论文阅读课3-GraphRel: Modeling Text as Relational Graphs for(实体关系联合抽取,重叠关系,关系之间的关系,自动提取特征)
文章目录
- abstract
- 1.Introduction
- 2.相关工作
- 3.回顾GCN
- 4.方法
-
- 4.1第一阶段
-
- 4.1.1 Bi-LSTM
- 4.1.2 Bi_GCN
- 4.1.3 实体关系抽取
- 4.2 第二阶段
-
- 4.2.1 构建关系权图
- 4.3训练
- 4.4 inference
- 5.实验
-
- 5.1 settings
- 5.1.1数据集
- 5.2 baseline and evaluation metrics
- 5.3 Quantitative Results
- 5.4 细节分析
Fu, T.-J., et al. (2019). GraphRel Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. Proceedings ofthe 57th Annual Meeting ofthe Association for Computational Linguistics.
原文code
https://www.cnblogs.com/conghuang/p/11923788.html
abstract
本文提出了一种基于图卷积网络(GCNs)的端到端关联抽取模型GraphRel,该模型利用图卷积网络(GCNs)联合学习命名实体和关联。与以前的基线相比,我们通过关系加权的GCN来考虑命名实体和关系之间的相互作用,以更好地提取关系。利用线性和依赖结构提取文本的序列特征和区域特征,利用完整的词图提取文本所有词对之间的隐含特征。使用基于图的方法,对重叠关系的预测比以前的顺序方法有了很大的改进。我们在两个公共数据集上评估GraphRel: NYT和WebNLG。结果表明,GraphRel在大幅度提高查全率的同时,保持了较高的查全率。同时,GraphRel比之前的工作分别高出3.2%和5.8% (F1分数),实现了一种新的关系提取技术。
- GraphRelFu, T.-J., et al. (2019).:
- 实体关系联合抽取
- 关系加权的GCNs
- 考虑实体关系间的相互作用
- 线性核依赖结构->文本的序列特征和区域特征
- 完整的词图:->提取文本所有词对之间的隐含特征
- 基于图的方法,有利于对重叠关系的预测
- 数据集:NYT,WebNLG
- 三个关键
- 想要自动提取特征的联合模型
- 通过堆叠Bi-LSTM语句编码器和GCN (Kipf和Welling, 2017)依赖树编码器来自动学习特征
- 用以考虑线性和依赖结构
- 类似于Miwa和Bansal(2016)(一样是堆叠的)
- 每个句子使用Bi-LSTM进行自动特征学习,
- 提取的隐藏特征由连续实体标记器和最短依赖路径关系分类器共享。
- 然而,在为联合实体识别和关系提取引入共享参数时,
- 它们仍然必须将标记者预测的实体提及通过管道连接起来,
- 形成关系分类器的提及对。
- 类似于Miwa和Bansal(2016)(一样是堆叠的)
- 考虑重叠关系
- 如何考虑关系之间的相互作用
- 2nd-phase relation-weighted GCN
- 重叠关系(常见)
- 情况
- 两个三元组的实体对重合
- 两个三元组都有某个实体mention
- 推断
- 困难(对联合模型尤其困难,因为连实体都还不知道)
- 情况
- 想要自动提取特征的联合模型
- work
- 学习特征
- 通过堆叠Bi-LSTM语句编码器和GCN (Kipf和Welling, 2017)依赖树编码器来自动学习特征
- 第一阶段的预测:
- GraphRel标记实体提及词,预测连接提及词的关系三元组
- 同时,用关系权重的边建立一个新的全连接图(中间图)
- 指导:关系损失和实体损失
- 第二阶段的GCN
- 通过对这个中间图的操作
- 考虑实体之间的交互作用和可能重叠的关系
- 对每条边进行最终分类
- 在第二阶段,基于第一阶段预测的关系,我们为每个关系构建完整的关系图,并在每个图上应用GCN来整合每个关系的信息,进一步考虑实体与关系之间的相互作用。
- 学习特征
- 本文贡献
- 我们的方法考虑了线性和依赖结构,以及文本中所有词对之间的隐含特征;
- 我们对实体和关系进行端到端的联合建模,同时考虑所有的词对进行预测;
- 仔细考虑实体和关系之间的交互。
1.Introduction
提取具有语义关系的实体提及对,即像 (BarackObama, PresidentOf, UnitedStates)这样的三元组是信息提取的中心任务,它允许从非结构化文本中自动构建知识。尽管这方面的研究很重要,但在一个统一的框架中,还有三个关键的方面需要全面处理
- 三个关键
- 实体识别和关系提取的端到端联合建模
- 预测重叠关系,即,共同提及的关系;
- 考虑关系之间的相互作用,尤其是重叠关系。
传统上,使用pipeline方法首先使用指定的实体识别器提取实体提及,然后预测每对提取的实体提及之间的关系(Zelenko,et al., 2003; Zhou et al., 2005; Chan and Roth, 2011).
