contos8分布式集群部署hadoop-3.2.1
部署条件准备
需要3台虚拟机master(192.138.137.161),slaver01(192.138.137.162),slaver02(192.138.137.163)
系统centos8,配置1核CPU,2G内存,20G硬盘
软件包:hadoop-3.2.2.tar.gz,jdk-8u191-linux-x64.tar.gz
安装虚拟机和设置静态ip联网可以参考如下:
安装虚拟机Centos8:https://blog.csdn.net/dp340823/article/details/112056146
宿主机连接wifi,centos8静态IP联网:https://blog.csdn.net/dp340823/article/details/112056911
一、安装jdk和hadoop
这些操作是在master(192.138.137.161)进行的,
后续将文件scp到slaver01(192.138.137.162)和slaver02(192.138.137.163)即可
1.上传软件包到指定目录下

2.将jdk解压到指定目录/opt下
tar zxvf jdk-8u191-linux-x64.tar.gz -C /opt
3.将hadoop解压到指定目录/opt下
tar zxvf hadoop-3.2.1.tar.gz -C /opt
4.修改环境变量并使之生效
vim /etc/profile
#java
export JAVA_HOME=/opt/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#hadoop
export HADOOP_HOME=/opt/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
source /etc/profile

5.验证jdk和hadoop安装是否正确
java -version
hadoop version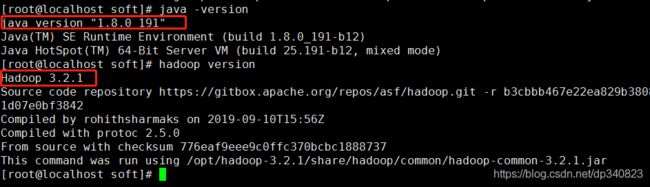
二、设置ssh免密登录
3台虚拟机都要做
1.关闭防火墙
systemctl stop firewalld
firewall-cmd --state
2.修改 hosts
vim /etc/hosts
192.168.137.161 master
192.168.137.162 slaver01
192.168.137.163 slaver02

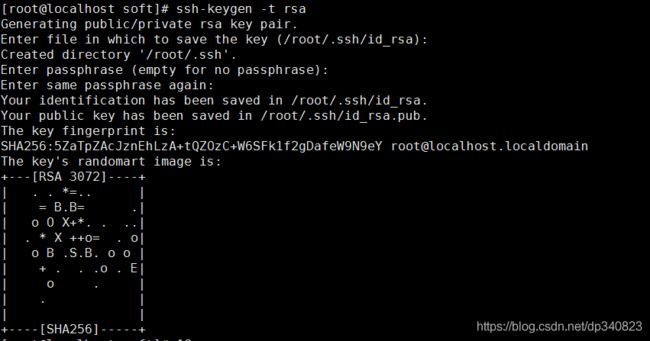
3.生成公钥
ssh-keygen -t rsa一直回车即可
4.公钥复制到其他机器上
ssh-copy-id master
ssh-copy-id slaver01
ssh-copy-id slaver02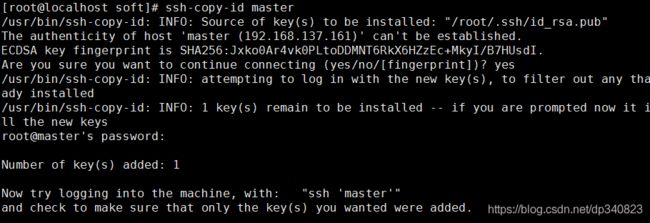
5.验证登录
ssh master
三、修改hadoop配置文件
配置文件都在/opt/hadoop-3.2.1/etc/hadoop/目录下
1.修改配置文件hadoop-env.sh(在末尾添加已下内容)
vim /opt/hadoop-3.2.1/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_191
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root

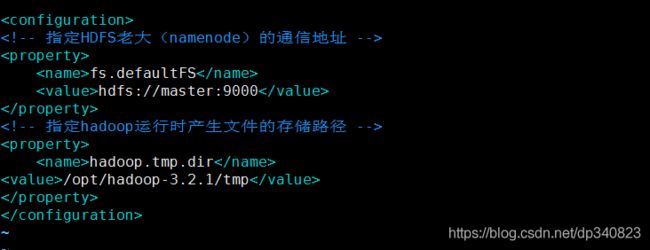
2.修改配置文件core-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/opt/hadoop-3.2.1/tmp
3.修改配置文件hdfs-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/hdfs-site.xml
dfs.namenode.http-address
master:50070
dfs.namenode.secondary.http-address
slaver01:50090
dfs.namenode.name.dir
/opt/hadoop-3.2.1/name
dfs.replication
2
dfs.datanode.data.dir
/opt/hadoop-3.2.1/data

