s=“http://www.mysite.cn/index.html”;
var n=s.lastIndexOf(“www”); //返回值为7,而不是10
如果第二个参数出现没有传递,或为负值,或大于等于length属性值等情况,则将遵循indexOf()方法来计算。
3.匹配字符串
search()和match()方法能够查找子字符串。由于它们都与正则表达式紧密联系,所以只有掌握正则表达式的使用之后,才能够灵活使用它们。
search()方法的功能与indexOf()方法相似,都是查找子字符串第一次出现的下标位置。但是它仅有一个参数,即指定的匹配模式,也没有lastIndexOf()的反向检索的功能,同时它也不支持全局模式。
【示例6】下面的代码使用了search()方法匹配斜杠字符在URL字符串的下标位置。
提示:使用search()方法时需要注意以下几个问题。
(1)该方法的参数为正则表达式,即声明要匹配的RegExp对象。如果该参数不是RegExp对象,则JavaScript会使用RegExp()构造函数把它转换成RegExp对象。
(2)search()方法遵循从左到右的查找顺序,并返回第一个匹配的子字符串的起始下标值。如果没有找到,则返回-1。
(3)该方法没有第二个参数,它无法查找指定的范围,换句话说它始终返回的是第一个匹配子字符串的下标值。从这点上考虑,它没有indexOf()灵活和实用。
【示例7】与search()方法相比,match()方法要强大很多,它能够找出所有匹配的子字符串,并存储在一个数组中返回。

【拓展】match()方法的用法也比较灵活,由于需要一定的正则表达式基础,下面介绍该方法应该注意的问题。
(1)match()方法返回的是一个数组,但是它的行为受正则表达式的匹配模式限制,如果匹配模式没有附带全局匹配修饰符g,那么match()方法只能执行一次匹配。例如,下面的匹配模式中没有g修饰符,只能够执行一次匹配,返回仅有一个元素h的数组。
(2)如果没有找到匹配字符,则返回null,而不是空数组。
(3)当不执行全局匹配(即附带有g修饰符)时,如果在匹配模式中包含有子表达式,则返回的数组中存放着找到的匹配文本相关的信息。
【示例8】下面的代码使用了match()方法匹配URL字符串中所有点号字符。

在这个正则表达式“/(.).(.).(.)/”中,左右两个斜杠是匹配模式分隔符,JavaScript解释器能够根据这两个分隔符来识别正则表达式。在正则表达式中小括号表示子表达式,每个子表达式匹配的文本信息多会被独立存储,以备调用。反斜杠表示转义序列,因为点号在正则表达式中表示匹配任意字符,星号表示前面的匹配字符可以匹配任意多次。
在上面示例中,数组a并非仅有一个元素,而包含4个元素,且每个元素存储着不同的信息。其中第一个元素存放的是匹配文本,其余的元素存放的是与正则表达式的子表达式匹配的文本。
另外,这个数组还包含两个对象属性,其中index属性存储匹配文本的起始字符在字符串中的位置,input属性存储对匹配字符串的引用。
(4)在全局匹配模式下,即附带有g修饰符。match()将执行全局匹配。此时返回的数组的内容与非全局匹配完全相同,它的数组元素存放的是字符串中所有匹配子串,该数组没有index属性和input属性。同时不再提供子表达式匹配的文本信息,也不声明每个匹配子串的位置。如果需要这些全局检索的信息,可以使用RegExp.exec()方法。
7.2.4 案例:截取子字符串
在字符串操作中,截取子字符串与查找子字符串一样都很重要。如果说查找是定位,那么截取才是操作的核心。JavaScript提供了3个字符串截取方法,如表7-2所示。
表7-2 String对象的截取子字符串方法

1.根据长度截取子字符串
substr()方法能够根据指定长度来截取子字符串。它可以包含两个参数,第一个参数表示准备截取的子串的起始下标,第二个参数表示截取的长度。
【示例1】在本示例中使用lastIndexOf()获取字符串的最后一个点号的下标位置,然后从其后的位置开始截取4个字符:

