数据挖掘算法和实践(二十):sklearn中通用数据集datasets
作为数据挖掘工具包sklearn不但提供算法实现,还通过sklearn.datasets模块提供数据集使用,根据需要有3种数据集API接口来获取数据集,分别是load,fetch,generate,load提供常用玩具数据集,fetch提供大型数据集,generate可以根据需要定制化生产数据集;
通用数据集sklearn.dataset的使用应该放在算法及模型学习之前, 熟练使用能够快速进行模型测试和调优,可参考sklearn中文社区:sklearn.datasets模块使用详解,
一、load用于加载小的标准数据集(玩具数据集)
loda是一类以“load_”开头的函数,通过参数设置返回不同的数据集,其中return_X_y=True可以让该类函数输出只包含数据和只包含标签的数据,即X和y,X是数据集,y是标签值,举个栗子下面的几行代码直接得到波士顿房价预测数据,拿来训练模型;
# 使用load_boston()得到波士顿房价预测数据集
import sklearn.datasets as dataset
import seaborn
import pandas as pd
X,y=dataset.load_boston(return_X_y=True)
datas=pd.DataFrame(X)
prices=pd.DataFrame(y)
from sklearn.linear_model import LinearRegression
modelOne=LinearRegression()
modelOne.fit(datas , prices)
modelOne.score(datas , prices)这里可以看一下load_boston()的参数和返回类型的详细文档,return_X_y=True为参数返回data数据集(506,13),其中一列是预测值,返回的数据默认是ndarray类型,可以手动转换为pandas.dataframe,同时文档中提供数据的版本号和例子,如下:
Parameters
----------
return_X_y : bool, default=False.
If True, returns ``(data, target)`` instead of a Bunch object.
See below for more information about the `data` and `target` object.
.. versionadded:: 0.18
Returns
-------
data : :class:`~sklearn.utils.Bunch`
Dictionary-like object, with the following attributes.
data : ndarray of shape (506, 13)
The data matrix.
target : ndarray of shape (506, )
The regression target.
filename : str
The physical location of boston csv dataset.
.. versionadded:: 0.20
DESCR : str
The full description of the dataset.
feature_names : ndarray
The names of features
(data, target) : tuple if ``return_X_y`` is True
.. versionadded:: 0.18
Notes
-----
.. versionchanged:: 0.20
Fixed a wrong data point at [445, 0].
Examples
--------
>>> from sklearn.datasets import load_boston
>>> X, y = load_boston(return_X_y=True)
>>> print(X.shape)
(506, 13)
File: d:\anaconda3\lib\site-packages\sklearn\datasets\_base.py
Type: functionload这一类函数包括波士顿、鸢尾花、啤酒、癌症数据集等;
| 调用 | 描述 |
|---|---|
load_boston([return_X_y]) |
Load and return the boston house-prices dataset (regression). |
load_iris([return_X_y]) |
Load and return the iris dataset (classification). |
load_diabetes([return_X_y]) |
Load and return the diabetes dataset (regression). |
load_digits([n_class, return_X_y]) |
Load and return the digits dataset (classification). |
load_linnerud([return_X_y]) |
Load and return the linnerud dataset (multivariate regression). |
load_wine([return_X_y]) |
Load and return the wine dataset (classification). |
load_breast_cancer([return_X_y]) |
Load and return the breast cancer wisconsin dataset (classification). |
二、fetch提供真实数据集
跟load类数据集函数用法一样,fetch也是一类可加载的数据集,区别在于后者需要下载,load类函数在sklearn包下载时候已经在本地;
| 调用 | 描述 |
|---|---|
| fetch_olivetti_faces([data_home, shuffle, …]) | Load the Olivetti faces data-set from AT&T (classification). |
| fetch_20newsgroups([data_home, subset, …]) | Load the filenames and data from the 20 newsgroups dataset (classification). |
| fetch_20newsgroups_vectorized([subset, …]) | Load the 20 newsgroups dataset and vectorize it into token counts (classification). |
| fetch_lfw_people([data_home, funneled, …]) | Load the Labeled Faces in the Wild (LFW) people dataset (classification). |
| fetch_lfw_pairs([subset, data_home, …]) | Load the Labeled Faces in the Wild (LFW) pairs dataset (classification). |
| fetch_covtype([data_home, …]) | Load the covertype dataset (classification). |
| fetch_rcv1([data_home, subset, …]) | Load the RCV1 multilabel dataset (classification). |
