BM3D图像去噪算法原理及代码详解

1. BM3D 算法简介
BM3D是2007年TIP的文章,题目是Image denoising by sparse 3D transform-domain collaborative ltering,论文、项目的地址是http://www.cs.tut.fi/~foi/GCF-BM3D/,提供matlab代码。
处理灰度图的BM3D以及它的变体CBM3D(彩色图)、VBM3D(时域)是图像去噪领域公认的去噪效果(PSNR)最好的,而BM4D、VBM4D等也都是沿袭BM3D的基于块处理(block-wise estimate)的思想,但其计算时间复杂度极大,或许只能用于离线处理(offline),当然后续有文章进行优化(代码、算法),这里就不再提及。
2. 算法流程介绍
算法总体流程如图:
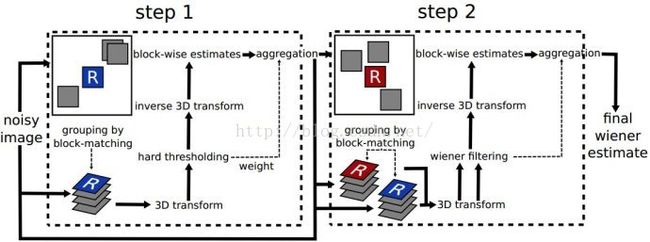
主要分为以下两大步:
第一步,基础估计:
1、对于每个目标图块,在附近寻找最多MAXN1(超参数)个相似的图块,为了避免噪点的影响,将图块经过2D变换(代码中使用DCT变换)后再用欧氏距离衡量相似程度。按距离从小到大排序后取最多前MAXN1个。叠成一个三维数组。

2、对3D数组的第三维,即图块叠起来后,每个图块同一个位置的像素点构成的数组,进行DCT变换后,采用硬阈值的方式将小于超参数 [公式] 的成分置为0。同时统计非零成分的数量作为后续权重的参考。后将第三维进行逆变换。

为什么要这么做?
传统方法,如NLM,由空域得到近似块,然后对近似块的每个像素一一对应去平均,作为目标块每个像素的值。但是,上述策略对于如下场景并不合适:
- i. 某些相似块拥有的噪声更小,相比其它相似块,该块的“权重”应更大,而不是简单取平均
- ii. 相似块图像信息冗余,从空域上看,两个有重叠区域的相似块,简单平均会造成目标块信息重复。
因此采用“Collaborative ltering by shrinkage in transform domain”的方式,能够加强相似块的稀疏性,同时降低相似块的噪声。

3、将这些图块逆变换后放回原位,利用非零成分数量统计叠加权重,最后将叠放后的图除以每个点的权重就得到基础估计的图像,此时图像的噪点得到了较大的去除。
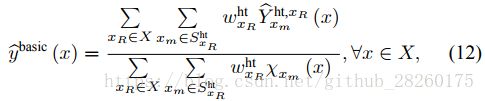
第二步,最终估计:
1、由于基础估计极大地消除了噪点,对于含噪原图的每个目标图块,可以直接用对应基础估计图块的欧氏距离衡量相似程度。按距离从小到大排序后取最多前MAXN1个。将基础估计图块、含噪原图图块分别叠成两个三维数组。

2、对含基础估计3D数组的第三维,即图块叠起来后,每个图块同一个位置的像素点构成的数组,进行DCT变换,利用如下公式得到系数。
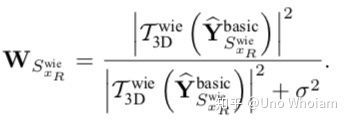
3、将系数与含噪3D图块相乘放回原处,最后做加权平均调整即可得到最终估计图。相对于基础估计图,还原了更多原图的细节。

3. 加速