提示:使用substr()方法时,需要注意两个问题。
(1)如果省略第二个参数,则表示截取从起始位置开始到结尾的所有字符。考虑到扩展名的长度不固定,省略第二个参数会更灵活:
var b=s.substr(s.lastIndexOf(".")+1);
(2)如果第一个参数为负值,则表示从字符串的尾部开始计算下标位置,即-1表示最后一个字符,-2表示倒数第二个字符,依此类推。这对于左侧字符长度不固定时非常有用。
ECMAScript没有标准化该方法,所以被列为不建议选用的方法,建议使用slice()和substring()方法。
2.根据起止下标截取子字符串
slice()和substring()方法都是根据指定的起止下标位置来截取子字符串,也就是说,它们都可以包含两个参数,第一个参数表示起始下标,第二个参数表示结束下标。不过slice()方法显得更加灵活。
【示例2】下面的代码使用了substring()方法截取URL字符串中网站主机名信息。

提示:使用时请注意两个问题。
(1)截取子字符串包含第一个参数所指定的字符。结束点不被截取,即不包含在子字符串中。
(2)第二个参数如果省略,表示截取到结尾的所有字符串。
但是slice()和substring()方法也存在很多不同点,具体比较如下:
区别一,如果第一个参数值比第二个参数值大,substring()方法能够在执行截取之前,先交换两个参数,而对于slice()方法来说则被视为无效,并返回空字符串。
【示例3】下面的代码比较了substring()方法和slice()方法其用法的不同。

这对于起始点和结束点的值无法确定时是有效的,因为substring()方法能够自动对参数进行调整。
区别二,如果参数值为负值,则slice()方法能够把负号解释为从右侧开始定位,这与Array的slice()方法相同。但是substring()方法会视其为无效,并返回空字符串。
【示例4】下面的代码进一步比较了substring()方法和slice()方法用法的不同。

7.2.5 案例:编辑字符串
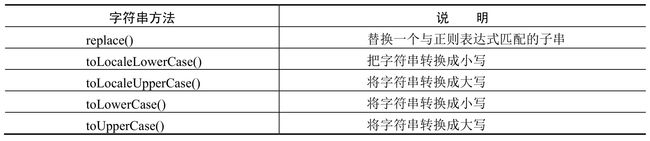
字符串编辑操作主要包括替换子字符串和字符串大小写转换,具体方法如表7-3所示。
表7-3 String对象的编辑字符串方法
1.替换子字符串
replace()方法包含两个参数,第一个参数表示执行匹配的正则表达式,第二个参数表示准备代替匹配的子字符串。
【示例1】下面的代码使用了replace()方法将字符串中的“html”修改为“htm”。

该方法第一个参数是一个正则表达式对象,也可以传递字符串,如下所示:
不过replace()方法不会把字符串转换为正则表达式对象,这与查找字符串中search()和match()等几个方法不同,而是以字符串直接量的文本模式进行匹配。第二个参数可以是替换的文本,或者是生成替换文本的函数,把函数返回值作为替换文本来替换匹配文本。
【示例2】下面的代码在使用replace()方法时,灵活使用了替换函数修改匹配字符串。

replace()方法实际上执行的是同时查找和替换两个操作。它将在字符串中查找与正则表达式相匹配的子字符串,然后调用第二个参数值或替换函数替换这些子字符串。如果正则表达式具有全局性质g,那么将替换所有的匹配子字符串,否则,它只替换第一个匹配子字符串。
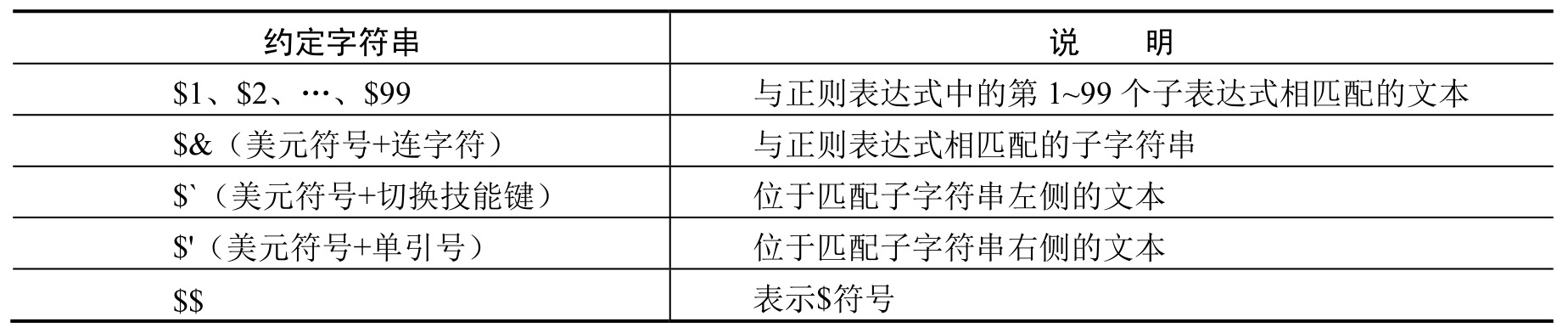
【示例3】在replace()方法中约定了一个特殊的字符($),这个美元符号如果附加一个序号就表示对正则表达式中匹配的子表达式存储的字符串引用。

