关系抽取RE的一些最新论文解读(三)
文章目录
- 0. 引言
- 1. A General Framework for Information Extraction using Dynamic Span Graphs (NAACL2019)
-
- 1.1 摘要
- 1.2 动机
- 1.3 贡献
- 1.4 模型
- 1.5 实验结果
- 2. Entity, Relation, and EE with Contextualized Span Representations(emnlp2019)
-
- 2.1 摘要
- 2.2 动机
- 2.3 贡献
- 2.4 模型
- 2.5 实验结果
- 3. CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning (aaai2020)
-
- 3.1 摘要
- 4. Effective Modeling of Encoder-Decoder Architecture for Joint Entity and Relation Extraction (aaai 2020)
- 5. Span-based Joint Entity and Relation Extraction with Transformer Pre-training(arxiv2019)
-
- 5.1 摘要
- 5.2 动机
- 5.3 贡献
- 5.4 模型
- 5.5 实验结果
- 6. Exploiting the Syntax-Model Consistency for Neural Relation Extraction(acl2020)
- 7. Few-shot relation extraction via bayesian meta-learning on relation graphs (icml2020)
0. 引言
我们前面已经分别介绍了文档级的RE和多重关系的RE,在19年、20年的相关工作已经讲解了大约15篇论文,但是还有一些论文并不属于上联两个范畴,也是一些最新的并且参考价值比较高的论文,我们将在这个博客上整理这些工作,均为ACL、EMNLP、AAAI等顶会的19年/20年论文。
1. A General Framework for Information Extraction using Dynamic Span Graphs (NAACL2019)
1.1 摘要
我们为使用动态构造的span图共享span表示,来为信息提取任务提出了一个通用框架。这些图是通过选择最可信的实体范围,并用信任加权的关系类型和共指关系连接这些节点来构建的。动态span图允许在图中传播共引用和关系类型信任,以迭代地细化span表示。这与以前用于信息提取的多任务框架不同,在以前的多任务框架中,任务之间的惟一交互是在共享的第一层LSTM中。我们的框架在跨反映不同领域的多个数据集的多信息提取任务上显著优于最先进的技术。我们进一步观察到,跨度枚举方法擅长于检测嵌套的跨度实体,在ACE数据集上有显著的F1得分改进。
1.2 动机
- 系提取(RE)涉及到在对跨越之间分配关系类型。协同引用解析组将对同一实体的引用扩展到一个集群中。因此,我们可能会认为从一项任务中学到的知识可能会有益于另一项任务。
1.3 贡献
在本文中,我们介绍了一个通用框架动态图IE (DYGIE),用于通过共享跨度表示来耦合多个信息抽取任务**,这些跨度表示利用了来自关系和协引用的上下文化信息。我们的框架在几个领域中都是有效的,这说明了合并从关系和共引用注释中学到的更广泛的上下文的好处**。
DYGIE使用多任务学习,通过动态构造的跨度图共享跨度表示来识别实体、关系和关联。图中的节点从一束高度自信提及中动态选择,并根据关联类型或共引用的置信度分数对边缘进行加权。与只共享本地上下文中的跨度表示的多任务方法不同,我们的框架通过共引用和关系链接传播信息,利用了丰富的上下文跨度表示。
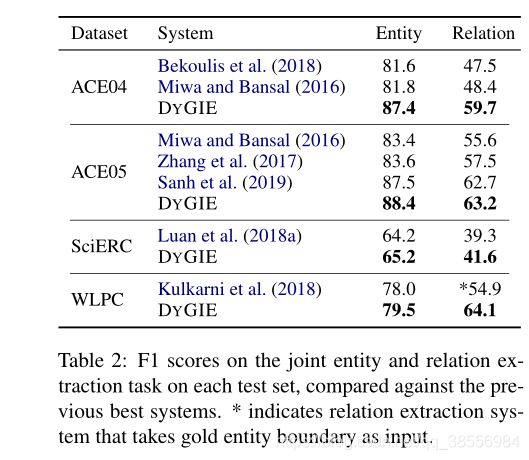
这篇论文有三方面的贡献。1)我们引入动态跨度图框架作为传播全局上下文信息的方法,使代码公开。2)我们证明联合实体和关系框架明显优于先进的检测任务在四个数据集。3)我们进一步表明,我们的方法擅长检测实体与重叠的跨越,实现改进F1的8分在三个基准与重叠范围注释:王牌2004,ACE GENIA 2005和。
1.4 模型
在本节中,我们将概述DYGIE框架的主要组件和层,如图2所示。图的构造和细化过程将在下一节中详细介绍。

Token Representation Layer
我们在输入令牌上应用双向LSTM。每个token的输入是GLOVE字符表示,输出token表示是通过堆叠正向和反向LSTM隐藏状态获得的。
Span Representation Layer
得到字符的编码后,用枚举的方式列举出所有可能的span,对于每个span 使用字符特征和宽度特征的拼接作为其向量表达 g i 0 g^0_i gi0。
