SQL Server2016入门使用
初学SQL Server的基本操作和使用,每一种操作均可以在Microsoft SQL Server Management Studio中进行,也可以使用SQL脚本进行。本笔记主要记录脚本的具体操作方式。
一、数据库的结构
1、数据库的创建
创建的关键词为create。
create database testdb
on primary (
name ='testdb',
filename='F:\testdb.mdf',
size=10MB,
maxsize=100MB,
filegrowth=5MB
)
log on (
name='testdb_log',
filename='F:\testdb.ldf',
size=10MB,
maxsize=100MB,
filegrowth=5MB
)
第一个代码块是定义数据库的主文件,第二个代码块是定义log日志。
name\filename是名称;size为文件初始的大小;maxsize为文件每次增长的步长。
如上图,在单击运行后,创建数据库成功!
2、数据库的修改与删除
修改的关键词为alter、modify,删除的关键词为drop。
在当前要修改和删除的数据库下,新建查询,输入指令。
esec sp_helpdb testdb //查看testdb数据库的属性。
alter database testdb
modify name=testdb02 //修改数据库的名称
成功将数据库datadb名字修改为datadb02。上述指令只修改了数据库的名称,注意数据库的逻辑文件名称不能修改。只能对它的参数进行改动。
alter database testdb02
modify file(
name='testdb',
size=50MB,
maxsize=100MB,
filegrowth=5MB
);
下面删除数据库的命令,删库跑路警告【手动滑稽保命】。
drop database [testdb02];
3、数据类型
①、数字类型
| 数据类型 | 所占内存 | 范围 |
|---|---|---|
| bigint | 8字节 | -9223372036854775808~9223372036854775807 |
| int | 4字节 | -2147483648~2147483647 |
| smallint | 2字节 | -32768~23767 |
| tinyint | 1字节 | 0~255 |
| float | 取决于n的值 |
②、时间类型
| 数据类型 | 输出 |
|---|---|
| time | 19:13:29.1234567 |
| date | 2020-03-13 |
| smalldatetime | 2020-03-13 19:14:20 |
| datetime | 2020-03-13 19:13:29.123 |
③、字符串类型
| 数据类型 | 说明 |
|---|---|
| char(n) | n必须为1~8000之间的值,是固定长度。 |
| varchar(n) | n可以为1~8000之间的值,是可变长度。 |
| nchar(n) | 固定长度Unicode字符串数据,n必须为1~4000 |
| nvarchar(n) | 可变长度Unicode字符串数据,n必须为1~4000 |
Unicode为双字节编码,可以统一所有语言的编码。每一个字符均占用两个字节。
4、数据库中数据表的创建
-
若要创建表,需要提供表的名称以及该表每个列的名称和数据类型。指出每个列中是否允许空值。
-
设定一个主键,由表的某一列或者多列组成,注意主键是非空且不可重复的。
create table dbo.users //数据库所有者默认为dbo。
(ID int primary key not null, //新建ID属性,设为主键,非空。
name varchar(10) not null, //新建name属性,非空。
age int null //新建age属性,可为空。
)
5、数据库中数据表结构的修改
- 更改字段类型长度
alter table 表名
alter column 字段名 更改后类型的长度
例如:将name字段类型从 varchar(10) 修改为 varchar(100)
alter table dbo.users
alter column name varchar(100)
- 更改字段类型
alter table 表名
alter column 字段名 更改后的类型