联合实体识别和关系提取模型(Yu和Lam, 2010;Li and Ji, 2014;Miwa和Sasaki, 2014;Ren等人,2017)已经建立了利用这两个任务之间的密切互动。在展示联合建模的优点的同时,这些复杂的方法是基于特征的结构化学习系统,因此严重依赖于特征工程。
- 早期的联合模型
- 严重依赖于特征
随着深度神经网络的成功,基于神经网络的特征自动学习方法被应用到关系提取中。这些方法使用CNN、LSTM或Tree-LSTM对两个实体提及之间的单词序列进行处理(Zeng et al., 2014;dos Santos等,2015),两个实体提及之间的最短依赖路径(Yan et al., 2015; Li et al., 2015),或the minimal constituency sub-tree spanning two entity mentions(Socher et al., 2012),为每对实体提及编码相关信息。然而,这些方法并不是实体和关系的端到端联合建模。他们假设实体提及是给定的,并期望在管道中需要一个命名实体识别器时显著降低性能。
- 自动学习特征的神经网络方法(非联合模型)
- CNN、LSTM或Tree-LSTM对两个实体提及之间的单词序列进行处理(Zeng et al., 2014;dos Santos等,2015)
- 两个实体提及之间的最短依赖路径(Yan et al., 2015; Li et al., 2015)
- the minimal constituency sub-tree spanning two entity mentions(Socher et al., 2012),为每对实体提及编码相关信息
关系提取的另一个挑战是如何考虑关系之间的相互作用,这对于重叠关系尤其重要,即,关系共享共同实体提及。
例如,(BarackObama, PresidentOf, UnitedStates)可以从(BarackObama, Governance, UnitedStates)中推出;据说这两个三元组实体对重叠了。
另一种情况是,前三个词也可以从(巴拉克·奥巴马,LiveIn,白宫)和(白宫,总统官邸,美国)推断出来,后两个词有单一的重合之处。尽管在知识库完成中很常见,但是这种交互,无论是通过直接推断还是间接证据,对于联合实体识别和关系提取模型来说都是特别困难的,因为实体并不存在于输入中。事实上,尽管Zheng等人(2017)提出了一种基于LSTM序列标记器的实体与关系的强神经端到端联合模型,但它们必须完全放弃重叠关系。
- 两个挑战
- 想要自动提取特征的联合模型
- 如何考虑关系之间的相互作用
- 重叠关系(常见)
- 情况
- 两个三元组的实体对重合
- 两个三元组都有某个实体mention
- 推断
- 困难(对联合模型尤其困难)
- 情况
- 自动学习特征的方法
- Zheng等人(2017)提出了一种基于LSTM序列标记器的实体与关系的强神经端到端联合模型
- 放弃了重叠关系
- Zheng等人(2017)提出了一种基于LSTM序列标记器的实体与关系的强神经端到端联合模型
在本文中,我们提出了一种用于实体识别和关系提取的神经端到端联合模型GraphRel,它是处理关系提取中所有三个关键方面的第一个模型。GraphRel通过堆叠Bi-LSTM语句编码器和GCN (Kipf和Welling, 2017)依赖树编码器,学会自动提取每个单词的隐藏特征。然后GraphRel标记实体提及词,预测连接提及词的关系三元组,这是为第一阶段预测。