在实际操作中,为加快BM3D的计算速度,在寻找相似块的步骤后,得到的块实际上已经进行了2D变换处理,然后再加上一个1D变换(文中使用1D-Haar离散小波变换),成为3D变换,使用2D+1D的变换方法替代直接3D变换。
4. 难点
文中提到的2D变换与各种超参数,并没有一个确定值,对于真实视频去噪,使用的2D变换与超参数可能与文章实验设置不同,因此需要进行微调,也就是需要大量实验的积累。
最终的去噪结果如下图所示,可以发现,噪声被很好地去除了,图像边缘保留完整,图像纹理得到了很好的还原。

但这些都是自行添加高斯白噪声产生的测试图像,若实际运用在图像降噪中,原始图像不会有这么多噪声,因此就不需要BM3D两步去噪。那么可以将BM3D的两步拆开,采用前步的硬阈值、2D变换寻找相似块、1D变换升至3D域再加权平均,或后步直接使用维纳滤波,或许就已经有很好的效果了。
4. C-BM3D
针对彩色图,本文将图像的RGB色彩空间转换为YUV色彩空间,因为YUV的Y分量拥有较其余分量更多的图像信息(边缘、材质、纹理等),并且拥有更高的SNR(信噪比),而U、V分量拥有更多的低频信息。
因此对于C-BM3D,本文使用Y分量搜寻相似块,U、V分量使用Y分量的相似块位置信息。
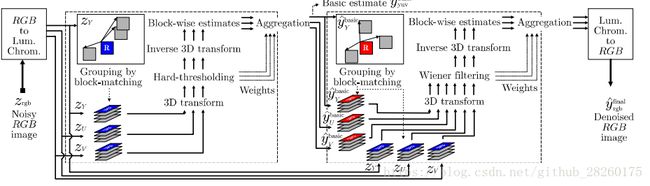
可以仿照他转换色彩空间、从Y分量搜索相似块的方法,来对彩色图像进行降噪处理。
5. VBM3D
对于视频去噪,一是可以将视频转化为单帧图像,然后使用图像去噪算法对单帧进行处理,然后融合还原成已去噪的视频;二是根据视频前后帧信息,某个像素点,前帧没有噪声,或噪声较少,那么就可以作为后帧的值,但视频中物体是运动的,如果按前后帧的同一位置的像素处理是不合理的,因此会引入运动补偿、跟踪的算法,对于实时处理来说,条件就有点苛刻。
VBM3D不含运动补偿,对中间帧的目标块搜索相似块,搜索对象是前后帧与中间帧,提出了predictive-search block-matching(PS-BM),用于前后帧的相似块搜索。具体而言,PS-BM,先以中间帧的目标块为中心、搜索半径NS的区域寻找相似块,然后在该块对应的前后帧的位置为中心、搜索半径NPR的区域寻找相似块,中间帧、前后帧的相似块构成块集合。其余步骤与BM3D无异。

6. 代码实现
# -*- coding: utf-8 -*-
"""
*BM3D算法简单实现,主要程序部分
"""
import cv2
import numpy
import math
import numpy.matlib
cv2.setUseOptimized(True)
# Parameters initialization
sigma = 25
Threshold_Hard3D = 2.7 * sigma # Threshold for Hard Thresholding
Step1_Blk_Size = 4 # block_Size即块的大小
Step1_Blk_Step = 1 # Rather than sliding by one pixel to every next reference block, use a step of Nstep pixels in both horizontal and vertical directions.