例如:将age字段类型从 int 变成 float
alter table dbo.users
alter column age float
- 添加not null约束
alter table 表名
alter column 字段名 字段类型 not null
例如:将age字段设为不允许为空
alter table dbo.users
alter column age float not null
- 设置主键
alter table 表名
add constraint 主键名 primary key (字段名)
例如:将字段ID设置为主键,且主键名称为KID。
alter table dbo.users
add constraint KID primary key(ID)
- 更改字段名
alter table 表名
exec sp_rename ‘表名.字段名’, ‘更改后的字段名’, ‘column’
例如:将users表中的age 字段名称改为 ages
exec sp_rename 'users.age','ages','column'
- 添加字段名
alter table 表名
add 字段名 字段类型 default not null
例如:添加grade字段,为varchar类型,且不允许为空。
alter table users
add grade varchar(10) not null
- 删除表
drop table 表名
例如:删除users这张表。
drop table users
- 添加外键
例如:在从表 subsidiary 中增加一个外键 FK_user ,是依赖于主表main中的MAIN_no
alter table subsidiary
add constraint FK_user foreign key(SUB_no) references main (MAIN_no)
- 删除外键
例如:将从表 subsidiary 中的外键 FK_user删除。
alter table subsidiary
drop constraint FK_user
二、数据库的单表查询
数据库字段如下:
course(cno,cname,cpon,ccredit)
sc(sno,cno,score)
student(sno,sname,ssex,sage,sdept,sclass,sbirth,stime)
1、查询指定列
从sudent表中查询属性为sno和sname的两列
select sno,sname
from student;
2、查询全部列
*号码表示全部属性
select *
from student;
3、“虚”列
例如:查询全体学生的姓名以及出生年份。(出生年份使用2020-年龄即可得到)
select sname , 2020-sage
from student
查询结果如下图所示:新建的列没有列名,下面来添加列名。

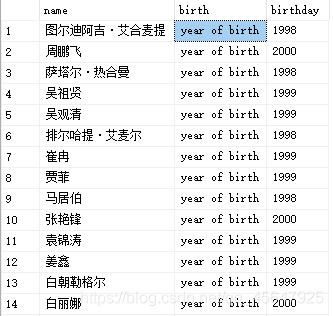
4、使用列别名改变查询结果的列标题
在要查询的属性后面加一个空格,跟上要指定的新列名即可。如下例:
此处的‘year of birth’为常量函数,所以每一行的属性均为‘year of birth’
select sname name,'year of birth'birth,2020-sage birthday
from student
运行结果如图:
5、取消重复的行
如果没有指定的distinct关键词,则缺省ALL
例如从student表中查询性别并去重:
select distinct ssex
from student
运行结果如图:

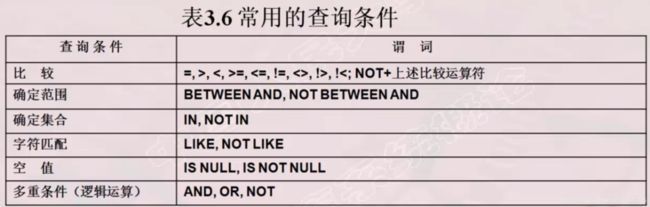
6、查询谓词的使用
下面是一些常见的查询谓词
- 例1:查询软件工程系的全体学生名单
select sname,sno ,sdept
from student
where sdept='软件工程'
运行结果如图:

- 例2:查询年龄小于20岁的学生的姓名和年龄
select sname,sage
from student
where sage<20
运行结果如图:
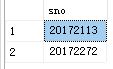
- 例3:查询有挂科记录的同学学号
select distinct sno
from sc
where score<60
运行结果如图:
- 例4:查询年龄不在20~22岁之间的学生的姓名(使用not between …and… 谓词)