在上面示例中,正则表达式/(java)(script)/中包含两对小括号,按顺序排列,其中第一对小括号表示第一个子表达式,第二对小括号表示第二个子表达式,在replace()方法的参数中可以分别使用字符串"$1"和" 2 " 来 表 示 对 它 们 匹 配 文 本 的 引 用 , 当 然 它 们 不 是 标 识 符 , 仅 是 一 个 标 记 , 所 以 不 可 以 作 为 变 量 参 与 计 算 。 < / s p a n > < / p > < s p a n > < / s p a n > < p c l a s s = " b o d y C o n t e n t − 1 " > < s p a n > 除 了 上 面 约 定 之 后 , 美 元 符 号 与 其 他 特 殊 字 符 组 合 还 可 以 包 含 更 多 的 语 义 , 详 细 说 明 如 表 7 − 4 所 示 。 < / s p a n > < / p > < s p a n > < / s p a n > < d i v c l a s s = " t a b l e i m g " > < s p a n > < / s p a n > < p c l a s s = " b i a o t i " > < s p a n > 表 7 − 4 r e p l a c e ( ) 方 法 第 二 个 参 数 中 的 特 殊 字 符 < / s p a n > < / p > < s p a n > < / s p a n > < i m g s r c = " h t t p : / / c s d n − e b o o k − r e s o u r c e s . o s s − c n − b e i j i n g . a l i y u n c s . c o m / i m a g e s / 2 c 83 a 3791 b 4 c 4 f 22 a d 1 a 1 a 333 c 88242 e / F i g u r e − T 21 2 1 89143. j p g " c l a s s = " p i c − i m g " a l t = " " > < s p a n > < / s p a n > < / d i v > < s p a n > < / s p a n > < p c l a s s = " b o d y C o n t e n t − 1 " > < b > < s p a n > 【 示 例 4 】 < / s p a n > < / b > < s p a n > 重 复 字 符 串 。 < / s p a n > < / p > < s p a n > < / s p a n > < d i v c l a s s = " c h a t u i m g " > < s p a n > < / s p a n > < i m g s r c = " h t t p : / / c s d n − e b o o k − r e s o u r c e s . o s s − c n − b e i j i n g . a l i y u n c s . c o m / i m a g e s / 2 c 83 a 3791 b 4 c 4 f 22 a d 1 a 1 a 333 c 88242 e / F i g u r e − P 21 2 1 89144. j p g " c l a s s = " p i c − i m g " a l t = " " > < s p a n > < / s p a n > < / d i v > < s p a n > < / s p a n > < p c l a s s = " b o d y C o n t e n t − 1 " > < s p a n > 由 于 字 符 串 “ 2"来表示对它们匹配文本的引用,当然它们不是标识符,仅是一个标记,所以不可以作为变量参与计算。
除了上面约定之后,美元符号与其他特殊字符组合还可以包含更多的语义,详细说明如表7-4所示。
表7-4 replace()方法第二个参数中的特殊字符
【示例4】重复字符串。

由于字符串“ 2"来表示对它们匹配文本的引用,当然它们不是标识符,仅是一个标记,所以不可以作为变量参与计算。</span></p><span></span><pclass="bodyContent−1"><span>除了上面约定之后,美元符号与其他特殊字符组合还可以包含更多的语义,详细说明如表7−4所示。</span></p><span></span><divclass="tableimg"><span></span><pclass="biaoti"><span>表7−4 replace()方法第二个参数中的特殊字符</span></p><span></span><imgsrc="http://csdn−ebook−resources.oss−cn−beijing.aliyuncs.com/images/2c83a3791b4c4f22ad1a1a333c88242e/Figure−T212189143.jpg"class="pic−img"alt=""><span></span></div><span></span><pclass="bodyContent−1"><b><span>【示例4】</span></b><span>重复字符串。</span></p><span></span><divclass="chatuimg"><span></span><imgsrc="http://csdn−ebook−resources.oss−cn−beijing.aliyuncs.com/images/2c83a3791b4c4f22ad1a1a333c88242e/Figure−P212189144.jpg"class="pic−img"alt=""><span></span></div><span></span><pclass="bodyContent−1"><span>由于字符串“&”在replace()方法中被约定为正则表达式所匹配的文本,所以利用它可以重复引用匹配的文本,从而实现字符串重复显示效果。其中正则表达式“/./”表示完全匹配字符串。
【示例5】对匹配文本左侧的文本完全引用。

