python3网络爬虫--使用Ip代理爬取新浪微博上小姐姐照片(附源码)
文章目录
- 一.准备工作
-
- 工具
- 二.思路
-
- 1.代码整体思路
- 1.代码详细思路
- 三.分析接口
-
- 1.微博用户搜索接口
- 2.用户微博数据接口
- 四.撰写爬虫
- 五.得到数据
- 六.总结
最近博文浏览量每况愈下,为了拯救它,我放大招了。本次爬取新浪微博上用户微博图片(可以是小姐姐),用ip代理进行伪装反爬,先来一张。

一.准备工作
工具
(1)chrome谷歌浏览器,分析接口
(2)python3.7,撰写代码
(3)你聪明的大脑,思考问题
二.思路
1.代码整体思路
这里我用viso画了两个流程图,便于大家理解代码,我的代码就是围绕下图的思路撰写的。
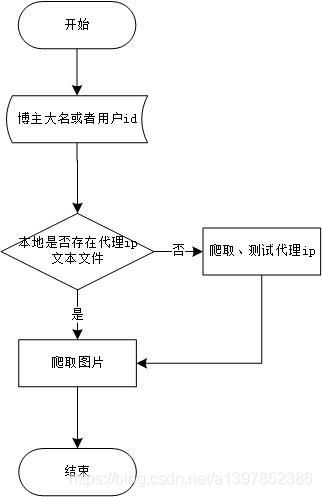
1.代码详细思路

