如何将单线程爬虫改成多线程
链家多线程爬虫
大家好,我是W
项目介绍:本项目将改写之前的链家单线程爬虫框架(如何爬取一万条数据),实现多线程爬虫,实现爬虫性能提升。数据采集的目标不变,存储的格式不变。
前置知识:
Python3多线程基础
python多线程结合Queue使用
如何爬取一万条数据
项目流程:项目分析、原项目分析、模块设计、代码实现、数据采集展示
项目时间:2020年2月21日
项目分析
这次要改之前的单线程框架,最主要的差别就是将单线程改为多线程,而根据这个项目数据采集的流程,依次是:
- 列表页拼接
- 列表页下载
- 列表页解析
- 详情页下载
- 详情页解析
- 数据存储
所以中间需要一系列的队列去接收这些数据,大致的流程图是:

而在这些流程中我们需要添加多线程的元素,而且利用队列让这些线程去重复做固定的工作(从队列中取对象,处理对象,存储到下一个队列)。
原项目分析
# 2.抓取二手房详情页连接,放入URL队列中等待请求
for area, pg_num in areas.items():
# 2.1 遍历列表长度,得到详情页URL队列
for num in range(1, pg_num + 1):
# 2.1.1 拼接列表页地址
page_url = "https://cd.lianjia.com/ershoufang/{}/{}/".format(area, 'pg' + str(num))
self.log.logger.info('[拼接列表页{}成功]'.format(page_url))
print('[拼接列表页{}成功]'.format(page_url))
# 2.1.2 启动下载器下载列表页
...
html_str = self.downloader.download(page_url)
上次的爬虫效率太低了,他的流程就是讲详情页拼出来,然后下载下来放入一个集合里面,当所有的详情页都下载完毕才开始下一步,这样的话爬虫的启动时间会相当长(可能有20分钟),而且前面的详情页没有下载完毕后面解析工作是无法进行的,所以效率很低。
所以在新的多线程项目中,我们可以一次性把列表页的URL全部拼接出来。交给一个(多个)线程A去负责下载列表页HTML,然后交给另一个线程B去解析列表页里的详情页的URL,下一个线程C去解析详情页的item,最后给负责保存数据的线程D去保存item。
模块设计
- 日志模块
- 持久化模块
- 页面下载模块
- 页面解析模块
- 爬虫逻辑模块
上次的爬虫模块设计基本上没什么大问题,主要修改的就是爬虫的主体逻辑模块就可以了。
代码实现
日志模块
这个模块不需要我们做任何修改,直接调用就可以了。
import logging
import datetime
class MyLog():
"""
日志输出用于调试
"""
def __init__(self, name, filepath):
"""初始化属性"""
# 初始化日志
self.logger = logging.getLogger(name)
self.logger.setLevel(logging.DEBUG)
# 每日生成一个新文件
filepath = (filepath + "/" + str(datetime.date.today()) + "log.txt")
self.fh = logging.FileHandler(filepath)
self.fh.setLevel(logging.DEBUG)
# 初始化格式器
self.formatter = logging.Formatter(
"%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
self.fh.setFormatter(self.formatter)
self.logger.addHandler(self.fh)
def getMyLogger(self):
return self.logger
持久化模块
也不许要修改。
import csv
from spider import cd_log
class DataSaver():
"""持久化模块"""
def __init__(self):
self.log = cd_log.MyLog('DataSaver', 'logs')
self.filename = "../doc/origin_data/cd_lianjia-qingyangqu4.csv"
with open(self.filename, 'w', encoding='utf-8', newline='') as f:
data = [
"id", "小区名称", "所在区域", "总价", "单价",
"房屋户型", "所在楼层", "建筑面积", "户型结构",
"套内面积", "建筑类型", "房屋朝向", "建筑结构",
"装修情况", "梯户比例", "配备电梯", "产权年限",
"挂牌时间", "交易权属", "上次交易", "房屋用途",
"房屋年限", "产权所属", "抵押信息", "房本备件",
]
writer = csv.writer(f, dialect='excel')
writer.writerow(data)
def save_item(self, detail_data):
if detail_data is None:
self.log.logger.error('[保存器 数据为空保存失败]')
print('[保存器 数据为空保存失败]')
