Python爬虫学习笔记-第十九课(Scrapy进阶上)
Scrapy进阶上
- 1. pipline补充
- 2. items.py文件
- 3. 案例演示
-
- 3.1 思路分析
- 3.2 完整代码
- 3.3 案例总结:
1. pipline补充
settings.py 默认生成一个管道,但用户可以自定义多个管道。
为什么需要多个pipeline:
- 可能会有多个spider,不同的pipeline处理不同的item的内容;
- ⼀个spider的内容可以要做不同的操作,比如存入不同的数据库中。
注意:
- 管道后的数字(权重)越小,优先级越高,设置该权重应在合理范围内;
- pipeline中process_item、open_spider和close_spider方法名不能修改。
在settings.py文件中添加自定义管道,将权重设为400,从逻辑上,先执行自带的管道,再执行自定义管道逻辑。
ITEM_PIPELINES = {
'firstscrapy.pipelines.FirstscrapyPipeline': 300,
# 自定义管道
'firstscrapy.pipelines.SelfDefinedPipeline': 400,
}
做个简单验证,爬虫程序仍采用笔者之前写的豆瓣案例:
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com'] # 域名可以后期修改
start_urls = ['http://douban.com/'] # url可以后期修改
def parse(self, response):
item = {
}
text_list = response.xpath('//div[@class="side-links nav-anon"]/ul/li')
for text in text_list:
item['title'] = text.xpath('a/em/text()').extract_first()
if item['title'] == None:
item['title'] = text.xpath('a/text()').extract_first()
yield item
管道代码:
class FirstscrapyPipeline:
def process_item(self, item, spider):
item['weapon'] = 'sword' # 随便添加一个值
return item
class SelfDefinedPipeline:
def process_item(self, item, spider):
print(item)
return item
运行结果:

从打印的结果看,item里面有{'weapon':'sword'},证明之前的提及的管道执行顺序是正确的。
可以在管道中获取爬虫的名字:
- process_item()方法中传递的形参spider是一个对象,可以访问对象的name属性获取爬虫程序的名字;
- 可以在item中添加数据,例如
item['come_from']=spider_name。
示例代码:
# 爬虫程序
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com'] # 域名可以后期修改
start_urls = ['http://douban.com/'] # url可以后期修改
def parse(self, response):
item = {
}
item['come_from'] = 'db'
yield item
# 管道部分
class FirstscrapyPipeline:
def process_item(self, item, spider):
# item['weapon'] = 'sword' # 随便添加一个值
print(type(spider))
print('use spider.name: ', spider.name)
print('use item data: ', item['come_from'])
return item
运行结果:

2. items.py文件
item.py文件中可以定义想要爬取的数据结构(封装数据)。
引用items文件的方法:
# items代码
import scrapy
class FirstscrapyItem(scrapy.Item):
# 给item对象添加一个名字为title的key
title = scrapy.Field()
# 爬虫代码
import scrapy
# from firstscrapy.items import FirstscrapyItem # 从项目根目录导入
from day18.firstscrapy.firstscrapy.items import FirstscrapyItem # 从最外层目录导入
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
def parse(self, response):
# 创建自定义item对象
item = FirstscrapyItem()
print(type(item))
item['title'] = 'douban'
item['name'] = 'movie'
yield item
运行结果:
为了方便查看结果,笔者在settings.py文件中加入了LOG_LEVEL = 'WARNING',避免不必要的信息打印。


