论文学习:Learning spatio-temporal features with 3D convolutional networks
0. 目录
Abstract & Contribution
Introduction
Learning Features with 3D ConvNets
3.1 2D 卷积 & 3D 卷积的区别
作者又提到了这篇文章与 [18] 的区别
这篇文章的主要工作
Common network settings
Varying network architectures
3.2 Exploring kernel temporal depth
3.3 Spatiotemporal feature learning
Dataset
Training
Sports-1M classification results
C3D video descriptor
What does C3D learn?
4. Action recognition Dataset
Things To Learn
Abstract & Contribution
- We experimentally show 3D convolutional deep networks are good feature learning machines that model appearance and motion simultaneously.
- We empirically find that 3 × 3 × 3 convolution kernel for all layers to work best among the limited set of explored architectures.
- The proposed features with a simple linear model outperform or approach the current best methods on 4 different tasks and 6 different benchmarks (see Table 1). They are also compact and efficient to compute.
Introduction
作者希望弄出一个 generic 的 video descriptor。他认为一个 generic 的 video descriptor 要有 4 个特性:
- generic:it can represent different types of videos well while being discriminative.
- compact:a compact descriptor helps processing, storing, and retrieving tasks much more scalable
- efficient:needs to be efficient to compute
- simple:be simple to implement
(之前已经有人做过了在视频上的 3D 卷积,证明在不同类型的视频分析任务上确实是有效果的:
[15] S. Ji, W. Xu, M. Yang, and K. Yu. 3d convolutional neural networks for human action recognition. IEEE TPAMI, 35(1):221–231, 2013. 1, 2
[18] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural)
所以作者并不是第一个在视频上用 3D 卷积的,而只是做了实验证明有用,所以这篇文章更像是图像分类领域的 VGG。后面作者在 Related Work 中介绍了这篇文章与 [15] 的区别:
[15] used a human detector and head tracking to segment human subjects in videos. The segmented video volumes are used as inputs for a 3-convolution-layer 3D ConvNet to classify actions. In contrast, our method takes full video frames as inputs and does not rely on any preprocessing, thus easily scaling to large datasets.

Learning Features with 3D ConvNets
3.1 2D 卷积 & 3D 卷积的区别

作者又提到了这篇文章与 [18] 的区别
Only the Slow Fusion model in [18] uses 3D convolutions and averaging pooling in its first 3 convolution layers. We believe this is the key reason why it performs best among all networks studied in [18]. However, it still loses all temporal information after the third convolution layer.
这篇文章的主要工作
In this section, we empirically try to identify a good architecture for 3D ConvNets.
由于 VGG 那篇文章里做过实验,说是用 “3*3 的卷积核 + 更深的网络结构” 效果更好。Hence, for our architecture search study we fix the spatial receptive field to 3 × 3 and vary only the temporal depth of the 3D convolution kernels.
Common network settings
- All video frames are resized into 128 × 171. Videos are split into non-overlapped 16-frame clips which are then used as input to the networks. The input dimensions are 3 × 16 × 128 × 171.
- random crops with a size of 3 × 16 × 112 × 112 of the input clips during training.
- The networks have 5 convolution layers and 5 pooling layers (each convolution layer is immediately followed by a pooling layer), 2 fully-connected layers and a softmax loss layer to predict action labels.
- The number of filters for 5 convolution layers from 1 to 5 are 64, 128, 256, 256, 256, respectively.
- All of these convolution layers are applied with appropriate padding (both spatial and temporal) and stride 1, thus there is no change in term of size from the input to the output of these convolution layers. All pooling layers are max pooling with kernel size 2 × 2 × 2 (except for the first layer) with stride 1 which means the size of output signal is reduced by a factor of 8 compared with the input signal.
- The first pooling layer has kernel size 1 × 2 × 2 with the intention of not to merge the temporal signal too early and also to satisfy the clip length of 16 frames (e.g. we can temporally pool with factor 2 at most 4 times be- fore completely collapsing the temporal signal).
- We train the networks from scratch using mini-batches of 30 clips, with initial learning rate of 0.003. The learning rate is divided by 10 after every 4 epochs. The training is stopped after 16 epochs.
Varying network architectures
- 1) homogeneous temporal depth: all convolution layers have the same kernel temporal depth:d = 1, 3, 5, 7
- 2) varying temporal depth: kernel temporal depth is changing across the layers:increasing: 3-3-5-5-7 and decreasing: 7- 5-5-3-3 from the first to the fifth convolution layer respectively.
作者还说明了:改变 kernel temporal depth 引起参数数量的改变相比起总参数来来说并没有太大的影响(仅有 0.3%),所以作者认为这点参数量的改变并不会引起网络的结果。
3.2 Exploring kernel temporal depth
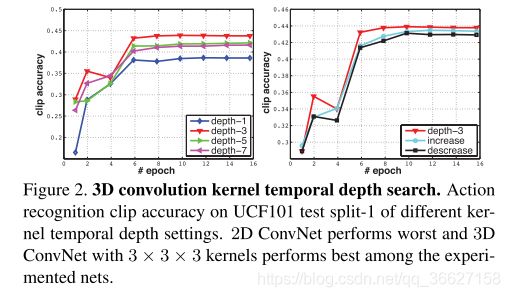
实验结论:
- 3 × 3 × 3 is the best kernel choice for 3D ConvNets (according to our subset of experiments)
- 3D ConvNets are consistently better than 2D ConvNets for video classification.(depth-1 is significantly worse than the other nets which we believe is due to lack of motion modeling. depth-1 net is equivalent to applying 2D convolutions on separate frames.)
3.3 Spatiotemporal feature learning