三.分析接口
微博接口的数据都是ajax异步加载的。
1.微博用户搜索接口
通过我的分析和网上资料的参考,发现通过输入name或者uid能够返回uid,screen_name等数据。
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D3%26q%3D【name】%26t%3D0
其中【name】为要检索的用户名或者用户id。
2.用户微博数据接口
此接口为用户所有微博(原创,不包括转载、回复),我们用此接口解析出图片地址。
https://m.weibo.cn/api/container/getIndex?uid=【uid】&containerid=【containerid】
这里的uid为1中返回结果中的uid,containerid为10760+uid的字符串拼接。
接口的获取参考了:
https://blog.csdn.net/weixin_43582101/article/details/96870665
道一声感谢!
这里具体每个接口如何获取,就不展开细说了,有时间的话会详细展开说一下。
四.撰写爬虫
import json
import requests
import random
import re
import os
import time
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
#获取&测试代理Ip类
class GET_Proxy_and_Test(object):
def __init__(self):
self.base_url = 'https://www.kuaidaili.com/free/inha/{}/'
#获取代理ip
def get_proxy(self):
print('第一次使用需要爬取ip代理...............')
headers = {
'Connection': 'keep-alive',
'Host': 'www.kuaidaili.com',
'Sec-Fetch-User': '?1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
}
result = list()
#爬取五页ip作为代理
for i in range(1, 4):
r = requests.get(self.base_url.format(i), headers=headers)
res = etree.HTML(r.text)
selector = res.xpath('//div[@id="list"]/table/tbody/tr')
for data in selector:
ip = data.xpath('./td[@data-title="IP"]/text()')
port = data.xpath('./td[@data-title="PORT"]/text()')
if ip:
proxy = ip[0] + ':' + port[0]
result.append(proxy)
print(proxy)
time.sleep(2)
aim_result=list(set(result))
return aim_result
#测试代理ip
def test_proxy(self,ip_proxy):
print(f'正在测试【{ip_proxy}】..............')
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'icanhazip.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
test_url = 'http://icanhazip.com/'
proxies = {
'HTTP': ip_proxy,
'HTTPS': ip_proxy
}
try:
r = requests.get(test_url, headers=headers, timeout=10, proxies=proxies)
res = r.text.strip()
if res:
self.save_to_txt(ip_proxy)
except:
pass
#写入文件
def save_to_txt(self,data):
aim_file='ip_proxy.txt'
with open(aim_file, 'a')as f:
f.write(data + '\n')
f.close()
#爬取类
class WeiBo_Spider(object):
def __init__(self):
print('开始爬取微博图片..............')
print('---------------------------------------------------------------------------------')
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4252.0 Safari/537.36'
}
self.proxy_file='ip_proxy.txt'
self.path = aim_disk + ':\weibodownload\\'
def getHTMLText(self,url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf8'
return r.text
except:
return ""
#获取uid构造containerid
def getUID(self,name):#获取uid构造containerid
url = f"https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D3%26q%3D{name}%26t%3D0"
html = self.getHTMLText(url)
_json = json.loads(html)
try:
user = _json['data']['cards'][1].get('card_group')[0].get('user')
print( _json['data']['cards'][1].get('card_group')[0])
"""
2020-12-18改进,使用微博ajax接口进行精准匹配用户,获取用户uid,screen_name
uid用于构造containerid,screen_name用于路径地址构造
"""
user_name = user.get('screen_name')
user_id = user.get('id')
start_url = 'https://m.weibo.cn/api/container/getIndex?containerid=107603' + str(
user_id) # containerid=107603+uid
global path
path = aim_disk + ':\weibodownload' + '\\' + user_name + f'_{user_id}'
return start_url
except:
print('没有检索到该用户!请更换关键词或使用2模式!')
os.system('pause')
#产生随机代理ip
def get_ip(self):
with open(self.proxy_file,'r')as f:
iplist=f.readlines()
proxy = random.choice(iplist)
return proxy.strip()
#解析图片地址
def getpics(self,base_url):
i=1
while True:
start_url = base_url+'&page={}'.format(i)
choice=self.get_ip()
print(f'系统选择了:{choice}作为代理IP')
r=requests.get(start_url,headers=self.headers,proxies={
'http':choice})
ret=r.content.decode()
_json=json.loads(ret)
items=_json["data"]["cards"]
flag=_json['ok']
if flag==1:#爬取数据标志
for v in items:
picslist=v.get('mblog')
if picslist is not None:
aims=picslist.get('pics')
if aims !=None:
for aim in aims:
img_url=aim['large']['url']
yield img_url
print('第',i,'页爬完了...............')
else:
print('爬取结束!在第[',i,']页终止',start_url)
os.system("pause")
break
i+=1
#下载图片
def download(self,url,img_path):
filename=url.split('/')[-1]
filename=filename[10:]
r=requests.get(url,headers=self.headers)
try:
os.makedirs(self.path+img_path)
except:
pass
with open(self.path+img_path+'\\'+filename,'wb')as f:
f.write(r.content)
print(f'{filename}下载完成..............')
def main():
pool=ThreadPoolExecutor(max_workers=4)
while True:
global key
global aim_disk
print('---------------------------------------------------------------------------------')
judge = input('请输入1.博主大名2.uid:')
print('---------------------------------------------------------------------------------')
if judge=='1':
user_name=input('请输入博主大名:')
print('---------------------------------------------------------------------------------')
aim_disk = input('保存到磁盘:')
print('---------------------------------------------------------------------------------')
if not os.path.exists('ip_proxy.txt'):
proxy_spider=GET_Proxy_and_Test()
result=proxy_spider.get_proxy()
for proxy in result:
pool.submit(proxy_spider.test_proxy,proxy)
pool.shutdown()
print('IP代理爬取、测试完成!..............')
spider = WeiBo_Spider()
start_url = spider.getUID(user_name)
print(start_url)
img_path=start_url.split('107603')[-1]
for img_url in spider.getpics(start_url):
spider.download(img_url, img_path)
pool.shutdown()
break
elif judge=='2':
key=input('请输入博主uid:')
print('---------------------------------------------------------------------------------')
aim_disk = input('保存到磁盘:')
print('---------------------------------------------------------------------------------')
#if re.match('\d+',key):
#如果目录下不存在ip_proxy.txt则取爬取最新的proxy
if not os.path.exists('ip_proxy.txt'):
proxy_spider = GET_Proxy_and_Test()
result = proxy_spider.get_proxy()
for proxy in result:
pool.submit(proxy_spider.test_proxy, proxy)
pool.shutdown()
print('IP代理爬取、测试完成!..............')
spider = WeiBo_Spider()
start_url = 'https://m.weibo.cn/api/container/getIndex?containerid=107603' + key
for img_url in spider.getpics(start_url):
spider.download(img_url,key)
pool.shutdown()
break
else:
print('信息输入有误!')
continue
if __name__=='__main__':
main()
五.得到数据
程序正常运行结束退出,打开文件夹查看。


我将这个脚本打包成exe放在
https://wws.lanzous.com/i8F8vjzk86d
六.总结
- 本次爬取了微博照片,使用了ip代理来规避微博的反爬,所有图片均为高清原图,经测试,爬几十、十几G没有问题的,稳定性还是不错的,最后打包成了exe可执行文件。图源水印,在此仅作举例,请勿用于商业用途。思路、代码方面有什么不足欢迎各位大佬指正、批评!最后恳请大家给个免费的赞!