| fetch_kddcup99([subset, data_home, shuffle, …]) | Load the kddcup99 dataset (classification). |
| fetch_california_housing([data_home, …]) | Load the California housing dataset (regression). |
三、generate类函数提供定制化数据需求
load和fetch提供有限的数据集合,大部分场景用的是generate类方法(以“make_”开头的系列函数)实现定制化数据需求,因为可以调整数据的维度、稀疏比例、噪声分布等,以make_blobs函数实现聚类数据为例,其默认生成100个高斯分布数据点(默认2个属性,3个类群),make_moons生成两个交错的半圆,经常用来衡量表示聚类算法的优劣程度,除了单标签generate还可以生成多标签的数据,参考文档;
# make_blobs得到可分的聚类数据集
from sklearn.datasets import make_blobs
import pandas as pd
import seaborn as seaborn
X,y=make_blobs(random_state=1)
datas=pd.DataFrame(X)
clusters=pd.DataFrame(y)
seaborn.scatterplot(datas[0],datas[1])
# 使用k均值进行聚类
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=3)
kmeans.fit(datas)
# make_moons得到
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=200,noise=0.05,random_state=0)
datas=pd.DataFrame(X)
clusters=pd.DataFrame(y)
seaborn.scatterplot(datas[0],datas[1])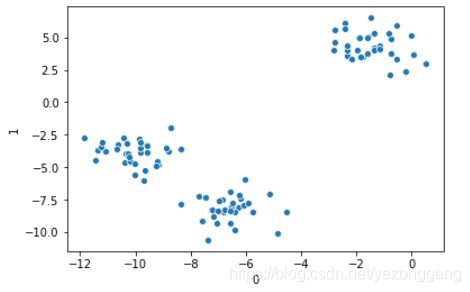 make_blobs生成数据
make_blobs生成数据
 make_moons生成数据
make_moons生成数据
make_blobs的官方文档:
Signature: dataset.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None, return_centers=False)
Docstring:
Generate isotropic Gaussian blobs for clustering.
Read more in the :ref:`User Guide `.
Parameters
----------
n_samples : int or array-like, optional (default=100)
If int, it is the total number of points equally divided among
clusters.
If array-like, each element of the sequence indicates
the number of samples per cluster.
.. versionchanged:: v0.20
one can now pass an array-like to the ``n_samples`` parameter
n_features : int, optional (default=2)
The number of features for each sample.
centers : int or array of shape [n_centers, n_features], optional
(default=None)
The number of centers to generate, or the fixed center locations.
If n_samples is an int and centers is None, 3 centers are generated.
If n_samples is array-like, centers must be
either None or an array of length equal to the length of n_samples.
cluster_std : float or sequence of floats, optional (default=1.0)
The standard deviation of the clusters.
center_box : pair of floats (min, max), optional (default=(-10.0, 10.0))
The bounding box for each cluster center when centers are
generated at random.
shuffle : boolean, optional (default=True)
Shuffle the samples.
random_state : int, RandomState instance, default=None
Determines random number generation for dataset creation. Pass an int
for reproducible output across multiple function calls.
See :term:`Glossary `.
return_centers : bool, optional (default=False)
If True, then return the centers of each cluster
.. versionadded:: 0.23
Returns
-------
X : array of shape [n_samples, n_features]
The generated samples.
y : array of shape [n_samples]
The integer labels for cluster membership of each sample.
centers : array, shape [n_centers, n_features]
The centers of each cluster. Only returned if
``return_centers=True``.
Examples
--------
>>> from sklearn.datasets import make_blobs
>>> X, y = make_blobs(n_samples=10, centers=3, n_features=2,
... random_state=0)
>>> print(X.shape)
(10, 2)
>>> y
array([0, 0, 1, 0, 2, 2, 2, 1, 1, 0])
>>> X, y = make_blobs(n_samples=[3, 3, 4], centers=None, n_features=2,
... random_state=0)
>>> print(X.shape)
(10, 2)
>>> y
array([0, 1, 2, 0, 2, 2, 2, 1, 1, 0])
See also
--------
make_classification: a more intricate variant
File: d:\anaconda3\lib\site-packages\sklearn\datasets\_samples_generator.py
Type: function 除了以上的三个方法,大部分使用pandas的读取数据API实现外部数据的读取和录入;