face_recognition库的安装以及学习
安装face_recognition库:
在pycharm的解释器的商店里直接搜 face-recognition
(注意不是face_recognition,这个搜不到的!!!)
然后安装就可以用了
一、load_image_file
这个方法主要用于要加载识别的人脸图像,加载返回的数据是Numpy数组。里面记录了图片的所有像素的特征向量。
二、face_locations
定位图中所有人脸的像素位置
- 返回值是一个列表形式,列表中每一行是一张人脸的位置信息,包括[top, right, bottom,
left],也可以理解为每个人脸就是一组元组信息。主要用于表示图像中的人脸信息。
load_image_file和face_locations方法的使用
import face_recognition
from PIL import Image
import cv2
# 1.通过load_image_file方法加载待识别的图像
image = face_recognition.load_image_file('C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/tianwang.jpg')
# 加载后的形式是Numpy 128维度的数组
print(image)
# 2.通过face_locations方法得到图像中所有的人脸的位置信息
face_loactions = face_recognition.face_locations(image)
print(face_loactions) #[(98, 184, 142, 141), (106, 265, 142, 229), (106, 101, 142, 65), (98, 347, 142, 304)]
# 因为有4个人,所以有4个元组
# 3.找到所有人脸,截出来
for face_loaction in face_loactions: # 得到每一个人脸的坐标信息[上,右,下,左]
top, right, bottom, left = face_loaction # 解包操作,得到每张人脸的位置信息
print("已识别到人脸部位,像素区域为:Top:{}, right:{}, bottom:{}, left:{}".format(top, right, bottom, left))
# 把每一个人的头像扣出来,抠图
# face_image = image[top:bottom, left:right] # 通过切片形式把坐标取出来
# pil_image = Image.fromarray(face_image) #使用PIL库的fromarray方法,生成一张图片
# pil_image.show()
start = (left, top) # 左上
end = (right, bottom) # 右下
# 在图片上绘制矩形框,从start坐标开始,end坐标结束,矩形框的颜色为红色(0,255,255),矩形框粗细为2
cv2.rectangle(image, start, end, (0, 255, 255), thickness=1)
cv2.imshow('window', image)
cv2.waitKey()


三、face_landmarks
返回人脸关键特征点
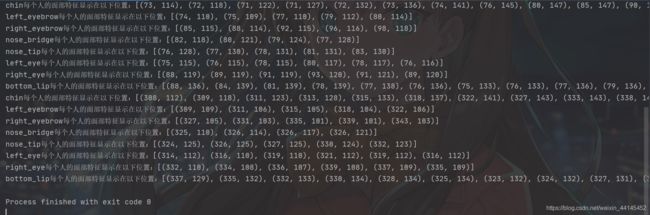
- 参数仍然是待检测的图像的对象,返回值是包含面部特征点所对应的字典的列表,列表长度就是图像中的人脸数
- 面部特征包括以下几个部分:chin(下巴)、left_eyebrow(左眼眉)、right_eyebrow(右眼眉)、nose_bridge(鼻梁)、left_eye、right_eye、nose_tip(人中或者下鼻部)、bottom_lip(下嘴唇)一共有68个特征点

- 勾勒脸部大体轮廓
face_landmarks方法运用实例:
import face_recognition
from PIL import Image, ImageDraw
import cv2
# 1.通过load_image_file方法加载待识别的图像
image = face_recognition.load_image_file('C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/tianwang.jpg')
# 2.接下来得到face_landmarks_list列表
face_landmarks_list = face_recognition.face_landmarks(image)
print(face_landmarks_list) # 里面都是每个人的特征字典
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image) # 生成一张PIL图像
# 对每一个人的特征点进行循环
for face_landmarks in face_landmarks_list:
facial_features = [ # 每个人的特征点通过数组的形式列出来
'chin',
'left_eyebrow',
'right_eyebrow',
'nose_bridge',
'nose_tip',
'left_eye',
'right_eye',
'bottom_lip'
]
for facial_feature in facial_features:
print("{}每个人的面部特征显示在以下位置:{}".format(facial_feature, face_landmarks[facial_feature]))
# 画线
d.line(face_landmarks[facial_feature], width=2) # 直接调用PIL中的line方法在PIL图片中绘制线条,帮助我们观察特征
pil_image.show()

