2020.6.25 ICRA2020中的有关重建的论文 二
DeepFactors: Real-Time Probabilistic Dense Monocular SLAM
单目SLAM,估计场景的稠密地图(使用深度图序列表达)
这是通过使用学习到的紧凑深度图表示,并重新构造三种不同类型的误差:光度误差,重投影误差和几何误差。
Introduction
单目SLAM的研究已分为两个范式,其主要区别在于几何图表示:
i)稀疏方法[1] – [3]形成并维护由一组特征点点地标组成的地图,缺点在于限制地图的实用性;优点是对图像噪声,离群值和照明变化具有鲁棒性。
ii)稠密方法:使用所有图像像素并估计观察到的场景的密集且更有用的重建方法[7]。
对因为运动模糊造成的图像退化鲁棒,因为使用光度误差使得对光度变化敏感。
基于深度学习的方法可以作为组件集成到SLAM中。解决方案从基于经典模型的系统委派子组件到神经网络(例如[8],[9])到可以直接预测摄像机姿势和场景几何形状的纯粹端到端学习系统(例如[10] – [12])。 直接从数据中学到的先验知识可以解决诸如单眼影像深度预测之类的难题[13] – [16]。
框架
为了重建场景的密集表示并估计相机运动,我们制定了多视图稠密BA问题。
我们将重建的几何G参数化为每个相机帧下的深度图。
FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow (基于光流的动态分割与背景重建)
针对动态环境的,稠密RGB-D SLAM。
使用光流残差来区别点云中的动态部分。
frame work
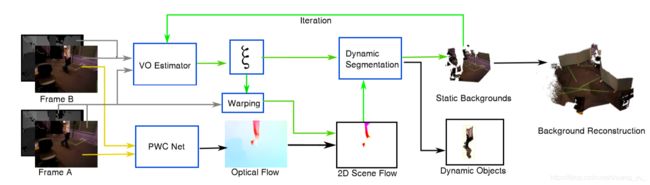
i) PWC Net:输入连续两帧RGB-D图进行光流估计。
ii) VO Estimate:初始运动估计。
iii) 根据初始位姿估计 ξ \xi ξ变换Frame A,并进行2D场景流估计,并将其用于动态分割。
iv) 利用背景进行重建。
∇SLAM: Dense SLAM meets Automatic Differentiation
Large-Scale Volumetric Scene Reconstruction using LiDAR
针对自动驾驶环境的,基于激光雷达的、大规模3D场景重建(建立TSDF然后抽取mesh)。
Introduction
在自动驾驶中,3D重建可用于各种任务。
大多数方法都使用点云来表示世界,并将当前的测量结果与之匹配([1] – [3])。 像[4]这样的其他方法也使用纹理网格内的图像对齐来估计传感器的姿势。
标签传递(Label transfer)是另一个应用程序 [5]、[6]、[7] – [9]。
多种重建场景方法:
i)最简单的方法是累积点云[1],[3]和[2]。 缺点:含有大量冗余数据,进一步处理效率低下,点密度随传感器分辨率变化,远距离区域的采样比近距离区域的采样稀疏,重建也没有拓扑信息。
ii)使用surfels。 [11] [12]。 优点:就像点云一样,它们不需要任何空间数据结构,同时可以将新的测量值与以前的测量值融合。 尽管它们具有表示曲面的能力,但是它们实现的重建缺少真正的体积方法的密度。
iii) 体素网格。[13],对于路径规划很有帮助,对于其他应用程序通常过于粗糙。
iv) TSDF, [15]。该方法实现了具有高细节水平的密集重构,同时具有滤除传感器噪声的能力。 此外,该方法能够通过在体素之间插入有符号距离函数来以亚体素精度重建表面。
在室外环境中,很少有使用体积深度融合的工作。
在[24]和[7]中,融合了立体摄像机的深度。 但是,单个立体声设置只能重建一半的场景,因为只能从一侧看。 此外,与LiDAR相比,立体声的深度质量要差得多。