Dataset
Sports-1M:consists of 1.1 million sports videos. Each video belongs to one of 487 sports categories.
Training
- randomly extract five 2-second long clips from every training video.
- Clips are resized to have a frame size of 128 × 171. On training, we randomly crop input clips into 16×112×112 crops for spatial and temporal jittering.
- We also horizontally flip them with 50% probability.
- Training is done by SGD with mini-batch size of 30 examples.
- Initial learning rate is 0.003, and is divided by 2 every 150K iterations. The optimization is stopped at 1.9M iterations (about 13 epochs).
- Beside the C3D net trained from scratch / we also experiment with C3D net fine-tuned from the model pre-trained on I380K.
Sports-1M classification results

乍一眼,从表中看 C3D 相比起 Deep Video 和 Convolution pooling 两种方法的结果并没有很好,作者给出的解释是:
- Convolution pooling [29] uses much longer clips.【[29] 的方法 Clip hit 1 和 Video hit 1 的 Acc 差不多,因为它每个 clip 有 120 frames;而 DeepVideo 和 C3D Video(16 frames)的 hit 1 的 Acc 相比起 Clip hit 1 要高很多,说明 C3D 如果使用更复杂的 aggregation schemes (使用更多 frames)结果可以提更高】
- DeepVideo uses more crops: 4 crops per clip and 80 crops per video compared with 1 and 10 used by C3D, respectively. 【C3D use only a single center crop per clip, and pass it through the network to make the clip prediction. For video predictions, we average clip predictions of 10 clips which are randomly extracted from the video. 】
C3D video descriptor
作者在这里提出一种后面用于视频分类的通用视频描述符:将一个视频分割成 overlap = 8 的 16 帧 clips,将这些 clips 送入 C3D 网络中提取每个 clip 的 fc6 层的输出,再 average,再接一个 L2-正则化。
What does C3D learn?

论文观点:C3D starts by focusing on appearance in the first few frames and tracks the salient motion in the subsequent frames.
我的疑问:C3D 第5层卷积层得到的 feature map 反卷积可视化图中,每个 clip 给出了 16 张 feature maps,原文中说这 16 张是“ C3D conv5b feature maps with highest activations projected back to the image space. ”,所以应该是每个 clip 在第5层卷积层得到的 activations 值最高的 feature map? 如果是这样的话,那这些 feature maps 应该不存在时序关系,那为什么能说“文章认为在视频的前几帧,C3D 主要关注的是视频帧中的显著性区域,在之后的几帧中会跟踪这些显著变化的区域。”呢?
4. Action recognition Dataset
作者在 UCF101 上试了四种网络的效果:
- C3D trained on I380K + multi-class linear SVM
- C3D trained on Sports-1M + multi-class linear SVM
- C3D trained on I380K and fine-tuned on Sports-1M + multi-class linear SVM
- 以上三种 concatenate
实验发现:C3D trained on I380K and fine-tuned on Sports-1M + multi-class linear SVM 这种模型是最好的

上面是两个 baseline 方法,中间部分是只用 RGB 数据的方法,下面部分是结合多种 features
从表中可以看出,C3D + iDT 的效果最好,作者认为:it is beneficial to combine C3D with iDT as they are highly complementary to each other. In fact, iDT are hand-crafted features based on optical flow tracking and histograms of low-level gradients while C3D captures high level abstract/semantic information.
作者还认为 C3D descriptor 是 compact ,因为他们将抽取出来的特征用 PCA 降维再做实验对比分类正确率的结果。
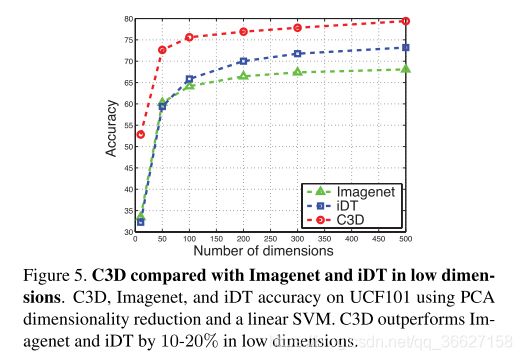
从这张图中看出,在最极端的情况下(只有 10 个维度),分类正确率可以比另外两种高很多。This indicates that our features are both compact and discriminative.
作者还认为 C3D descriptor 是 generic。
We randomly select 100K clips from UCF101, then extract fc6 features for those clips using for features from Imagenet and C3D. These features are then projected to 2-dimensional space using t-SNE [43].

Things To Learn
- improved Dense Trajectories (iDT)
- download Sports 1M + openCV 处理
- L2 normalization
- deconvolution