四、face_encodings
获取图像文件中所有的面部编码信息–也是以向量形式保存的
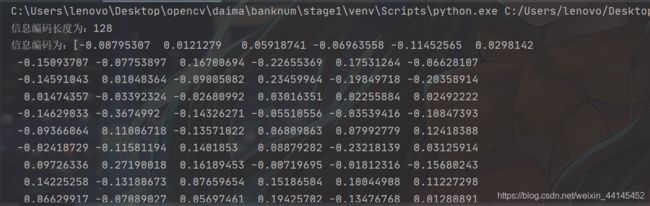
- 返回值是编码列表,参数仍然是要识别的图像对象。如果后续访问时,需要注意加上索引或者遍历来访问,每张人脸的编码是一个128维的向量。
- 面部编码信息是进行人像对比的重要参数。
face_encodings方法运用实例:
import face_recognition
from PIL import Image, ImageDraw
import cv2
image = face_recognition.load_image_file('C:/Users/lenovo/Desktop/opencv/daima/banknum/stage1/test_data/test1.jpg')
# 不管图像中有多少人脸信息,返回值都是一个列表
face_encodings = face_recognition.face_encodings(image)
for face_encoding in face_encodings:
print("信息编码长度为:{}\n信息编码为:{}".format(len(face_encoding), face_encoding))
cv2.imshow('window', image)
cv2.waitKey()

五、compare_faces
由面部编码信息进行面部识别匹配
- 主要用于匹配两个面部特征编码,利用两个特征向量的内积来衡量相似度,根据阈值来确认是否是同一个人。
- 第一个参数就是一个面部编码的列表(很多张脸或者一张脸)、第二个参数就是给出单个的面部编码(单人的一张脸),compare_faces会将第二个参数中的编码信息与第一个参数中的所有编码信息依次匹配,返回值是一个布尔列表,匹配成功则返回True,匹配失败则返回False,顺序与第一个参数中脸部编码顺序一致。

- 参数里有一个tolerance=0.6参数,大家可以根据实际效果进行调整,一般经验值是0.39,tolerance值越小,匹配越严格
compare_faces方法运用实例:
import face_recognition
from PIL import Image, ImageDraw
import cv2
# 加载一张合照
image1 = face_recognition.load_image_file('C:/Users/lenovo/Desktop/opencv/daima/banknum/stage1/test_data/test3.jpg')
# 加载一张单人照片
image2 = face_recognition.load_image_file('C:/Users/lenovo/Desktop/opencv/daima/banknum/stage1/test_data/test1.jpg')
# 拿到合照已知的的image1编码
known_face_encoding = face_recognition.face_encodings(image1)
# face_encodings返回的是列表类型,我们只需要拿到一个人脸编码即可
compare_face_encoding = face_recognition.face_encodings(image2)[0]
# 注意第二个参数,只能是单个面部特征编码,不能传列表
matches = face_recognition.compare_faces(known_face_encoding, compare_face_encoding, tolerance=0.39)
print(matches)
cv2.imshow('ymlkw', image1)
cv2.imshow('yangmi', image2)
cv2.waitKey()
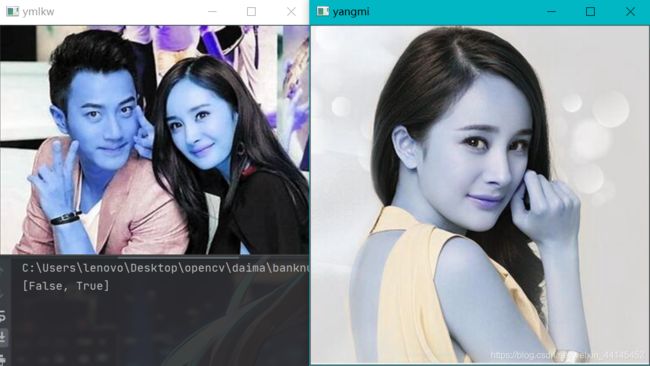
compare_faces返回值是一个布尔列表,匹配成功则返回True,匹配失败则返回False,顺序与第一个参数中脸部编码顺序一致。
在刘恺威和杨幂的图中,有True代表在合照中匹配到了杨幂