frame work
Linear RGB-D SLAM for Atlanta World
针对Atlanta世界(相对于Manhattan world的概念),线性RGB-D SLAM。
它由垂直方向和与垂直方向正交的一组水平方向组成,因此可以表示更宽的场景范围。 我们的方法利用Atlanta世界的结构规律性来解耦摄像机姿态估计的非线性。 这使我们能够分别估计摄像机的旋转和平移,从而绕过了传统SLAM技术固有的非线性。
Introduction
visual SLAM已经在机器人技术和计算机视觉社区中被广泛研究了数十年[1]。 它们已显示出令人鼓舞的结果,但是,它们对挑战性条件仍然敏感,例如人造环境[2],[3]中典型的无纹理或无特征的场景(例如室内场景)。
为了应对这种局限性,一种常见的替代方法是利用其他高级基元,例如结构化环境中的平面特征[4],[5],[6]。 这些额外的特征提高了对不良纹理场景的鲁棒性,尤其是在基于图的SLAM方法[7],[8]的情况下。 但是,这些技术的适用性受到它们的高复杂度的限制,因为由此产生的基于图的优化是非凸和非线性的[9]。
为了克服这些限制,[3]提出了一种线性RGB-D SLAM方法(L-SLAM),该方法依赖于一类人造环境的结构简化,即曼哈顿世界(MW)[11]。 MW由三个正交方向定义,这些方向称为曼哈顿框架(MF)。
在MF的假设下,通过跟踪单个MF估计相机旋转。 这种方法可以解耦旋转估计,从而可以通过线性卡尔曼滤波器(KF)联合估计相机位置和MF的平面组成。 L-SLAM证明了其在无纹理环境下的有效性,并且由于问题的线性表达,因此其计算复杂度较低。 但是,严格的L-SLAM分子量假设将其应用范围限制在长方体形结构上。
为了减轻MW的局限性,我们将以前的L-SLAM方法扩展到称为亚特兰大世界(AW)假设的更一般的结构表示[12]。
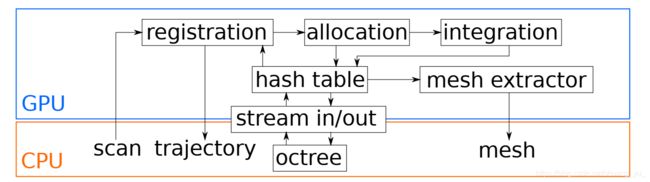
Loam livox: A fast, robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV
LiDAR odometry and mapping (LOAM)
FrameWork
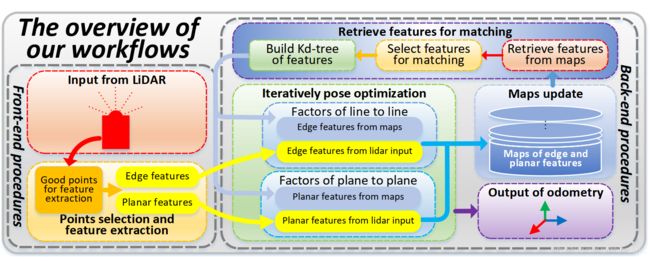
我们的工作流程概述。
i)每个新框架都直接与全局地图匹配,以提供里程表输出。 匹配结果依次用于将帧注册到全局地图,从而导致里程表输出和地图更新的速率相同(即20 Hz)。
ii)在我们的实现中,只有特征点(即边缘点和平面点)被保存在内存中,所有原始点都被保存在硬盘中以进行可能的离线处理(例如,离线全局优化)。
Topological Mapping for Manhattan-like Repetitive Environments
针对室内仓库环境的 拓扑建图框架。
仓库被表示为拓扑图,其中图的节点代表特定的仓库拓扑结构,边表示为两个节点之间的路径。
Introduction
文章探讨了拓扑理解对SLAM框架的作用。
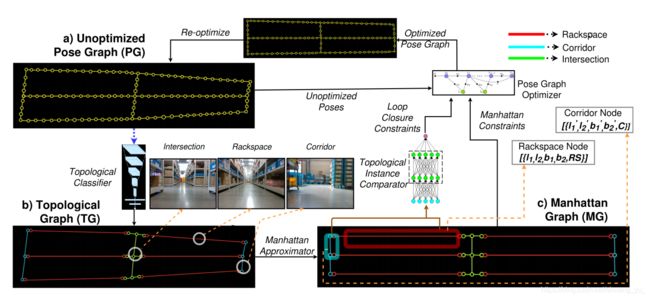
输入时位姿图Pose Graph。其中CNN分类器对区域结构进行了分类。
a) 错误Pose Graph(尚未矫正的),
b) 拓扑Graph(TG),TG中的每个节点经由深度卷积网格进行了标记。
c)拓扑图转化为曼哈顿图(MG),曼哈顿图中的节点属性(长、宽)和边,来自于位姿图(PG)
