利用 Python 分析城市各区域楼盘
文章目录
- 1. 项目目标
- 2. 信息爬取
-
- 2.1 房产网站 URL 分析
- 2.2 楼盘列表页爬取
- 2.3 楼盘详情页爬取
- 2.4 保存文件
- 2.5 提高代码运行速度
- 3. 数据分析
-
- 3.1 数据清洗
- 3.2 数据分析与可视化
- 4. 总结
- *5. 拓展
-
- 5.1 选择不同城市爬取分析
- 5.2 利用数据库进行存储
1. 项目目标
- 信息爬取:通过爬取某房产网站,得到重庆各楼盘的一些基本信息,包括楼盘名称,楼盘区域,参考价格,产权年限,开发商,物业公司,物业费,容积率,绿化率等信息
- 数据分析:利用 Pandas, Numpy 等数据分析库对数据进行清洗与整理,并分析数据得出结论
2. 信息爬取
2.1 房产网站 URL 分析
1. 基础 URL:
-
通过观察房产链接,可以看到其基础 URL 格式如下:
https://[city].fang.lianjia.com/loupan/ -
其中 city 为城市拼音首字母,例如重庆为 ‘cq’
2. 楼盘列表页:
-
楼盘列表页包含了楼盘名称和对应的楼盘代码,楼盘代码是楼盘详情页链接的组成部分,所以我们要先提取列表页的信息
-
观察可以发现,列表页的 URL 格式如下:
base_url + house_class + page -
其中:
- house_class = {‘全部’: ‘’, ‘住宅’: ‘nht1’, ‘别墅’: ‘nht2’, ‘写字楼’: ‘nht3’, ‘商业’: ‘nht4’, ‘底商’: ‘nht5’,},本次我们只分析住宅,所以选择 ‘nht1’
- page,页数,与 house_class 直接相连,没有任何分隔符,格式为 ‘pg’+number,一页 10 个楼盘,我们分析前 50 页
-
于是我们的列表页链接为:
pages = range(1, 51) my_list_url = base_url + my_house_class + page, page in pages 如:https://cq.fang.lianjia.com/loupan/nht1pg1
3. 楼盘详情页
-
观察可以发现,楼盘详情页的 URL 格式如下:
base_url + 'p_'+ 楼盘代码 + '/xiangqing/' -
可见关键部分为楼盘代码,这部分通过爬取列表页得到。通过观察列表页的源码,如下截图,我们可以在爬取楼盘列表页的时候使用 BeautifulSoup,利用 CSS 选择器,在楼盘列表页提取对应节点和楼盘代码。
selected = soup.select('ul.resblock-list-wrapper div.resblock-name a')

2.2 楼盘列表页爬取
1. 网页源码分析:
-
楼盘列表页中,我们只需要提取楼盘名称及其对应的 URL 代码即可,在 Chrome 中查看楼盘名称的源码,可以发现该文字链接在一个 a 节点中,完整的节点结构如下,在爬取的时候可以适当简化:
body > div.resblock-list-container.clearfix > ul.resblock-list-wrapper > li:nth-child(1) > div > div.resblock-name > a
2. 提取信息:
- 知道了楼盘名称及其代码的节点结构后,我们使用 BeautifulSoup 的 CSS 选择器来选中节点,并提取相关信息,存储到字典中,封装为函数后的代码如下:
def get_name_dic(url):
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
selected = soup.select('ul.resblock-list-wrapper div.resblock-name a')
name_dic = {
}
for item in selected:
name_dic[item.string] = item['href'][8:]
print('code of {} getted.'.format(item.string))
return name_dic2.3 楼盘详情页爬取
1. 网页源码分析
- 节点查找: 打开任意几个楼盘的详情页,观察网页结构及源码,发现我们需要的信息都在 class 为 x-box 的 ul 节点下面的 li 节点中,其中 ul 节点有两个,分别为基本信息和规划信息,前者包含参考价格,区域位置以及开发商,后者包含绿化率、容积率、产权年限等信息。
- 节点分析:
- 在 li 节点中,信息名称在 class 为 label 的节点中,信息值在 class 为 label-val 的节点中。
- 仔细观察发现,参考价格并没有在 li .label-val 节点中,而在其子节点中,不过没有关系,当我们使用 text 属性提取文本的时候,节点中的所有文本都会被提取出来。
- 对于区域名称也是一样的,即使城市名称和区域名称是分开的,我们可以都提取出来,在后面数据处理的时候统一处理,这样所有类型的信息提取方法都是一样的了。
2. 提取信息
