R-CNN,Fast R-CNN,Faster R-CNN Mask R-CNN论文阅读
写在前面的话
原本打开2018何凯明团队发表在CVPR上的论文《Learning to segment everything》,发现这篇论文是基于Mask R-CNN,打开Mask R-CNN发现前面还有Faster R-CNN,Fast R-CNN,R-CNN。初入深度学习做图像分割,所以就从R-CNN看起,打个基础。对文章可能有理解不对的地方,欢迎指正讨论。
R-CNN

R-CNN是Ross Girshick 2014年在CVPR上提出的。所谓R-CNN,就是Regions with CNN features。下面介绍一下算法的整体思路:输入一张图片,
- 利用selective research生成1k~2k个region proposals
- 把region proposals warp 成227*227大小,送入到CNN网络中输出4096维的特征向量
- 把CNN输出的特征向量送入一组SVM挨个进行二分类(有N类,就有N个SVM)
- Bounding-box regression对候选框进行位置精修
Bounding Box Regression
这个部分一开始没看懂,参考了这位博主的博客,觉得写的很好,贴上链接供参考。
1.训练
R-cnn训练有三个步骤:
-
Supervised pre-training:有监督预训练,就是迁移学习。先拿模型在ILSVRC2012 classification数据集上进行分类训练,此网络提取的特征为4096维,之后送入一个4096->1000的全连接层进行分类。用训练好的参数来初始化训练真正训练集的模型,这样解决了训练集数据太少的问题。
-
Domain-specific fine-tuning:微调训练。微调训练网络和前面预训练网络结构相同,只是把最后一层4096->1000的全连接换成4096->N+1(文章中N=20)的全连接层。learning rate为0.001,每个mini-batch有128张图片,包含32张正样本和96张负样本。正负样本来自selective research生成的2k个proposal regions,与对应图片上所有ground-truth框的Iou大于等于0.5为正样本,其余的为负样本。
-
Object category classifiers:分类器训练。SVM训练的数据也是来自selective research生成的2k个proposal regions,与上面不同的是,这里的Iou阈值为0.3,Iou大于等于0.3的为正样本,其余的为负样本。SVM训练时输入正负样本在CNN网络计算下的4096维特征,输出为该类的得分,训练的是SVM权重向量。由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本。
2.测试
非极大值抑制:在测试阶段,一张图片生成的2k张proposal regions通过网络和svm分类后,每一类所”剩下“的框可能不止1个,为了找出最符合条件的候选框,文章中采用了非极大值抑制的方法,去除重叠区域较大的框。假设某一类最后通过SVM后按照得分排序有有A,B,C,D,E,F六个候选框,那么我们首先把得分最高的F框确定为输出框,剩下的A,B,C,D,E五个框分别计算与F框的Iou,如果大于我们设定的阈值,则去除。假设A,B两个框大于设定阈值,则去除A,B两个框。剩下C,D,E三个框,再选取这三个框中的分最大的E,E为第二个输出的框,计算C,D与E的Iou,去除与E重叠Iou大于阈值的框,重复上述步骤。
Fast R-CNN
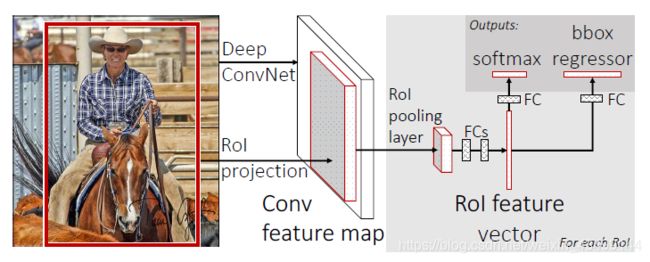
R-CNN虽然在当时目标检测精度得到很大提升,但是还是有很多缺点。比如生成的2k个候选框全部要送入CNN学习实在太浪费时间,所以2015年又提出了Fast -CNN。Fast R-CNN主要贡献是提出了ROI pooling,多任务联合loss,实现了end to end的模型。Fast R-CNN主要流程:
- 利用selective research生成1k~2k个region proposals
- 把整张image输入CNN网络,得到feature map
- 找到每个region proposal映射在feature map上的ROI(Region of Interest),将ROI输入到ROI pooling layer得到固定大小的feature map,再送入后面两个全连接层
- 再分别送入两个全连接层输出特征向量,然后分别送入两个损失层,利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置
ROI pooling: 为什么要进行ROI pooling?为了生成固定大小的图片。因为后面的全连接层要求输入固定长度的特征向量,
假设一张M * H的图片,想输出m * h大小的图片,把M * H大小的原始图片的宽平均分成 m份,长平均分成h份,则M * H的图片被平均分成m * h个小区域,对每个区域做最大池化,最后生成m*h大小的特征图。
Multitask loss:
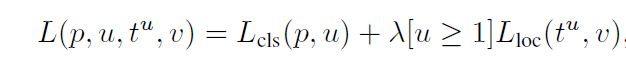
第一项是softmax loss,u表示ground-truth类别,p表示预测类别。
第二项是bbox regression loss。[u>=1]表示当u>=1时时此项为1,即RoI边框修正是对于非背景(框中至少含有1类)的RoI而言的,文章中,上式的λ取1。
训练
mini-batch 分层采样: 与R-CNN不同的是,Fast R-CNN训练时的训练样本不是随机从不同图片选取,文章中采用分层采样的方法,一个mini-batch的128张ROI来自两张图片,每张图片采样64张。文章中把与ground-truth重叠Iou大于等于0.5的设置为正样本,标签为u>=1。Iou在[0.1,0.5)之间的设置为负样本,标签为u=0。每个mini-batch有25%正样本。
Faster R-CNN
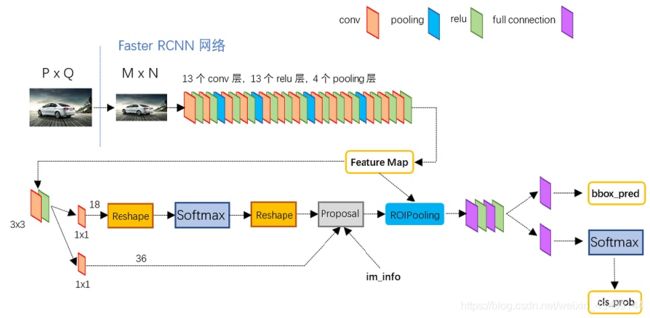
图片来自:https://zhuanlan.zhihu.com/p/31426458
Fast R-CNN与R-CNN相比虽然提升了速度,但是每张图片selective research生成2k个ROI依然很耗时,所以2016年的Faster R-CNN又对此做了改进。这篇文章的主要创新就是提出了RPN(Region Proposal Network ),直接生成待检测区域。Faser R-CNN主要流程:
- 整张图片输入CNN主网络得到feature map,该feature maps被共享用于RPN层和后续全连接层
- 卷积特征输入到RPN,得到region proposal
- 找到每个region proposal映射在feature map上的ROI(Region of Interest),将ROI输入到ROI pooling layer得到固定大小的feature map,再送入后面两个全连接层
- 再分别送入两个全连接层输出特征向量,然后分别送入两个损失层,利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置
RPN(Region Proposal Network )

RPN输入是CNN主网络输出的feature map,输出是一组矩形框。上图中,主网络输出的256维的conv feature map输入到RPN中,然后在feature map上滑动一个out number =256的3* 3的卷积层(因为feature map 是原图经过缩放和下采样之后的,文章中3* 3的滑动窗口有171个像素的感受野),每个窗口都输出一个256维的feature,并且每个滑动窗都会产生9个anchor。这个时候就分为两路,一路把输出的256维feature输入到一个out number =18的1 * 1的卷积层,输出18维的特征向量(9个anchor,每个都可分为前景和背景两类),再经过softmax loss层对anchor进行分类;另外一路经过一个1* 1的卷积层,输出36维的特征向量(9个anchor,每个anchor有4个坐标),再经过bbox regression loss层对anchor进行精修。最后会输出一组带有前景的region proposal。