为了优雅地预测三元关系,同时考虑到它们之间的相互作用,我们在GraphRel中添加了一个2nd-phase relation-weighted GCN。在实体损失和关系损失的指导下,第一阶段的GraphRel沿着依赖链接提取节点隐藏特征,同时建立一个新的具有关系加权边的全连通图。然后,通过对中间图进行操作,第2阶段的GCN在对每条边进行最终分类之前,有效地考虑实体之间的交互作用和(可能重叠的)关系。对于GraphRel,我们的贡献有三
- work
- 学习特征
- 通过堆叠Bi-LSTM语句编码器和GCN (Kipf和Welling, 2017)依赖树编码器来自动学习特征
- 第一阶段的预测:
- GraphRel标记实体提及词,预测连接提及词的关系三元组
- 同时,用关系权重的边建立一个新的全连接图(中间图)
- 指导:关系损失和实体损失
- 第二阶段的GCN
- 通过对这个中间图的操作
- 考虑实体之间的交互作用和可能重叠的关系
- 对每条边进行最终分类
- 学习特征
- 本文贡献
- 我们的方法考虑了线性和依赖结构,以及文本中所有词对之间的隐含特征;
- 我们对实体和关系进行端到端的联合建模,同时考虑所有的词对进行预测;
- 仔细考虑实体和关系之间的交互。
2.相关工作
- Miwa和Bansal(2016):
- 本文模型的BiLSTM-GCN编码器部分类似于Miwa和Bansal(2016)提出的BiLSTM-TreeLSTM模型,因为它们也是堆叠的序列上的依赖树,用于联合建模实体和关系。每个句子使用Bi-LSTM进行自动特征学习,提取的隐藏特征由连续实体标记器和最短依赖路径关系分类器共享。然而,在为联合实体识别和关系提取引入共享参数时,它们仍然必须将标记者预测的实体提及通过管道连接起来,形成关系分类器的提及对。
- Zheng,et al(2017)
- 与在以前的工作中试图把每一对提到分类的工作不同,Zheng,et al。(2017)将关系提取和实体识别问题一样作为一个序列标注问题(NovelTagging)。这使他们关系提取的LSTM解码器的Bi-LSTM编码器。然而,尽管在《纽约时报》的数据集上显示出可喜的成果,他们的力量来自于专注于孤立的关系,完全放弃在数据集中出现少的重叠关系。
- 相比之下,提出所有类型的关系而被GraphRel以端到端的方式联合建模识别。
- Zeng等(2018)提出了一种端到端序列到序列的关系提取模型。
- 编码:它们使用一个Bi-LSTM对每个句子进行编码,
- 解码:并使用最后一个编码器隐藏状态初始化一个(一个解码器)或多个(多解码器)LSTMs,
- 以便动态解码关系三元组。
- 解码时,通过选择一个关系并从句子中复制两个单词来生成三元组。
- eq2seq设置部分处理三元组之间的交互。
- 然而,关系之间的相互作用只能通过在生成新关系时考虑以前生成的带有强制线性顺序的三元组来单向捕获。
- 在Graph-rel中,我们在LSTM-GCN编码器的基础上,采用2dn-phase的GCN来实现自动学习链接的字图上的实体和关系信息的传播。
- 近年来,在自然语言处理(NLP)任务中,GCN考虑依赖结构已经得到了广泛的应用。
- Marcheggiani和Titov(2017)将GCN应用于语义角色标记的单词序列。
- Liu等(2018)通过GCN对长文档进行编码,进行文本匹配。