- 我们同样使用 BeautifulSoup 的 CSS 选择器来选中节点,并提取相关信息,存储到字典中,封装为函数后的代码如下:
# 获取楼盘中需要的信息
def get_info(url):
soup = get_soup(url)
lis = soup.select('ul.x-box li')
infos = {
}
my_keys = ['参考价格:', '区域位置:', '绿化率:', '容积率:', '产权年限:', '开发商:', '物业公司:', '物业费:']
for li in lis:
if li.select('.label')[0].text in my_keys:
label = li.select('.label')[0].text.replace(':', '')
value = li.select('.label-val')[0].text.strip()
else:
continue
infos[label] = value
print('info getted')
return infos2.4 保存文件
- 由于我们保存的数据结构均为字典,这里我们先保存为 JSON 格式的文件(后面再拓展以下保存至数据库等)
- 注意中文字符在转换为 JSON 对象的时候要添加 ensure_ascii=False,否则会出现乱码
- 另外我们在每次写入后都添加了一个换行符,避免一行字符太多,方便后面逐行读取数据
- 封装后的代码如下:
def save_to_json(data, name='data'):
results = json.dumps(data, ensure_ascii=False)
with open(name + '.json', 'a+', encoding='utf-8') as f:
f.write(results)
f.write('\n')
return None2.5 提高代码运行速度
1. 第一版,效率低下
- 其实上面已经完成了爬取的基本模块,主函数如下,但是运行速度很慢,爬取 50 页,500 个楼盘花了约 6 分多钟,需要提高代码运行效率。
'''效率低下版'''
CITY = 'cq'
MY_HOUSE_CLASS = 'nht1'
PAGES = range(1, 51)
def main():
# 文件初始化
with open(CITY + '.json', 'w', encoding='utf-8') as f:
pass
base_url = 'https://{}.fang.lianjia.com/loupan/'.format(CITY)
houses = []
name_dic = {
}
start = ctime()
# 获取楼盘名称及代码
for page in PAGES:
print(page)
list_url = '{base}{house}pg{page}'.format(base=base_url, house=MY_HOUSE_CLASS, page=page)
name_dic.update(get_name_dic(list_url))
# 爬取各楼盘信息
for name, code in name_dic.items():
detail_url = base_url + code + 'xiangqing/'
my_info = get_info(detail_url)
my_info['楼盘名称'] = name
houses.append(my_info)
# 保存文件
save_to_json(houses)
end = ctime()
print('All done\nStarted at {}, done at {}'.format(start, end))2. 多线程版本
- 前段时间刚学习了使用 threading 模块实现多线程,在这个项目中,由于每页的爬取与存储是相对独立,互不干扰的,因此我们可以将每页的爬取与存储封装为一个函数,再使用 threading 模块实现多线程,使每页的工作同时进行。修改代码后,整个工作只使用了 40 多秒,速度提升了约 90% 。多线程版本的代码如下:
# 定义每页的爬取与保存函数
def get_and_save(page, base_url, filename):
page_info = []
print(page)
list_url = '{base}{house}pg{page}'.format(base=base_url, house=MY_HOUSE_CLASS, page=page)
name_dic = get_name_dic(list_url)
for name, code in name_dic.items():
detail_url = base_url + code + 'xiangqing/'
my_info = get_info(detail_url)
my_info['楼盘名称'] = name
page_info.append(my_info)
save_to_json(page_info, name=filename)
print('Page {} saved'.format(page))
# 主函数
def main():