select sname,sage
from student
where sage not between 20 and 22
运行结果如图:
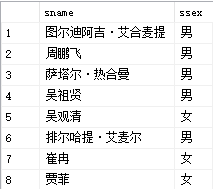
- 例5:查询软件工程系和计算机系的学生姓名和性别(使用in谓词)
select sname,ssex
from student
where sdept in ('软件工程','计算机')
--如果不适用谓词,则可以写成
--where sdept ='软件工程' or sdept= '计算机'
运行结果如图:
- 字符串的匹配
%代表任意长度(长度可以为0)的字符串,例如a%b代表以a开头,b结尾的任意长度的字符串。
_代表任意单个字符,例如a_b代表以a开头,以b结尾的长度为3的任意字符串。
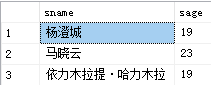
例6:查询所有名字中第二个子为元字的学生姓名和性别
select sname,ssex
from student
where sname like '_元%'
运行结果如图:
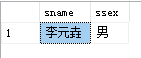
- 例7:查询姓李的名字为三个字的学生姓名和性别
select sname,ssex
from student
where sname like '李__'
运行结果如图:

- 例8:查询所有不姓程的同学的姓名和性别
select sname,ssex
from student
where sname not like '程%'
运行结果如图:
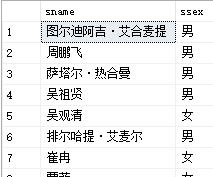
- 使用换码字符将通配符转义为普通字符
例9:查询以李_开头,且倒数第三个字为嘤的学生名字和性别
select sname,ssex
from student
where sname like '李\_%嘤__' escape'\'
其中,escape’'意为“\”为转义字符
运行结果如图:
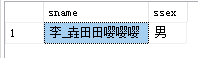
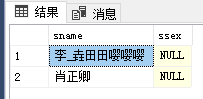
- 例10:查询性别未填写,即为NULL的同学(使用谓词is null,注意is不可用=代替)
select sname,ssex
from student
where ssex is null
- 多个运算的连接
使用and和or来进行。and的优先级高于or,并且可以使用括号来改变优先级。
如例5中的等价替换:
where sdept in ('软件工程','计算机')
如果不适用谓词,则可以写成
where sdept ='软件工程' or sdept= '计算机'
7、order by 子句
可以按照一个或多个属性列排序,asc为升序,desc为降序。默认的缺省值为升序。
对于空值,排序时显示的次序由具体的系统实现来决定。
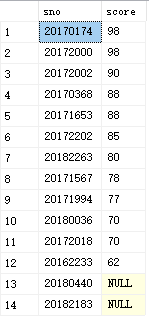
例11:查询选修了c1号课程的学生的学号以及成绩,查询结果按照分数降序排列
select sno,score
from sc
where cno='c1'
order by score desc
运行结果如图:
例12:查询全体学生情况,查询结果按照所在系的系号升序排列,同一系中学生按年龄降序排列。
select sdept,sage,ssex
from student
order by sdept asc,sage desc
从左到右依次为排序字段的优先级。

8、聚集函数的使用
1 .统计元组个数
语法规则:**count(*)**
例13:查询学生的总人数
select count(*)
from student
运行结果如下:
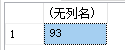
2. 统计一列中值的个数
语法规则:count (distinct 列名)
例14:查询选修了课程的学生人数
select count(distinct sno)
from sc
运行结果如图:

3. 计算一列值的中和
语法规则:sum (distinct 列名)
例15:查询学生20172018选修课程的总学分数
select sum(ccredit)
from sc,course
