深度学习环境配置综述——CUDA/cudnn/tensorflow三剑客
深度学习平常有所涉及,自己要捣鼓明白,有必要先从环境配置开始捣鼓,GPU加速训练是必不可少的,GPU加速的环境就是CUDA/cudnn/tensorflow这三样,本文试图将这一环境的众多细节介绍清楚。基于TF的Keras也差不多。要玩Pytorch就不在本文范围内了。
有必要叙述一下我的操作系统: CentOS ,想必Linux系统下都差不多?至少Ubuntu是差不多的。Windows系统怎么做有能力再写,不建议玩深度学习还用Windows的 ^.^
一. 前言
首先说明,深度学习这环境,不把许多细节弄清楚,可能在安装中/后,出现很多错误提示,不知所措。所以在自己捣鼓的时候也建议认真从头看。所以,前言部分是坠重要的。
1. 说明一下最重要的版本问题。最重要的放在前面说,简单一句话就是 CUDA、cudnn、tf 三者的版本是要一致的,而且一般不具有向下兼容的优点。下面列出版本对应的情况:
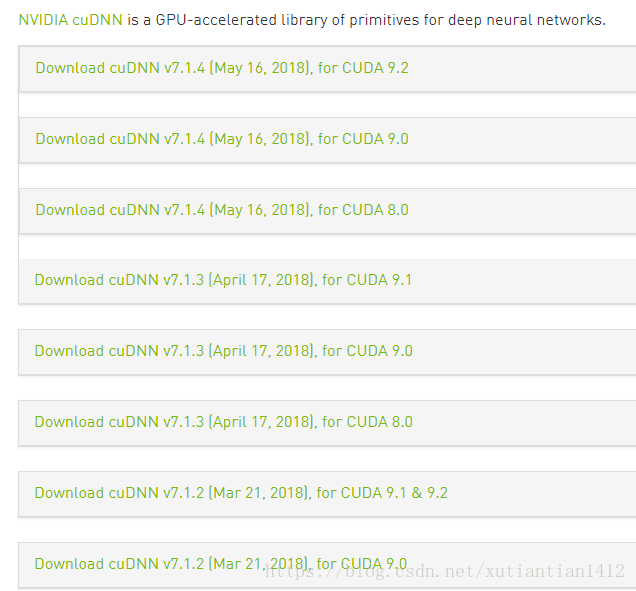
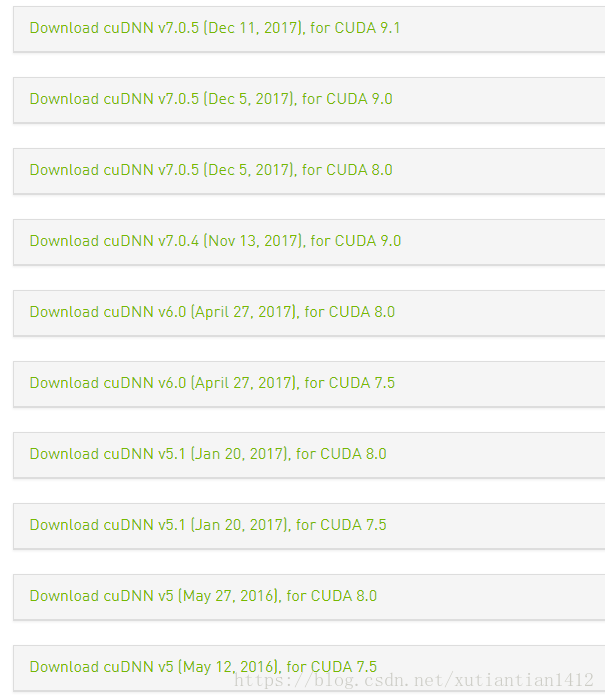
可以看到,CUDA 最新出了9.2,cudnn也各种版本跟随,到了7.1.4。简单来说,CUDA 9 对应 cudnn 7 ; CUDA 8 对应 cudnn 6。更低的版本可以不考虑了吧。
再了解一下 ,tensorflow的发展,目前最新似乎是1.9.0,但是即使是1.9.0 也仍然只是资词 CUDA 9.0。总结一下支持的版本是酱紫的:
CUDA 9.0以上的先不要用,因为tf 没有资词的版本;
第一种推荐的组合是 CUDA 9.0 + cudnn 7.0 + Tensorflow 1.5 以上(查了一下,应该是1.5以上的都用CUDA 9.0,如果嫩们用这个组合的话,建议再了解一下tf 的版本问题);
第二种推荐的组合很稳定,也是鄙人安装的版本,CUDA 8.0 + cudnn 6.0 + Tensorflow 1.4 。
PS: 当初服务器上前人安装的 CUDA 9.1,没有对应的tf 版本,查了各种教程,github上找到了有人改写了现有的 Tensorflow 1.6可以支持CUDA9.1,然而装上还是有错误,好久解决不了,愤而改了组合二。
2. 明白了1以后,给大家提供几个鄙人参考的博客和官方文档、网站,嫩们看这些不往下看我都博客也可以。
官方安装文档 NVIDIA CUDA Installation Guide for Linux, 为了捣鼓明白,鄙人确实认真的看了一部分;有篇博客算是翻译了一下: Ubuntu16.04超低配版显卡GTX730配置pytorch-gpu+cuda9.0+cudnn, 步骤介绍很简洁实用;
下面两个差不多,可以参考:
Ubuntu16.04安装tensorflow_gpu教程
CentOS 7 卸载CUDA 9.1 安装CUDA8.0 并安装Tensorflow GPU版 (本地查看远程服务器Tensorboard 也可以了解一下)
关于版本啊,各种细节,以及在win系统的一下情况,可以参考下面博客及其相关文章:
我的AI之路(5)--如何选择和正确安装跟Tensorflow版本对应的CUDA和cuDNN版本。关于安装那些事博主写了十余篇,十分佩服。
二. CUDA及cudnn安装
废话说完了,终于可以开始安装了~
1)先检查安装的条件
lspci | grep -i nvidia检查GPU是否支持cuda运算uname -m && cat /etc/*release确保你的系统支持cudagcc --version确保你已安装gccuname -r确保你的kernel版本满足安装需求(ubuntu16.04要求最低4.4)
2)然后下载CUDA和cudnn
下载也不是那么容易,在官网下载配套的二者,还需要注册账号之类的。CUDA下载 cudnn下载
可能速度也慢,但是提供了官网,有心思的可以去看看上面的东西。鄙人提供了自己的网盘,亲测可用的。而且是和我接下来的安装方法一致的(CUDA好像有两种安装方法)。
CUDA8+cudnn6网盘下载链接:https://pan.baidu.com/s/1IMNJGce6QRkA07KQtr7qsg 密码:v3bh
CUDA9+cudnn7网盘下载: 待添加
3)安装前
如果你跳过坑,安装了CUDA其他版本,可以卸载,如
cd /usr/local/cuda-9.1/bin
sudo ./uninstall_cuda_toolkit_9.1.pl鄙人没有卸载之前的CUDA9.1,直接安装8,也是可行的。(可能会有一些前提,如果你出错了,我也不知道)因为安装目录在/usr/local/下,cuda有链接指向当前版本,所以你在安装8的时候,有个提示,是否链接,只要链接了已安装的9.1就不起作用了。
Do you want to install a symbolic link at /usr/local/cuda
4)安装CUDA
安装文件为cuda_8.0.61_375.26_linux.run ,执行需要root权限。