其中字符“KaTeX parse error: Expected 'EOF', got '&' at position 1: &̲amp;”代表匹配子字符串“<…`”代表匹配文本左侧文本“java”。
【示例6】对匹配文本右侧的文本完全引用。

其中字符“KaTeX parse error: Expected 'EOF', got '&' at position 1: &̲amp;”代表匹配子字符串“j…’”代表匹配文本右侧文本“script”。然后把"KaTeX parse error: Expected 'EOF', got '&' at position 1: &̲amp;’ is"所代表的字符串"JavaScript is"替换原字符串中的"java"子字符串,即组成一个新的字符串"JavaScript is script"。
切换技能键与单引号键比较相似,使用时很容易混淆。
2.字符串大小写转换
String对象为了实现字符串大小写转换操作,特地定义了4个方法,其中toUpperCase()方法可以把字符串转换为大写形式,而toLowerCase()方法可以把字符串转换为小写形式。
【示例7】下面的代码将字符串全部转换为大写形式。
为了适应本地化设计需要,String对象定义了toLocaleLowerCase()和toLocaleUpperCase()两个本地化方法。它们能够按照本地方式转换大小写字母,由于只有几种语言(如土耳其语)具有地方特有的大小写映射,所以通常与toLowerCase()和toUpperCase()方法的返回值一样。
7.2.6 案例:灵活使用replace()方法
ECMAScript 3.0版本中明确规定,replace()方法的第二个参数建议使用函数,而不是字符串,JavaScipt 1.2版本和JScript 5.5版本实现了对这个特性的支持。这样当replace()方法执行匹配时,每次匹配时都会调用该函数,函数的返回值将作为替换文本执行匹配操作,同时函数可以接收以$为前缀的特殊字符组合,用来对匹配文本的相关信息的引用。
【示例1】下面的代码是使用替换函数将字符串中每个单词转换为首字母大写形式显示。

上面示例中,函数f()的参数为特殊字符“KaTeX parse error: Undefined control sequence: \b at position 14: 1”,它表示正则表达式/(\̲b̲\w+\b)/中小括号每次匹配…)/gm说明如下。
☑ “\s”表示空格,“^”表示字符串的开始处。
☑ “KaTeX parse error: Double subscript at position 659: …9787302421924_7_̲1_1_6_11">
【示例5】如果要清除字符串中所有空格,包括字符串内部的,则可以使用如下方法来实现。

7.3.2 检测特殊字符
特殊字符检测和过滤是字符串操作中的常见任务。可以为String对象扩展一个方法check(),用来检测字符串中是否包含指定的特殊字符。
设计思路:方法check()的参数为任意长度和个数的特殊字符列表,检测的返回结果为布尔值。如果检测到任意指定的特殊字符,则返回true,否则返回false。
【示例】下面为字符串扩展一个原型方法check(),它能够根据参数检测字符串中是否存在特定字符。

在该特殊字符检测的扩展方法中,使用了Array对象扩展的each()方法,该方法能够迭代数组。下面应用String对象的扩展方法check(),来检测字符串中是否包含特殊字符尖角号,以判断字符串中是否存在HTML标签。

由于Array对象的扩展方法each()能够多层迭代数组。所以,还可以以数组的形式传递参数。例如:

把特殊字符存储在数组中,这样更方便管理和引用。
7.3.3 优化字符串连接
在应用开发中,经常需要连接字符串进行输出。例如,通过JavaScript控制HTML标签在客户端输出。一般在连接字符串操作时都是使用加号运算符来实现的,但是当这种操作的字符串容量很大时,效率是非常低的。
【示例1】下面的代码演示了使用加号运算符连接字符串的方法。