return
with open(self.filename, 'a', encoding='utf-8', newline='') as f:
writer = csv.writer(f, dialect='excel')
writer.writerow(detail_data)
self.log.logger.info("[保存器 详情页数据保存成功]")
print("[保存器 详情页数据保存成功]")
页面下载模块
这个模块主要负责下载网页HTML,不管是详情页和列表页,都是需要下载到本地做解析的,所以直接下载他们的HTML就可以了,所以只需要写一个下载方法。
import random
import time
import requests
from spider import cd_log
class HtmlDownloader:
def __init__(self):
self.log = cd_log.MyLog('HtmlDownloader', 'logs')
self.USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser; GTB5; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser 1.98.744; .NET CLR 3.5.30729)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser; GTB5; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; SV1; Acoo Browser; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; GTB5; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; Maxthon; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; GTB5;",
"Mozilla/4.0 (compatible; Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser 1.98.744; .NET CLR 3.5.30729); Windows NT 5.1; Trident/4.0)",
"Mozilla/4.0 (compatible; Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB6; Acoo Browser; .NET CLR 1.1.4322; .NET CLR 2.0.50727); Windows NT 5.1; Trident/4.0; Maxthon; .NET CLR 2.0.50727; .NET CLR 1.1.4322; InfoPath.2)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser; GTB6; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser; GTB5; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB6; Acoo Browser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
]
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
"Accept-Encoding": "gzip, deflate, br",
'Accept-Language': 'zh-CN,zh;q=0.9',
"Cache-Control": "max-age=0",
"User-Agent": random.choice(self.USER_AGENTS),
"Referer": "https://cd.lianjia.com/ershoufang/",
}
# 设置下载延迟时间
self.delay = random.choice([1, 1.2, 1.5, 1.8])
def download_html(self, url):
"""
页面下载器
负责下载对应URL的html
:param url: URL
:return: HTML_str :response.text
"""
if url == '' or url is None:
self.log.logger.error("[列表页下载器 URL为空]")
print("[列表页下载器 URL为空]")
return None
# 下载前随机睡眠
time.sleep(self.delay)
response = requests.get(url=url, headers=self.headers)
if response.status_code != 200:
self.log.logger.error('[页面下载器 请求失败]')
print("[页面下载器 请求失败]")
return None
self.log.logger.info("[页面下载器 {} 请求成功]".format(url))
print("[页面下载器{} 请求成功]".format(url))
