Python 编程1000例(10):以当前日期时间批量创建文件及实现字符串与列表等数据的去重案例
文章目录
- 一、以当前日期时间批量创建文件
- 二、实现字符串与列表等数据的去重
本系列文章通过 1000(一篇文章表示 1 个实例) 个实例 ,为读者提供较为详细的练习题目,以便读者举一反三,深度学习。本系列的文章涉及到 Python 知识点包括:Python 语言基础、运算符和表达式、语句和程序结构、列表和元组、字典和集合、字符串、正则表达式、函数、面向对象编程、模块和包、异常处理和程序调试、文件和目录操作、数据库编程、界面编程、网络编程、WEB 编程、进程和线程、网络爬虫、游戏编程等知识点,由易到难,由浅入深,一步步打下坚实的编程基础。
本系列文章涉及的算法包括搜索、回溯、递归、排序、迭代、贪心、分治和动态规划等,涉及的数据结构包括字符串、列表、指针、区间、队列、矩阵、堆栈、链表、哈希表、线段树、二叉树、二叉搜索树和图结构等。
本系列文章是笔者为适应当前教育改革的创新要求,更好地践行语言类课程,满足实践教学与创新能力培养的需要,阅读大量书籍、各大互联网公司的面试算法、LintCode、LeetCode、九章算法和结合笔者近几年项目经验编写的系列文章,精选了 1000 个趣味性、实用性强的应用实例,从不同难度、不同算法、不同类型和不同数据结构等方面,将实际算法进行总结,希望为 Python 编程人员抛砖引玉。由于笔者经验与水平有限,博文中疏漏及不妥之处在所难免,衷心地希望各位读者在评论区多提宝贵意见及具体的修改建议,以便笔者进一步修改和完善。
一、以当前日期时间批量创建文件
需求:在平时的工作中,我们经常会遇到需要批量创建文件的情况,例如,汇总一个月中每天回复问题的文件、存储不同型号产品信息的相应文件等,要求使用 Python 以当前日期时间批量创建文件。示例效果如下:
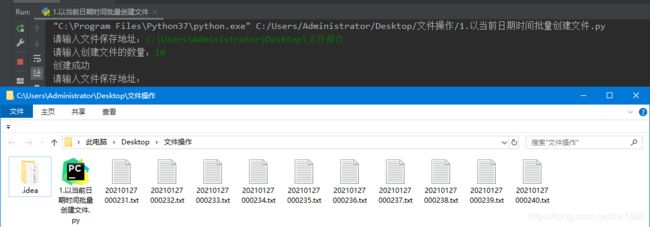
实现根据日期时间创建文件,首先使用 datetime 模块的 datetime.now()方法获取当前日期时间;然后使用 strftime()方法对获取到的日期时间进行格式化,获取要创建的文件名,最后使用open()方法创建相应的文件。关键代码如下:
import os
import datetime
import time
while True:
path = input("请输入文件保存地址:").strip() # 记录文件保存地址
num = int(input("请输入创建文件的数量:").strip()) # 记录文件创建数量
# 循环创建文件
for i in range(num):
t = datetime.datetime.now() # 获取当前时间
# 对当前时间进行格式化,作为文件名
file = os.path.join(path, t.strftime("%Y%m%d%H%M%S") + ".txt")
open(file, "w", encoding="utf-8") # 以UTF-8编码创建文件
time.sleep(1) # 休眠一秒钟
i += 1 # 循环标识加1
print("创建成功")
os.startfile(path) # 打开路径查看
在上面的案例当中使用了 os.startfile() 方法,该方法是用于使用关联的应用程序启动文件。语法格式如下:
def startfile(filepath, operation=None):
参数说明如下:
- path:表示要启动文件的路径。
- operation:可选参数,如果未指定,则相当于在 Windows 资源管理器中双击该文件,或者将文件名作为参数提供给交互式 Shell 的 start 命令中,文件将以关联的应用程序打开;否则必须是一个
命令动词,用来指定对文件做什么。常见动词有 print 和 edit (要在文件中使用),以及 explore 和 find (要在目录中使用).。 - 返回值:无。
使用系统默认的程序打开文本文件、图片文件、Word 文件和 PDF 文件,代码如下:
import os
# 导入文件与操作系统相关模块
os.startfile(r"e:/mot.txt") # 采用系统默认的编辑潜打开文本文件
os.startfile(r'e:/qrcode.png') # 采用系统默认的编辑器打开图片文件
os.startfile(r'e:/test1.docx') # 用系统默认的编辑潜打开word文件
os.startfile(r'e:/test2.pdf') # 采用系统默认的编辑器打开PDF文件
上面代码中的应用程序路径为博主计算机中所安装软件的路径,读者在编写代码时,需要根据实际情况进行修改。在上面的案例当中还使用了 os.path.join() 方法,join() 方法用于将两个或者多个路径拼接到一起组成一个新的路径。语法格式如下:
os.path.join(path,*paths)
参数说明:
- path:表示要拼接的文件路径。
- *paths:表示要拼接的多个文件路径,这些路径间使用逗号进行分隔。如果在要拼接的路径
中,没有一个绝对路径,那么最后拼接出来的将是一个相对路径。 - 返回值:拼接后的路径。
说明:使用 os.path.join() 方法拼接路径时,并不会检测该路径是否真实存在。示例代码如下:
import os # 导入模块
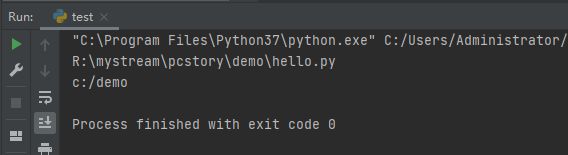
print(os.path.join(r"R:\mystream\pcstory", r"demo\hello.py")) # 拼接字符串