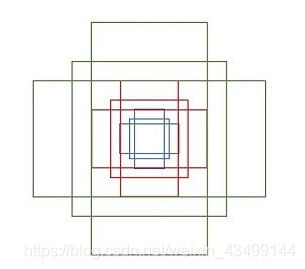
anchor: anchor其实就是矩形框,本文中每个滑动窗口会生成9个矩形窗,共有3种形状,长宽比为大约为 {1:1, 1:2, 2:1} 三种,如下图:
下图中,框架后面的部分就是Fast R-CNN的内容,生成的候选框和主网络生成的feature map送入ROI Pooling和之后的层进行分类和精修。
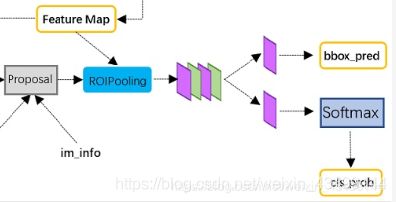
训练
Faster R-CNN的训练部分可参考知乎上这篇文章的第五节。
Mask R-CNN
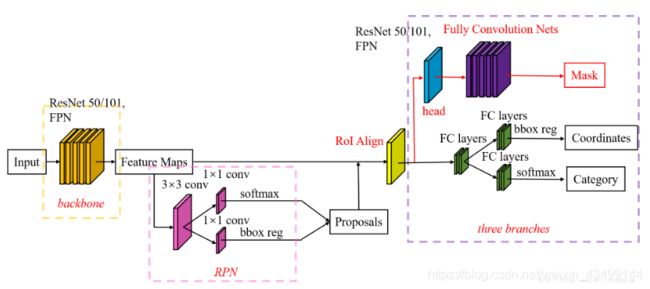
图片来自:https://blog.csdn.net/jiongnima/article/details/79094159
Mask R-CNN,顾名思义,可以输出mask的R-CNN。Mask R-CNN 在Faster R-CNN的基础上,加了一个分支,这个分支的主要工作是使feature map经过一个FCN,输出一张Mask图,实现了分割的任务。
另外由于分割需要较准确的像素位置,而Faster R-CNN方法中,在进行Roi-Pooling之前需要进行两次量化操作(第一次是原图像中的目标到conv5之前的缩放,比如缩放32倍,目标大小是600,结果不是整数,需要进行量化舍弃,第二次量化是比如特征图目标是55,ROI-pooling后是22,这里由于5不是2的倍数,需要再一次进行量化,这样对于Roi Pooling之后的结果就与原来的图像位置相差比较大了),因此作者对ROI-Pooling进行了改进,提出了RoI Align方法,在下采样的时候,对像素进行对准,使得像素更准确一些。
ROI Align
- 遍历每一个候选区域,保持浮点数边界不做量化
- 将候选区域分割成k * k个单元,每个单元的边界也不做量化
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作

Mask R-CNN的损失函数:
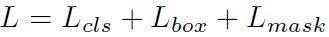
前两项loss和前面的是一样的,主要增加了一个L mask,网络最后会输出一个kmm的mask,k为类别数。L mask被定义为 average binary cross-entropy loss(平均二值交叉熵损失函数)。首先分割层会输出channel为k的Mask,每个Mask对应一个类别。在计算loss的时候,假如ROI对应的ground-truth的类别是Ki,则计算第Ki个mask对应的loss,其他mask对这个loss没有贡献。
在网上下载了Mask R-CNN 的代码,用训练好的模型运行了一下demo,附上图片:



感谢
第一次写博客,参考了很多文章,附上链接感谢大佬:
https://zhuanlan.zhihu.com/p/31426458
https://blog.csdn.net/chunfengyanyulove/article/details/83545784
https://blog.csdn.net/auto1993/article/details/78513907
https://www.cnblogs.com/CZiFan/p/9903518.html
https://blog.csdn.net/wopawn/article/details/52133338