DQN强化学习 MountainCar Deep Q-Learning
虽则你我被每粒星唾弃,我们贫乏却去到金喜。 ———七百年后
这篇文章关于神经网络的Qlearning实现,Qlearning的一些方法概念写在第一篇文章 “强化学习:Q表格方法”里:
文章链接: https://blog.csdn.net/weixin_43968987/article/details/112959287
对于Qlearning的方法,适用于动作空间是离散的环境,比如说象棋中的棋子,只能以有限的运动状态运动。
我们可以看到,使用表格的方法解决较为复杂的环境,很容易使得表格变得很大,因为表格中需要存储与环境交互的状态以便于查表更新。随着表格的增大,查表,权重更新等操作的效率会大为降低,使得训练智能体成为一大负担。这时候,就有人站出来了,提出了以神经网络代替表格的方法,就正式和表哥说拜拜了(如果是表妹说不定会舍不得)。
DQN算法有两大创新:
(1)神经网络代替Q表格:
神经网络代替表格使得Qlearning的方法可以用在更为复杂环境中,使得模型的训练更新更为细化简洁。神经网络有两个,一个是决策的网络,一个是Target网络。我近似把Target网络理解为一个“监督”的方法,在无监督的强化学习中,类似的产生一个“监督”,来使得决策网络的训练能正常进行。
(2)经验池的使用:
对于经验池,则是存储了智能体与环境的交互序列,可以看作一个队列,在一定容量的前提下存储了智能体与环境“最近”的交互数据。在模型训练时,用随机的取出一个batch的数据。它的使用增大了数据之间的非线性关系,使得模型收敛更为可行。
一.对于这次要用到的环境的介绍(MountainCar-v0):

(1)动作空间:

(2)观测值:
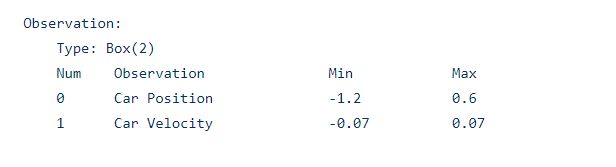
观测值着重要用到第一个,用来改进我们的Reward,后面会提到
(3)目的:
简单来说,就是驱动小车到达旗帜的位置,但是小车的动力不够,不能一次性到达,就得左右运动。就像我们小时候荡秋千,要荡的高,就要来回晃动。除非被猛推一把,但容易产生吃“粑粑”的奇观。
二.具体的实现(主体的分析我会写在代码注释里,我jo的结合来看更清晰一点)
from tensorflow.keras import Sequential,layers
from tensorflow.keras.models import load_model
from collections import deque
import numpy as np
import random
import gym #open ai 的开源强化学习库
class Agent(object):
def __init__(self,):
'''
初始化类的变量:为了简单我把学习率等参数直接写在了learn函数中
(1)steps记录与环境交互的次数,用来控制target网络的参数更新以及模型的训练
(2)var和e共同参与探索率的衰减
(3)model和target网络,model是决策的主体,target网络作为一个“监督”
(4)replay_memory是经验池
'''
self.steps = 0
self.var = 1e-1
self.e = 1e-5
self.Model = self.model_()
self.Target = self.model_()
self.replay_memory = deque(maxlen=1000)
def model_(self):
'''
定义决策网络,这里采用了两层“relu”作为激活函数的全连接层
最后一层不采取激活函数,也可使用linear,但用处不大
最后一层的神经元数量为输出的动作类型的数量,这个模型有三个动作
因此我们最后一层有三个神经元
编译使用了均方差作为loss函数,也可改用交叉熵等
'''
model = Sequential(name="DQN")
model.add(layers.Dense(100,"relu"))
model.add(layers.Dense(100,"relu"))
model.add(layers.Dense(3,None))
model.compile("adam","mse")
return model
def add(self,obs,action,reward,n_s,done):
'''
reward函数的选择很大程度上决定着模型的好坏
这里采用了reward的增值处理,当下一个动作使得小車
更靠右的时候(也就是达到更高的位置),增加回报
(reward)的数值
'''
if n_s[0]>0.2:
reward += n_s[0]*5
self.replay_memory.append((obs,action,reward,n_s,done))
def sample(self,obs):
'''
动作选择函数,根据决策网络选择动作
也有一定的概率随机选择动作,即探索
随着训练的进行,探索率会逐渐降低
'''
self.var -= self.e
if np.random.uniform() <= self.var:
return np.random.randint(3)
return np.argmax(self.Model.predict(obs))
def data(self):
'''
从经验池中选择数据,batch_size = 64
这里可以根据需要自行调整
每一条数据都包括五部分,即为
(观测值,动作,回报,下一个观测值,结束状态)
每次调用这个函数都返回一个batch的数据用来训练
'''