return response.text
页面解析模块
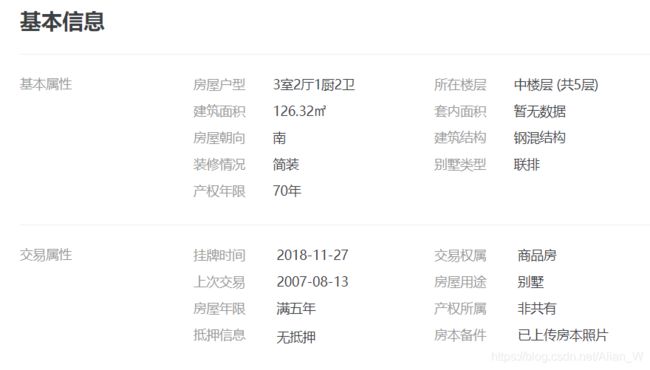
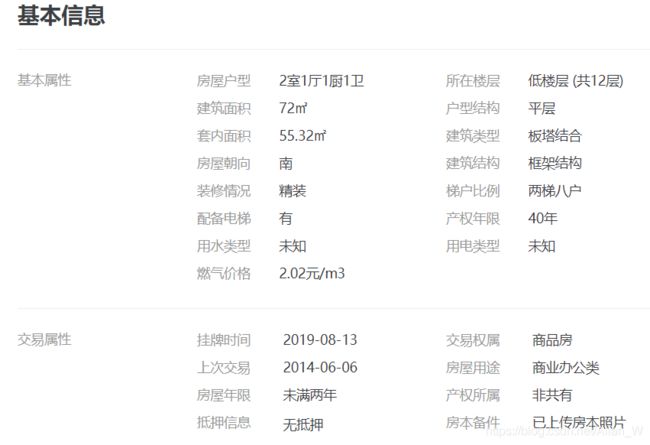
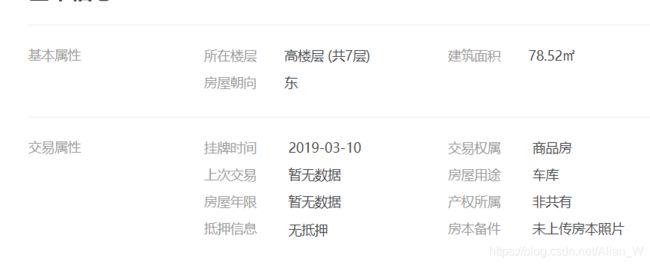
这个模块与单线程模板有点不同,主要还是解析详情页的时候我将别墅、车库和普通住宅做了区分,分别用不同的代码做解析,这样在后期做数据清洗的时候少了很多麻烦。

from lxml import etree
from spider.cd_log import MyLog
from spider.html_downloader import HtmlDownloader
class HtmlParser:
def __init__(self):
self.downloader = HtmlDownloader()
self.log = MyLog('HtmlParser', 'logs')
self.id = 1 # 因为多线程的进入id值可能会重复,需要通过pandas处理
def parse_detail_url_list(self, html_str):
"""
负责从列表页的HTML中解析出详情页的URL列表
:param html_str:
:return: detail_url_list : list
"""
if html_str is None or html_str == '':
self.log.logger.error("[列表页解析器 列表页为空]")
print("[列表页解析器 列表页为空]")
return None
tree = etree.HTML(html_str)
detail_url_set = set(tree.xpath("//ul[@class='sellListContent']/li/a/@href"))
if detail_url_set is None:
self.log.logger.error('[列表页解析器 详情页URL集合为空]')
return None
self.log.logger.info('[列表页解析器 详情页URL列表解析成功]')
return list(detail_url_set)
def parse_detail_item(self, detail_url):
"""
负责调用详情页下载器下载详情页HTML,并将HTML解析出item
:param detail_url:详情页的URL
:return:item
"""
if detail_url == '' or detail_url == None:
self.log.logger.error('[详情页解析器 详情页URL为空 无法解析]')
print('[详情页解析器 详情页URL为空 无法解析]')
return
html_str = self.downloader.download_html(detail_url)
tree = etree.HTML(html_str)
transaction_list = tree.xpath("//div[@class='transaction']//ul/li/span/text()")
item = ['null' for i in range(25)]
item[0] = 1 # id列固定1 后期用pandas重新排
communityName = tree.xpath("//div[@class='communityName']/a/text()")[0]
areaName = tree.xpath("//div[@class='areaName']/span/a/text()")[0]
price = tree.xpath("//span[@class='total']/text()")[0]
unitPrice = tree.xpath("//div[@class='unitPrice']/span/text()")[0]
item[1] = communityName
item[2] = areaName
item[3] = price
item[4] = unitPrice
content = tree.xpath("//div[@class='base']/div[@class='content']//li/text()")
if transaction_list[7] == '车库':
# 按照车库类型解析
self.parse_car(content, item)
elif transaction_list[7] == '别墅':
# 按照别墅类型解析
self.parse_big_house(content, item)
else:
# 按照其他类型解析
self.parse_nomal(content, item)
item[17] = transaction_list[1].strip() # 挂牌时间
item[18] = transaction_list[3].strip() # 交易权属
item[19] = transaction_list[5].strip() # 上次交易
item[20] = transaction_list[7].strip() # 房屋用途
item[21] = transaction_list[9].strip() # 房屋年限
item[22] = transaction_list[11].strip() # 产权所属
