爬虫初体验——python爬取学院教师公开信息并存入Excel表格
爬虫初体验——python爬取学院教师公开信息并存入Excel表格
- 0 引言
- 1 单个教师信息爬取
- 2 多个教师信息爬取
- 3 将表存入excel表格中
- 4 总结
0 引言
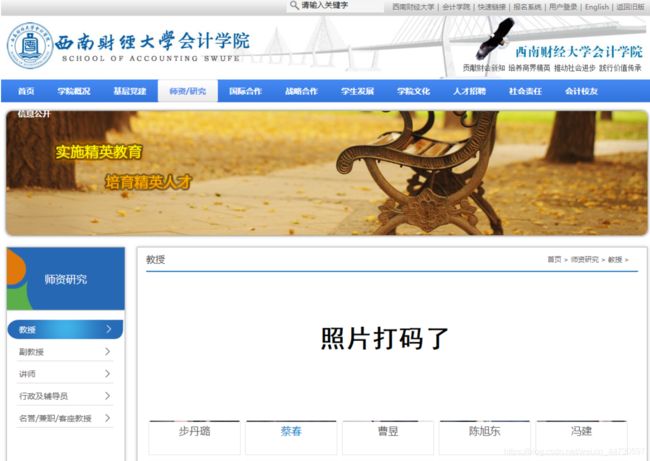
最近学习了爬虫技术,想自己写个小程序练练手。于是选取了西南财经大学会计学院的教师资料页面进行爬取。页面如下(将照片打码了)
1 单个教师信息爬取
在我看来,如果要逐个爬取教师信息,首先需要爬取单个教师的信息。以陈磊副教授为例,界面如下(照片已打码)

本个爬虫项目只爬取姓名,行政职务,系别,职称等信息。
很多网站在申请访问的时候没有请求头会不成功,或者返回乱码,所以需要写一个Header,伪装成浏览器进行访问。
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',
}
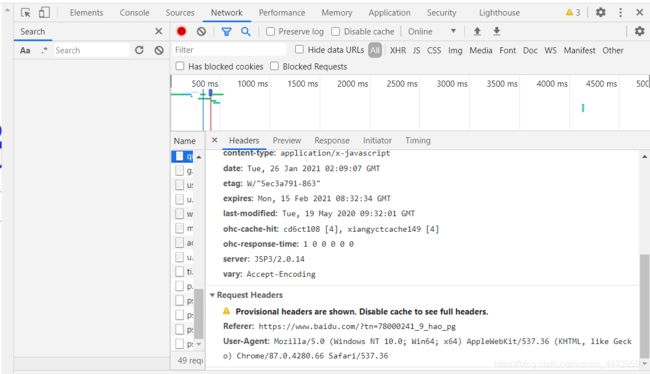
要获取自己浏览器的header也比较容易,以谷歌浏览器为例,按下F12,切换到Network,刷新页面后,任意选择一项点击。在最下方可以看到Request Header,这是浏览器的请求报头,复制其中的User-Agent即可。
令url2等于该老师的网址,data赋值为Request库中的get方法返回的HTML网页,第一个参数为要访问的网址url2,timeout是访问超时大于1秒就停止访问并报错(可要可不要,timeout的值也可以根据自己的需要修改)。
url2 = 'https://kj.swufe.edu.cn/info/1506/9681.htm'
data = requests.get(url2,headers = headers,timeout = 1)
MyHtml = data.text
print(MyHtml)
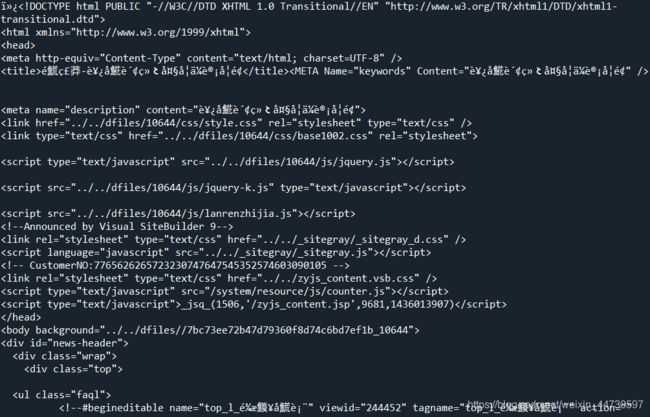
得到的结果如上图,发现乱码。根据查询资料,需要加上一行代码,data.encoding = “UTF-8”,因为windows中文默认不是UTF-8,而网页返回的第二行中默认的编码是UTF-8(第五行),修改后的本部分代码如下。
url2 = 'https://kj.swufe.edu.cn/info/1506/9681.htm'
data = requests.get(url2,headers = headers,timeout = 1)
data.encoding = "utf-8"
MyHtml = data.text
print(MyHtml)
返回的网页源码如下
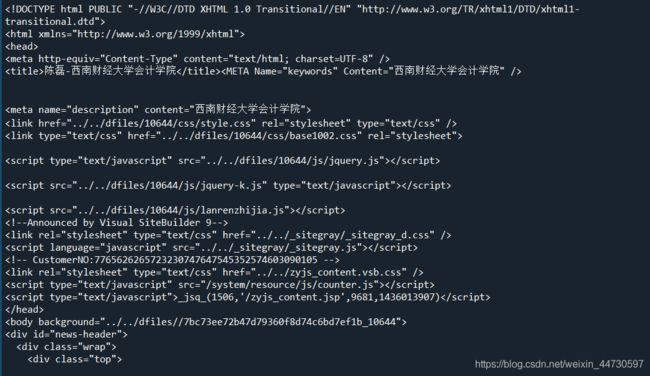
此时在结果中Ctrl+F,找到我们需要的部分的信息。

这一部分就是我们需要爬取的部分。此时可以通过re正则表达式来处理 pat1 = re.compile(‘行政职务:(.*?) ’),这条语句的作用是找到行政职务:和 之间的全部内容,然后type_two.extend(pat1.findall(MyHtml))是把行政职务内容都放入到type_one这个列表之中,最后可以进行导出。
这个地方有两点需要注意的点,第一是若只想匹配1个或以上的中文字,则可以用[\u4e00-\u9fa5]+来代表。第二是如果要匹配换行,则使用\r\n。
pat = re.compile('([\u4e00-\u9fa5]+)
\r\n')
pat1 = re.compile('行政职务:(.*?) ')
pat2 = re.compile('系别:(.*?) ')
pat3 = re.compile('职称:(.*?) ')