在这一领域已经有很多工作,可以在[1]中看到对这种方法的详细回顾。其中引人注目和引人注目的包括[2] – [7]。这些方法大多数都专门针对具有不变描述符的基于视觉的环路检测。 许多任务都将单个图像作为场景的独特拓扑结构,而没有将此类节点与元级标签(例如机架,走廊,交叉点等)相关联。
诸如[11],[12]和最近的[13],[14]之类的作品介绍了分层的场景表示以及它们如何用于各种导航任务。
文献[15]展示了借助图神经网络将拓扑结构用于仿真环境中的机器人导航,其中拓扑特征被嵌入到图网络的节点中。 但是,该方法依赖于无噪声传感器输入以及不同拓扑的可用性。 [16]展示了如何对拓扑进行贝叶斯推断以获得更准确的拓扑图。 但是,它不接受超出限于机器人所看到的场景的直接下级拓扑的元级拓扑标签的概念。
Voxgraph: Globally Consistent, Volumetric Mapping using Signed Distance Function Submaps
针对无人机的、可以在CPU上运行的、基于SDF子图的、全局一致的稠密地图。
通过计算子图之间的最佳对齐来保持全局一致性。
Introduction
为了进行导航和与环境互动,机器人平台为环境建立地图表示。
SLAM在过去几十年一直是机器人技术研究的重点[1]。
稀疏:最近的系统已经显示出实时估计全局一致的基于特征的地图[2],[3]。尽管基于特征的地图已被证明对于在机器人平台上进行运动估计必不可少[4],[5],但由于难以从稀疏的样本集中提取表面的形状和连通性,因此它们用途有限。
稠密:表示为符号距离函数(SDF)的隐式表面已成为实现此目的的有效表示形式。 但是,难以达到全局一致性,且随着数据量的增加,地图的全局优化很快变得难以处理。
Overview
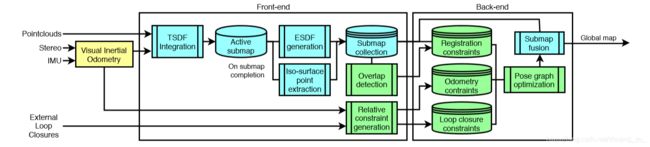
前端:将传感器的测量结果转换为子图。
A. 子图创建:输入点云序列,并通过TSDF融合创建子图,以固定的频率创建子图,并假设足够短的时间内创建的子图内部保持一致。 同时有TSDF创建ESDF,即将欧几里得距离传播到TSDF使用的截断带之外,从而允许从表面进一步查找距离。然后通过 marching cubes algorithm 计算isosurface points
B. 生成约束:前端向后端发出信号,以向基础优化问题添加约束。 我们实现了三种约束:测距法,配准和闭环约束。
后端:后端通过最小化所有姿势图约束的总误差来对齐子图集合。
Modeling of Architectural Components for Large-scale Indoor Spaces from Point Cloud Measurements
针对大型室内建筑的,基于雷达点云的、重建(点云->mesh)
Introduction
基于3D点云的 室内空间构建是一个已经深入研究的课题[1][2]。
但是由于实验过程中使用的传感器系统的种类,获取数据的条件以及用于稳健建模的假设,使其仍未一个较为困难的项目。
这些因素可以分为 i)固有的 ii)无关的复杂性
固有的复杂性:存在于建筑组件中的各种几何形状,例如简单的平面贴片,曲面,圆柱体柱和倾斜表面。传统方法通过做出强大的几何假设来处理固有的复杂性。 最流行和最有力的一个是曼哈顿世界的假设[3],[4],或者是2.5D假设[5][6],最近,[7]报告了该领域的显着进步,该领域通过将整个点云划分为更小的封闭空间(称为房间)将室内空间分为6种结构模式。 但是,对于大空间的逐个房间划分是病态问题,他们的假设的有效性尚不清楚。
Overview
首先构建architectural point cloud(建筑点云),它表示目标环境的建筑部分的几何形状。
然后,提取分段的平面段,并通过使用邻接图将它们彼此连接。
迭代更新邻接图,直到每个平面段都具有足够的邻域并闭合以生成watertight mesh
A. 预处理:使用基于LiDAR-IMU的SLAM,获得经过配准的点云,以及姿态。
B. 构建建筑点云:输入注册点云的点可以分为建筑点和非建筑点,需要从输入点云中提取建筑点。i)手动删除明显噪点 ii)凸切算法提取建筑点 iii)对提取出来的带孔的建筑组件进行填充 iv)
C. 分段平面提取: i)平面提取:使用基于鲁棒主成分分析(R-PCA)的分层平面提取[22]。 ii)基于分段平面度的曲面提取.
D. 邻接图构造,借助邻接图G =(V,E)来表示逐段平面段之间的连通性,以验证用于watertight mesh生成的闭合表面。
E. 生成Mesh,室内建筑组件可以用三角mesh表示,通过对邻接图中的每个平面段执行三角剖分提取。 。 在此过程中,每个平面段的角点都从其相邻点提取。 然后,将提取的角点用作Delaunay三角剖分期间的约束。
Depth Based Semantic Scene Completion with Position Importance Aware Loss
基于3D-CNN的语义重建。
Introduction
语义场景完成(Semantic scene completion ,SSC)[1],[2],[3]由场景完成和语义标记组成,目标是同时推断场景中已完成的3D形状和所占用体素(网格单元)的语义类别。
在3D场景预测任务中经常使用3D卷积神经网络(3D-CNN)。 由于3D-CNN需要规则的网格作为输入,因此在这些基于3D-CNN的方法中自然选择了体素来表示3D场景,并且采用了不同的损失函数来训练它们[3],[8],[9]。
先前的方法忽略体素位置的相对重要性(所有体素受到同等对待),因此,我们提出了局部几何各向异性(LGA)来定量确定不同位置的重要性。
先前方法的另一个局限性在于它们不使用完整的深度信息,由于内存的限制,在3D-CNN中使用的输入分辨率不太可能很大,从而导致粗糙的体素级别表示。 特别是,用于3D-CNN模型的普通体素化输入为240×144×240 [3],[12],[13],而原始输入深度的分辨率为640×480或更高。 在本文中,我们通过设计具有两个输入分支的混合网络结构,充分利用了全分辨率深度和编码体素的优势。
Overview

用SSC的PALNet混合网络结构。
在深度流中,使用2D-CNN处理全分辨率深度,将特征图通过2D-3D投影层投影到3D空间,然后进行3D卷积。
在体素流中,将TSDF编码的体素作为输入发送,采用的所有卷积操作均为3D卷积。
将两个信息流汇总后,将它们发送到具有较大接受域的后续网络,以捕获3D上下文以预测完整的语义场景。
Panoptic 3D Mapping and Object Pose Estimation Using Adaptively Weighted Semantic Information
对象级、基于RGB-D相机、估计对象的六自由度位姿,基于深度的语义、实例分割, 基于surfel的建图系统。
Introduction
对于同时导航与操作的机器人,在3D重建地图中将语义和几何信息融合在一起是一种有前途的方法[1]。
在密集地图中对对象实例进行了语义注释[2],[3],[4],[5]。
在我们之前的工作中,我们开发了一种称为Object-RPE(重构和姿势估计)[5]的语义映射系统,用于使用RGBD摄像机进行精确的3D实例感知语义重构和6D姿态估计。但,i)使用Mask-RCNN从每一帧生成对象遮罩会严重限制其速度,ii)尚未通过有效利用深度信息来充分利用RGB-D数据的潜力。
Overview
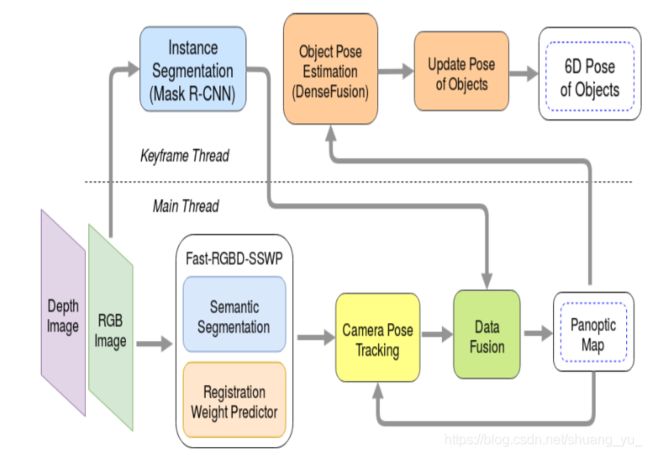
i) 对RGB-D图像进行语义分割与自适应权重预测,采用Fast-RGBD-SSWP框架,进行RGBD数据的实时语义标注。
ii) 相机位姿追踪:系统维护了基于surfel的环境模型,基于联合ICP算法(最小化几何、光度、语义误差)进行相机姿态估计。
iii) 数据融合:a.将深度信息增量地融合到surfel地图中,b.采用递归贝叶斯融合语义信息,c.概率分配给每个对象实例,而不是将概率分配给组成3D地图的每个元素,同时每个surfel有一个实例ID。
在一个单独的线程中,RGB关键帧通过实例分割(Mask R-CNN)进行处理,并对检测结果进行过滤并将其与3D映射中的现有实例进行匹配。 当没有匹配发生时,将创建新的对象实例。 请注意,我们的管道确实
iv) 多视角对象位姿估计,对于每个单帧,我们都应用DenseFusiontop来预测3D空间中对象的位置和方向。
OmniSLAM: Omnidirectional Localization and Dense Mapping for Wide-baseline Multi-camera Systems
针对FOV鱼眼镜头的、宽基线multi-view双目、omnidirectional localization and dense mapping系统。
将全方向深度图和估计的顶点融合到截断的符号距离函数(TSDF)体积中,以获取3D地图。
Introduction
环境的3D几何建图是汽车或机器人自主导航的重要组成部分。
距离传感器:激光的LiDAR [1]和结构光3D扫描仪[2],优点:深度感应准确。缺点:低垂直分辨率,传感器间干扰,尺寸,成本和功耗问题。
基于摄像头的系统[3],[4]也可用于3D密集映射,优点:具有足够的分辨率,成本较低且尺寸较小,被动运行。 缺点:不能直接感应到表面的距离,但可以使用多视点立体声来估计3D深度。此外,基于齿形的声学性能改进最近基于深度学习的立体深度估计算法已经显示[5] – [7], 基于相机系统变得越来越有利。
最近,已经提出了一种宽基线全向立体声设置,该设置由面向四个基本方向的四个220°FOV闪光眼摄像机组成[13]。 这种宽基线设置可以在覆盖360°的范围内进行远程感测,并且由于立体声对之间有足够的重叠,因此大多数区域都可以从两个以上的摄像机中看到。 使用相同的捕获系统,还提出了鲁棒的视觉里程表(VO)ROVO [14]和用于全方位深度估计OmniMVS的端到端深度神经网络[15]。
Overview

i) 全向深度估计:我们使用 wide-baseline multi-camera rig system和spherical sweeping-based approach [13]进行全向立体匹配。
我们使用OmniMVS [15]来获得密集的全向深度。端到端网络的OmniMVS [15](由一元特征提取,球面扫掠和cost volume computation模块组成),允许从宽基线设备进行密集的全方位多视图立体匹配。
ii) 全向视觉SLAM:定位模块:ROVO[14];闭环检测;使用位姿图优化以校正轨迹。
iii)基于TSDF的稠密重建:当新的全向深度到达时,我们将其转换为3D点云,并使用估计的位姿将其转换为全局坐标系。 然后,将射线从估计的当前装备位置投射到点云中的每个点,并沿射线更新体素,通过体素雕刻去除嘈杂的表面或移动的物体。
Day and Night Collaborative Dynamic Mapping in Unstructured Environment Based on Multimodal Sensors