chmod +x cuda_8.0.61* # 加上执行权限
./cuda_8.0.61_375.26_linux.run前面是长长的说明,略过后,选择同意;
第一个问题,是否安装NVIDIA驱动,这可能是一个问题,鄙人也不知其细节。 可供参考的情况是,有一次没安装,后来报错了(一般是指import tensorflow时候,后面会详细说),于是重新安装了驱动;又有一次,选择了安装NVIDIA,结果安装NVIDIA的时候失败,于是选择了不安装。(更: 建议自己安装NVIDIA驱动,选择合适的版本, 此处选择no,貌似他安装的有问题)
其他问题自己决定,默认装到/usr/local即可。
最后有一个samples的东东,如下

不打算看的话就不要安装了,想安装的话这样:到Samples目录,先make编译,然后到bin下找到deviceQuery,执行./deviceQuery,如果安装成功应该会显示类似如下信息:
|
5)安装cudnn
cuDNN的全称为NVIDIA CUDA® Deep Neural Network library,是NVIDIA专门针对深度神经网络(Deep Neural Networks)中的基础操作而设计基于GPU的加速库。cuDNN为深度神经网络中的标准流程提供了高度优化的实现方式,例如convolution、pooling、normalization以及activation layers的前向以及后向过程。
cuDNN只是NVIDIA深度神经网络软件开发包中的其中一种加速库。想了解NVIDIA深度神经网络加速库中的其他包请戳链接https://developer.nvidia.com/deep-learning-software。
基本上所有的深度学习框架都支持cuDNN这一加速工具,例如:Caffe、Caffe2、TensorFlow、Torch、Pytorch、Theano等。
江下载的这个文件cudnn-8.0-linux-x64-v6.0.solitairetheme8 改为 cudnn-8.0-linux-x64-v6.0.tgz (mv命令即可),复制到/usr/local目录下,然后解压即可:
tar -zxvf cudnn-8.0-linux-x64-v6.0.tgz这就OK了,其实是解压后文件夹内的文件,自动移动到了相应位置,相当于下面的命令:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn6)修改环境变量
环境变量是一个很复杂的问题。我只是按别人写的这么修改,出现什么偏差不负泽:
vim ~/.bashrc
添加:
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda
export PATH=$CUDA_HOME/bin:$PATH
source .bashrc当然,如果安装的CUDA9, 环境变量里也要换。
7)验证
验证CUDA是否安装成功是个激动人心的时刻。
命令 nvcc -V ,显示如下就成功了:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Tue_Jan_10_13:22:03_CST_2017
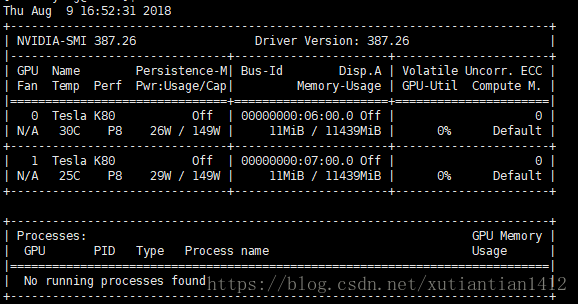
Cuda compilation tools, release 8.0, V8.0.61或者是 nvidia-smi,可以查看当前显卡及占用进程(加 -l 可以实时更新):
验证cudnn的话,下面的命令不报错即可
$ echo -e '#include"cudnn.h"\n void main(){}' | nvcc -x c - -o /dev/null -lcudnn
或者
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
显示结果如下
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 5
#define CUDNN_PATCHLEVEL 0
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
说明这是 7.5 版本的哈。
还可以看这篇博客,还是针对的win系统,很有借鉴意义: 深度学习配置CUDA8.0/9.0及对应版本cuDNN安装
文中提到了前面安装时说的 SAMPLES,貌似有一些功能,有机会有兴趣的话可以研究一番!
三. 安装Tensorflow-gpu
如果之前安装了其他tensorflow,应该先卸载。
pip uninstall tensorflow然后安装并钦定版本:
pip install tensorflow-gpu==1.4.0此时安装Keras也没有问题:
pip install keras安装成功后可以简单测试一下是否成功:
import tensorflow as tf # 如果import没有出偏差就基本上成功了
sess = tf.Session()