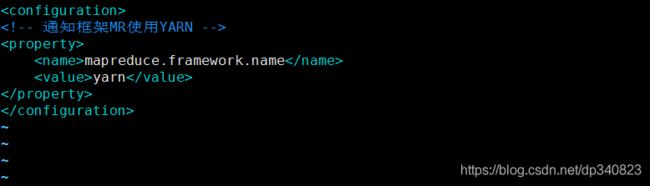
4.修改配置文件mapred-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
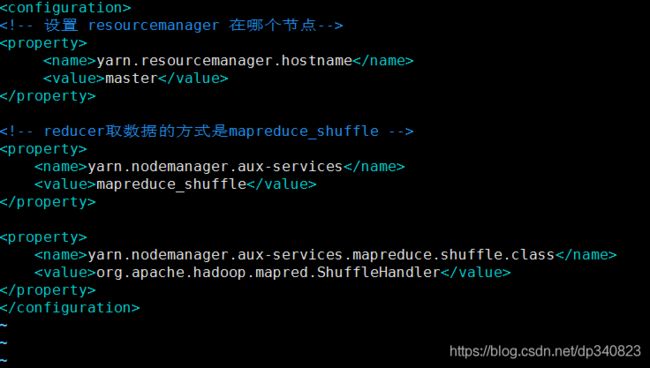
5.修改配置文件yarn-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
6.新建masters文件(/opt/hadoop-3.2.1/etc/hadoop/目录下)
vim masters

7.新建workers文件(/opt/hadoop-3.2.1/etc/hadoop/目录下)
vim workers
8.新建tmp、name、data文件夹(/opt/hadoop-3.2.1目录下)
mkdir tmp name data
9.将master机上的复制文件到slaver01、slaver02
scp /etc/profile slaver01:/etc/
scp /etc/profile slaver02:/etc/
scp -r /opt slaver01:/
scp -r /opt slaver02:/需要在slaver01、slaver02执行source /etc/profile 使用配置文件生效
java -version和hadoop version验证slaver01和slaver02 上的jdk和hadoop是否安装成功
四、启动hadoop
3台虚拟机都要做
1.第一次启动需要格式化namenode(/opt/hadoop-3.2.1)
./bin/hdfs namenode -format
2.启动dfs
./sbin/start-dfs.sh
3.启动yarn
./sbin/start-yarn.sh 
4.用jps验证
master

slaver01

slaver02

五、访问应用
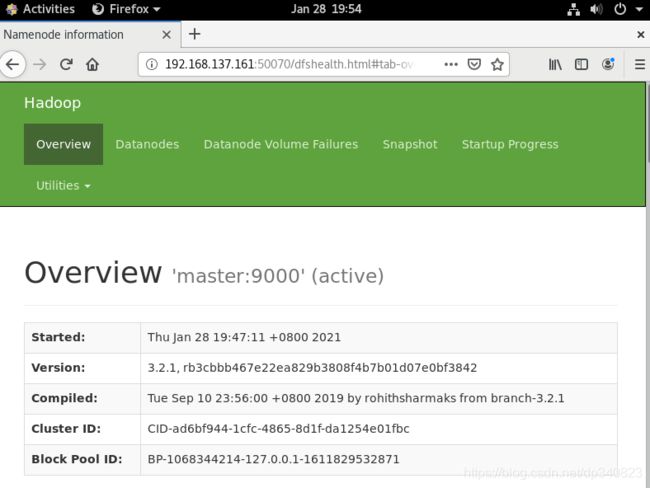
1.浏览器输入192.168.137.161:50070
2.浏览器输入192.168.137.161:8088
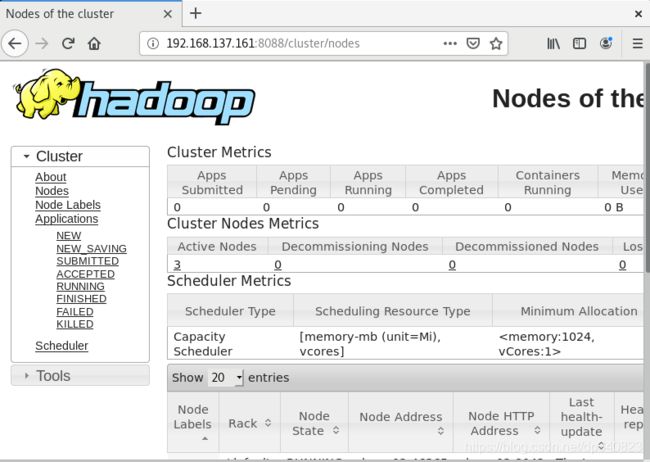
点击nodes查看