where sno='20172018'and sc.cno=course.cno
运行结果如图:
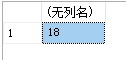
4 .计算一列值的平均值
语法规则:avg(distinct 列名)
例16:计算c1课程学生的平均成绩
select avg(score)
from sc
where cno='c1'
运行结果如图:
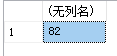
5 . 求一列中的最大值和最小值
语法规则:max(distinct 列名) 或者是 min(distinct 列名)
例17: 查询选修c1课程学生的最高分数
select max(score)
from sc
where cno='c1'
运行结果如图:
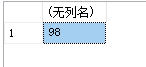
9、group by子句、having子句
group by 可以细化聚集函数的作用对象,如果未对查询结果分组,聚集函数将作用于整个查询结果。对查询结果分组后,聚集函数将分别作用于每一个组。
例18:求每个课程号以及相应的选课人数
select cno,count(sno)
from sc
group by cno
运行结果:
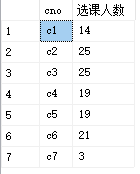
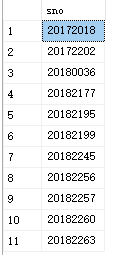
例19:查询选修了3门以上课程的学生学号
select sno
from sc
group by sno
having count(sno)>3
运行结果如图:
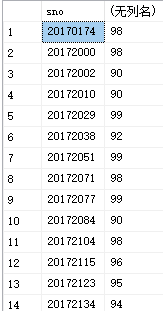
例20:查询平均成绩大于等于90分的学生学号和平均成绩
select sno,avg(score)
from sc
group by sno
having avg(score)>=90
运行结果如图所示:
总结:
- where子句作用于基表,即列,从中选择满足条件的元组。
- having子句作用于组,即新建的组,从中选择满足条件的组。
- where子句中不能有聚集函数表达式。
- 聚集函数只能用于group by …having子句(用于分类统计)或select子句(用于单项统计)。
- 当表中的原始字段和新建组字段在select中同时出现,必须使用group by子句,将原始字段包含进去。
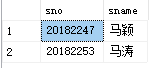
例21:列出软件工程系姓马且名字为两个字的同学的学号和姓名,并按照学号大小排序。
select sno,sname
from student
where sname like '马_'and sdept='软件工程'
order by sno asc
运行结果如图:
例22:按系并区分男女统计各系学生的人数、并按照人数降序排列。
select ssex,sdept,count(sno)
from student
group by ssex,sdept
order by count(sno) desc
运行结果如图:
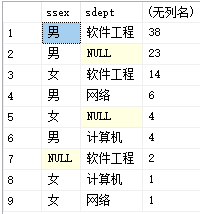
三、数据库的多表查询
1、连接查询
(1)、等值连接和非等值连接查询
等值连接:连接运算符为“=”
- 例1:查询每个学生及其选修课程的情况
select student.*,sc.*
from student,sc
where student.sno=sc.sno
--连接条件为student.sno=sc.sno
运行结果如下:
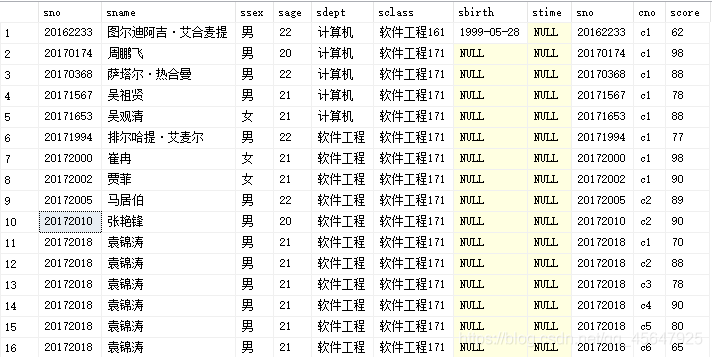
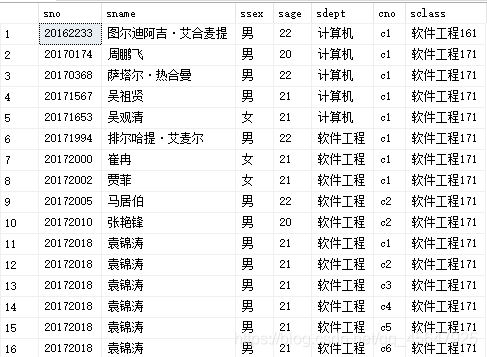
在上面的运行结果中,student.sno和sc.sno是重复冗余的,为了实现自然连接,可以手动将要展示的列在select语句中写出来,可采用以下代码
select student.sno,sname,ssex,sage,sdept,cno,sclass
from student,sc
where student.sno=sc.sno
运行结果如图:
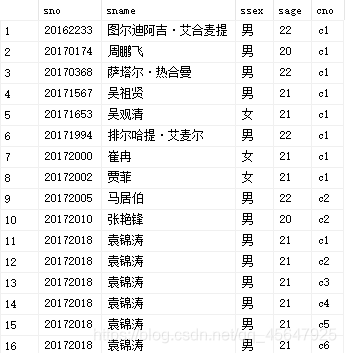
- 例2:查询选修了c2课程且成绩在90分以上的所有学生的学号和姓名
select sname,student.sno,score
