Kafka的分布式架构设计
一、Kafka的基本概述
1、Kafka是什么?
Kafka官网上对Kafka的定义叫:Adistributed publish-subscribe messaging system。publish-subscribe是发布和订阅的意思,所以准确的说Kafka是一个消息订阅和发布的系统。最初,Kafka实际上是LinkedIn用于日志处理的分布式消息队列,LinkedIn的日志数据容量大,但对可靠性要求不高,其日志数据主要包括用户行为(登录、浏览、点击、分享、喜欢)以及系统运行日志(CPU、内存、磁盘、网络、系统及进程状态)。
2、Kafka能做什么?
现今,Kafka主要用于处理活跃的流式数据,如分析用户的行为,包括用户的pageview(页面浏览),以便能够设计出更好的广告位,对用户搜索关键词进行统计以便分析出当前的流行趋势,比如经济学上著名的长裙理论:如果长裙的销量高了,说明经济不景气了,因为姑娘们没钱买各种丝袜了。当然还有些业务数据,如果存数据库浪费,而直接用传统的存硬盘方式效率又低下,这个时候,也可以使用Kafka的分布式进行存储。
3、Kafka中的相关概念
· Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。一台Kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以容纳多个topic。
· Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,Kafka中Topic可以理解为一个存储消息的队列。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存在一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处。
· Partition
Partition是物理上的概念,Kafka物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。如创建topic1和topic2两个topic,且分别有13个和19个Partition分区,则整个集群上相应会生成32个文件夹。为了实现扩展性,一个非常大的topic可以分布到多个broker上,但Kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
· Producer
负责发布消息到Kafkabroker。
· Consumer
消息消费者,向Kafkabroker读取消息的客户端。
· Consumer Group(CG)
这是Kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个 topic可以属于多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。每个consumer属于一个特定的Consumer Group, Kafka允许为每个consumer指定group name,若不指定group name则属于默认的group。
4、Kafka的特性:
1)数据在磁盘上存取代价为O(1),而一般数据在磁盘上是使用BTree存储的,存取代价为O(lgn)。
2)高吞吐率:即使在普通的节点(非常普通的硬件)上每秒钟也能处理成百上千的message。
3)显式分布式:即所有的producer、broker和consumer都会有多个,均匀分布并支持通过Kafka服务器和消费机集群来分区消息。
4)支持数据并行加载到Hadoop中。
5) 支持Broker间的消息分区及分布式消费,同时保证每个partition内的消息顺序传输。
6)同时支持离线数据处理和实时数据处理:当前很多的消息队列服务提供可靠交付保证,并默认是即时消费(不适合离线),而Kafka通过构建分布式的集群,允许消息在系统中累积,使得Kafka同时支持离线和在线日志处理。
7)Scale out:支持在线水平扩展。
二、Kafka的架构设计
1、 最简单的Kafka部署图
如果将消息的发布(publish)称作producer,将消息的订阅(subscribe)表述为consumer,将中间的存储阵列称作broker,这样可以得到一个最简单的消息发布与订阅模型:

2、Kafka的拓扑图:
Kafka是显示的分布式消息发布和订阅系统,除了有多个producer, broker,consumer外,还有一个zookeeper集群用于管理producer,broker和consumer之间的协同调用。
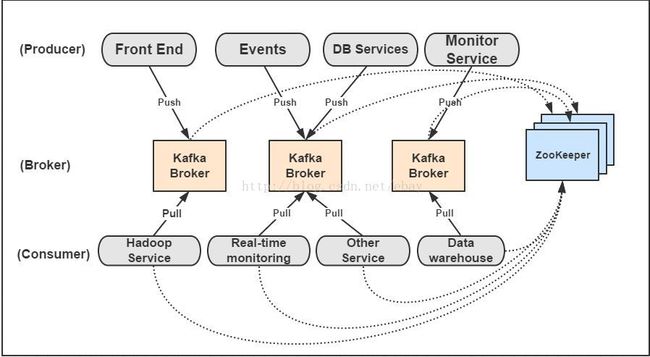
从图中可以看出,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的PageView,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
图上有个细节需要注意,Producer到Broker的过程是push,也就是有数据就推送到Broker,而Consumer到Broker的过程是pull,是通过Consumer主动去拉数据的,而不是Broker把数据主动发送到Consumer端的。
3、Zookeeper和Producer、Broker、Consumer的协同工作
为了便于理解,假定此时Kafka集群中有两台Producer,但只有一台Kafka的Broker、Zookeeper和Consumer。如下图所示的部署集群。