Coreference Propagation
得到初始的span向量表示后,接下来先进行共指传播。
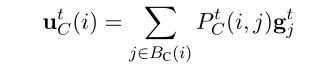
Relation Propagation
共指传播后,再进行关系传播,关系传播的方式和共指传播类似。

Updating Span Representations with Gating
为了计算下一个迭代的span表示,我们定义一个选门向量,以确定是否保留之前的跨度表,和是否来整合来自共参考或关系更新向量的新信息。
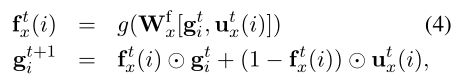
Final Prediction Layer
我们利用关系图层的输出来预测实体标签E和关系标签r。对于实体,我们将 g i N + M g^{N+M}_i giN+M传递给前馈网络预测实体信息;对于关系,我们将 g i N + M g^{N+M}_i giN+M和 g N + M g^{N+M} gN+M的连接传递给一个FFNN,以产生每类关系得分。实体和关系分数跨标签空间标准化。对于共参照,从共参照图层输出 ( g i N , g j N ) (g^N_i,g^N_j) (giN,gjN)中计算跨度对之间的分数,然后对所有可能的前件进行归一化。
Training
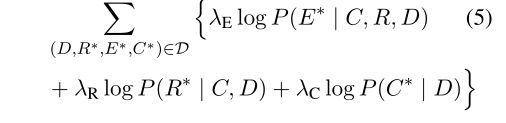
1.5 实验结果
2. Entity, Relation, and EE with Contextualized Span Representations(emnlp2019)
2.1 摘要
我们为三个信息提取任务检查了一个统一的,多任务框架的能力:命名实体识别,关系提取,和事件提取。我们的框架(称为DYGIE++)通过枚举、精炼和评分文本范围来完成所有任务,这些文本范围旨在捕获本地(句子内)和全局(跨句子)上下文。我们的框架在来自不同领域的四个数据集上实现了所有任务的最新成果。我们通过实验比较不同的技术来构造跨度表示。像BERT这样的上下文化嵌入在捕获相同或相邻句子中实体之间的关系方面表现良好,而动态跨度图更新了远程交叉句子关系的模型。例如,通过预测的共引用链接传播跨度表示,可以使模型消除具有挑战性的实体提及的歧义。
2.2 动机
2.3 贡献
在本文中,我们研究了在一般的多任务IE框架中纳入全局上下文的不同方法,建立在先前基于spans的IE方法的基础上。我们的DYGIE++框架,如图1所示,枚举候选文本并使用上下文语言模型和通过文本范围图传递的特定于任务的消息更新对它们进行编码。我们的框架实现了三个IE任务的结果状态,利用了两种上下文化方法的好处。
2.4 模型

Token encoding
使用BERT使用方法表示token
Span enumeration
通过连接表示文本左端点和右端点的标记,以及学习过的span-width嵌入,枚举并构造文本的span。
Span graph propagation
根据模型当前对文档中跨度之间关系的最佳猜测,动态生成一个图结构。根据图传播的三种不同形式,通过对图中相邻的跨度表示进行积分来更新每个span representation。在共指传播中,一个span在图中的邻居是它可能的共参前件。在关系传播中,邻居是句子中相关的实体。在事件传播中,有事件触发节点和事件参数节点;触发器节点将消息传递给它们可能的参数,而参数将消息传递回它们可能的触发器。整个过程是端到端的训练。
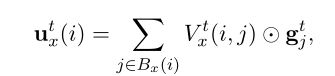
Multi-task classification
用两层前馈神经网络(FFNN)作为评分函数。对于span gi的触发器和命名实体预测,我们计算 ( g i ) (g_i) (gi)。对于共指、关系和参数角色预测,我们将相关的嵌入对连接起来,计算 ( [ g i , g j ] ) ([gi,gj]) ([gi,gj])。
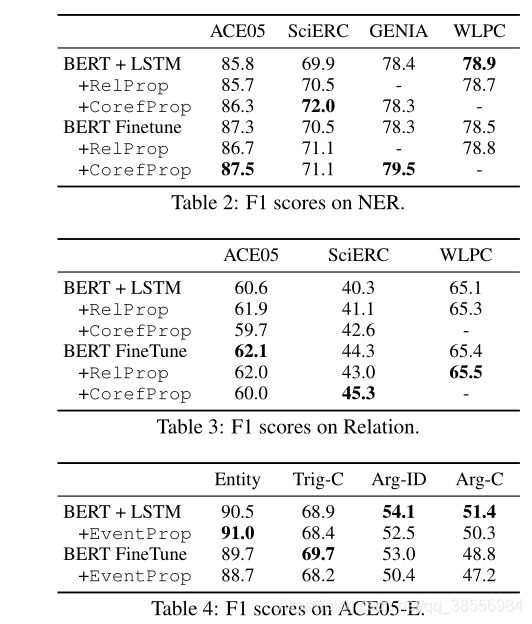
2.5 实验结果
3. CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning (aaai2020)
3.1 摘要
由于实体和关系的联合提取在两种任务中都具有较高的性能,因此受到了广泛的关注。在现有的方法中,CopyRE是一种有效且新颖的方法,它使用序列到序列的框架和复制机制直接生成关系三联。然而,它有两个致命的问题。该模型在区分头尾实体方面非常薄弱,导致实体提取不准确。它也不能预测多token实体(例如Steven Jobs)。针对这些问题,我们分析了实体提取不准确的原因,并提出了一种简单但非常有效的模型结构来解决这一问题。此外,我们提出了一个带有复制机制的多任务学习框架,称为CopyMTL,以允许模型预测多个token实体。实验揭示了CopyRE的问题,并表明我们的模型在NYT和WebNLG (F1得分)上取得了显著的改进,分别提高了9%和16%。