from student,sc
where student.sno=sc.sno and sc.cno='c2'and score>90
运行结果如图:

(2)、自身连接
自身连接:一个表与自己进行连接,是一种特殊的连接,需要给表起别名以示区别
由于所有属性名都是同名属性,因此必须使用别名前缀
- 例3:查询每一门课的直接先修课的名称
select first.cname,second.cname
from course first,course second
where first.cpno=second.cno
运行结果如图:

(3)、外连接
普通连接操作只输出满足连接条件的元组。外连接操作以指定表为连接主体,将主体表中不满足连接条件的元组一并输出。
左外连接——列出左边关系中所有的元组
右外连接——列出右边关系中所有的元组
- 比如可以改写例1,查询每个学生及其选修课程的情况。可以使用左外连接
select student.sno,sname,ssex,sage,cno
from student
left join sc on
(student.sno=sc.sno);
运行截图如下:
(4)、多表连接
两个表以上进行连接
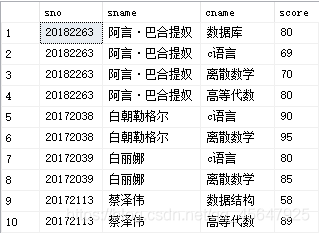
- 例4:查询每个学生的学号、姓名、选修的课程名及成绩
select student.sno,student.sname,course.cname,score
from student,sc,course
where student.sno=sc.sno and sc.cno=course.cno
运行结果如下:
2、嵌套查询
(1)、嵌套查询概述
- 一个select—from—where语句称为一个查询块
- 将一个查询块嵌套在另一个查询块的where子句或having短语的条件中的查询称为嵌套查询
- 上层的查询块称为外层查询或父查询
- 下层的查询块称为内层查询或子查询
- SQL语言允许多层嵌套查询
- 子查询中不能使用order by子句
(2)、嵌套查询求解方法
①、不相关子查询
子查询的查询条件不依赖于父查询,由里向外逐层处理。即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其父查询的查找条件。
②、相关子查询
子查询的查询条件依赖于父查询。
- 首先取外层查询中表的第一个元组,根据它与内层查询相关的属性值处理内层查询若where子句返回值为真,则取此元组放入结果表
- 然后再取外层表的下一个元组
- 重复这一过程,直至外层表全部检查完为止
(3)、带有IN谓词的子查询
例5:查询与“李元垚”在同一个系学习的学生。
分析:①先确定“李元垚”所在的系名
select sdepy
from student
where sname=‘李元垚’
此段代码运行结果为:‘软件工程’
然后再查询软件工程系的所有学生
select sno,sname,sdept
from student
shere sdept=‘软件工程’
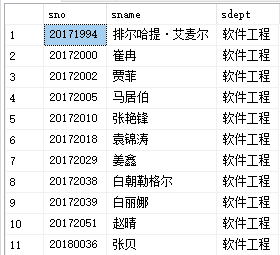
将上述两段代码合二为一,即可得到一个嵌套查询的语句
select sno,sname,sdept
from student
where sdept in
(select sdept
from student
where sname='李元垚')
此查询为不相关子查询,运行结果如图所示:
还可以用自身连接查询来完成
select s1.sno,s1.sname,s1.sdept
from student s1,student s2
where s2.sname='李元垚' and s1.sdept=s2.sdept
不相关子查询可以转换成相关的连接查询。
例6:查询选修了课程名为“数据结构”的学生学号和姓名
分析:①首先在course表中找出‘’“数据结构”课程的课程号
select cno
from course
where cname=‘数据结构’
得到数据结构课程号为‘c3’
②然后在sc表中找出选修了’c3’课程的学生学号
select sno
from sc
where cno=‘c3’
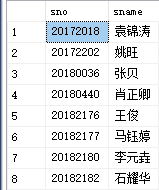
③在student表中取出对应的sno和sname
select sno,sname
from student
where sno in
(select sno
from sc