- Cetoli等人(2016)将RNN和GCN结合起来识别命名实体。
- 也有一些作品(Peng et al., 2017;Zhang等,2018;Qian等。2019; Luan et al., 2019) 考虑词序列的依存结构进行关系提取。
- 在GrpahRel中,不仅将Bi-LSTM和GCN堆叠起来考虑线性和依赖结构,还采用了2nd-phase关系加权的GCN来进一步建模实体和关系之间的交互
3.回顾GCN
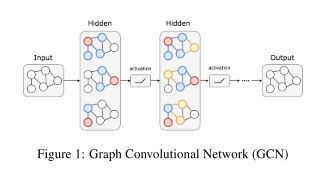
图卷积网络(Graph convolutional neural network, CNN) (Kipf and Welling, 2017)是卷积神经网络(convolutional neural network, GCN)的一种,它对相邻节点的特征进行卷积,并将一个节点的信息传播给最近的邻居。如图1所示,通过叠加GCN层,GCN可以提取每个节点的区域特征。
GCN层通过考虑相邻节点的特征来获取新的节点特征,其计算公式如下:
- h i k + 1 = f ( Σ u ∈ v ( i ) ( W k h u k + b k ) ) h_i^{k+1}=f(\Sigma_{u\in v(i)}(W^kh_u^k+b^k)) hik+1=f(Σu∈v(i)(Wkhuk+bk))
4.方法
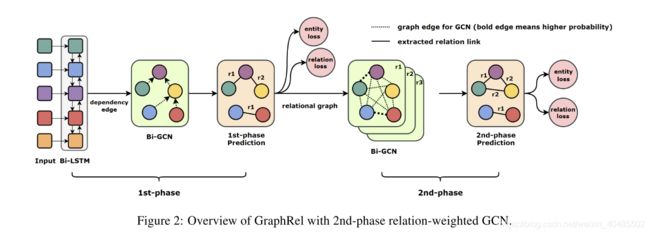
所提出的包含两阶段预测的GraphRel整体结构如图2所示。
- 在第一个阶段,
- 我们采用bi-RNN来提取序列,
- 用Bi-GCN来提取区域依赖词特征。
- 依据上述单词特征,我们预测每个单词对的关系和所有单词的实体。
- 在第二阶段,
- 基于预测的第一阶段关系,
- 我们为每个关系构建完整的关系图,
- 并在每个图上应用GCN来整合每个关系的信息,
- 进一步考虑实体与关系之间的相互作用。
4.1第一阶段
第一阶段:依据最先进的文本特征提取器(Marcheggiani和Titov, 2017;为了同时考虑序列依赖和区域依赖,我们首先使用双向RNN提取序列特征,然后使用双向GCN进一步提取区域依赖特征。然后,根据提取的词特征,预测每个词对与词实体之间的关系。
4.1.1 Bi-LSTM
- 输入:单词u的单词嵌入Word(u)+词性嵌入POS(u)
- 嵌入矩阵:
- 单词:glove
- 词性:随机初始化,一起训练
- 嵌入矩阵:
- 公式: h u 0 = W o r d ( u ) ⊕ P O S ( u ) h_u^0=Word(u)⊕POS(u) hu0=Word(u)⊕POS(u)
- ⊕??异或?只是个连接符号
4.1.2 Bi_GCN
由于原始输入句是一个序列,没有内在的图结构,就像Cetoli et al.(2016),我们使用依赖解析器为输入句创建一个依赖树。我们使用依赖树作为输入句子的邻接矩阵,使用GCN提取区域依赖特征。
最初的GCN是为无向图设计的。考虑到传入和传出的word特性,我们遵循Marcheggiani和Titov(2017),实现bi-GCN
- 输入:句子的依赖树的邻接矩阵
- 公式:
- h → i k + 1 = R e L U ( Σ u ∈ ( v → ( i ) ( W → k h u k + b → k ) ) \stackrel{\rightarrow}{h}_i^{k+1}=ReLU(\Sigma_{u\in (\stackrel{\rightarrow}{v}(i)}(\stackrel{\rightarrow}{W}^kh_u^k+\stackrel{\rightarrow}{b}^k)) h→ik+1=ReLU(Σu∈(v→(i)(W→khuk+b→k))
- h ← i k + 1 = R e L U ( Σ u ∈ v ← ( i ) ( W ← k h u k + b ← k ) ) \stackrel{\leftarrow}{h}_i^{k+1}=ReLU(\Sigma_{u\in \stackrel{\leftarrow}{v}(i)}(\stackrel{\leftarrow}{W}^kh_u^k+\stackrel{\leftarrow}{b}^k)) h←ik+1=ReLU(Σu∈v←(i)(W←khuk+b←k))
- h i k + 1 = h ← i k + 1 ⊕ h ← i k + 1 {h}_i^{k+1}=\stackrel{\leftarrow}{h}_i^{k+1}⊕\stackrel{\leftarrow}{h}_i^{k+1} hik+1=h←ik+1⊕h←ik+1–concatenate
4.1.3 实体关系抽取
利用从bi-RNN和bi-GCN中提取的词特征,预测词的实体,并提取每对词之间的关系。对于单词实体,我们根据1层LSTM上的单词特征对所有单词进行预测,并应用分类损失(categorical loss,记为eloss1p)对它们进行训练。
- 输入:上面的特征
- 损失:分类损失函数–记做 e l o s s 1 p eloss_{1p} eloss1p
- 预测词的实体
- 提取每一对词的关系
- 对于关系提取,我们删除了依赖边并对所有的词对进行预测。对于每个关系r,我们学习了权值矩阵 W r 1 , W r 2 , W r 3 W^1_r, W^2_r, W^3_r Wr1,Wr2,Wr3,并计算了关系倾向score
- s c o r e ( w 1 , r , w 2 ) = W r 3 R e L U ( W r 1 h w 1 ⊕ W r 2 h w 2 ) score(w1,r,w2)=W_r^3ReLU(W_r^1h_{w1}⊕W_r^2h_{w2}) score(w1,r,w2)=Wr3ReLU(Wr1hw1⊕Wr2hw2)
- 正向和反向不同
- 无关系score(w1,null,w2)
- 概率 P r ( w 1 , w 2 ) = s o f t m a x ( s c o r e ( w 1 , r , w 2 ) ) P_r(w1,w2)=softmax(score(w1,r,w2)) Pr(w1,w2)=softmax(score(w1,r,w2))
- 无三元组计数约束
- 损失函数:利用 P r ( w 1 , w 2 ) , 记 做 r l o s s 1 p P_r(w1,w2),记做rloss_{1p} Pr(w1,w2),记做rloss1p
因为我们提取每个词对之间的关系,所以我们的设计不包含三元组计数限制。通过研究每个词对之间的关系,GraphRel标识尽可能多的关系。利用Pr(w1, w2),我们也可以计算出这里的关系范畴损失,记为rloss1p。请注意,虽然eloss1p和rloss1p都不是最终预测,但它们也是训练第一阶段图形的良好辅助损失。