# 文件初始化
with open(CITY + '.json', 'w', encoding='utf-8') as f:
pass
base_url = 'https://{}.fang.lianjia.com/loupan/'.format(CITY)
print('Started at:{}'.format(ctime()))
for page in PAGES:
threading.Thread(target=get_and_save, args=(page, base_url, CITY)).start()
@register
def _atexit():
print('All done at {}'.format(ctime()))3. 数据分析
- 信息提取完成后开始进行数据清洗与分析工作
3.1 数据清洗
1. 读取数据
- 首先读取数据,并将其转换为 DataFrame:
# 读取文件
with open('D://Code/House Analysis/{}.json'.format(city), 'r', encoding='utf-8') as f:
for line in f.readlines():
data.extend(json.loads(line))
# 转换为 DataFrame
df = pd.DataFrame(data, index=(range(1, len(data) + 1)))2. 索引处理
- 将行索引重命名为 No
- 将列索引重排序,并利用字典映射重命名
# 索引处理
df.index.name = 'No'
new_col = ['楼盘名称', '区域位置', '参考价格', '产权年限', '开发商', '物业公司', '物业费', '容积率', '绿化率']
col_name = {
'参考价格': '价格 (元/平)', '产权年限': '产权 (年)', '物业费': '物业费 (元/平/月)', '绿化率': '绿化率(%)'}
df = df.reindex(columns=new_col).rename(columns=col_name)3. 区域位置处理
- 提取区域位置的时候,我们包含了城市名,这里我们将城市名去掉,只保留区县:
# 区域位置数据处理,去掉城市,只保留区县
df['区域位置'] = df['区域位置'].map(lambda x: str(x).split('-')[1])4. 均价处理
- 均价有三种情况,最多的是单价,另外还有一些总价形式的,还有一些是价格未定的。
- 我们利用正则表达式提取数字,价格未定以及总价形式的不具有可比性,并且数量不多,暂以 NA 填充
price_re = re.compile(r'均价 (\d+)元/平')
# 先函数映射正则匹配,再剔除未匹配到的,再利用函数映射提取数据,这里使用了 pandas 的方法链,一步到位
df['价格 (元/平)'] = df['价格 (元/平)'].map(lambda x: price_re.match(x)).dropna().map(lambda x: int(x.group(1)))5. 产权处理
- 产权和均价一样,有些是唯一的,有些根据户型不同有不同的产权,但多种产权的楼盘数量不多,这里我们都提取第一个数字,以节约资源
# 产权修改,产权有些有多种,但数量不多,为了节省资源,以第一个数字为准
df['产权 (年)'] = df['产权 (年)'].map(lambda x: int(x[:2]))6. 物业费处理
- 物业费有些是范围,有些是数字,还有些是暂无信息。对于范围的,我们利用 numpy 求平均值,需注意缺失值处理
- 这里我们都使用 split 方法来提取数字,对于不是范围的,split 得到的只有一个数字,在进行求均值的时候并不影响,所以统一方法,不用判断是数字还是范围
# 先提取数字部分,以 '~' 分隔,并剔除缺失值
no_na = df['物业费 (元/平/月)'].map(lambda x: x[:-6].split('~') if x[:-6] != '' else None).dropna()
# 转换为 array 数组并求平均值
df['物业费 (元/平/月)'] = no_na.map(lambda x: np.array(list(map(float, x))).mean())7. 容积率、绿化率处理
- 读取 JSON 文件后,数据类型都是字符串,因此需要将容积率、绿化率转换为数字,其中因为绿化率的单位是 % ,因此需提取数字字符串后再转换为数字类型
# 将容积率、绿化率转换为数字
df['容积率'] = df['容积率'].map(lambda x: float(x))
df['绿化率(%)'] = df['绿化率(%)'].map(lambda x: float(x[:-1]) if x != '暂无信息' else None)8. 保存数据
- 处理后的数据为 DataFrame,可以保存为 CSV 或者 Excel
df.to_csv('Processed_{}.csv'.format(city.upper()), encoding='utf-8-sig')3.2 数据分析与可视化