Step1_Search_Step = 1 # 块的搜索step
First_Match_threshold = 125 * Step1_Blk_Size ** 2 # 用于计算block之间相似度的阈值
Step1_max_matched_cnt = 16 # 组最大匹配的块数
Step1_Search_Window = 15 # Search for candidate matching blocks in a local neighborhood of restricted size NS*NS centered
Step2_Blk_Size = 4
Step2_Blk_Step = 1
Step2_Search_Step = 1
Second_Match_threshold = 220. / 16 * Step2_Blk_Size ** 2 # 用于计算block之间相似度的阈值
Step2_max_matched_cnt = 32
Step2_Search_Window = 25
Beta_Kaiser = 1.5
def init(img, _blk_size, _Beta_Kaiser):
"""该函数用于初始化,返回用于记录过滤后图像以及权重的数组,还有构造凯撒窗"""
m_shape = img.shape
m_img = numpy.matrix(numpy.zeros(m_shape, dtype=float))
m_wight = numpy.matrix(numpy.zeros(m_shape, dtype=float))
# 窗函数(window function)是一种除在给定区间之外取值均为0的实函数
K = numpy.matrix(numpy.kaiser(_blk_size, _Beta_Kaiser))
m_Kaiser = numpy.array(K.T * K) # 构造一个凯撒窗
# 窗函数:https://zh.wikipedia.org/wiki/窗函数#Kaiser窗
# print m_Kaiser, type(m_Kaiser), m_Kaiser.shape
# cv2.imshow("Kaisser", m_Kaiser)
# cv2.waitKey(0)
# cv2.imwrite("Kaisser.jpg", m_Kaiser.astype(numpy.uint8))
return m_img, m_wight, m_Kaiser
def Locate_blk(i, j, blk_step, block_Size, width, height):
'''该函数用于保证当前的blk不超出图像范围'''
if i * blk_step + block_Size < width:
point_x = i * blk_step
else:
point_x = width - block_Size
if j * blk_step + block_Size < height:
point_y = j * blk_step
else:
point_y = height - block_Size
m_blockPoint = numpy.array((point_x, point_y), dtype=int) # 当前参考图像的顶点
return m_blockPoint
def Define_SearchWindow(_noisyImg, _BlockPoint, _WindowSize, Blk_Size):
"""
该函数利用block的左上顶点的位置返回一个二元组(x,y)
用以界定_Search_Window左上角顶点坐标
"""
point_x = _BlockPoint[0] # 当前坐标
point_y = _BlockPoint[1] # 当前坐标
# 获得SearchWindow四个顶点的坐标
LX = point_x + Blk_Size / 2 - _WindowSize / 2 # 左上x
LY = point_y + Blk_Size / 2 - _WindowSize / 2 # 左上y
RX = LX + _WindowSize # 右下x
RY = LY + _WindowSize # 右下y
# 判断一下是否越界
if LX < 0:
LX = 0
elif RX > _noisyImg.shape[0]:
LX = _noisyImg.shape[0] - _WindowSize
if LY < 0:
LY = 0
elif RY > _noisyImg.shape[0]:
LY = _noisyImg.shape[0] - _WindowSize
return numpy.array((LX, LY), dtype=int)
def Step1_fast_match(_noisyImg, _BlockPoint):
"""快速匹配"""
'''
*返回邻域内寻找和当前_block相似度最高的几个block,返回的数组中包含本身
*_noisyImg:噪声图像
*_BlockPoint:当前block的坐标及大小
'''
(present_x, present_y) = _BlockPoint # 当前坐标
Blk_Size = Step1_Blk_Size
Search_Step = Step1_Search_Step
Threshold = First_Match_threshold
max_matched = Step1_max_matched_cnt
Window_size = Step1_Search_Window
blk_positions = numpy.zeros((max_matched, 2), dtype=int) # 用于记录相似blk的位置