1、 Kafka Broker其实就是Kafka的server,Broker主要做存储用,每个Broker启动后会在Zookeeper上注册一个临时的broker registry,包含Broker的IP地址和端口号,所存储的topics和partitions信息。
2、Zookeeper,可以把Zookeeper想象成它维持了一张表,记录了各个节点的IP、端口等配置信息。
3、Producer1,Producer2,Consumer的共同之处就是都配置了zkClient,更明确的说,就是运行前必须配置Zookeeper的地址,道理也很简单,因为他们之间的连接都是需要Zookeeper来进行分发的。
4、Kafka Broker和Zookeeper可以放在一台机器上,也可以分开放,此外Zookeeper也可以配集群,这样就不会出现单点故障。
5、 每个Consumer启动后会在Zookeeper上注册一个临时的consumer registry:包含Consumer所属的Consumer Group以及订阅的topics。每个Consumer Group关联一个临时的owner registry和一个持久的offset registry。对于被订阅的每个partition包含一个owner registry,内容为订阅这个partition的consumer id,同时包含一个offset registry,内容为上一次订阅的offset。
整个系统运行的顺序可简单归纳为:
1、启动Zookeeper的server。
2、启动Kafka的server。
3、Producer如果生产了数据, 会先通过Zookeeper找到Broker,然后将数据存放进Broker。
4、Consumer如果要消费数据,会先通过Zookeeper找对应的Broker,然后消费。
Producer代码实例:
| producer = new Producer(...); message = new Message("Hello Ebay".getBytes()); set = new MessageSet(message); producer.send("topic1", set); |
发布消息时,Producer先构造一条消息,将消息加入到消息集set中(Kafka支持批量发布,可以往消息集合中添加多条消息,然后一次性发布), send消息时,client需指定消息所属的topic。
Consumer代码实例:
| streams[] = Consumer.createMessageStreams("topic1", 1); for (message : streams) { bytes = message.payload(); // do something with the bytes } |
订阅消息时,Consumer需指定topic以及partition num(每个partition对应一个逻辑日志流,如topic代表某个产品线,partition代表产品线的日志按天切分的结果),client订阅后,就可迭代读取消息,如果没有消息,client会阻塞直到有新的消息发布。Consumer可以累积确认接收到的消息,当其确认了某个offset的消息,意味着之前的消息也都已成功接收到,此时Broker会更新Zookeeper上的offset registry。
那么怎样记录每个Consumer处理的信息的状态呢?其实在Kafka中仅保存了每个Consumer已经处理数据的offset。这样有两个好处:一是保存的数据量少,二是当Consumer出错时,重新启动Consumer处理数据时,只需从最近的offset开始处理数据即可。
4、Kafka的存储策略
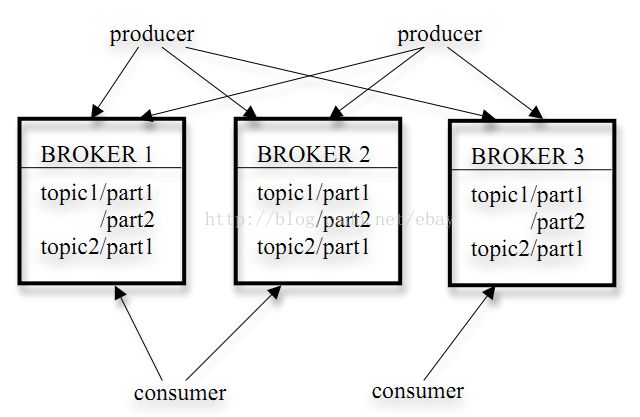
Kafka broker主要是用于做存储使用,每个broker上可存储很多的topic信息。
4、Kafka的存储策略
Kafka broker主要是用于做存储使用,每个broker上可存储很多的topic信息。

2、每个segment中存储多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3、每个partition在内存中对应一个index,记录每个segment中的第一条消息偏移。
4、Producer发到某个topic的消息会被均匀的分布到多个part上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应part的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
5、Kafka的deliveryguarantee
在Kafka上,有两个原因可能导致低效:太多的网络请求和过多的字节拷贝。为了提高网络利用率,Kafka把message分成一组一组的,每次请求会把一组message发给相应的consumer。 此外,为了减少字节拷贝,采用sendfile系统调用, sendfile比传统的利用socket发送文件进行拷贝高效得多。
Kafka支持有这几种delivery guarantee:
· Atmost once 消息可能会丢,但绝不会重复传输
· Atleast one 消息绝不会丢,但可能会重复传输
· Exactlyonce 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
6、Kafka多数据中心的数据流拓扑结构
实际设计中,有时由于安全性问题并不想让一个单个的Kafka集群系统跨越多个数据中心(数据中心之间可以进行通信),而是想让Kafka支持多数据中心的数据流拓扑结构。这可通过在集群之间进行镜像或“同步”实现。这个功能非常简单,镜像集群只是作为源集群的数据使用者(Consumer)的角色运行。这意味着,一个单个的集群就能够将来自多个数据中心的数据集中到一个位置。下面所示是可用于支持批量装载(batch loads)的多数据中心拓扑结构的一个例子:

请注意,在图中上方的两个集群之间不存在通信连接,两者可能大小不同,具有不同数量的节点,而下面部分中的这个单个的集群可以镜像任意数量的源集群。