1. 各区县楼盘数量与均价对比
- 首先,坐标轴要显示中文,需设置图片全局参数;
# 显示中文
from pylab import *
mpl.rcParams['font.sans-serif']=['SimHei']- 然后计算区域楼盘数、各区均价、全市均价并绘制到同一个图里。这里设置了 marker,设置了轴名称等,并且有双坐标轴
# 计算区域楼盘数
area = df['区域位置'].value_counts()
# 计算各区均价
price = df.groupby(df['区域位置'])[['价格 (元/平)']].mean().reindex(area.index)
# 计算全市均价
average_price = df['价格 (元/平)'].mean()
# 设置图片参数
plt.rc('figure', figsize=(8, 6))
plt.rc('font', size=10)
# 新建绘图区
fig, axes1 = plt.subplots(1, 1)
# 设置图片标题
axes1.set_title('{}各区楼盘数量及均价图', fontsize=16)
# 绘制各区域楼盘数柱状图
axes1.bar(x=area.index, height=area.values, label='各区楼盘数', color='k', alpha=0.3)
# x 轴标签旋转 45 度,设置 x, y 轴名称
axes1.set_xticklabels(area.index, rotation=45)
axes1.set_xlabel('区域')
axes1.set_ylabel('楼盘数量')
# 绘制各区均价,与 axes1 共用 x 轴
axes2 = axes1.twinx()
axes2.plot(price.values, label='各区均价', color='darkorange', marker='o', markersize='5', markerfacecolor='white')
axes2.set_ylabel('均价(元/平)')
# 设置均价值标签
x = np.arange(len(price))
y = np.array(price.values)
for a,b in zip(x,y1):
plt.text(a, b+0.1, '%.0f' % b, fontsize=8, horizontalalignment='center', verticalalignment='bottom')
# 绘制全市均价线,与 axes2 共用 y 轴
axes3 = axes2.twiny()
axes3.plot(np.ones(len(area)) * average_price, 'r--', label='全市均价:%d' % average_price)
axes3.set_xticks([]) # 关闭均价线的 x 轴
# 设置图例
handles1, labels1 = axes1.get_legend_handles_labels()
handles2, labels2 = axes2.get_legend_handles_labels()
handles3, labels3 = axes3.get_legend_handles_labels()
plt.legend(handles1 + handles2 + handles3, labels1 + labels2 + labels3, loc='best')
# 保存图片
plt.savefig('{}各区域楼盘数量及均价.png'.format(cities[city]), dpi=400, bbox_inches='tight')
# 关闭绘图区
plt.close()- 得到的图片如下:
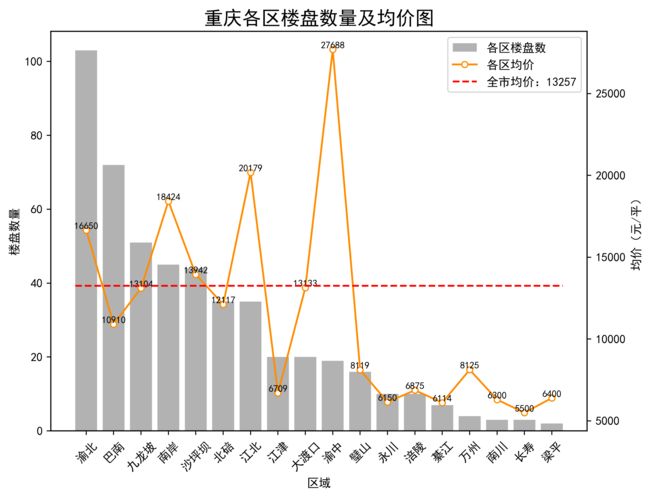
- 结论:
- 数量:楼盘数量最多的区域是渝北、巴南以及九龙坡,最少的为梁平
- 均价:市区内的均价均已达到 1W 以上,其中渝中区一枝独秀(富人区),其次为江北、南岸。全市的均价约为 1.3 W,九龙坡、大渡口最接近全市均价
2. 各区县楼盘平均产权、物业费、绿化率、容积率对比
- 接下来计算其他四项指标,这里我们将四个指标绘制在一个图中,分为 4 个子图,格式统一,因此我们使用循环来完成,避免重复代码
# 计算各指标,并封装到列表中,以便遍历调用
grouped = df.groupby(df['区域位置'])
property_years = grouped[['产权 (年)']].mean().reindex(area.index)
property_costs = grouped[['物业费 (元/平/月)']].mean().reindex(area.index)
volume_rate = grouped[['容积率']].mean().reindex(area.index)
greening_rate = grouped[['绿化率(%)']].mean().reindex(area.index)
values = [property_years, property_costs, volume_rate, greening_rate]