Final_similar_blocks = numpy.zeros((max_matched, Blk_Size, Blk_Size), dtype=float) # 用于保存最后结果
img = _noisyImg[present_x: present_x + Blk_Size, present_y: present_y + Blk_Size]
dct_img = cv2.dct(img.astype(numpy.float64)) # 对目标作block作二维余弦变换
Final_similar_blocks[0, :, :] = dct_img # 保存变换后的目标块
blk_positions[0, :] = _BlockPoint
Window_location = Define_SearchWindow(_noisyImg, _BlockPoint, Window_size, Blk_Size)
blk_num = (Window_size - Blk_Size) / Search_Step # 确定最多可以找到多少相似blk
blk_num = int(blk_num)
(present_x, present_y) = Window_location
similar_blocks = numpy.zeros((blk_num ** 2, Blk_Size, Blk_Size), dtype=float)
m_Blkpositions = numpy.zeros((blk_num ** 2, 2), dtype=int)
Distances = numpy.zeros(blk_num ** 2, dtype=float) # 记录各个blk与它的相似度
# 开始在_Search_Window中搜索,初始版本先采用遍历搜索策略,这里返回最相似的几块
matched_cnt = 0
for i in range(blk_num):
for j in range(blk_num):
tem_img = _noisyImg[present_x: present_x + Blk_Size, present_y: present_y + Blk_Size]
dct_Tem_img = cv2.dct(tem_img.astype(numpy.float64))
# 先对块进行dct变换再求l2-norm,寻找相似块,降低噪点的干扰
m_Distance = numpy.linalg.norm((dct_img - dct_Tem_img)) ** 2 / (Blk_Size ** 2)
# 下面记录数据自动不考虑自身(因为已经记录)
if m_Distance < Threshold and m_Distance > 0: # 说明找到了一块符合要求的
similar_blocks[matched_cnt, :, :] = dct_Tem_img
m_Blkpositions[matched_cnt, :] = (present_x, present_y)
Distances[matched_cnt] = m_Distance
matched_cnt += 1
present_y += Search_Step
present_x += Search_Step
present_y = Window_location[1] # 搜索窗的行
# 取前matched_cnt个块
Distances = Distances[:matched_cnt]
# 对distance进行排序,找到对应顺序的序号
# numpy.argsort() 的用法:
# https://docs.scipy.org/doc/numpy/reference/generated/numpy.argsort.html
Sort = Distances.argsort()
# 统计一下找到了多少相似的blk
if matched_cnt < max_matched:
Count = matched_cnt + 1
else:
Count = max_matched
# 将前matched_cnt个块放入Final_similar_blocks,左上坐标信息保存在lk_positions
if Count > 0:
for i in range(1, Count):
Final_similar_blocks[i, :, :] = similar_blocks[Sort[i - 1], :, :]
blk_positions[i, :] = m_Blkpositions[Sort[i - 1], :]
return Final_similar_blocks, blk_positions, Count
def Step1_3DFiltering(_similar_blocks):
'''
*3D变换及滤波处理
*_similar_blocks:相似的一组block,这里已经是频域的表示
*要将_similar_blocks第三维依次取出,然在频域用阈值滤波之后,再作反变换
'''
statis_nonzero = 0 # 非零元素个数
m_Shape = _similar_blocks.shape
# 下面这一段代码很耗时
for i in range(m_Shape[1]):
for j in range(m_Shape[2]):
# print _similar_blocks[:, i, j], type(_similar_blocks[:, i, j])
tem_Vct_Trans = cv2.dct(_similar_blocks[:, i, j])
# 硬阈值变换,去掉较小的频率成分
tem_Vct_Trans[numpy.abs(tem_Vct_Trans[:]) < Threshold_Hard3D] = 0.