针对协作机器人、跨越白天与黑夜的长期运行的,可在动态环境中、协同构建全局地图。
Introduction
一组机器人的协作操作引起了极大的关注[1],这些机器人已逐渐用于应对艰巨的任务,例如协作3D映射[2],编队控制[3]和人为推理[4],[ 5]。
协作机器人3D环境重建通常称为协作建图,目前已有i)估算机器人之间的相对转换[7],ii)考虑相对定位的不确定性[8],iii)整合来自相邻机器人的信息[9],从全局角度更新地图[10]等。
但是,上面提到的方法假定世界是静态的,动态对象(如行人)将被忽略。
Fast Local Planning and Mapping in Unknown Off-Road Terrain
针对未知的越野环境,一个快速的、在线、制图与路径规划。
将障碍物检测与地形梯度图结合在一起,以制作简单且可调整的cost map。
A* planner会在地图上找到最佳路径。
Introduction
对于无人地面车辆而言,在越野环境中航行是一个独特的挑战——越野环境的非结构化环境。
swamps、deep mud,看起来可以通过,但实际没法通过。
像高高的草丛、小灌木丛这样的物体:看起来像障碍物,实际可以通过。
SLOAM: Semantic Lidar Odometry and Mapping for Forest Inventory
针对树林环境的,基于语义分割、激光雷达的,可以估计树径的、LOAM算法。
Introduction
获得准确的木材库存对于森林经营者至关重要,当前,林务人员使用陆地激光扫描(TLS)传感器[1],[2]来提取树状指标,且精度高,人力减少[1]。 但是,这些传感器需要四处移动以测量多个位置的木材库存,以完全覆盖森林,这需要额外的时间和人力。 我们提出了一种机器人巡游木材的方案,其中涉及一个机器人对木材的立场进行导航,测量样品并估算森林总体积的方法。
Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping
A Spatial-temporal Multiplexing Method for Dense 3D Surface Reconstruction of Moving Objects
针对运动对象的,基于结构光的时空复用方法的,3D表面重建。
Introduction
对象的三维表面重建在机器人技术中起着重要作用:同时定位和地图绘制(SLAM)[2] – [4],机器人操纵[5],[6],机器人识别[7],空中机器人[8] ]和机器人辅助手术[9] – [13]等。
3D表面重建方法,可以将其分为两类:被动方法和主动方法[14]。
被动方式,例如 立体视觉[15],[16],出较低的匹配精度和较低的点云密度[14]。
主动方法。 结构光技术。 结构光的编码策略基于空间复用或时间复用[14]。 对于时间多路复用结构光方法,需要将一系列图案连续投影到目标上,例如格雷码[17]和n元代码[18]等。时间码字有助于提高重构精度。但是,捕获多个图案会严重限制重建速度。此外,如果目标物体在图像获取期间移动,则所获得的码字将是不正确的。 这导致重建结果不准确。 为了增强对移动物体的鲁棒性,已经尝试减少用于时间多路复用方法的投影图案的数量。