# 设置图片参数
plt.rc('figure', figsize=(10, 10))
plt.rc('font', size=8)
# 新建绘图区
fig, axes = subplots(2, 2)
# 指标序号
k = 0
keys = ['产权', '物业费', '容积率', '绿化率']
# 开始绘图
for i in range(2):
for j in range(2):
# 绘制各指标
axes[i, j].bar(x=values[k].index, height=values[k].values.T[0], color='k', alpha=0.3)
# x 轴标签旋转 45 度
axes[i, j].set_xticklabels(values[k].index, rotation=45)
axes[i, j].set_xlabel('区域')
axes[i, j].set_ylabel(values[k].columns[0])
axes[i, j].set_title('重庆各区域楼盘平均{}对比'.format(keys[k]))
# 设置值标签
x = np.arange(len(values[k]))
y = np.array(values[k].values)
for a,b in zip(x,y):
axes[i, j].text(a, b+0.05, '%.0f' % b, ha='center', va= 'bottom',fontsize=8)
k += 1
# 调整子图周围间距
plt.subplots_adjust(hspace = 0.3)
# 保存图片
plt.savefig('{}各区域楼盘产权、物业费、容积率及绿化率.png'.format(cities[city]), dpi=400, bbox_inches='tight')
# 关闭绘图区
plt.close()- 得到的图片如下:

- 结论:
- 产权:全市产权几乎都为 50 年,少部分楼盘还有 60、70年产权的
- 物业费:渝中区最贵,平均 4 块/平/月,不愧是富人区,其他的平均在 2~3 块钱
- 容积率:渝中区仍然一枝独秀,容积率高达 6,说明全是高楼大厦,其他区都在 2~3,楼层并不高
- 绿化率:綦江最高 39%,璧山紧随其后 38%,梁平仅 20% 仍需努力,其他区都在 30%~35%
4. 总结
- 以上完成了数据爬取、数据清洗、数据分析以及数据可视化,这只是一个简单的项目,用到的都是一些基础知识,中间有遇到过很多问题,例如 CSS 节点选择、JSON 编码格式、代码运行效率慢、绘图样式不熟等等问题。不过通过查询资料以及工具文档,最终完成了第一个自己的项目,很好地巩固了之前学习的知识。
- 对于这个项目,还有很多其他的想法,例如可以选择城市,爬取不同城市的数据,甚至城市与城市对比;另外还有给各指标设置一个权重,计算各楼盘评分,得到各区县评分最高的楼盘,这个后面会继续研究
本项目源代码放到了 Github 上,如有需要可查阅,地址如下
https://github.com/Raymone23/House-Analysis
----------------------------------------------8/28 更新------------------------------------------------------
*5. 拓展
5.1 选择不同城市爬取分析
- 昨天的博客中有提到增加一个功能,使用户可以输入城市,然后爬取对应城市的数据,昨天完成了这个功能。
1. 城市代码:
- 文章前面提到我们爬取的基础 URL 的一个组成部分就是城市,因此最关键的地方在于城市字典,这部分我们可以通过爬取城市选择页面获得。
- 我们打开重庆的基础 URL,观察网页源代码,找到城市选择的部分,可以看到所有城市的名称及链接都在名称为 a 的节点中,我们单独用一个 CSS 选择器选择所有 class 为 clear 的 li 节点下面的所有 a 节点,再提取其文本及属性,封装到字典中即可

- 提取城市字典的代码如下,这部分我们没有封装到项目中,因为城市字典是固定变量,不需要每次都爬取:
import requests
from bs4 import BeautifulSoup
url = 'https://cq.fang.lianjia.com/loupan'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
selected = soup.select('li.clear a')
cities = {
}
for item in selected:
cities[item.text] = item['href'].split('.')[0][2:]2. 其他部分代码修改
- 得到城市字典后,其他部分相对简单,只需将城市字典作为全局变量加入,然后增加输入模块,最后将数据处理中的城市相关字符串进行格式化即可。
- 城市字典(城市较多,中间省略):
CITIES = {
'保定': 'bd',
'保亭': 'bt',
'北京': 'bj',
'承德': 'chengde',
...