batch = random.sample(self.replay_memory,64)
Obs,Action,Reward,N_s,Done = [],[],[],[],[]
for (obs,action,reward,n_s,done) in batch:
Obs.append(obs)
Action.append(action)
Reward.append(reward)
N_s.append(n_s)
Done.append(done)
return np.array(Obs).astype("float32"),np.array(Action).astype("int64"),np.array(Reward).astype("float32"),\
np.array(N_s).astype("float32"),np.array(Done).astype("float32")
def learn(self):
'''
训练的主体
(1)与环境交互150次同步一哈target网络与决策网络的参数
即复制决策网络到target网络
(2)为了更高效的训练,在数据足够的前提下,每隔五步训练一次
(个人感觉tensorflow的优化要比paddlepaddle高效一些)
(3)通过obs得到Q,next_obs得到Target_Q,通过Q_learning的方法更新Q的
数据如果done为True,说明环境终止,不需要考虑下一个动作。否则依据
Q(s,a) <-- Q(s,a) + α{r + γ*max*Q(s', : ) - Q(s,a)}来更新Q
最后将更新好的Q作为“标签”来进行训练
'''
if self.steps % 150 == 0:
self.Target.set_weights(self.Model.get_weights())
if self.steps % 5 == 0 and len(self.replay_memory) >= 200:
#取出一个batch的数据
Obs,Action,Reward,N_s,Done = self.data()
Q = self.Model.predict(Obs.reshape(64,1,2))
Q_ = self.Target.predict(N_s.reshape(64,1,2))
#64为batch_size,我直接写在里面了
for i in range(64):
if Done[i]:
#0.01为学习率的大小
Q[i][0][Action[i]] = 0.01*Reward[i]
Q[i][0][Action[i]] = 0.01*(Reward[i] + 0.9*np.argmax(Q_[i][0]))
#Q[i][0][Action[i]] = 0.01*(Reward[i] + 0.9*np.amax(Q_[i][0]))
#训练决策网络
self.Model.fit(Obs.reshape(64,1,2),Q,verbose=0)
env = gym.make("MountainCar-v0")
agent = Agent()
Scores = []
for times in range(2000):
s = env.reset()
Score = 0
while True:
agent.steps += 1
a = agent.sample(s.reshape(1,1,2))
next_s, reward, done, _ = env.step(a)
agent.add(s,a,reward,next_s,done)
agent.learn()
Score += reward
s = next_s
if done:
Scores.append(Score)
print('episode:',times,'score:',Score,'max:',np.max(Scores))
break
#提前终止训练
if np.mean(Scores[-2:])>= -120:
agent.Model.save("car_2_1000.h5")
break
agent.Model.save("car_2_1000.h5")
三.训练结果:
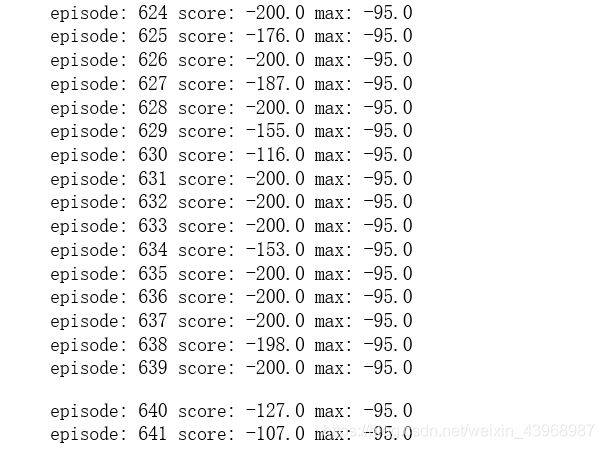
可以看到,训练在641轮终止,并保存了模型((-127-107)/2 > -120)
四.测试:
model_aim = load_model("car_2_1000.h5")
def Test():
s = env.reset()
score = 0
while True:
agent.steps += 1
a = np.argmax(model_aim.predict(s.reshape(1,1,2)))
next_s, reward, done, _ = env.step(a)
score += reward
s = next_s
env.render()
if done:
break
env.close()
return score
if "__main__":
All_scores = []
for i in range(5):
All_scores.append(Test())
print(np.mean(np.array(All_scores)))
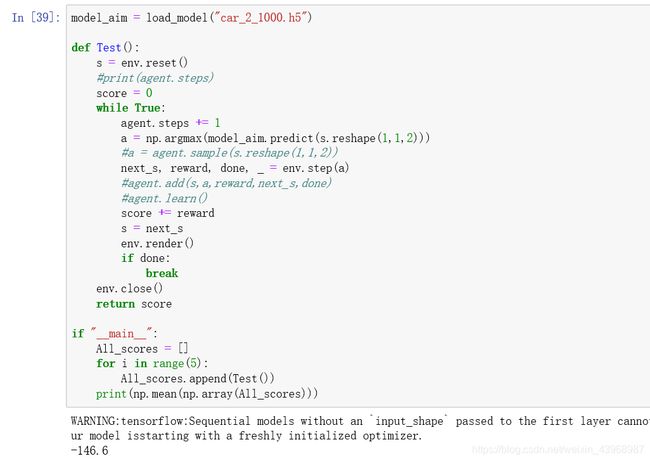
五轮训练得到了-146.6分
五.总结:
这里一定要提一下reward函数的定义,它的意义不可小觑,后面的文章也会着重介绍reward函数的作用。
此次文章是关于DQN的一个相对简单的尝试,但是本人水平能力有限,多有不足,还望大家批评指正,共同提高,感谢。