statis_nonzero += tem_Vct_Trans.nonzero()[0].size
_similar_blocks[:, i, j] = cv2.idct(tem_Vct_Trans)[0]
return _similar_blocks, statis_nonzero
def Aggregation_hardthreshold(_similar_blocks, blk_positions, m_basic_img, m_wight_img, _nonzero_num, Count, Kaiser):
'''
*对3D变换及滤波后输出的stack进行加权累加,得到初步滤波的图片
*_similar_blocks:相似的一组block,这里是频域的表示
*对这些块,用非零项的权重乘以凯撒窗之后再分别放回原位
'''
_shape = _similar_blocks.shape
if _nonzero_num < 1:
_nonzero_num = 1
block_wight = (1. / (sigma ** 2 * _nonzero_num)) * Kaiser
for i in range(Count):
point = blk_positions[i, :]
tem_img = block_wight * cv2.idct(_similar_blocks[i, :, :])
m_basic_img[point[0]:point[0] + _shape[1], point[1]:point[1] + _shape[2]] += tem_img
m_wight_img[point[0]:point[0] + _shape[1], point[1]:point[1] + _shape[2]] += block_wight
def BM3D_1st_step(_noisyImg):
"""第一步,基本去噪"""
# 初始化一些参数:
(width, height) = _noisyImg.shape # width = row, height = col
block_Size = Step1_Blk_Size # 块大小
blk_step = Step1_Blk_Step # N块步长滑动
# 根据步长确定搜索的次数
Width_num = (width - block_Size) / blk_step
Height_num = (height - block_Size) / blk_step
# 初始化几个数组
# 空图像、空权重表、凯撒窗
Basic_img, m_Wight, m_Kaiser = init(_noisyImg, Step1_Blk_Size, Beta_Kaiser)
# 开始逐block的处理,+2是为了避免边缘上不够
for i in range(int(Width_num + 2)):
for j in range(int(Height_num + 2)):
# m_blockPoint当前参考图像的左上角顶点
m_blockPoint = Locate_blk(i, j, blk_step, block_Size, width, height) # 该函数用于保证当前的blk不超出图像范围
Similar_Blks, Positions, Count = Step1_fast_match(_noisyImg, m_blockPoint) # 相似块集合、相似块位置、相似块数量
Similar_Blks, statis_nonzero = Step1_3DFiltering(Similar_Blks) # 协同过滤后的相似块集合、非零项数量
Aggregation_hardthreshold(Similar_Blks, Positions, Basic_img, m_Wight, statis_nonzero, Count, m_Kaiser)
Basic_img[:, :] /= m_Wight[:, :]
basic = numpy.matrix(Basic_img, dtype=int)
basic.astype(numpy.uint8)
return basic
def Step2_fast_match(_Basic_img, _noisyImg, _BlockPoint):
'''
*快速匹配算法,返回邻域内寻找和当前_block相似度最高的几个block,要同时返回basicImg和IMG
*_Basic_img: 基础去噪之后的图像
*_noisyImg:噪声图像
*_BlockPoint:当前block的坐标及大小
'''
(present_x, present_y) = _BlockPoint # 当前坐标
Blk_Size = Step2_Blk_Size
Threshold = Second_Match_threshold
Search_Step = Step2_Search_Step
max_matched = Step2_max_matched_cnt
Window_size = Step2_Search_Window
blk_positions = numpy.zeros((max_matched, 2), dtype=int) # 用于记录相似blk的位置
Final_similar_blocks = numpy.zeros((max_matched, Blk_Size, Blk_Size), dtype=float)
Final_noisy_blocks = numpy.zeros((max_matched, Blk_Size, Blk_Size), dtype=float)
img = _Basic_img[present_x: present_x + Blk_Size, present_y: present_y + Blk_Size]
dct_img = cv2.dct(img.astype(numpy.float32)) # 对目标作block作二维余弦变换
Final_similar_blocks[0, :, :] = dct_img
n_img = _noisyImg[present_x: present_x + Blk_Size, present_y: present_y + Blk_Size]
dct_n_img = cv2.dct(n_img.astype(numpy.float32)) # 对目标作block作二维余弦变换
Final_noisy_blocks[0, :, :] = dct_n_img
blk_positions[0, :] = _BlockPoint