4.2 第二阶段
在第一阶段提取的实体和关系不考虑彼此。为了考虑命名实体和关系之间的相互作用,并考虑文本中所有词对之间的隐含特征,我们提出了一个新颖的2nd-phase关系加权GCN来进一步提取。
- 2nd-phase relation-weighted GCN
- 希望
- 考虑实体和关系之间的相互作用(这一部分说的)
- 考虑关系之间的关系(前面说的)
- 希望
4.2.1 构建关系权图
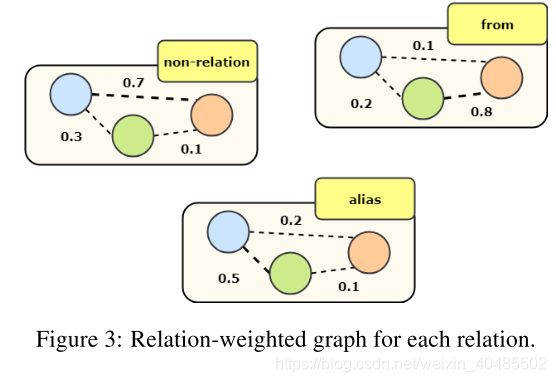
- 对每一个关系
- 依据 P r ( w 1 , w 2 ) P_r(w1,w2) Pr(w1,w2)(作为边权)构建图(一个关系一个图)
- 对每一个图用Bi-GCN
- h u k + 1 = R e L U ( Σ v ∈ V Σ r ∈ R P r ( u , v ) × ( W r k h v k + b r k ) ) + h u k h_u^{k+1}=ReLU(\Sigma_{v\in V}\Sigma_{r\in R}P_r(u,v)\times(W_r^kh_v^k+b_r^k))+h_u^k huk+1=ReLU(Σv∈VΣr∈RPr(u,v)×(Wrkhvk+brk))+huk
- 考虑出度和入度两个方向
- 第二阶段的Bi-GCN考虑关系权重的传递并且从每个词中提取出更充足的信息
- 再分类
- 对得到的新的特征,在进行一次命名实体识别和关系分类,可以得到更稳定的庴预测。
- 损失函数: e l o s s 2 p , r l o s s 2 p eloss_{2p},rloss_{2p} eloss2p,rloss2p
4.3训练
在RelGraph中,我们使用了两种类型的损失:实体损失和关系损失,它们都属于分类损失(categorical loss)。对于实体损失,我们使用传统的标记(Begin, Inside, End, Single, Out)。每个单词都属于这五个类中的一个。eloss1p和eloss2p的ground-truth实体标签是相同;在训练过程中,我们使用交叉熵作为分类损失函数。
- 实体识别:
- 标签:(Begin, Inside, End, Single, Out)
- 损失:交叉熵(分类损失
- 对eloss1p和eloss2p来说,ground-truth的实体(标准答案)是相同的
- 关系抽取
- 使用one-hot关系向量对每一个单词对
- 既然我们是基于词组来预测关系,那么ground truth(标准答案)也应该基于词组。
- 也就是说,word United与word Barack和word Obama都有“总统”的关系,word States也是如此。
- 我们认为,这种基于单词对的关系表示为GraphRel提供了它需要学习提取关系的信息。对rloss1p和rloss2p来说,groundtruth(标准答案)关系向量是相同的。
- 作为实体损失,我们也使用交叉熵作为训练中的分类损失函数。
- 对于eloss和rloss,我们为类内的实体或关系项添加了额外的double-weighted。
- 总的损失: l o s s a l l = ( e l o s s 1 p + r l o s s 1 p ) + α ( e l o s s 2 p + r l o s s 2 p ) loss_{all}=(eloss_{1p}+rloss_{1p})+\alpha(eloss_{2p}+rloss_{2p}) lossall=(eloss1p+rloss1p)+α(eloss2p+rloss2p)