# 出现下面这样的各种gpu字样 表示GPU可用,成功
2018-08-09 17:28:48.342553: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
2018-08-09 17:28:48.677355: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:06:00.0
totalMemory: 11.17GiB freeMemory: 11.09GiB
2018-08-09 17:28:48.973653: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 1 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:07:00.0
totalMemory: 11.17GiB freeMemory: 370.88MiB
2018-08-09 17:28:48.973962: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1045] Device peer to peer matrix
2018-08-09 17:28:48.974022: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1051] DMA: 0 1
2018-08-09 17:28:48.974034: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1061] 0: Y Y
2018-08-09 17:28:48.974043: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1061] 1: Y Y
2018-08-09 17:28:48.974164: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Tesla K80, pci bus id: 0000:06:00.0, compute capability: 3.7)
2018-08-09 17:28:48.974184: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:1) -> (device: 1, name: Tesla K80, pci bus id: 0000:07:00.0, compute capability: 3.7)
# 我们也可以跑个运算看一下
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))运行结果如下的话,说明你的tensorflow-gpu版本成功:
MatMul: (MatMul): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-24 10:16:54.250346: I tensorflow/core/common_runtime/placer.cc:874] MatMul: (MatMul)/job:localhost/replica:0/task:0/device:GPU:0
b: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-24 10:16:54.250413: I tensorflow/core/common_runtime/placer.cc:874] b: (Const)/job:localhost/replica:0/task:0/device:GPU:0
a: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-24 10:16:54.250437: I tensorflow/core/common_runtime/placer.cc:874] a: (Const)/job:localhost/replica:0/task:0/device:GPU:0
[[ 22. 28.]
[ 49. 64.]]如果是下面这样,说明你用的是cpu版本:
MatMul: (MatMul): /job:localhost/replica:0/task:0/device:CPU:0
2018-06-29 15:04:57.366949: I tensorflow/core/common_runtime/placer.cc:874
b: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2018-06-29 15:04:57.367048: I tensorflow/core/common_runtime/placer.cc:874
a: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2018-06-29 15:04:57.367099: I tensorflow/core/common_runtime/placer.cc:874
[[22. 28.]