Window_location = Define_SearchWindow(_noisyImg, _BlockPoint, Window_size, Blk_Size)
blk_num = (Window_size - Blk_Size) / Search_Step # 确定最多可以找到多少相似blk
blk_num = int(blk_num)
(present_x, present_y) = Window_location
similar_blocks = numpy.zeros((blk_num ** 2, Blk_Size, Blk_Size), dtype=float)
m_Blkpositions = numpy.zeros((blk_num ** 2, 2), dtype=int)
Distances = numpy.zeros(blk_num ** 2, dtype=float) # 记录各个blk与它的相似度
# 开始在_Search_Window中搜索,初始版本先采用遍历搜索策略,这里返回最相似的几块
matched_cnt = 0
for i in range(blk_num):
for j in range(blk_num):
tem_img = _Basic_img[present_x: present_x + Blk_Size, present_y: present_y + Blk_Size]
# dct_Tem_img = cv2.dct(tem_img.astype(numpy.float32))
# m_Distance = numpy.linalg.norm((dct_img - dct_Tem_img)) ** 2 / (Blk_Size ** 2)
m_Distance = numpy.linalg.norm((img - tem_img)) ** 2 / (Blk_Size ** 2)
# 下面记录数据自动不考虑自身(因为已经记录)
if m_Distance < Threshold and m_Distance > 0:
dct_Tem_img = cv2.dct(tem_img.astype(numpy.float32))
similar_blocks[matched_cnt, :, :] = dct_Tem_img
m_Blkpositions[matched_cnt, :] = (present_x, present_y)
Distances[matched_cnt] = m_Distance
matched_cnt += 1
present_y += Search_Step
present_x += Search_Step
present_y = Window_location[1]
Distances = Distances[:matched_cnt]
Sort = Distances.argsort()
# 统计一下找到了多少相似的blk
if matched_cnt < max_matched:
Count = matched_cnt + 1
else:
Count = max_matched
# nosiy图像的3D Stack,利用第一步的Basic估计结果来构造
if Count > 0:
for i in range(1, Count):
Final_similar_blocks[i, :, :] = similar_blocks[Sort[i - 1], :, :]
blk_positions[i, :] = m_Blkpositions[Sort[i - 1], :]
(present_x, present_y) = m_Blkpositions[Sort[i - 1], :]
n_img = _noisyImg[present_x: present_x + Blk_Size, present_y: present_y + Blk_Size]
Final_noisy_blocks[i, :, :] = cv2.dct(n_img.astype(numpy.float64))
return Final_similar_blocks, Final_noisy_blocks, blk_positions, Count
def Step2_3DFiltering(_Similar_Bscs, _Similar_Imgs):
'''
*3D维纳变换的协同滤波
*_similar_blocks:相似的一组block,这里是频域的表示
*要将_similar_blocks第三维依次取出,然后作dct,在频域进行维纳滤波之后,再作反变换
*返回的Wiener_wight用于后面Aggregation
'''
m_Shape = _Similar_Bscs.shape
Wiener_wight = numpy.zeros((m_Shape[1], m_Shape[2]), dtype=float)
for i in range(m_Shape[1]):
for j in range(m_Shape[2]):
tem_vector = _Similar_Bscs[:, i, j]
tem_Vct_Trans = numpy.matrix(cv2.dct(tem_vector))
Norm_2 = numpy.float64(tem_Vct_Trans.T * tem_Vct_Trans)
m_weight = Norm_2 / (Norm_2 + sigma ** 2)
Wiener_wight[i, j] = m_weight
#if m_weight != 0: Wiener_wight[i, j] = 1. / (m_weight ** 2 * sigma ** 2)
# else:
# Wiener_wight[i, j] = 10000
# RES=IDCT(WEIGHT(DCT(NOISE_BLOCK)))
tem_vector = _Similar_Imgs[:, i, j]
tem_Vct_Trans = m_weight * cv2.dct(tem_vector)
_Similar_Bscs[:, i, j] = cv2.idct(tem_Vct_Trans)[0]
return _Similar_Bscs, Wiener_wight
def Aggregation_Wiener(_Similar_Blks, _Wiener_wight, blk_positions, m_basic_img, m_wight_img, Count, Kaiser):
'''
*对3D变换及滤波后输出的stack进行加权累加,得到初步滤波的图片
*_similar_blocks:相似的一组block,这里是频域的表示