item[23] = transaction_list[13].strip() # 抵押信息
item[24] = transaction_list[15].strip() # 房本备件
return item
def parse_car(self, content, item):
"""
车库的基本属性只有三个 分别解析出来对应位置放入
:param tree:
:param item:item列表
:return:None
"""
item[6] = content[0] # 所在楼层
item[7] = content[1] # 建筑面积
item[11] = content[2] # 房屋朝向
def parse_big_house(self, content, item):
"""
别墅有9个基本属性 但是位置不对 需要手工对应
:param content:
:param item:
:return:
"""
item[5] = content[0] # 房屋户型
item[6] = content[1] # 所在楼层
item[7] = content[2] # 建筑面积
item[9] = content[3] # 套内面积
item[11] = content[4] # 房屋朝向
item[12] = content[5] # 建筑结构
item[13] = content[6] # 装修情况
item[10] = content[7] # 建筑类型
item[16] = content[8] # 产权年限
def parse_nomal(self, content, item):
"""
普通住在和商业办公类位置都一样 只是商业办公类多了几个 且并不需要
:param content:
:param item:
:return:
"""
item[5] = content[0] # 房屋户型
item[6] = content[1] # 所在楼层
item[7] = content[2] # 建筑面积
item[8] = content[3] # 户型结构
item[9] = content[4] # 套内面积
item[10] = content[5] # 建筑类型
item[11] = content[6] # 房屋朝向
item[12] = content[7] # 建筑结构
item[13] = content[8] # 装修情况
item[14] = content[9] # 梯户比例
item[15] = content[10] # 配备电梯
item[16] = content[11] # 产权年限
爬虫逻辑模块
前面的模块已经准备完毕,接下来就可以开始写爬虫的主要逻辑。
init函数
def __init__(self):
self.item_queue = Queue() # item队列
self.list_page_url_queue = Queue() # 列表页URL队列
self.list_page_html_queue = Queue() # 列表页HTML队列
self.detail_page_url_queue = Queue() # 详情页URL队列
self.log = MyLog('lianjia_spider', 'logs')
self.saver = DataSaver()
self.html_downloader = HtmlDownloader()
self.parser = HtmlParser()
首先需要将各种队列都定义好,并且将需要的模块全都导入进来。可能有人发现为什么没有详情页HTML队列,因为我写这个项目的时候已经很晚了,所以为了省时间我把下载详情页、解析详情页都放到一起写了,大家要改的话很轻松也能改回来的。
拼接列表页的函数
def prepare_list_page(self, areas):
"""
通过URL拼接将列表页的URL拼接出来,并将其装在list_page_queue里
:param areas:所要拼接的区的字典
:return:None
"""
for area, page_num in areas.items():
for page in range(1, page_num + 1):
url = "https://cd.lianjia.com/ershoufang/{}/{}/".format(area, 'pg' + str(page))
print("拼装URL {} 成功 列表页队列size={}".format(url, self.list_page_url_queue.qsize()))
self.list_page_url_queue.put(url)
这个函数负责将字典areas里的参数拼接进队列里,一次遍历就做好了所以不需要开线程来做。
列表页下载函数
这个函数负责下载列表页的HTML代码,并且由于有子线程专门负责这件事,所以我们需要将其写成死循环,这样线程进入这个函数之后才会不断从队列中取出URL进行下载。
同时必须要注意的是,多个线程来执行这个函数,可能会出现资源抢占的问题和队列判断不准确的问题,所以我们需要在使用队列这个资源之前上锁,相当于在高速路上设置一个窄桥,让线程(汽车)只能一个一个的使用(通过)列表(窄桥)。这样不管到底会不会出事,也保证了数据的安全。