pat4 = re.compile('办公电话:(.*?) ')
pat5 = re.compile('Email:(.*?)\r\n')
type_one.extend(pat.findall(MyHtml))
#print(type_one)
type_two.extend(pat1.findall(MyHtml))
#print(type_two)
type_three.extend(pat2.findall(MyHtml))
#print(type_three)
type_four.extend(pat3.findall(MyHtml))
#print(type_four)
type_five.extend(pat4.findall(MyHtml))
#print(type_five)
type_six.extend(pat5.findall(MyHtml))
#print(type_six)
将上面的#去掉,则可以进行测试,看到底获得了什么信息。

获取到的信息与网页上看到的一致,行政职务和电话两行为空。
2 多个教师信息爬取
通过对副教授网页的初步判断,副教授网页满足一个式子
https://kj.swufe.edu.cn/info/1506/’+str(i)+’.htm
最开始的时候,我想用遍历的方法对每个副教授的信息进行爬取。代码块如下:
for i in range(9600,9800):
url2 = 'https://kj.swufe.edu.cn/info/1506/'+str(i)+'.htm'
后来发现在此范围内的网址不一定存在,9601是副教授,9602不一定是副教授,超时的话会自动停下来,所以这种遍历的方法是不可取的。
于是我想了下,从目录页面进行下手,目录页面有各个老师页面的超链接,于是对目录页面的源码进行返回,方法同上,代码如下。
#在索引页对该职称下所有老师的链接进行获取
firsturl = 'https://kj.swufe.edu.cn/szyj1/fjs.htm'
webdata = requests.get(firsturl,headers = headers,timeout = 1)
webdata.encoding = "utf-8"
MyHtml = webdata.text
print(MyHtml)
在得到的结果中Ctrl+F,找到1506,得到的结果如下

此时用正则式对编号进行匹配,将匹配到的数值存入到fujiaoshou[ ]中。
pat = re.compile('a href="../info/1506/(.*?).htm')
fujiaoshou.extend(pat.findall(MyHtml))
对fujiaoshou[ ]进行print操作,证实这种想法可行。
![]()
使用for循环,只改变编号的值,此时需要注意使用str(),即可完成对每一个老师的页面进行遍历。
for i in range(0,fujiaoshou.__len__()):
url2 = 'https://kj.swufe.edu.cn/info/1506/'+str(fujiaoshou[i])+'.htm'
#time.sleep(random.randint(10,12)) 如果爬大网站时需要用到,防止反爬虫机制
data = requests.get(url2,headers = headers,timeout = 1)
data.encoding = "utf-8"
MyHtml = data.text
pat = re.compile('([\u4e00-\u9fa5]+)
\r\n')
pat1 = re.compile('行政职务:(.*?) ')
pat2 = re.compile('系别:(.*?) ')