*对于最后的块,乘以凯撒窗之后再输出
'''
_shape = _Similar_Blks.shape
block_wight = _Wiener_wight * Kaiser
for i in range(Count):
point = blk_positions[i, :]
tem_img = _Wiener_wight * cv2.idct(_Similar_Blks[i, :, :]) * Kaiser
m_basic_img[point[0]:point[0] + _shape[1], point[1]:point[1] + _shape[2]] += tem_img
m_wight_img[point[0]:point[0] + _shape[1], point[1]:point[1] + _shape[2]] += block_wight
def BM3D_2nd_step(_basicImg, _noisyImg):
'''Step 2. 最终的估计: 利用基本的估计,进行改进了的分组以及协同维纳滤波'''
# 初始化一些参数:
(width, height) = _noisyImg.shape
block_Size = Step2_Blk_Size
blk_step = Step2_Blk_Step
Width_num = (width - block_Size) / blk_step
Height_num = (height - block_Size) / blk_step
# 初始化几个数组
m_img, m_Wight, m_Kaiser = init(_noisyImg, block_Size, Beta_Kaiser)
for i in range(int(Width_num + 2)):
for j in range(int(Height_num + 2)):
m_blockPoint = Locate_blk(i, j, blk_step, block_Size, width, height)
Similar_Blks, Similar_Imgs, Positions, Count = Step2_fast_match(_basicImg, _noisyImg, m_blockPoint)
Similar_Blks, Wiener_wight = Step2_3DFiltering(Similar_Blks, Similar_Imgs)
Aggregation_Wiener(Similar_Blks, Wiener_wight, Positions, m_img, m_Wight, Count, m_Kaiser)
m_img[:, :] /= m_Wight[:, :]
Final = numpy.matrix(m_img, dtype=int)
Final.astype(numpy.uint8)
return Final
def Gauss_noise(img, sigma=25):
noise = numpy.matlib.randn(img.shape) * sigma
res = img + noise
return res
def PSNR(img1, img2):
D = numpy.array(img1 - img2, dtype=numpy.int64)
D[:, :] = D[:, :] ** 2
RMSE = D.sum() / img1.size
psnr = 10 * math.log10(float(255. ** 2) / RMSE)
return psnr
if __name__ == '__main__':
cv2.setUseOptimized(True) # OpenCV 中的很多函数都被优化过(使用 SSE2,AVX 等)。也包含一些没有被优化的代码。使用函数 cv2.setUseOptimized() 来开启优化。
img_name = "./len128*128.jpg" # 图像的路径
ori = cv2.imread(img_name, cv2.IMREAD_GRAYSCALE) # 读入图像,cv2.IMREAD_GRAYSCALE:以灰度模式读入图像
cv2.imwrite("ori.jpg", ori)
img = Gauss_noise(ori)
cv2.imwrite("noise.jpg", img)
print 'The PSNR After add noise %f' % PSNR(ori, img)
# 记录程序运行时间
e1 = cv2.getTickCount() # cv2.getTickCount 函数返回从参考点到这个函数被执行的时钟数
# if(img is not None):
# print("success")
Basic_img = BM3D_1st_step(img)
e2 = cv2.getTickCount()
time = (e2 - e1) / cv2.getTickFrequency() # 计算函数执行时间
print ("The Processing time of the First step is %f s" % time)
cv2.imwrite("Basic3.jpg", Basic_img)
print ("The PSNR between the two img of the First step is %f" % PSNR(ori, Basic_img))
# Basic_img = cv2.imread("Basic3.jpg", cv2.IMREAD_GRAYSCALE)
Final_img = BM3D_2nd_step(Basic_img, img)
e3 = cv2.getTickCount()
time = (e3 - e2) / cv2.getTickFrequency()
print ("The Processing time of the Second step is %f s" % time)
cv2.imwrite("Final3.jpg", Final_img)
print ("The PSNR between the two img of the Second step is %f" % PSNR(ori, Final_img))
time = (e3 - e1) / cv2.getTickFrequency()
print ("The total Processing time is %f s" % time)
补充C++代码:https://github.com/gfacciol/bm3d
7. 最后