# 如果要拼接的路径中,存在多个绝对路径,那么按从左到右顺序,以最后一次出现的绝对路径为准,并且该路径之前的参数都将被忽略
print(os.path.join("E:/code", 'E:/python/amo', "Code", "c:/", "demo")) # 拼接字符串
程序运行结果如下:
注意:把两个路径拼接为一个路径时,不要直接使用字符串拼接,而是使用 os.path.join() 方法,这样可以正确处理不同操作系统的路径分隔符。
二、实现字符串与列表等数据的去重
需求:随着大数据、云技术等的发展,各行各业每天都会产生海量的大数据,如何让这些大数据逐步为人类创造更多的价值,为企业所用,已经成为互联网经济的核心发展方向。由于目前各行各业产生的大数据会有很多重复的数据,影响分析效率,因此进行大数据分析的第一步,是检测和消除其中的重复数据,通过数据去重,一方面是减少存储空间和网络带宽的占用;另一方面可以减少数据分析量。数据去重又称重复数据删除,是指在一个数据集合中,找出重复的数据并将其删除,只保存唯一的数据单元。要求定义如下字符串和列表,使用 Python 对其中重复的数据进行剔除。
name = "王李张李陈王杨张吴周王刘赵黄吴杨"
city = ["上海", "广州", "上海", "成都", "上海", "上海", "北京", "上海", "广州", "北京", "上海"]
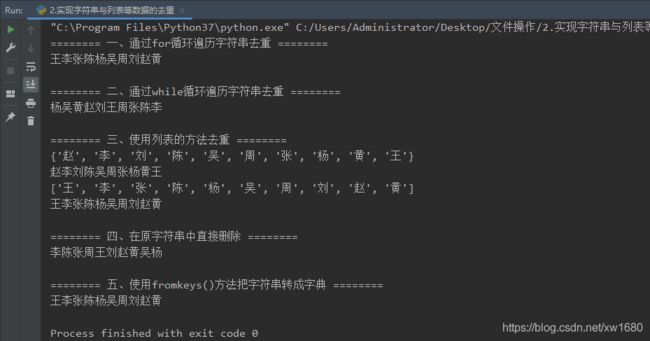
(1) 字符串去重的 5 种方法。下面通过 5 种方法对 “王李张李陈王杨张吴周王刘赵黄吴杨” 进行去重。示例代码如下:
# 一、通过for循环遍历字符串去重
print("======== 一、通过for循环遍历字符串去重 ========")
name = "王李张李陈王杨张吴周王刘赵黄吴杨"
new_name = ""
for char in name:
if char not in new_name: # 如果不在结果字符串中
new_name += char # 添加到结果字符串中
print(new_name)
print()
# 二、通过while循环遍历字符串去重
print("======== 二、通过while循环遍历字符串去重 ========")
new_name = ""
i = len(name) - 1 # 获取字符串的长度-1,即最大索引值
while True:
if i >= 0: # 如果还超出索引范围
if name[i] not in new_name:
new_name += name[i]
i -= 1
else: # 超出索引范围则结束循环
break
print(new_name)
print()
# 三、使用列表的方法去重
print("======== 三、使用列表的方法去重 ========")
my_name = set(name) # 转换为集合,则去除重复元素
print(my_name)
new_name = list(my_name) # 将集合转换为列表
print("".join(new_name)) # 将列表连接为字符串并输出
new_name.sort(key=name.index) # 对列表排序
print(new_name)
print("".join(new_name)) # 将排序后的列表连接为字符串并输出
print()
# 四、在原字符串中直接删除
print("======== 四、在原字符串中直接删除 ========")
L = len(name) # 字符串的长度
for s in name:
if name[0] in name[1:L]:
name = name[1:L]
else:
name = name[1:L] + name[0]
print(name)
print()
# 五、使用fromkeys()方法把字符串转成字典
print("======== 五、使用fromkeys()方法把字符串转成字典 ========")
name = "王李张李陈王杨张吴周王刘赵黄吴杨"
zd = {
}.fromkeys(name)
my_list = list(zd.keys())
print("".join(my_list))
程序运行结果如下:
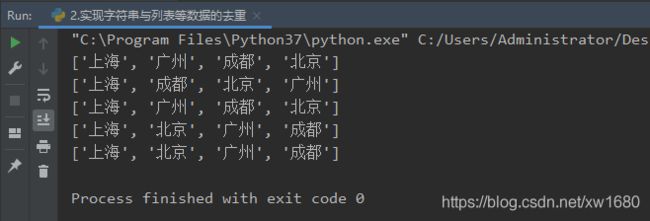
(2) 列表的去重方法,示例代码如下:
city = ["上海", "广州", "上海", "成都", "上海", "上海", "北京", "上海", "广州", "北京", "上海"]
# 方法一:for循环语句(不改变原来顺序)
n_city = []
for item in city:
if item not in n_city:
n_city.append(item) # 添加到新列表中
print(n_city)
# 方法二:set方法(改变原来顺序)
n_city = list(set(city))
print(n_city)
# 方法三:set方法(不改变原来顺序)
n_city = list(set(city))
n_city.sort(key=city.index)
print(n_city)
# 方法四:count()方法统计并删除,需要先排序(改变原来顺序)
city.sort()
for x in city:
while city.count(x) > 1:
del city[city.index(x)]
print(city)
# 方法五:把列表转成字典
my_list = list({
}.fromkeys(city).keys())
print(my_list)
程序运行结果如下:
感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!