where cno =
(select cno
from course
where cname='数据结构'))
运行结果如图:
用连接查询实现该功能
select student.sno,student.sname
from student,sc,course
where course.cname='数据结构' and
course.cno=sc.cno and
sc.sno=student.sno
(4)、带有比较运算符的子查询
当能确切知道内层查询返回单值时,可用比较运算符(> ,< ,= ,>= ,<= ,!= 或< >)。
例7:找出每个学生超过他选修课程平均成绩的课程号
可以用相关子查询的思路来解决
需要找出每一个学生的平均分,再选出比平均分高的课程。
select sno,cno
from sc x
where x.score>=(
select avg(score)
from sc y
where x.sno=y.sno)
相关子查询的代码执行过程:
1、从外层查询中取出sc的一个元组x,将元组x的sno值传入内层循环,执行代码如下:
select avg(score)
from sc y
where y.sno=‘20182182’
2、假设执行上述内层查询,得到结果99,则继续返回执行外层查询。执行代码如下:
select sno,cno
from sc
where score>=99
3、假设上述查询可得到结果(20182182,c1) ,(20182182,c2)
4、按照上面三步再次循环,直到外层查询sc元组全部处理完毕。类似于双层for循环的执行。
(4)、带有any或all谓词的子查询
在SQL中,采用“谓词”的方式来表达存在量词和全称量词。
- 引入any和all谓词,其对象为某个查询结果,表示其中任意一个值或全部的值
- 引入exist谓词, 其对象也是某个查询结果,但表示这个查询结果是否为空,返回真值。
使用any和all谓词时必须同时使用比较运算符,具体用法如下表:
| 表示 | 含义 |
|---|---|
| > any | 大于子查询结果中的某个值 |
| > all | 大于子查询结果中的所有值 |
| < any | 小于子查询结果中的某个值 |
| > all | 小于子查询结果中的所有值 |
| >= any | 大于等于子查询结果中的某个值 |
| >= all | 大于等于子查询结果中的所有值 |
| <= any | 小于等于子查询结果中的某个值 |
| <= all | 小于等于子查询结果中的所有值 |
| = any | 等于子查询结果中的某个值 |
| = all | 等于子查询结果中的所有值 |
| != any | 不等于子查询结果中的某个值 |
| != all | 不等于子查询结果中的任何一个值 |
例8:查询非软件工程系中比软件工程系中任意一个学生年龄小的学生姓名和年龄
本题中要求非软件工程系学生比软件工程任意一个学生年龄小的学生,因为是“任意”,所以只要比年龄最大的学生小,即可满足题意。所以可使用谓词any或者是聚合函数max。
使用any谓词
select sname,sage
from student
where sage<any (
select sage
from student
where sdept='软件工程')
and sdept!='软件工程'
使用max集合函数
select sname,sage
from student
where sage< (
select max(sage)
from student
where sdept='软件工程')
and sdept!='软件工程'
运行结果相同,如下图:

例8:查询非软件工程系中比软件工程系中所有一个学生年龄小的学生姓名和年龄
本题中要求非软件工程系学生比软件工程所有学生年龄小的学生,因为是“所有”,所以只要比年龄最小的学生小,即可满足题意。所以可使用谓词all或者是聚合函数min。
使用all谓词
select sname,sage
from student
where sage<all(
select sage
from student
where sdept='软件工程')
and sdept!='软件工程'
使用min聚合函数
select sname,sage
from student
where sage<(
select min(sage)
from student
where sdept='软件工程')
and sdept!='软件工程'