就这么一步操作,耗时203毫秒,如此操作的字符串非常大,那么这个时间消耗也是令人难以忍受的。但是如果改用数组来执行连接操作,执行效率会大幅提高。
【示例2】下面的代码演示了如何借助数组方法提升字符串的连接效率。
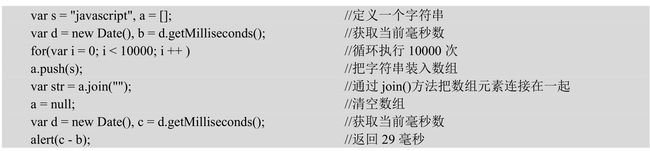
在上面示例中,通过把所有要连接的字符串装入数组,然后调用数组的join()把数组元素连接为字符串输出,这样执行效率大约能够提高10倍左右。如果操作的字符串巨大的话,通过数组中转来进行连接,则执行效率是非常明显的。当然,由于定义数组也会占用系统资源,使用完毕应该立即清除数组。所以,对于比较少的字符串连接操作来说,可以直接使用加号运算符来进行操作,当操作的字符串非常大时,可以考虑使用数组。
7.4 加密和解密
加密和解密是字符串的高级操作,字符串加密解密算法千奇百怪,本节将结合常规字符串加密和解密方法进行讲解,帮助用户初步认识加密和解密的实现途径和设计思路。
7.4.1 JavaScript编码和解码
为了方便开发,JavaScript在Global对象中预定义了6个编码和解码的方法,如表7-6所示。对于一些简单的信息,直接调用这些方法即可快速达到加密和解密的目的。
表7-6 JavaScript预定义编码和解码方法

1.escape()和unescape()方法
escape()是不完全编码的方法,它仅能将字符串中某些字符替换为十六进制的转义序列。具体说,就是除了ASCII字母、数字和标点符号(如@、、、+、-、\、(、)之外,所有字符都被转换为%xx或%uxxxx(x表示十六进制的数字)的转义序列。从\u0000到\u00ff的Unicode字符由转义序列%xx替代,其他所有Unicode字符由%uxxxx序列替代。
【示例1】下面的代码使用了escape()方法编码字符串。

可以使用该方法对Cookie值进行编码,避免与其他约定字符发生冲突,因为Cookie包含的标点符号是有限制的。
与escape()方法对应的是unescape()方法,它能够对escape()编码的字符串解码。该函数是通过找到形式为%xx和%uxxxx的字符序列(这里x表示十六进制的数字),使用Unicode字符\uOOxx和\uxxxx替换这样的字符序列进行解码的。
【示例2】下面的代码使用了unescape()方法解码被escape()方法编码的字符串。

【示例3】这种被解码的代码是不能够直接运行的,读者可以使用eval()方法来执行它。

2.encodeURI()和decodeURI()方法
虽然ECMAScript 1.0版本标准化了escape()和unescape()方法,但是ECMAScript 3.0版本反对使用它们,提倡使用encodeURI()和encodeURIComponent()方法代替escape()方法,使用decodeURI()和decodeURIComponent()方法代替unescape()方法。
【示例4】encodeURI()方法能够把URI字符串进行转义处理。

通过结果可以看到,encodeURI()方法与escape()方法编码结果是不同的。但是,与escape()方法相同,对于ASCII的字母、数字和ASCII标点符号(如-、、.、!、~、、’、(、))来说,也不会被编码。
相对来说,encodeURI()方法会更加安全。它能够将字符转换为UTF-8编码字符,然后用十六进制的转义序列(形式为%xx)对生成的一个、两个或3个字节的字符编码。在这种编码模式中,ASCII字符由一个%xx转义字符替换,在\u0080到\u07ff之间编码的字符由两个转义序列替换,其他的16位Unicode字符由3个转义序列替换。使用decodeURI()方法可以对上面结果进行解码操作。
【示例5】下面的代码演示了如何对URL字符串进行编码和解码操作。