在过去的几十年中,已经开发了各种基于相移条纹的有源3D成像方法。 相移条纹可以仅利用三个正弦条纹将唯一的本地码字分配给像素,从而大大减少了图案数量。 但是,它们的主要局限性是由于相移条纹的周期性重复性,它们无法唯一地编码整个图像。 结果,需要相位展开来消除歧义。 一些工作[19] – [23]提出通过投影更多模式来检索相位,例如格雷码和多频相移条纹,这会导致更长的图像采集时间,不适合重建运动物体。 对于空间复用方法,只需要投影一个包含丰富特征的单个图案,例如唯一纹理[24],De Bruijin序列[25],统计随机斑点[26]等。因此,空间复用 方法适合于重建动态对象。 然而,噪声,环境光,图像模糊和运动模糊将很容易导致错误的解码[14]。 此外,如果图案的特征密度不足或在重建不连续的表面和边缘时,空间复用方法的精度会很低。
为了为运动对象的精确3D曲面重构提供解决方案,在本文中,我们开发了一种新颖的时空复用方法。
Deep-Learning Assisted High-Resolution Binocular Stereo Depth Reconstruction
针对高分辨率(4K)双目图像的、深度学习辅助的,重建算法。
目前的立体声重建方法,会在高分辨率数据上消耗过多的计算资源。
我们建议在基于学习的模型的指导下,使用资源较少的非学习方法来处理高分辨率图像并实现准确的立体声重建。
在基础设施审查中,UAV(无人机)技术已广泛集成,这需要对桥梁和电网等设施进行密集的3D重建。
但是,由于大的视差搜索范围和像素数量,计算量大。
同时,由于缺少纹理,表面倾斜[1]和照明不足,导致失败。
我们的目标 是对高分辨率图像进行密集且准确的深度重建:

从4K分辨率立体图像重构点云。 a)来自扫描仪的点云,作为真实数据.b)通过深度学习辅助方法进行密集重构的点云.c)重建误差.d)放大图。
高分辨率立体图像具有大量像素,并且具有很大的潜在视差搜索范围。 近年来,深度学习方法的表现往往优于非学习方法。
但是,图像大小受可用训练数据和计算硬件的限制。常见数据集的双目图像尺寸小于100万像素的。
具有跳过连接的编码器/解码器[5]和空间轮询[6],[7]等技术可以减少内存需求。
大多数方法采用了成本量概念[8],它消耗了大量的GPU内存。
最近的作品甚至进一步减少了内存,例如 [9],但仍不足以拟合一对4K图像。
半全局匹配(Semi-Global Matching,SGM)等非学习方法在4K图像(12兆像素)上消耗超过50GB的CPU内存,视差范围为1000[10]。
在OpenCV [11]软件包中实现的SGBM(SemiGlobal Block Matching,简化版的SGM)方法可以使用有限的计算资源直接处理我们的4K图像对。 但是,模型参数取决于大小写,并且SGBM可能无法预测一些区域中的视差。
Towards the Probabilistic Fusion of Learned Priors into Standard Pipelines for 3D Reconstruction
将深度学习的结果与标准3D重建框架相结合的最佳方法仍然没有确定。
目前的方法:目前将传统的多视图立体方法的输出传递给网络以进行正则化、或优化的系统获得了最佳结果。
本文的方法:通过让其网路预测概率分布而不是单个值,取得了良好的结果。
系统可以为一组关键帧增量地生成密集的深度图。
我们训练了一个深度神经网络,以预测来自单个图像的每个像素深度的离散。
然后我么基于后续帧与关键帧之间的光度一致性,将此probability volume与另一个probability volume融合。
结合两者的概率体积可以使得目标概率体积更为准确。然后从概率体积中提取深度图。
Introduction
使用运动结构(SfM)和视觉同时定位和制图(SLAM)增量创建密集3D场景几何。
直到最近,密集的单眼重建系统通常通过最小化几帧的光度误差来工作。
