java jsoup及jsoup+HtmlUnit简单爬虫
以下是两种爬虫方式
**
1.Jsoup简单爬虫
**

首先是普通jsoup爬取网页信息,由于我是搭建的一个简单地maven项目,所以先上maven依赖(以下maven依赖两个代码都适用):
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<dependency>
<groupId>javax.xml</groupId>
<artifactId>jaxp-api</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>net.sourceforge.htmlcleaner</groupId>
<artifactId>htmlcleaner</artifactId>
<version>2.9</version>
</dependency>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.29</version>
</dependency>
代码部分:
package com.jsoup;
import org.htmlcleaner.CleanerProperties;
import org.htmlcleaner.DomSerializer;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class JsoupHelper {
public static Object fecthNode(String url, String xpath) throws Exception {
String html = null;
try {
Connection connect = Jsoup.connect(url);
html = connect.get().body().html();
} catch (IOException e) {
e.printStackTrace();
return null;
}
HtmlCleaner hc = new HtmlCleaner();
TagNode tn = hc.clean(html);
Document dom = new DomSerializer(new CleanerProperties()).createDOM(tn);
XPath xPath = XPathFactory.newInstance().newXPath();
Object result = xPath.evaluate(xpath, dom, XPathConstants.NODESET);
return result;
}
/**
* 获取xpath下的a标签的文本值及href属性值
* @param url
* @param xpath
* @return
* @throws Exception
*/
public static Map<String, String> fecthByMap(String url, String xpath) throws Exception {
Map<String, String> nodeMap = new LinkedHashMap<>();
Object result = fecthNode(url, xpath);
if (result instanceof NodeList) {
NodeList nodeList = (NodeList) result;
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if(node == null){
continue;
}
nodeMap.put(node.getTextContent(), node.getAttributes().getNamedItem("href")!=null ?
node.getAttributes().getNamedItem("href").getTextContent() : "");
System.out.println(node.getTextContent() + " : " + node.getAttributes().getNamedItem("href"));
}
}
return nodeMap;
}
/**
* 获取xpath下的某个属性值
* @param url
* @param xpath
* @param attr
* @return
* @throws Exception
*/
public static List<String> fecthAttr(String url, String xpath, String attr) throws Exception {
List<String> list = new ArrayList<>();
Object result = fecthNode(url, xpath);
if (result instanceof NodeList) {
NodeList nodeList = (NodeList) result;
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if(node == null){
continue;
}
list.add(node.getAttributes().getNamedItem(attr).getTextContent());
System.out.println(node.getTextContent() + " : " + node.getAttributes().getNamedItem("href"));
}
}
return list;
}
public static void main(String[] args) throws Exception{
fecthByMap("https://www.jianshu.com/u/df0f6525c1c5","//ul[@class='note-list']/li//a[@class='title']");
}
}
效果如下:
2.jsoup+HtmlUnit动态获取页面信息
maven依赖参考文章开头配置

代码部分:
package com.jsoup;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.util.List;
public class JsoupHttpClient {
/**
* Xpath:级联选择 ✔
* ① //:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
* ② h3:匹配标签
* ③ [@class='name']:属性名为class的值为name
* ④ a:匹配标签
*/
public static void main(String[] args) {
// jsoup("http://wwww.baidu.com","kw","jsoup","su","//h3[@class='t']/a");
jsoup("https://cn.bing.com/","sb_form_q","jsoup","sb_form_go","//li[@class='b_algo']");
}
/**
*
* @param url 网址
* @param inputId 获取搜索输入框
* @param inputVal 往输入框 “填值”
* @param btnId “点击” 搜索
* @param xpath 选择元素
*/
public static void jsoup(String url, String inputId, String inputVal, String btnId, String xpath){
try {
//创建webclient
WebClient webClient = new WebClient();
//取消JS支持
webClient.getOptions().setJavaScriptEnabled(false);
//取消CSS支持
webClient.getOptions().setCssEnabled(false);
//获取指定网页实体
HtmlPage page = (HtmlPage) webClient.getPage(url);
//获取搜索输入按钮
HtmlInput input = page.getHtmlElementById(inputId);
//往输入框填值
input.setValueAttribute(inputVal);
//获取搜索按钮
HtmlInput btn = page.getHtmlElementById(btnId);
//点击搜索
HtmlPage page1 = btn.click();
//选择元素
List<HtmlElement> elementList = page1.getByXPath(xpath);
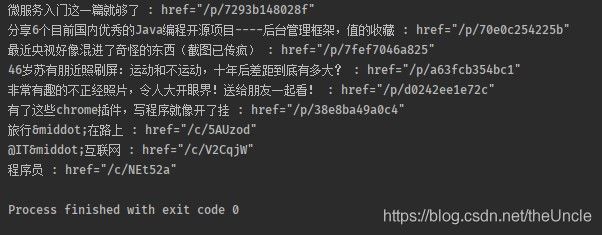
System.out.println("----begin----");
for(int i=0;i<elementList.size();i++) {
// 输出新页面的文本
System.out.println(i+1+"、"+elementList.get(i).asText());
}
System.out.println("----end----");
}catch (Exception e){
e.printStackTrace();
}
}
}
效果:

这里外加一个jsoup爬取豆瓣的小例子:
package com.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupMovie {
public static void main(String[] args) {
crawlMovieinfo();
}
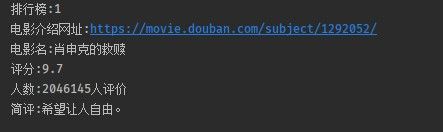
public static void crawlMovieinfo() {
// 1.获取网页
final String URL = "https://movie.douban.com/top250";
Document document = null;
try {
document = Jsoup.connect(URL).get();
} catch (IOException e) {
e.printStackTrace();
}
// 2.选择具体的电影的项,注意first方法,这里先只选取第一个进行测试
Element itemElement = document.select("ol li").first();
// 3.1电影排名
Element rankElement = itemElement.select("em").first();
String rankString = rankElement.text();
System.out.println("排行榜:" + rankString.toString());
// 3.2电影网址
Element urlElement = itemElement.select("div.hd a").first();
String urlString = urlElement.attr("href");
System.out.println("电影介绍网址:" + urlString.toString());
// 3.3电影名
Element titleElement = urlElement.select("span.title").first();
String titleString = titleElement.text();
System.out.println("电影名:" + titleString.toString());
// 3.4评分
Element ratingNumElement = itemElement.select("div.star span.rating_num").first();
String ratingNumString = ratingNumElement.text();
System.out.println("评分:" + ratingNumString.toString());
// 3.5评价人数
Element ratingPeopleNumElement = itemElement.select("div.star span").last();
String ratingPeopleNumString = ratingPeopleNumElement.text();
System.out.println("人数:" + ratingPeopleNumString.toString());
// 3.6 一句话简评
Element quoteElement = itemElement.select("p.quote span.inq").first();
String quoteString = quoteElement.text();
System.out.println("简评:" + quoteString.toString());
}
}
效果: