2019美赛C题论文解读
文章目录
- 题目分析
-
- 题目分析三步骤
- 题目翻译
- 解读
-
- 题干
- 问题
-
- 第1部分
- 第2部分
- 第3部分
- 第4部分
- 题目切入点及模型选择
-
- 针对第一问
-
- 数据清洗
- 可能出现的位置
- 文章撰写
题目分析
题目分析三步骤
- 这是个什么样的题
- 需要我们干什么
- 我们需要做什么
美赛的问题可能说的很模糊,很笼统,这就要我们自己去消化理解。
题目翻译


数据附件可在这里下载:2019美赛C题数据+O奖论文
解读
题干
他就是说在美国有个毒品叫阿片,然后给了我们两种数据。
一种数据是联邦、州和地方法医实验室分析的毒品案件的毒品鉴定结果和相关信息。就是给了五个州,然后这五个州下面有很多个县,每个县出现了毒品问题会有法医进行鉴定,然后将结果进行统计,比如有海洛因、大麻啥的,每出现一次就多一次计数。
第二种是7个zip文件为2010-2016年间每年人口普查时为这五个州的县收集的一些社会因素,包含了几百个因素指标。
问题
第1部分
让我们根据阿片这个毒品在美国五个州之间传播的特点,建立一个模型进而确定每个州开始使用特定阿片的任何可能位置。
如果阿片会按我们模型发展,这时美国政府应该特别关注哪些具体问题?在什么药物识别的阈值水平会发生这些问题?根据我们模型预测他将在何时何地发生?
第2部分
阿片的泛滥是什么导致的?为什么人们明明知道阿片有毒会上瘾,但仍然坚持使用?阿片的使用是否与人口普查中某些社会经济数据有关?如果是,请修改你的模型,以包含人口普查数据集中的任何重要因素。
第3部分
结合1、2部分的结果,找出对应阿片药物危机的可能策略,使用你的模型测试此策略的有效性。
第4部分
除了主报告外,还需要想组委会提交一份1-2页的备注,以总结你在DEA\NFLIS数据库总结发现的任何重要见解或结果。
题目切入点及模型选择
针对第一问

数据清洗
首先对己知数据进行筛选,观察附件中数据,对Drug Reports列进行主成分分析。不妨设小于等于5的事件为小概率事件。运用Exdal操作除去小概率事件,重新生成新的可靠数据。然后对合成阿片类药物x和事件总数的影响度y进行相关性分析,分别求出各种合成阿片类药物和y之间的线性关系。
根据熵权法在MATLAB环境下确定综合权系数 y = w 1 x 1 + w 2 x 2 + w 3 x 3 + w 4 x 4 + w 5 x 5 y=w1x1+w2 x2+w3 x3+w4 x4+w5 x5 y=w1x1+w2x2+w3x3+w4x4+w5x5,然后利用药物传播预测模型求解确定性微分方程,之后建立药物传播预测模型,从而建立确定性微分方程。
最后利用元胞自动机进行仿真处理,建立基于元胞自动机的药物传播预测模型,得出仿真曲线,从而求出合成阿片类药物和海洛因事件在给定五个州及其县之间的传播和特点,特定阿片类药物在给定五个州中任何可能开始使用的位置,以及按上述模型确定的特点和模式条件下未来可能出现的问题和药物鉴定阈值水平。最后利用上述模型预测它们发生的时间地点。
利用提供的美国人口普查社会经济数据,解决以下问题:
阿片类药物的使用如何达到目前的水平,谁在使用/滥用阿片类药物,是什么导致阿片类药物使用和成瘾的增长,以及为什么人们知道使用阿片类药物的危险,但仍然持续使用,人们提出了大量相互矛盾的假说来解释这些问题。该药物的使用或使用趋势是否与提供的某些美国人口普查的社会经济数据有关?如果是这样,请修改第1部分的模型以包含此数据集中的任何重要因素。
针对问题二,对附件中数据进行分析,通过观察每一- 年的人口普查数据,得到与题目相关的有效数据,将数据分类。再根据附件7个压缩包中所给的数据筛出规则,将相似类型的大类进行筛选合并,最终得到与社会经济相关的数据。对分析得到的数据和合成阿片类药物和海洛因事件进行相关性分析。分析后再利用熵权法以及负反馈的原理在MATLAB环境下对所有相关因素和海洛因事件的影响度y进行综合熵权。对问题二的结果进行仿真同时与问题一的仿真结果进行对比,观察改进程度。
可能出现的位置
根据NFLIS数据中阿片类毒品在美国五个州之间传播的特点,建立一个模型进而确定每个州开始使用特定阿片的任何可能位置。
- step1
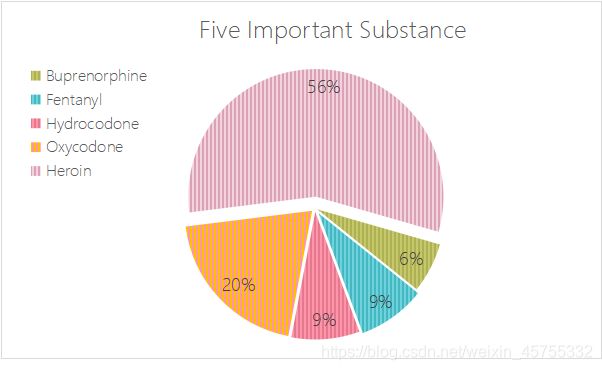
首先对已知数据进行筛选,观察附件中的数据,对Grug Reports这一列进行主成分分析。不妨设小于等于5的事件危机小概率事件,重新生成新的可靠数据。确定影响比较显著的五种阿片,分别为:Buprenorphine、Fentanyl、Hydrocodone、Oxycodone、Heroin
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_excel('MCM_NFLIS_Data.xlsx',sheet_name='Data')
data