[49. 64.]]如果你不知道你的机器的情况,这一方法也可以用来判断。
四. 结束语
到此就大功告成了,当然前提是验证的时候没有什么报错的信息。结尾处简要提一下一些错误。
ImportError: libcudart.so.8.0: cannot open shared object file: No such file or directory出现这种 .so.8.0(如果安装的CUDA9,就是so.9.0;如果你的tf版本是1.5,而你安装的CUDA是8.0,那么这里也是so.9.0,也就是这是tf在倒入相应的库文件的过程),如果你确认版本对应没问题,那么这很可能是环境变量的问题了。
按照上面的教程设置的环境变量如果出现了这种偏差,建议检查一下,比如是否你安装的CUDA9 却全都照抄了我的= =,或者环境变量没有生效等问题。
最后总结一下,深度学习环境的配置,遵循下面的步骤:一是查看自己的机器配置、安装环境;二是三剑客之间的版本对应关系,选择合适的组合;三是下载及安装,多关注官方文档和官网;四是环境变量的配置;五是验证CUDA及Tensorflow是否成功。
五. TF 2.0版本的配置 —— 于2019/8/15
TF都2.0了,哪能继续用 tf 1.4/1.5什么的啊,版本太low了。于是自己又配置了新的环境,更新一下。当然,前面的基础知识不变。当然,你如果用 cpu来跑,什么也不用看。。
官方文档: https://www.tensorflow.org/install/gpu

因此,鄙人成功配置的对应版本为 NVIDIA 418.67 - CUDA 10.0 - cudnn 7.5.0 - Tensorflow2.0 alpha0 。
参考:
tensorflow各个版本的CUDA以及Cudnn版本对应关系
Tensorflow2.0 GPU版本安装(CUDA10.0 + cuDNN7.5 + Tensorflow2.0 Alpha)
其中nvidia驱动版本可以再旧一点,有个可查的表格,找不到了。。大概410.x 以上都可;
CUDA 必须是10.0 (还不资磁10.1别搞错);
cudnn 官网上写7.4.1,鄙人用7.5.0也正常,目前已出到7.6 没敢尝试。
给出网盘链接,省得下载费事:
ADDR:https://pan.baidu.com/s/1-hNpJw-MWUyGMca-Y0jj7Q
MM:np08
最后安装一下 TF
pip install tensorflow-gpu==2.0.0-alpha0
基本就这样了,只是补充一下TF2.0对应版本,下面我们测试一下:
import tensorflow as tf
tf.__version__
# '2.0.0-alpha0'
tf.test.is_gpu_available()
# 用于测试GPU是否可用 显示为True即可
"""
2019-08-15 11:16:29.810595: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-08-15 11:16:29.848969: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcuda.so.1
2019-08-15 11:16:29.987477: I tensorflow/compiler/xla/service/service.cc:162] XLA service 0x5594d9fb28f0 executing computations on platform CUDA. Devices:
2019-08-15 11:16:29.987549: I tensorflow/compiler/xla/service/service.cc:169] StreamExecutor device (0): Tesla K80, Compute Capability 3.7
2019-08-15 11:16:29.987571: I tensorflow/compiler/xla/service/service.cc:169] StreamExecutor device (1): Tesla K80, Compute Capability 3.7
2019-08-15 11:16:29.991982: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2199800000 Hz
2019-08-15 11:16:29.994561: I tensorflow/compiler/xla/service/service.cc:162] XLA service 0x5594da0d2aa0 executing computations on platform Host. Devices:
2019-08-15 11:16:29.994668: I tensorflow/compiler/xla/service/service.cc:169] StreamExecutor device (0): ,
2019-08-15 11:16:29.994996: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1467] Found device 0 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:06:00.0
totalMemory: 11.17GiB freeMemory: 11.05GiB
2019-08-15 11:16:29.995164: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1467] Found device 1 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:07:00.0
totalMemory: 11.17GiB freeMemory: 11.05GiB
2019-08-15 11:16:29.995427: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1546] Adding visible gpu devices: 0, 1
2019-08-15 11:16:29.995517: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.0
2019-08-15 11:16:29.999898: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1015] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-08-15 11:16:29.999938: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1021] 0 1
2019-08-15 11:16:29.999998: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1034] 0: N Y
2019-08-15 11:16:30.000014: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1034] 1: Y N
2019-08-15 11:16:30.000256: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1149] Created TensorFlow device (/device:GPU:0 with 10748 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:06:00.0, compute capability: 3.7)
2019-08-15 11:16:30.000854: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1149] Created TensorFlow device (/device:GPU:1 with 10748 MB memory) -> physical GPU (device: 1, name: Tesla K80, pci bus id: 0000:07:00.0, compute capability: 3.7)
Out[3]: True
"""