在ECMAScript 3之前,可以使用escape()和unescape()方法执行相似的编码解码操作。
3.encodeURIComponent()和decodeURIComponent()
encodeURI()仅是一种简单的URI字符编码方法,如果使用该方法编码URI字符串,必须确保URI组件(如查询字符串)中不含有URI分隔符。如果组件中含有这些分隔符,就必须使用encodeURIComponent()方法分别对各个组件编码。
encodeURIComponent()方法与encodeURI()方法不同。它们的主要区别就在于,encodeURIComponent()方法假定参数是URI的一部分,例如,协议、主机名、路径或查询字符串。因此,它将转义用于分隔URI各个部分的标点符号。而encodeURI()方法仅把它们视为普通的ASCII字符,并没有转换。
【示例6】下面的代码比较了URL字符串被encodeURIComponent()方法编码前后的不同。
var s =“http://www.mysite.cn/navi/search.asp?keyword=URI”;
a=encodeURI(s);
document.write(a);
document.write("
");
b=encodeURIComponent(s);
document.write(b);
输出显示为:
http://www.mysite.cn/navi/search.asp?keyword=URI
http%3A%2F%2Fwww.mysite.cn%2Fnavi%2Fsearch.asp%3Fkeyword%3DURI
第一行字符串是encodeURI()方法编码的结果,而第二行字符串是encodeURIComponent()方法编码的结果。同encodeURI()方法一样,encodeURIComponent()方法对于ASCII的字母、数字和部分标点符号(如-、_、.、!、~、、’、(、))不编码。而对于其他字符(如/、:、#)这样用于分隔URI各种组件的标点符号,都由一个或多个十六进制的转义序列替换。
【示例7】对于encodeURIComponent()方法编码的结果进行解码,可以使用decodeURIComponent()方法来快速实现:
var s =“http://www.mysite.cn/navi/search.asp?keyword=URI”;
b=encodeURIComponent(s);
b=decodeURIComponent(b)
document.write(b);
7.4.2 案例:Unicode编码
所谓Unicode编码就是根据字符在Unicode字符表中的编号对字符进行简单的编码,从而实现对信息进行加密。例如,字符“中”的Unicode编码为20013,如果在网页中使用Unicode编码显示,则可以输入“中”。因此,把文本转换为Unicode编码之后在网页中显示,能够实现加密信息的效果。
String对象提供了预定charCodeAt()方法,该方法能够把指定的字符串转换为Unicode编码。所以,该方法的设计思路是,利用replace()方法逐个字符地进行匹配、编码转换,最后返回以网页显示的编码格式的信息。
【示例】下面的代码利用了字符串的charCodeAt()方法对字符串进行自定义编码。

简单说明一下,toUnicode()是一个全局静态方法,同时也是一个String对象的方法,为此在函数体内首先判断方法的参数值,以决定执行操作的方式。在replace()字符替换方法中,借助文本替换函数来完成被匹配字符的转码操作。如下所示:

以String对象方法调用的形式如下:

7.4.3 案例:Unicode解码
与Unicode编码操作相对应,可以设计Unicode解码方法,设计思路和代码实现基本相同。
【示例1】下面的代码使用了字符串的charCodeAt()方法定义了一个字符串解码函数。

关于Unicode编码和解码操作,应该注意正则表达式的设计,对于ASCII字符来说,其Unicode编码在\u00~\uFF(十六进制)之间;而对于双字节的汉字来说,则应该是大于\uFF编码的字符集,因此在判断时要考虑到不同的字符集合。
【示例2】利用上面定义的方法尝试把被toUnicode()方法编码的字符进行解码:

7.4.4 综合实战:自定义加密和解密方法
加密和解密的关键是算法设计,通俗地说就是设计一个函数式,输入字符串之后,经过复杂的函数处理,返回一组看似杂乱无章的字符串。对于常人来说,输入的字符串是可以阅读的信息,但是被函数打乱或编码之后显示的字符串就变成无意义的垃圾信息。要想把这些垃圾信息变为有意义的信息,还需要使用相反的算法把它们逆转回来。
【示例】假设把字符串“中”进行自定义加密。可以考虑利用JavaScript预定义的charCodeAt()方法获取该字符的Unicode编码:
然后以36为倍数不断取余数:

那么不断求得的余数,可以通过下面公式反算出原编码值:
有了这种算法,就可以实现字符与加密数值之间的相互转换。如果定义一个密钥:
var key =“0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ”;
把余数定位到密钥中某个下标值相等的字符上,这样就实现了加密效果。反过来,如果知道某个字符在密钥中的下标值,然后反算出被加密字符的Unicode编码值,就可以逆推出被加密字符的原信息。
我们设定密钥是以36个不同的数值和字母组成的字符串。不同密钥,加密解密的结果是不同的,加密结果以密钥中的字符作为基本元素。
具体加密字符串的方法如下:

解密字符串的方法如下:

最后,利用上面自定义的加密和解密方法来进行试验:
