python数据处理中Pandas数据处理及分析----超详细
实现Pandas自行车行驶数据分析
假设现在有一组自行车行驶数据,这组数据记录的是蒙特利尔市内7条自行车道的自行车骑行人数,下面用python中的pandas对其进行分析。原始数据找我要就行QQ 2534659467 注明来意谢谢
#第一步导入Pandas
import pandas as pd
import matplotlib.pyplot as plt
#导入Pandas那些屁事我就不说了 不会的找我来
#第二步准备画图环境
#pd.set_option(‘display.mpl_style’, ‘default’)
#此处很坑爹 由于python版本的原因 此行代码导致图形崩溃 因此如果你用的是python3.0以上的就不要用此行代码进行渲染图形及表格
plt.rcParams[‘figure.figsize’] = (15,5)
#调整生成的图表最大尺寸为15*5
#第三步 使用read_csv函数读取csv文件,读取一组自行车骑行数据,得到一个DataFrame对象
broken_df = pd.read_csv(‘bikes.csv’, encoding=‘latin1’)
#使用latin1编码读入,默认的UTF-8编码不适合,注意此处的latin1是latin后面加数字1并不是L的小写
broken_df[:3]
#查看表格的前3行

#第四步 对比原始文件与read_csv函数读入的前3行,可发现读入的原始数据未发生变化,这将导致我们无法提取属性列,这是因为原始数据使用“;”作为分隔符,read_csv函数无法自动识别,需定义,且首列的日期文本为dd/mm/yyyy(不符合Pandas的时间日期格式)
broken_df.head(5)
#查看自行车数据前5行的样式

#第五步修复读入问题
#1 定义“;”作为分隔符,下面代码参数设定sep=’;‘即实现数据分隔。
#2 解析Date列的日期文本。
#3 设置日期文本格式。
#4 使用日期列作为索引。
fixed_df = pd.read_csv(‘bikes.csv’,encoding=‘latin1’,sep=’;’,parse_dates=[‘Date’],dayfirst=True,index_col=‘Date’)
fixed_df[:3]

#第六步 读取csv文件,所得结果是一个DataFrame对象,每列对应一条自行车道,每行对应一天的数据。我们从DataFrame中选择一列,使用类似字典的语法访问选择其中的一列。
fixed_df[‘Berri 1’]
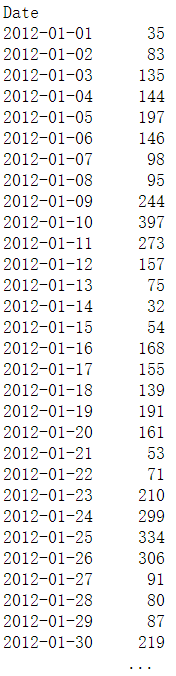

#第七步 将所选择的列绘成图2-2所示的曲线,可以直观地看出骑行人数的变化趋势。
fixed_df[‘Berri 1’].plot()
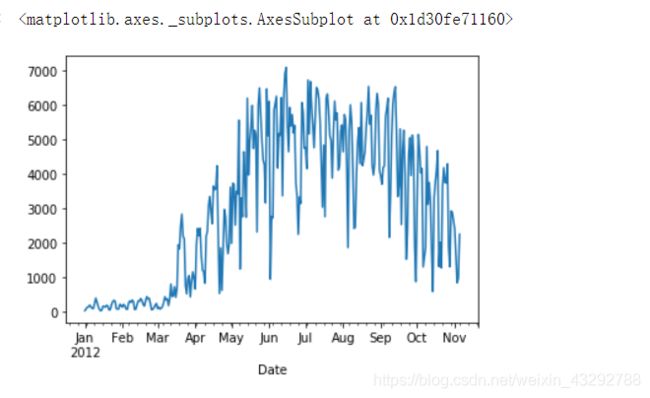
#第八步 绘制所有的列(自行车道),每条车道的变化趋势都是类似的。
fixed_df.plot(figsize=(15,10))
#第九步 假设我们希望了解在周末还是在工作日骑自行车的人更多,那就要在数据结果DataFrame中添加一个“工作日”列区分周末和工作日。
#为了简化问题。我们只考虑贝里(元数据名为Brrri 1)的自行车路径数据。贝里市蒙特利尔的一条街道,有一条非常重要的自行车道。
#人们会在去图书馆时骑自行车,有时去旧梦特利尔时也常常骑自行车。
#因此,我们将创建一个数据结构berri_bikes,其中只有贝里自行车道数据。
berri_bikes = fixed_df[[‘Berri 1’]].copy()
berri_bikes[:5]

#第十步 接下来需要添加一个“工作日”列。首先,从索引中获得工作日。索引位于上面的数据框的左边,在“日期”下。
berri_bikes.index

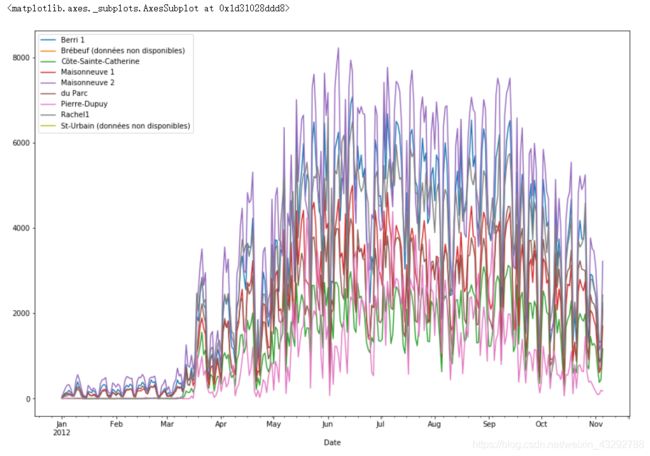
#第十一步 我们可以看到,实际的数据是不完整的,通过length数据可以发现一年只有310天,这是为什么呢?这是因为数据起始时间为2012-01-01
#结束时间为2012-11-05。Pandas时间序列功能非常强大,所以我如果我们要得到每一行的月份,可以输入以下语句。
berri_bikes.index.day
#第十二步 为普通日进行索引设置。
berri_bikes.index.weekday

#第十三步 通过上面的语句,可获得一周中的日,通过与日历进行对比会发现数据中的0代表的是星期一。
#我们现在已经知道如何设置普通日进行索引了,接下来需要把普通日的索引设置为dataframe中的一列。
berri_bikes.loc[:,‘weekday’] = berri_bikes.index.weekday
berri_bikes[:5]
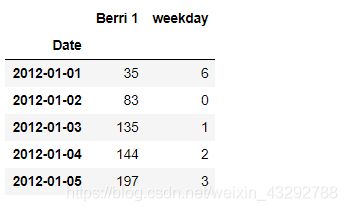
#第十四步 接下来我们就可以把普通日作为一个统计日继续骑行人数的统计了,这在pandas中实现方法非常简单。
#DataFrames中有一个groupby()方法,类似SQL语句中的groupby方法。如果读者对SQL语法不清楚,可以自行查阅。该方法实现的语句如下。
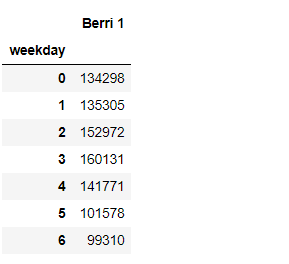
weekday_counts = berri_bikes.groupby(‘weekday’).aggregate(sum)
#这一语句的目的是把贝里的车道数据按照相同普通日的标准进行分组并累加。其中aggregate为聚合函数,应用较多,大家应掌握。
weekday_counts
#第十五步 这时候我们会发现通过0、1、2、3、4、5、6这样的数字很难记住其对应的日子,可以通过以下方法修改。
weekday_counts.index = [‘Monday’,‘Tuesday’,‘Wednesday’,‘Thurday’,‘Friday’,‘Saturday’,‘Sunday’]
weekday_counts

#第十六步 通过直方图来看统计情况:可以发现蒙特利尔似乎是一个喜欢使用自行车作为通勤工具的城市,因为人们在工作日也大量地使用自行车。
weekday_counts.plot(kind=‘bar’)

#此直方图为所有车道的骑行人数直方图