大家可以看到在列表页URL队列中获取URL的操作里设置了timeout=60 * 20,其实这一步并没有必要,因为URL是一次性拼接完成全部装进队列里了,所以当线程发现队列为空,那就是下载完毕了,并不需要犹豫要不要退出的问题,但是由于我当时没有发现这个问题,所以也懒得改了,大家可以理解就好。
def multi_thread_parse_list_page(self):
"""
开启线程执行本函数
这个函数负责调用下载函数去下载出列表页的html
:return:None
"""
print('[列表页下载器]', self.list_page_url_queue.empty())
# 当列表页URL队列不为空时 可以下载网页
while True:
print("[列表页url队列大小:{}]".format(self.list_page_url_queue.qsize()))
print('[下载列表页HTML线程]', threading.currentThread().name)
lock = threading.Lock() # 加锁
lock.acquire() # 获取锁 使得多个线程访问queue变为单线程操作
# 20 分钟还是没有数据则线程销毁
try:
list_page_url = self.list_page_url_queue.get(timeout=60 * 20)
except Exception as e:
self.log.logger.error('[列表页URL队列等待超过20分钟 ,估计没有需要下载的列表页了 准备正常退出]')
print('[列表页URL队列等待超过20分钟 ,估计没有需要下载的列表页了 准备正常退出]')
return
lock.release() # 解锁 每个线程获取自己的url后去解析URL
print("[爬虫 取出列表页URL {}]".format(list_page_url))
html_str = self.html_downloader.download_html(list_page_url)
lock.acquire()
self.list_page_html_queue.put(html_str)
lock.release()
self.log.logger.info("[爬虫 列表页 {} HTML放入列表页HTML队列]".format(list_page_url))
print("[爬虫 列表页 {} HTML放入列表页HTML队列]".format(list_page_url))
解析出详情页的URL的函数
ef multi_thread_parse_detail_url(self):
"""
开启多线程执行本函数
这个函数负责调用解析函数去解析出列表页中的详情页URL,并将其放入详情页URL队列
:return:None
"""
print('[详情页解析器]', self.list_page_html_queue.empty())
while True:
lock = threading.Lock() # 定义锁
lock.acquire() # 拿锁=加锁
try:
html_str = self.list_page_html_queue.get(timeout=60 * 20)
except Exception as e:
self.log.logger.error("[列表页HTML队列等待超过20分钟 估计没有HTML代码需要解析了 准备正常退出]")
print('[列表页HTML队列等待超过20分钟 估计没有HTML代码需要解析了 准备正常退出]')
return
lock.release() # 解锁
detail_url_list = self.parser.parse_detail_url_list(html_str)
if detail_url_list is None or len(detail_url_list) == 0:
self.log.logger.error("[爬虫 详情页URL列表为空]")
print("[爬虫 详情页URL列表为空]")
return
lock.acquire()
self.add_to_detail_page_url_queue(detail_url_list)
lock.release()
print('[详情页URL队列大小为:{}]'.format(self.detail_page_url_queue.qsize()))
多线程去下载并解析详情页中的item的函数
这个函数直接调用了下载器去下载详情页,然后又调用了解析器去解析详情页的HTML代码,最终将item装好送出来放入队列里。
def multi_thread_parse_detail_html(self):
"""
开启多线程执行本函数
这个函数负责从详情页URL队列里取出URL,并调用详情页解析器来解析出item,然后将item放入item队列
:return:None
"""
print('[详情页解析器]', self.detail_page_url_queue.empty())
while True:
# time.sleep(1)
lock = threading.Lock() # 开锁
lock.acquire()
try:
print('[进入获取详情页URL的队列]')
detail_url = self.detail_page_url_queue.get(timeout=60 * 20)
except Exception as e:
self.log.logger.error('[详情页URL队列等待超过20分钟 估计没有URL了 准备正常退出]')