- 以end-to-end的方式最小化loss
4.4 inference
在推理过程中,基线预测的方法是头部预测,一个关系(BarackObama,PresidentOf, UnitedStates)被提取当且仅当BarackObama和UnitedStates都被标识为提及的实体,且总统(PresidentOf)有最大的可能P(Obama,States)
- head prediction:
- 关系被提取的前提:
- 两个实体均被识别
- 且Pr(e1,e2)最大
- 关系被提取的前提:
另一种可能更稳定的基线提取方法是平均预测,即考虑实体提及对之间的所有词对,并确定具有最大平均概率的关系。
- 平均预测
- 一对实体提及对的所有词对的概率平均最大的关系
最后,我们提出一种阈值预测方法,该方法仍然以独立的方式考虑实体提及对的所有词对。例如,如果2/4分布都认为最可能的类是PresidentOf,然后三元组(BarackObama,PresidentOf, UnitedStates)被提取当且仅当2/4 = 50% >θ,θ是一个自由的阈值参数。这种方式,用户可以选择他们喜欢的精度和召回权衡通过调整θ。在实验中,如果未指定,阈值推理与θ= 0。
- threshold阈值预测
- 独立地思考实体提及对的所有词对
- 实体提及对中的所有词对中有θ以上占比认为此关系最有可能,则提取此关系
5.实验
5.1 settings
- 输入embedding:
- word embedding:glove-300d
- pos embedding:15d,随机初始化
- concate作为输入
- 词性标注和依赖树:spaCy(Honnibal and Johnson, 2015)
- 1st-phase
- bi-LSTM:256 units
- bi-GCN:256 feature size,2 layer
- 2nd-phase
- 关系权重的bi-GCN:1-layer,256 feature size
- 训练
- LSTM:dropout=0.5
- lr=0.0008
- 损失函数中的 α \alpha α=3
- 优化器:adam optimizer
- pytorch
5.1.1数据集
- NYT
- 用于
- 传统信息抽取
- 开放信息抽取
- 远程监督
- 介绍
- NYT数据集是关于远程监督关系抽取任务的广泛使用的数据集。该数据集是通过将freebase中的关系与纽约时报(NYT)语料库对齐而生成的。纽约时报New York Times数据集包含150篇来自纽约时报的商业文章。抓取了从2009年11月到2010年1月纽约时报网站上的所有文章。在句子拆分和标记化之后,使用斯坦福NER标记器(URL:http://nlp.stanford.edu/ner/index.shtml)来标识PER和ORG从每个句子中的命名实体。对于包含多个标记的命名实体,我们将它们连接成单个标记。然后,我们将同一句子中出现的每一对(PER,ORG)实体作为单个候选关系实例,PER实体被视为ARG-1,ORG实体被视为ARG-2。
- GraphRel用
- 用于
- WebNLG
- python
-
- GraphRel用
- GraphRel用