由于由于遮挡边界或低纹理区域而无法很好地约束此最小化问题,因此大多数重建系统均基于平滑度([1],[2])或平面([3] – [5])假设采用正则化方法。
DTAM: Dense Tracking and Mapping in Real-Time 2011
REMODE: Probabilistic, monocular dense reconstruction in real time 2014
Manhattan and piecewise-planar constraints for dense monocular mapping 2014
DPPTAM: Dense Piecewise Planar Tracking and Mapping from a monocular sequence 2015
Visual-inertial direct SLAM 2016
Super-Pixel Sampler: a Data-driven Approach for Depth Sampling and Reconstruction(没看懂)
一个RGB图像引导的、深度采样与重建算法。
基于主动照明的深度采样对于导航至关重要。带有机械、固定、采样模板的LiDAR,在当今的自动驾驶汽车中通常使用。一个基于固态深度传感器,也没有机械部件,可以得到快速、自适应的扫描。
本文提出了一个自适应、图像驱动的、快速、采样的、重构策略。
首先,制定一个分段的平面深度模型,并估计了其在室内和室外场景中的有效性。在最佳的情况下,具有20~60个piece-wise平面结构可以很好地近似一个深度图。大概1200张RGB图像需要一张深度样本。
一个Super-Pixel Sampler(超像素采样器),一个基于超像素的、简单的、通用的、采样与重构算法。
第三,我们为采样器提出了一个非常简单,快速的重建方法。
Introduction
深度感知已经成为自动驾驶汽车导航与避障的关键[1]。
主动深度感测 的物理限制,如 LiDAR只能产生一个稀疏的深度测——导致粗略的点云,需要对丢失的数据进行额外的估计。
传统的LiDAR只能产生固定数量的水平扫描线。固态深度传感器正在出现一种新的革命性技术。它们基于没有机械部件的光学相控阵,因此可以自适应方式快速扫描场景(可编程扫描)[2],[3]。
因为每个自动驾驶平台都装备有RGB相机,因此考虑通过RGB图像改善深度采样效果。

自适应采样效果展示(对比盲采样)
d)使用66个采样点的盲采样的线性重建(RMSE= 0.52m) 、
e)使用57个点的自适应采样(RMSE=0.31m)
f)达到RMSE=0.31 采用固定采样需要669个采样点。
深度图像空间
提出了一个简单的深度模型,并尝试对基准数据进行实验验证。然后,我们将其与RGB相关联。
piece-wise平面深度模型
我们的主要目标是获取用于自主导航的深度信息。
考虑到针对物体,我们对其位置(而不是形状)感兴趣。
这引出了分段平面模型,这是深度估计中的常见假设(参见例如[25],[26])。
考虑深度图像 d d d,假设场景中的大部分可以由分段的平面近似。记 Ω ∈ R 2 \Omega\in R^2 Ω∈R2代表图像区域。集合 E = { Ω i } E=\{\Omega_i \} E={ Ωi}是图像空间 Ω \Omega Ω的子集集合。
记 d ^ \hat{d} d^是2D平面的线性函数:
d ^ ( x , y ) = a i x + b i y + c i \hat{d}(x,y)=a_ix+b_iy+c_i d^(x,y)=aix+biy+ci
v v v指代该模型在 Ω \Omega Ω中是否有效。
容忍偏差 δ \delta δ。
图像的模型估计,就是估计以上各个参数。