Python操作Excel实例(封装从json读文件函数,将其存入excel函数)
目录
实例一 把列表内容写入Excel
实例二 将excel中的内容读到实例一的lst中
封装——从json读文件函数Rjson,将其存入excel函数W_inExcel
封装——将写excel 读excel和copy excel都封装成类
实例一 把列表内容写入Excel
#!/usr/bin/python
#-*-coding:utf-8-*-
import xlrd
import xlwt
wbook = xlwt.Workbook( )
wsheet = wbook.add_sheet("列表存入表")
""" :type :xlwt.Worksheet"""
lst = [{"id": 1, "name": "虞姬", "age": 25},
{"id": 2, "name": "王昭君", "age": 21,"住址":"南京"},
{"id": 3, "name": "成吉", "age": 265,"住址":"镇江"},
{"id": 4, "name": "鲁班", "age": 43}]
#选取最多的key作为表头
len_key = len(lst[0].keys())
for i in range(0,len(lst)):
if len(lst[i].keys())>len_key:
len_key=len(lst[i].keys())
num=i
#表中写入表头
lst_key=list(lst[num].keys())
for i in range(len(lst_key)):
wsheet.write(0,i,lst_key[i])
#循环写入表
for i in range(len(lst)):
lst_value=list(lst[i].values())
for j in range(len(lst_value)):
wsheet.write(i+1,j,lst_value[j])
wbook.save("E:\\工作学习\\工作前自学\\Python\\excel_study\\excel_python.xls")最后得到结果
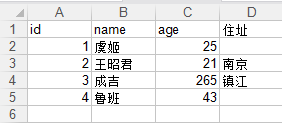
实例二 将excel中的内容读到实例一的lst中
#!/usr/bin/python
#-*-coding:utf-8-*-
import xlrd
import xlwt
"""将表中的内容写入字典list"""
wb=xlrd.open_workbook("E:\\工作学习\\工作前自学\\Python\\excel_study\\excel_python.xls")
wsheet=wb.sheet_by_index(0)
rowNum=wsheet.nrows
lst=[]
dic=dict.fromkeys(wsheet.row_values(0))
for i in range(rowNum):
for j in range(wsheet.row_len(i)):
dic[wsheet.cell_value(0,j)]=wsheet.cell_value(i,j)
lst.append(dic)
print(lst)最后结果
封装——从json读文件函数Rjson,将其存入excel函数W_inExcel
#!/usr/bin/python
#-*-coding:utf-8-*-
import xlwt
import json
"""从本地文件读json文件,针对格式为[{},{}],且每个{}中的key相同,读到表格中key为第一行表头。
如果格式只有一个字典则变为[{}]"""
def Rjson(adress_file):
try:
with open(adress_file) as file_json:
print("成功打开文件%s" % adress_file)
json_load=json.load(file_json)
lst_dict=json_load
except IOError:
print("文件打开失败,%s 文件不存在" % adress_file)
else:
if type(json_load) is dict:
lst=[]
lst.append(json_load)
lst_dict =lst
return lst_dict
""" 将上述读出的json_load放入excel,由于每个字典的keys都相同,故放第一行做表头"""
def W_inExcel(json_load,sheet_name,save_path):
wbook = xlwt.Workbook()
wsheet = wbook.add_sheet("sheet_name")
""" :type :xlwt.Worksheet"""
# 选取最多的key作为表头
len_key = len(json_load[0].keys())
num=0 ###记录keys最多的一行
for i in range(len(json_load)):
if len(json_load[i].keys()) > len_key:
len_key = len(json_load[i].keys())
num = i
# 表中写入表头
lst_key = list(json_load[num].keys())
print(lst_key)
for i in range(len(lst_key)):
wsheet.write(0, i, lst_key[i])
# 循环写入表
for i in range(len(json_load)):
lst_value = list(json_load[i].values())
for j in range(len(lst_value)):
if lst_value[j] is dict or list: ##放入Excel中的元素类型有限,转换为string
lst_value[j]=str(lst_value[j])
wsheet.write(i + 1, j, lst_value[j])
wbook.save(save_path)
if __name__ == '__main__':
adress_file="E:\\工作学习\\工作前自学\\Python\\record.json"
save_path="E:\\工作学习\\工作前自学\\Python\\excel_study\\excel_python1.xls"
sheet_name="存入"
lst=Rjson(adress_file)
print(lst)
W_inExcel(lst, sheet_name, save_path)输入为 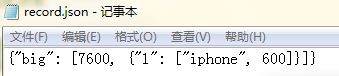
输出为 ![]()
和 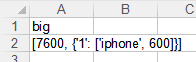
封装——将写excel 读excel和copy excel都封装成类
import xlrd
import openpyxl
import time
class ReadExcel:
def __init__(self, excelPath, sheetName='Sheet1'):
self.data = xlrd.open_workbook(excelPath)
try:
self.table = self.data.sheet_by_name(sheetName)
except BaseException:
self.table = self.data.sheet_by_index(0)
# Get the first row as the key value
self.keys = self.table.row_values(0)
self.rowNum = self.table.nrows
self.colNum = self.table.ncols
def dic_data(self):
if self.rowNum <= 1:
print("The total number of testcases < 1")
else:
case_data = []
data_num = 1
for i in range(self.rowNum - 1):
single_data = {}
# Take the corresponding values from the second line
single_data['rowNum'] = i + 2
values = self.table.row_values(data_num)
for x in range(self.colNum):
single_data[self.keys[x]] = values[x]
case_data.append(single_data)
data_num += 1
return case_data
class WriteExcel:
"""
change data of excel
"""
def __init__(self, excel_path):
self.excel = excel_path
self.workbook = openpyxl.load_workbook(excel_path)
self.sheet = self.workbook.active
def write_excel(self, row_n, col_n, value):
self.sheet.cell(row_n, col_n).value = value
self.workbook.save(self.excel)
def copy_excel(excel_ori, excel_dst=None):
"""
copy data of excel_ori to excel_dst
:param excel_ori:
:param excel_dst:
:return: None
"""
if excel_dst is None:
timestr = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
excel_dst = excel_ori.rsplit(
'.', 1)[0] + timestr + 'result.' + excel_ori.rsplit('.', 1)[1]
dst = openpyxl.Workbook()
dst.save(excel_dst)
ori_workbook = openpyxl.load_workbook(excel_ori)
dst_workbook = openpyxl.load_workbook(excel_dst)
ori_sheets = ori_workbook.sheetnames
dst_sheets = dst_workbook.sheetnames
ori_sheet = ori_workbook[ori_sheets[0]]
dst_sheet = dst_workbook[dst_sheets[0]]
max_row = ori_sheet.max_row
max_column = ori_sheet.max_column
for m in range(1, max_row + 1):
for n in range(97, 97 + max_column):
n = chr(n)
i = '%s%d' % (n, m)
try:
cell = ori_sheet[i].value
dst_sheet[i].value = cell
except BaseException:
print()
dst_workbook.save(excel_dst)
ori_workbook.close()
dst_workbook.close()