通过以上例子可以发现谓词和聚合函数之间具有一定的转换关系。
- any,all,与聚合函数,in谓词的转换关系
| = | != | < | <= | > | >= | |
|---|---|---|---|---|---|---|
| any | in | - - | | <=max |
>min |
>=min |
|
| all | - - | not in | | <=min |
>max |
>=max |
|
(5)、带有exists谓词的子查询
- 带有 带有exists谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”。
- 若内层查询结果非空,则外层的where子句返回真值。
- 若内层查询结果为空,则外层的where子句返回假值。
- 由EXISTS 引出的子查询,其目标列表达式通常都用 * ,因为带exists的子查询只返回真值或假值,给出列名无实际意义。
例9:查询所有选修了c1课程的学生姓名
用相关子查询的思路来解决这个问题,查询涉及sc关系和student关系。
1、在student表中依次取出每个元组的sno值,用于检测sc中是否存在。
2、若存在且cno=‘c1’,则取出sname,并送入结果表。
select sname
from student
where exists (
select *
from sc
where student.sno=sc.sno and cno='c1')
运行结果如下:

- 所有带in谓词、比较运算符、any和all谓词的子查询都能用带exists谓词的子查询等价替换。
但是反过来不一定可行。
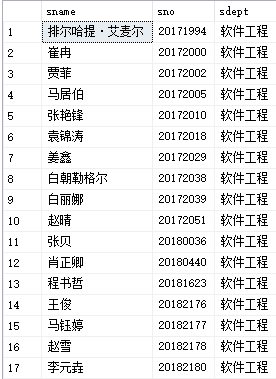
例10:查询"李元垚"在同一个系学习的学生(exists替换版本)
select sname,sno,sdept
from student a
where exists(
select*
from student b
where a.sdept=b.sdept and b.sname='李元垚')
运行结果如下:
例10:查询选修了全部课程的学生姓名。
not exists的用法:
若内层查询结果非空,则外层的where子句返回假值;
若内层查询结果为空,则外层的where子句返回真值;
最后将真值的sname显示出来。
假设一个同学选修了全部课程:内层循环因为能找到记录,所以返回假值。外层循环中因为子句的where为假值(即记录不存在),所以返回外层循环返回真值。每一门课程都不可以输出时,这个学号对应的元组才可以输出。表示这个学生选修了全部的课程。
假设一个同学有一门课程没选:内层循环会有一个值返回真值。所以外层循环会返回假的值,所以该同学的姓名不予显示。
select sname
from student
where not exists(
select *
from course
where not exists(
select *
from sc
where sno=student.sno and cno=course.cno))
(6)、用exists/not exists实现逻辑蕴涵
例11:查询至少选修了学生20182182选修的全部课程的学生学号。
用逻辑蕴涵表达式来表达该查询。
p:“学生20182182选修了课程y”
q:“学生x选修了课程y”
则可以表示为 任意p—>q
经过逻辑演算,可变为:不存在y(p∧¬q)
即:不存在这样的课程y,学生20182182选修了y,而学生x没有选。
3、集合查询
并操作:union
交操作:intrsect
差操作:except
参加集合操作的各查询结果的列数必须相同,对应项的数据类型也必须相同。
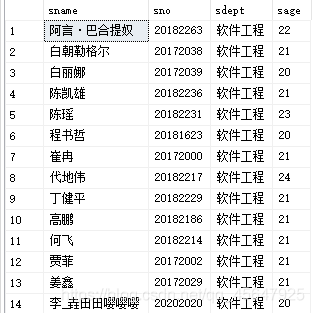
例12:查询软件工程系学生和年龄不大于19岁的学生。
select sname,sno,sdept,sage
from student
where sdept='软件工程'
union
select sname,sno,sdept,sage
from student
where sage<=19
- union:将多个查询结果合并起来,系统自动去掉重复元组。(与逻辑表达式中的or等价)
- union all:将多个查询结果合并起来,保留重复元组。
运行结果如下:
例13:查询软件工程系的学生与年龄不大于19岁的学生的交集。
select sname,sno,sdept,sage
from student