'镇江': 'zj',
'漳州': 'zhangzhou',
'郑州': 'zz',
'珠海': 'zh',
'中山': 'zs',
}- 输入模块:
- 因为我们城市字典并不包括所有城市,所以需要一个异常处理语句(也可以用条件语句)来处理用户输入的城市错误问题
# 选择城市
while True:
try:
inputs = input('选择你的城市:')
city = CITIES[inputs]
except KeyError:
print('没有该城市数据,请重新输入!')
else:
break- 字符串格式化就省略了,这个很简单
- 修改后得到的成都以及深圳的数据分析结果如下:




5.2 利用数据库进行存储
1. MySQL
- MySQL 为关系型数据库,基础是二维表格,要将城市数据存储到 MySQL 中,需要先建立数据库,然后创建城市表,再添加表头,最后将爬取的数据插入表中
- 创建数据库:我们在第一次存储数据的时候需要创建一个数据库,之后只需连接即可,因此我们使用异常处理模块,尝试连接数据库,如果出现连接错误,则新建数据库:
# 连接数据库
try:
db = pymysql.connect(host='localhost', user='root', password='xxxxxx', port=3306, db='house')
cursor = db.cursor()
except pymysql.err.InternalError:
db = pymysql.connect(host='localhost', user='root', password='xxxxxx', port=3306)
cursor = db.cursor()
cursor.execute('CREATE DATABASE house DEFAULT CHARACTER SET utf8')- 创建表:创建数据库后,我们创建城市表,将每个城市的数据分别存储到一个表中
# 数据表表头,为 main 模块的全局变量
LIST = ["参考价格", "区域位置", "开发商", "绿化率", "容积率",
"产权年限", "物业公司", "物业费", "楼盘名称"]
HEAD = ' VARCHAR(255), '.join(LIST) + ' VARCHAR(255), PRIMARY KEY(楼盘名称)'# 创建城市表
sql = 'CREATE TABLE IF NOT EXISTS {} ({})'.format(name, head)
cursor.execute(sql)
db.close()- 存储到表中:爬取数据后,我们将数据存储到表中,这里我们使用 SQL 的更新数据语句,楼盘存在则更新,楼盘不存在则插入
def save_to_db(data, name='data'):
# 表头键名
keys = ', '.join(data.keys())
# 构造插入的占位符,使用 , 分隔,数量等于字典的长度
values = ','.join(['%s'] * len(data))
# 连接数据库
db = pymysql.connect(host='localhost', user='root', password='yeswedid631,,', port=3306, db='house')
cursor = db.cursor()
# 加上 ON DUPLICATE KEY,表明如果主键已经存在,则执行更新操作
sql = 'INSERT INTO {table}({keys}) VALUES({values}) ON DUPLICATE KEY UPDATE'.format(table=name, keys=keys, values=values)
# update = 'id = %s, name = %s, age = %s'
update = ','.join([" {key} = %s".format(key=key) for key in data])
# 完整的 SQL 语句
sql += update
try:
cursor.execute(sql, tuple(data.values()) * 2)
print('Data saved')
db.commit()
except:
print('Failed to save data')
db.rollback()
db.close()
return None- 数据处理模块:数据处理模块中的数据读取部分也要改为读取数据库
db = pymysql.connect(host='localhost', user='root', password='yeswedid631,,', port=3306, db='house')
cursor = db.cursor()
cursor.execute('SELECT * FROM {}'.format(city))
rows = cursor.fetchall()
df = pd.DataFrame(list(rows), columns=[x[0] for x in cursor.description])2. MongoDB
- MongoDB 是非关系型数据库,是基于键值对的,比起 MySQL,更适合存储爬虫数据,使用上也相对简单很多
- 数据存储:MongoDB 创建数据库直接使用 MongoClient 对象即可,创建和连接表也很简洁,这里插入多条数据,使用 insert_many() 方法:
def save_to_db(data, name='data'):
# 连接数据库
client = pymongo.MongoClient(host='localhost', port=27017)
db = client.house
collection = db[name]
collection.insert_many(data)
print('Data saved')
return None- 数据读取:数据读取也很简单,使用 find() 方法即可。这里要注意的是在存储数据的时候自动添加了 _id 属性,在读取数据的时候要把 _id 去掉:
# 链接数据库
client = pymongo.MongoClient(host='localhost', port=27017)
db = client.house
collection = db[city]
data = []
for item in collection.find():
del item['_id']
data.append(item)
df = pd.DataFrame(data)