异常检测 初识pyod TASK5
摘要:本次练习,采用了三个数据集,generate_data,breast cancer以及癫痫数据集,对于feature bagging ,使用breast cancer数据集,探索提高基分类器的个数,发现测试集的precision @ n 的精度先升高后下降,后来针对基分类器的个数,画出了breast cancer数据集的曲线。该开始没有控制train_test_split的random_state,没有单一变量,所以结果不对,但是后来发现,控制完以后,每次的结果也是不一样的。但是大部分情况下,曲线是比较稳定的,偶尔会有一个小的上冲,随后下降。基分类器的数目,只要影响的是训练集的precision @ n所以,基本上,选择默认的个数就可以了,也可能存在一定概率会有更好的可能性。random_state会影响最后的结果,尤其对于异常数目较少的数据。
目录
- 1.笔记
-
- 1.1 简介
-
- 1.1.1 维度诅咒
- 1.2 Feature Bagging
-
- 1.2.1简介
- 1.2.2 基检测器
- 1.2.3 组合方法
- 1.3 Isolation Forests
-
- 1.3.1 简介
- 1.3.2 原理
- 1.3.3 步骤
- 2.练习
-
- 2.1 feature bagging
-
- 2.1.1 Generate data
- 2.1.2 breast cancer(10 abnormal)
- 2.1.3 癫痫数据集
- 2.2 Isolation Forests
-
- 2.2.1 generate data
- 2.2.2 breast cancer(10 abnormal)
- 2.2.3癫痫数据集
- 2.3 思考题:feature bagging为什么可以降低方差?
- 2.4 思考题:feature bagging存在哪些缺陷,有什么可以优化的idea?
- 3.附件
1.笔记
1.1 简介
这一节主要讲的是,高维数据的异常检测,包含三个部分:简介维度诅咒,以及两种方法(Feature Bagging和Isolation Forests)的详细论述。

1.1.1 维度诅咒
这部分讲述了维度诅咒的含义,以及解决方案。

1.2 Feature Bagging
这部分主要讲解了简介、基检测器以及组合的方法
1.2.1简介
主要简介集成方法的分类,方差与偏差
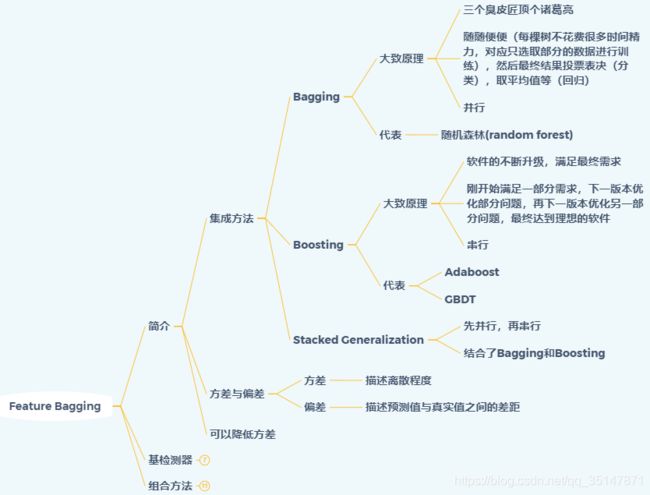
1.2.2 基检测器
主要讲述常用算法以及通用算法流程

1.2.3 组合方法
主要有两种方法,第一种是广度优先的方法,第二种是平均法。第一种理解起来比较有难度,建议看原文,在本文最后附件里面。
- 主要就是,某种算法算出所有样本的异常得分之后,是进行了排序的
- 然后依次选出异常得分最大的样本(已经选出的,不再选),直到选出数据集样本数目个样本。也相当于把所有算法得出的异常分数,进行降序排列,依次选择,选过的样本不再选,每一个异常得分都会对应一个异常的索引,索引到原始数据集里面的对应样本。
- 字符有时候容易搞混,建议带入具体数值进行理解

1.3 Isolation Forests
1.3.1 简介

1.3.2 原理

路径的计算,是在经过多少次分类的次数+调整值,调整值是如果树的高度达到上限了,那么这个调整值代表的就是还没有建立的树所对应的路径。
1.3.3 步骤

2.练习
2.1 feature bagging
画图均采用前两个维度的数据,因此,有的图,可能有的奇怪
2.1.1 Generate data


2.1.2 breast cancer(10 abnormal)
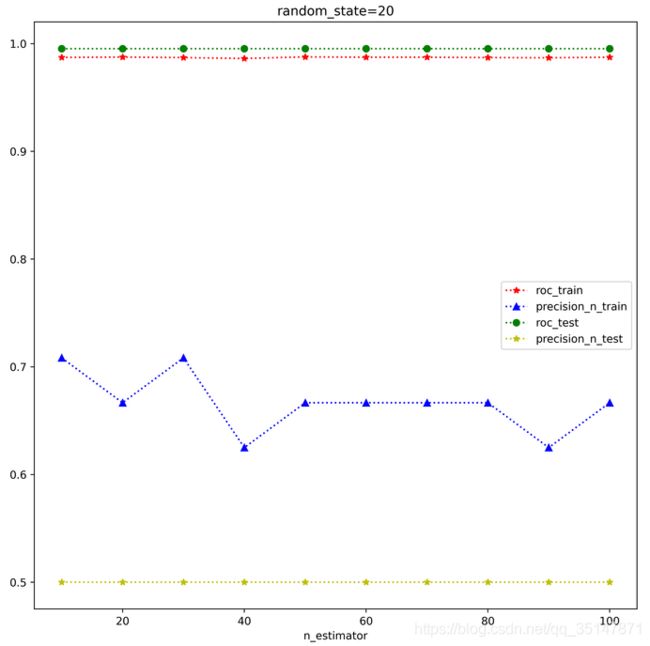
提高基分类器的个数,可以提高测试集的精度,之前大概0.6左右,现在可以0.8,偶尔1.0(极端情况,测试集就一个异常值),但是再增高的话,精度反而降低了