where sdept='软件工程'
intersect
select sname,sno,sdept,sage
from student
where sage<=19
- intersect 取两次查询的交集。(与逻辑表达式中的and等价)
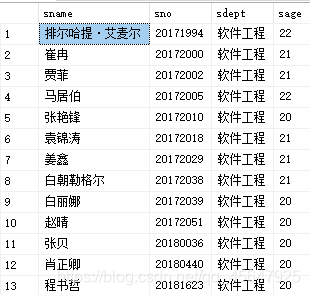
例13:查询软件工程系的学生与年龄不大于19岁的学生的差集。
select sname,sno,sdept,sage
from student
where sdept='软件工程'
except
select sname,sno,sdept,sage
from student
where sage<=19
- except 取两次查询的差集,本题中实际上是查询软件工程系中年龄大于19岁的学生。
运行结果如下:
4、查询语句总结
(1)、select语句的一般格式
select [all/distinct] <列表表达式> [别名]
from <表名或视图名> [别名]
join <表名> on <连接条件>
where <条件表达式>
group by <列名>
having <条件表达式>
order by <列名>
使用示例如下:
select student.sno,sname,avg(score)
from student
left join sc on student.sno=sc.sno
where student.sno like '2018%'
group by student.sno,sname
having avg(score)>60
order by avg(score)
(2)、目标表达式格式
- <表名>.*
- count (distinct sno)
- [< 表名>.] < 属性列名表达式> 如:student.sage+1
(3)、聚集函数的一般格式
(count、sum、avg、max、min)+(distinct/all 列名)
(4)、where子句的一般格式



四、数据更新
1、插入数据
(1)、插入元组
- 语法规则:
insert
into <表名><属性列1><属性列2>……
values(<常量1><常量2>……).
可以将新元组插入指定表中,属性列的顺序可以与表定义的顺序不一致,但是要与values里面的值相对应。如果没有规定的列,会自动取空值。
例1:插入一个新学生元组:(学号:20182233,姓名:李小布,性别:男,专业:‘软件工程’,姓名:21岁),插入到student表中
insert
into student (sno,sname,ssex,sdept,sage)
values('20182233','李小布','男','软件工程',21)
插入成功,运行结果如下图:
例2:在SC中插入一条选课记录,(‘20186666’,‘c1’)
insert into sc(sno,cno)
values('20186666','c1')
或者可以写成下面的样子,系统会把values里面的值对应到sc表中。
insert into sc
values('20186666','c1','NULL')
(2)、插入子查询结果
语法规则:insert into <表名> [<属性列>…]
子查询
例3:对每一个系,求学生的平均年龄,并把结果存入数据库。
题目要分为两步来做,首先建立新表,然后再插入数据。
第一步:建表
create table dept_age
(sdept char(15),
avg_age smallint
)
第二步:插入数据
insert into dept_age(sdept,avg_age)
select sdept,avg(sage)
from student
group by sdept
关系数据库管理系统会在执行插入语句时,检查所插元组是否破坏已定义的完整性规则。·
2、修改数据
- 语句格式
update <表名>
set <列名>=<表达式>
[where < 条件>];
例4:将学生20172018的年龄改为22岁
update Student
set sage=22
where sno='20172018'
例5:将所有学生年龄增加1岁
update Student
set sage=sage+1
例6:将软件工程系全体学生的成绩置为零
update sc
set score=0
where sno in(
select sno
from student
where sdept='软件工程')