name = set(data['SubstanceName'])
name = list(name)
# 创建一个字典保存SubstanceName的DrugReports所有值,
DrugReports_dick = {
}
for i in name:
DrugReports_dick[i] = sum(data[data['SubstanceName'] == i]['DrugReports'])
# print(DrugReports_dick)
# 然后进行排序提取前五个的值
DrugReports_dick = sorted(DrugReports_dick.items(), key=lambda item:item[1])
# 画一下所有数据
plt.figure(figsize=(10,10))
plt.scatter(np.arange(len(DrugReports_dick)),np.array(DrugReports_dick)[:,1],s=10,c="r",alpha=0.8)

DrugReports_five = np.array(DrugReports_dick)[-5:]
plt.figure(figsize=(10,10))
plt.pie(DrugReports_five[:,1],
autopct='%1.1f%%',
shadow=False,
startangle=150)
plt.title("Substance")
plt.savefig("Substance.png")
plt.legend(labels=DrugReports_five[:,0])
plt.show()
plt.savefig('five_pie.jpg')
2. Step2:
然后对合成阿片类药物和海洛因x和事件总数的影响度y进行相关性分析,分别求出各种合成阿片类药物和y之间的线性关系。根据 熵权法 在MATLAB环境下确定综合权系数 y = w 1 x 1 + w 2 x 2 + w 3 x 3 + w 4 x 4 + w 5 x 5 y=w1x1+w2x2+w3x3+w4x4+w5x5 y=w1x1+w2x2+w3x3+w4x4+w5x5
得出综合权系数 y = 0.78 x 1 − 1.41 x 2 + 0.58 x 3 + 0.49 x 4 + 0.56 x 5 y=0.78x_1-1.41x_2+0.58x_3+0.49x_4+0.56x_5 y=0.78x1−1.41x2+0.58x3+0.49x4+0.56x5;发现合成阿片类药物和海洛因事件的影响度y与x2呈负相关,且.x2相对 于其他四种因素对y影响程度大。
但我算的并没有-值,而且五个的权重几乎相同。
# 提取5个特征的 DrugReports所有值
five = []
for i in range(len(DrugReports_five)):
five.append(np.array(data[data['SubstanceName'] == DrugReports_five[:,0][i]]['DrugReports']))
p_ij = []
for i in five:
a = [x/sum(i) for x in i ]
print(a)
p_ij.append(a)
e_j = [- sum(i*np.log(i)) for i in p_ij]
w_j = [i/sum(e_j) for i in e_j]
[0.21362155593657947,
0.1580864454826483,
0.2208284846678793,
0.21451323648805518,
0.19295027742483767]
将人群分为五种,

a是单位时间的感染率

元胞自动机传染病模型


用较大的权重确定影响度Y的位置
计算五种药物的权重与总权重的比率
找出更大比例的毒品,找出位置
找出每种药物可能开始使用的位置









文章撰写