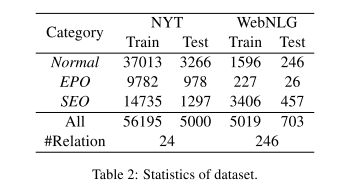
们使用NYT (Riedel et al., 2010)和WebNLG (Gardent et al., 2017)的数据集来评估所提出的方法。作为NovelTagging和多译码器,对于《纽约时报》,我们过滤超过100个单词的句子;对于WebNLG,我们在实验中每次只使用第一个句子。NYT和WebNLG的统计数据如表2所示。
我们将关系三元组分为三类:正常关系、实体对重复的关系(EPO)和单个实体重复(SPO)的关系。每个类别的计数也显示在表2中。由于一个实体属于几个不同的关系,因此,整型和单型重叠是比较困难的任务。我们在详细分析中讨论了不同类别的结果。
5.2 baseline and evaluation metrics
- baseline
- NovelTagging (Zheng et al., 2017)
- 一个序列标记器,它预测每个句子词的实体和关系类
- MultiDecoder (Zeng et al., 2018). (最先进的方法)
- 将关系提取看作一个seq-seq问题,使用动态解码器提取关系三元组
- oneDecoder(出自同一篇)
- NovelTagging (Zheng et al., 2017)
- evaluation metrics
- 作为两个基线,我们采用标准F1评分来评价结果。
- 当且仅当两个对应实体的关系和头部均与标准答案相同时,预测的三元组才被认为是正确的。
5.3 Quantitative Results

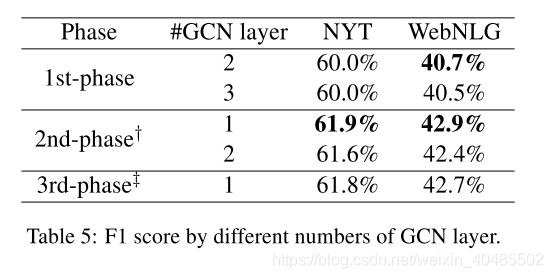
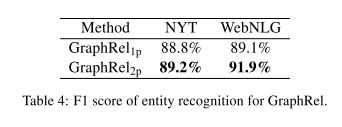
- GraphRel1p比baseline好:因为同时获得了顺序和区域依赖词的特征,因此它在精度和召回率方面都有更好的表现,从而获得更高的F1分数。
- GraphRel2p更好的原因:考虑名称实体和关系之间的交互
- 从NYT和WebNLG的结果中,我们发现GCN的区域依赖特征和2期预测在精度、召回率和F1分数方面都有助于关系预测。
- NovelTagging和MultiDecoder都使用sequence结构。
- 因为NovelTagging假设一个实体属于单一关系,所以精确度高,但回忆率低。
- MultiDecoder使用动态的解码器生成关系三元组。由于对RNNrolling的固有限制,它能生成的三元组数目有限。
- 但是,对于GraphRel,因为我们预测每个词对之间的关系,所以我们不受这个限制。我们认为GraphRel是最平衡的方法,因为它保持了较高的精确度和较高的召回率,可以产生较高的F1分数。
5.4 细节分析
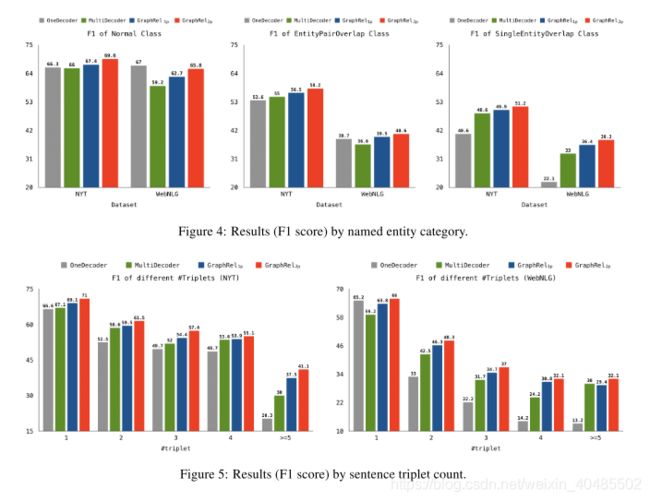
- 对于GraphRel,正如我们预测所有单词对的关系一样,所有单词都可以与其他单词有关系:因此实体重叠不是问题。
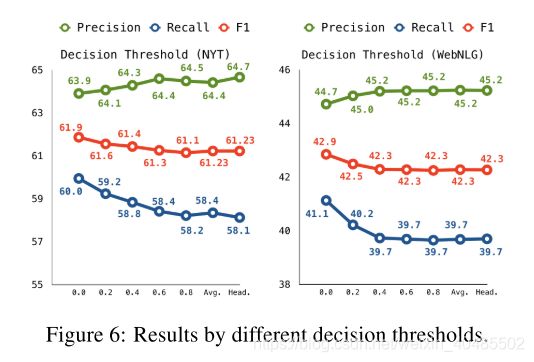
- 用阈值好
可以看出阈值推理方法有效地调整之间的权衡精度和召回θ的不同的选择。通过减少阈值从0.8->θ= 0,召回明显分别增加了1.8%和1.4%在纽约时报和WebNLG,只有边际损失0.6%的精度。该阈值方法的有效性使其在两个数据集上都达到了最佳性能,超过了头和平均水平。