pat3 = re.compile('职称:(.*?) ')
pat4 = re.compile('办公电话:(.*?) ')
pat5 = re.compile('Email:(.*?)\r\n')
type_one.extend(pat.findall(MyHtml))
#print(type_one)
type_two.extend(pat1.findall(MyHtml))
#print(type_two)
type_three.extend(pat2.findall(MyHtml))
#print(type_three)
type_four.extend(pat3.findall(MyHtml))
#print(type_four)
type_five.extend(pat4.findall(MyHtml))
#print(type_five)
type_six.extend(pat5.findall(MyHtml))
#print(type_six)
dict = {
'名字':type_one,
'行政职务':type_two,
'系别':type_three,
'职称':type_four,
'办公电话':type_five,
'Email':type_six}
new_frame = pd.DataFrame(dict)
print(new_frame)
得到的部分结果如下
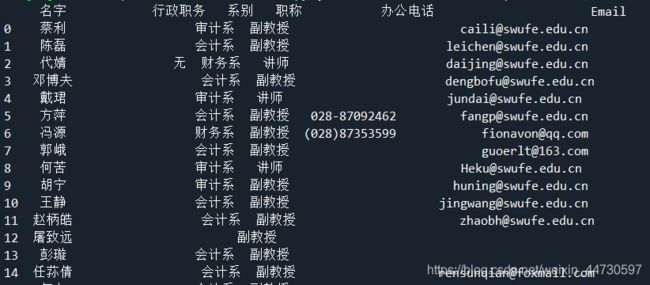
3 将表存入excel表格中
代码如下
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding = 'utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('会计学院副教授名册')
# 写入excel
# 参数对应 行, 列, 值
worksheet.write(0,0,'名字') #在1行1列写名字
worksheet.write(0,1,'行政职务') #在1行2列写行政职务
worksheet.write(0,2,'系别') #在1行3列写系别
worksheet.write(0,3,'职称') #在1行4列写职称
worksheet.write(0,4,'办公电话') #在1行5列写办公电话
worksheet.write(0,5,'Email') #在1行6列写Email
for i in range(1,fujiaoshou.__len__()):
worksheet.write(i,0,new_frame['名字'][i-1])
worksheet.write(i,1,new_frame['行政职务'][i-1])
worksheet.write(i,2,new_frame['系别'][i-1])
worksheet.write(i,3,new_frame['职称'][i-1])
worksheet.write(i,4,new_frame['办公电话'][i-1])
worksheet.write(i,5,new_frame['Email'][i-1])
# 保存
workbook.save('会计学院老师名册.xls')
结果如下
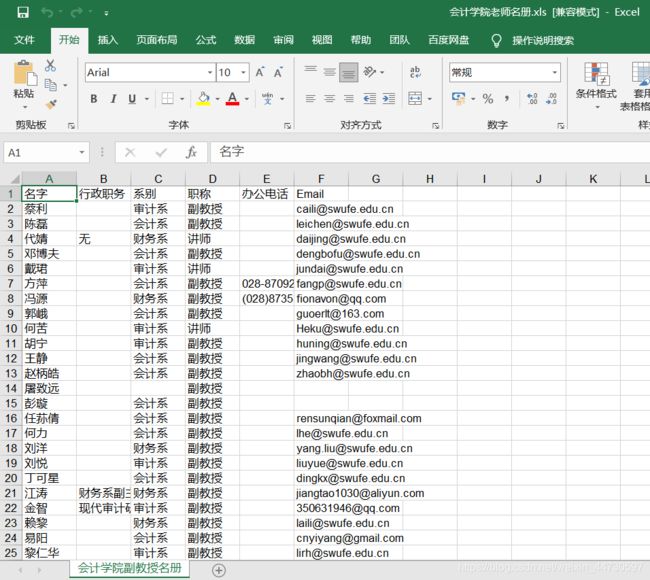
4 总结
经过这次爬虫程序的编写,我对爬虫的机制与技巧有了初步的了解。
1、爬虫是根据网页源码的特点进行匹配,匹配到了我们需要的信息进行保存。重点就是找到匹配信息的格式,写出正确的正则式进行匹配。
2、爬虫需要对网址的格式进行判断, 遍历是一种很好的方法(比如爬取淘宝评论,以及一些网址有规律的页面时),遍历不可取的时候,则需要考虑以其他方式获取所有页面的信息,此时目录是一个很好的切入点。