print('[详情页URL队列等待超过20分钟 估计没有URL了 准备正常退出]')
return
lock.release() # 解锁
item = self.parser.parse_detail_item(detail_url)
lock.acquire()
self.item_queue.put(item)
lock.release()
保存item的函数
def multi_thread_save(self):
"""
开启多线程执行本函数
这个函数负责从item队列中取出item,并调用保存器保存item
:return:None
"""
print('[保存器]', self.item_queue.empty())
while True:
lock = threading.Lock() # 拿锁
lock.acquire()
print('[item队列大小:{}]'.format(self.item_queue.qsize()))
try:
item = self.item_queue.get(timeout=60 * 20)
except Exception as e:
self.log.logger.error('[保存器已经等待超过20分钟 估计已经没有item需要保存 准备正常退出]')
print('[保存器已经等待超过20分钟 估计已经没有item需要保存 准备正常退出]')
return
print(item)
self.saver.save_item(item)
lock.release() # 开锁
一个小函数
def add_to_detail_page_url_queue(self, detail_url_list):
for url in detail_url_list:
self.detail_page_url_queue.put(url)
函数的逻辑部分
在爬虫主体逻辑的run函数里,首先需要定义一下爬虫的范围,也就是areas字典。
接下来就需要分批的开启线程去调用这些函数。
def run(self):
areas = {
'babaojie': 17, 'beisen': 19, 'caoshijie': 17, 'caotang': 10, 'funanxinqu': 29, 'guanghuapaoxiao': 16,
'huanhuaxi': 5, 'huapaifang': 22,
'jiaolonggang': 60, 'jinsha': 31, 'jinfu': 11, 'kuanzhaixiangzi': 5, 'renmingongyuan': 12, 'taishenglu': 14,
'waiguanghua': 52,
'waijinsha': 26, 'wanjiawan': 18, 'xinancaida': 17, 'youpindao': 9,
}
# 将列表页地址拼接出来放进队列里
self.prepare_list_page(areas)
# 开启线程下载列表页
for i in range(1, 5):
t = threading.Thread(target=self.multi_thread_parse_list_page, name='parse_list_page_{}'.format(i))
t.start()
print('[开启线程下载列表页 准备睡眠 让列表页队列有余量]')
# time.sleep(60 * 5)
# 开启线程解析列表页中详情页的URL
for i in range(1, 5):
t = threading.Thread(target=self.multi_thread_parse_detail_url, name='parse_detail_url_{}'.format(i))
print('[开启解析详情页URL的线程]')
t.start()
print('[开启线程解析出详情页URL 准备睡眠 让详情页队列有余量]')
# time.sleep(60 * 5)
# 开启线程从详情页中解析出item
for i in range(1, 6):
t = threading.Thread(target=self.multi_thread_parse_detail_html, name='parse_detail_html_{}'.format(i))
t.start()
print('[开启线程下载并解析出item 准备睡眠 让item队列有余量]')
# time.sleep(60 * 9)
# 开启线程保存item
for i in range(1, 3):
t = threading.Thread(target=self.multi_thread_save, name='save_item_{}'.format(i))
t.start()
另外,这里的线程是不设置为守护线程的,因为若设置为守护线程,run方法就是父线程,run一执行完他的子线程全都自动结束了,所以不能设置为守护线程。
那么子线程的退出接口都在哪呢?这些线程在从队列中获取对象的时候都需要设置timeout=60 * 20,并且进行了异常处理,这样一旦线程发现没有对象可以获取并且等了20分钟还是不行,就会自动结束线程。
采集数据展示

GitHub地址
链家多线程源码
总结
总的来说这个多线程工程改造的地方并不多,只是需要把我们的思路理得更清楚一点,让每个模块每个功能都分的更加仔细,就能够造出多线程的爬虫。