注意:xxx=scrapy.Field(),Field继承自字典,但xxx不是字典对象。上述代码中尝试给item添加键值对'name':'movie',但是会报没有相应key的错。
3. 案例演示
代码需求:爬取古诗文网站上的诗歌名字、作者、朝代以及诗歌具体内容,并爬取不同页数的数据。
网站链接:https://www.gushiwen.cn/
3.1 思路分析
第一步,创建scrapy工程。
> scrapy startproject gsw
> cd gsw
> scrapy genspider gushu gushiwen.org
第二步,修改settings.py文件,做一些基本配置。
BOT_NAME = 'gsw'
SPIDER_MODULES = ['gsw.spiders']
NEWSPIDER_MODULE = 'gsw.spiders'
LOG_LEVEL = 'WARNING'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 1
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# Configure item pipelines
ITEM_PIPELINES = {
'gsw.pipelines.GswPipeline': 300,
}
第三步,页面分析
要爬取的内容及其对应的标签:
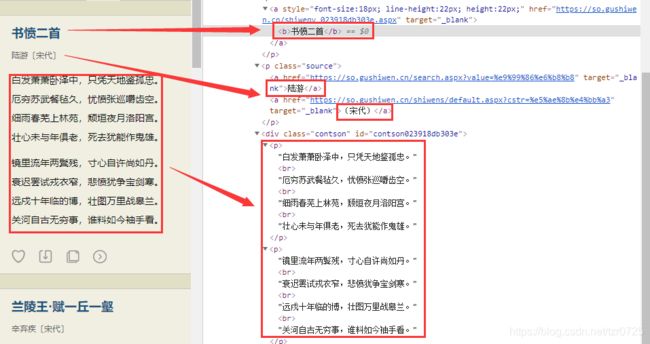
通过页面结构分析,所有的内容在class='left’标签里面,每首诗的具体内容在class='cont’里面。
观察不同页数的url:
https://www.gushiwen.org/default_1.aspx 第一页
https://www.gushiwen.cn/default_2.aspx 第二页
https://www.gushiwen.cn/default_3.aspx 第三页
gushiwen.org gushiwen.cn
第一页的域名也与其它页数的域名不同。
拓展:为何要使用yield关键字
- 生成器可以更加节省内存空间;
- 使用更加灵活,体现在:
2.1 return在运行之后程序结束,yield在返回之后可以继续执行后续操作;
2.2 通过yield scrapy.Request对象,框架可获取该对象,把其中的url链接给引擎,自动开始下一次的请求并获得响应。
此处,翻页的逻辑是:通过分析数据接口寻找下一页的url,处理完当前页的逻辑后,yield一个scrapy.Request对象,引擎收到下一页的url,会自动执行重复的逻辑。

3.2 完整代码
# 爬虫代码
import scrapy
from day19.gsw.gsw.items import GswItem
class GushuSpider(scrapy.Spider):
name = 'gushu'
# 增加一个域名
allowed_domains = ['gushiwen.org', 'gushiwen.cn']
# 修改起始的url
start_urls = ['https://www.gushiwen.org/default_1.aspx']
def parse(self, response):
poem_divs = response.xpath('//div[@class="cont"]')
for poem_div in poem_divs:
poem_title = poem_div.xpath('.//b/text()').extract_first()
source = poem_div.xpath('.//p[@class="source"]//text()').extract()
cont_list = poem_div.xpath('.//div[@class="contson"]//text()').extract()
poem_content = ''.join(cont_list).strip() # 拼接字符串,顺便去空格
# source内容非空
if source:
poem_author = source[0]
poem_dynasty = source[1][1:-1]
# 写法2 item不是一个字典类型
item = GswItem(title=poem_title, author=poem_author, dynasty=poem_dynasty, content=poem_content)
yield item
# 翻页处理
next_href = response.xpath('//a[@id="amore"]/@href').extract_first()
if next_href:
next_url = response.urljoin(next_href) # 补全url
request = scrapy.Request(next_url)
yield request
# 管道代码
import json
class GswPipeline:
def process_item(self, item, spider):
with open('poems.txt', 'a', encoding='utf-8') as fobj:
# item不是字典类型,需先将其转化为字典,才能变成json字符串
item_json = json.dumps(dict(item), ensure_ascii=False)
fobj.write(item_json + '\n')
return item
# item代码
import scrapy
class GswItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
dynasty = scrapy.Field()
content = scrapy.Field()
运行结果:

3.3 案例总结:
- 当域名不一样的时候,增加那个不同的,比如
allowed_domains = ['gushiwen.org','gushiwen.cn']
也可以给一个最大的,视情况而定。
-
如何处理列表为空的逻辑,可以做非空判断,比如在本案例当中判断source是否为空,不是空就直接保存,也可以使用
try...except语句,在try中写正常逻辑,except里面写遇到内容为空时的特殊处理。 -
在 pipline中注意item的数据类型,如果没有在items.py文件中进行设置,它就是一个字典;反之则不是字典对象,需要处理(比如转化为字典对象);
-
若要使用items.py封装数据,在爬虫文件中返回数据时可以有两种写法:
4.1 常规写法,item['title'] = poem_title;
4.2 新颖写法,item = GswItem(title=poem_title) -
翻页处理:
4.1 可以去找页数规律(常规方法);
4.2 通过接口找到下一页的url,然后 yield.scrapy.Request(url)。 -
遇到url 地址不全(常见的就是缺少请求头)的时候两种解决方式:
6.1 采用字符串拼串;
6.2 urljoin()