n_estimators 从10到100,间隔10,roc,precision @ n,在训练集和测试集上面的表现。每个estimator,做三次实验,取平均值。发现取值为30的时候是precision @ n最好的时候。这次结果错误的原因是,没有控制train_test_split的random_state,控制好以后,结果大致是稳定的,n_estimator=100做了两次,小数据集,受到random_state的应先还是比较大的,尤其是异常的个数很少的时候,受到n_estimator影响较小。






2.1.3 癫痫数据集


2.2 Isolation Forests
2.2.1 generate data

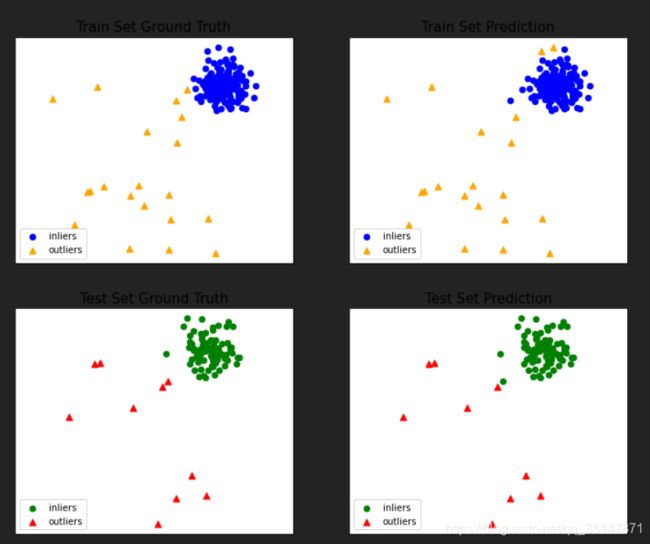
2.2.2 breast cancer(10 abnormal)

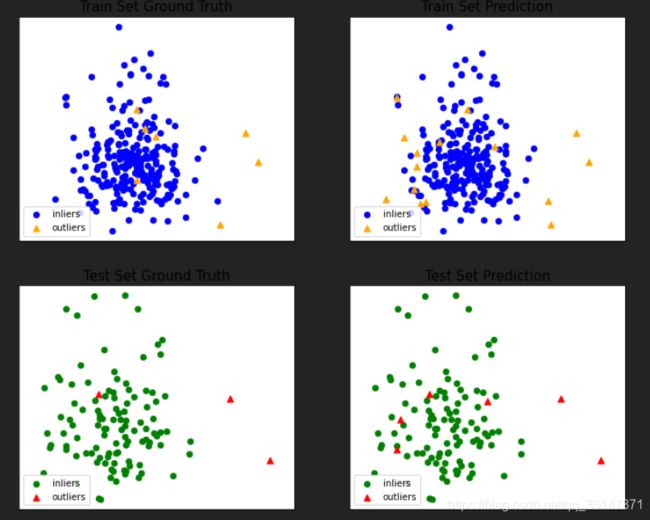
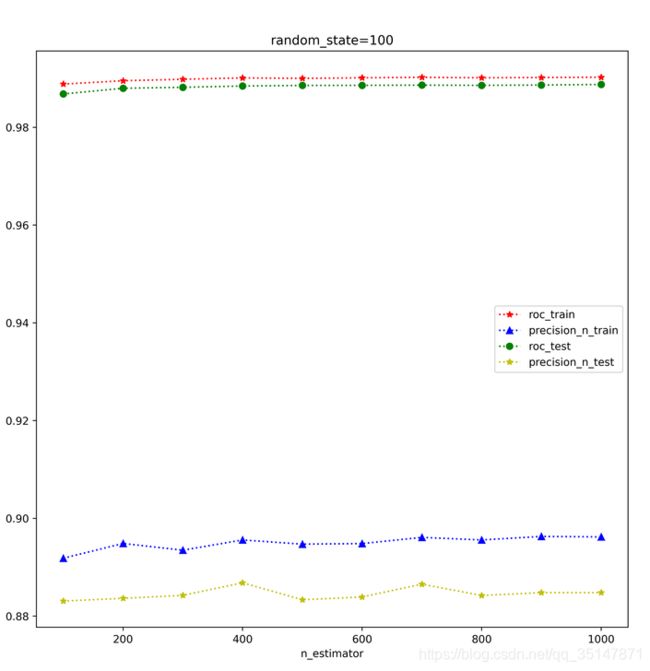
2.2.3癫痫数据集
n_estimators影响很小,从100-1000间隔100


2.3 思考题:feature bagging为什么可以降低方差?
因为变量之间具备相关性,不是完全独立的
为什么说bagging是减少variance,而boosting是减少bias? - 过拟合的回答 - 知乎
2.4 思考题:feature bagging存在哪些缺陷,有什么可以优化的idea?
超高维度的话,有些维度,也可能是一直不被选中的;
从d/2到d-1之间不再是随机的了,采用二分法进行
评估的算法,没有规定。
可以使用不同类型的算法,也可以针对数据集,采取某些算法
3.附件
特征选择原文(英文)
孤立森林原文(英文)
思维导图.xmind
feature bagging jupyter 代码
iForest jupyter 代码