4. Effective Modeling of Encoder-Decoder Architecture for Joint Entity and Relation Extraction (aaai 2020)
5. Span-based Joint Entity and Relation Extraction with Transformer Pre-training(arxiv2019)
5.1 摘要
我们引入了一个用于基于span的联合实体和关系提取的关注模型SpERT。我们的主要贡献是对BERT嵌入的轻量级推理,其特征是实体识别和过滤,以及使用本地化的、无标记上下文表示的关系分类。该模型使用强句内负样本进行训练,这些负样本在单次BERT pass中被有效地提取出来。这些方面促进了对句子中所有跨度的搜索。在消融研究中,我们证明了预训练、强负采样和局部环境的好处。在联合实体和关系提取方面,我们的模型在几个数据集上的表现比之前的工作高出2.6% F1分。
5.2 动机
这项工作研究了Transformer网络用于关系提取的使用,提出了一种以BERT为核心的联合实体和关系提取模型。采用基于span的方法:任何标记子序列(或span)构成一个潜在的实体,任何一对span之间都可以保持关系。
5.3 贡献
我们的贡献如下:
-
提出了一种基于spans的联合实体和关系的提取方法。我们的方法看似简单但有效,始终比之前的工作多出2.6%(关系提取F1得分)。
-
我们调查了几个对我们的模型成功至关重要的方面,表明(1)来自同一个句子的负样本产生的训练既高效又有效,而且足够多的强负样本是至关重要的。(2)局部上下文表示是有益的,特别是对于较长的句子。(3)我们还发现了对预训练模型进行微调,比从零开始训练的效果更好。
5.4 模型

Span Classification
我们的span分类器采用一个任意的候选span作为输入。设 s = ( e i , e i + 1 , … , e i + k ) s= (ei,ei+1,…,ei+k) s=(ei,ei+1,…,ei+k)表示这样一个张成空间。此外,我们假设E是一组预定义的实体类别,如person或organization。span分类器将span s映射到 E ∪ n o n e E∪{none} E∪none中的一个类。none表示不成立的跨度。
我们从一个专用的嵌入矩阵中查找一个宽度嵌入wk+1(蓝色),它包含一个固定大小的嵌入。这些嵌入是通过反向传播来学习的,并且允许模型在跨度宽度上合并一个先验(注意跨度太长不太可能表示实体)。
![]()
最后,我们添加了分类器标记c(图1,绿色),它表示整个句子(或上下文)。上下文是消除歧义的一个重要来源,因为关键字(如spouse或said)是实体类(如person)的有力指示符。span分类器的最后输入是:
![]()
此输入输入softmax分类器,它为每个实体类(包括. none)生成一个后验值:
![]()
Span Filtering
通过查看得分最高的类,跨度分类器的输出估计了每个跨度属于哪个类。我们使用一种简单的方法过滤分配给none类的所有span,只留下一组spans,它们可能构成实体。注我们预先过滤跨度超过10个标记,将跨度分类的代价限制在O(n)。
Relation Classification
设R是一组预定义的关系类。关系分类器处理从S×S中抽取的实体的每个候选对(s1, s2),并估计是否存在来自R的任何关系。分类器的输入由两部分组成:
关联分类器的输入也是通过将上述特征连接起来得到的。注意-因为关系通常是不对称的-我们需要对(s1, s2)和(s2, s1)进行分类,即输入变成:
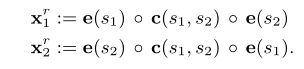
![]()
给定可信阈值,任何与得分≥可测的关系都被认为是激活的。如果没有激活,则假设该句子表示两个实体之间没有已知的关系。
Training
![]()
我们使用所有标记实体Sgtas的正样本,加上一个固定数目的随机非实体跨度的Neof作为负样本。例如,鉴于判决“1913年,奥运传奇人物(杰西•欧文斯)出生在(奥克维尔,阿拉巴马州)。”我们会抽取负样本,比如" Owens “或” born in "
在训练关系分类器时,我们使用ground truth关系作为正样本,从那些没有标记任何关系的实体对S * S中提取Nrnegative样本。例如,给定一个包含两个关系(“Marge”,妈妈,“Bart”)和(“Bart”,老师,“Skinner”)的句子,没有连接的实体对(“Marge”,*,“Skinner”)构成了任何关系的否定样本。我们发现,与随机跨度对抽样相比,如此强烈的负抽样是重要的。
5.5 实验结果
