Java : Stream 数据流 (Collection 接口扩充, Stream基本操作, MapReduce 模型)
文章目录
- Collection 接口改进
-
- 范例: 使用foreach 输出
- 范例: 观察 Stream
- Stream 数据流的基本操作
-
- 范例: 数据过滤 filter()
- Stream 接口里有两个重要的操作方法:
- MapReduce 基础模型
-
- 范例: 编写一个简单的数据统计操作
- 范例: 实现订单信息的保存, 随后进行一个总量的统计
从 JDK 1.8 发起的时候实际上就是世界上大数据兴起的时候, 在大数据开发里面有一个最经典的模型: MapReduce, 实际上这属于数据的两个操作阶段:
- Map : 处理数据
- Reduce: 分析数据.
而在类集里面, 由于其本身的作用也可以进行大量数据的存储, 所以顺其自然的产生了 MapReduce 的操作, 而这些操作就通过 Stream 数据流来完成了.
Collection 接口改进
现在的 Collection 接口除了定义了一些抽象方法之外, 也提供有一些普通方法, 下面来观察这样一个方法:
- foreach 的输出支持:
public default void forEach(Consumer action) - 取得Steam 数据流的对象:
public default Streamstream()
范例: 使用foreach 输出
package com.beyond.nothing;
import java.util.ArrayList;
import java.util.List;
public class test {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("java");
all.add("python");
all.add("javaScript");
all.add("php");
all.forEach(System.out::println);
}
}
这种操作只是对数据进行显示(foreach是一个消费型接口), 如果需要更复杂的处理, 还是使用 Iterator 方便一些.
但是在 Collection 接口中提供有一个重要的Stream() 的方法, 这个方法才是整个 JDK1.8 数据操作的关键.
范例: 观察 Stream
package com.beyond.nothing;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class test {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("java");
all.add("python");
all.add("javaScript");
all.add("php");
Stream<String> stream = all.stream();
System.out.println(stream.count());
}
}
将我们的数据交给Stream之后, 就相当于这些数据一个一个进行处理, 上面的 count() 只是做了一个数据的统计, 整体的流程还是体现了遍历的的操作.
Stream 数据流的基本操作
在之前使用的count() 方法是针对于数据量做了一个统计的操作, 那么除了这些之外, 也可以进行数据的过滤, 即满足某些条件的内容才允许做数量统计.
范例: 数据过滤 filter()
package com.beyond.nothing;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class test {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("java");
all.add("python");
all.add("javaScript");
all.add("php");
Stream<String> stream = all.stream();
System.out.println(stream.filter((e)->e.contains("java")).count()); // filter 断言型函数式接口
}
}
现在我不想要这些数据的个数, 我希望得到哪些数据被进行了筛选, 这时候就可以使用一个收集器来完成.
- 收集器:
package com.beyond.nothing;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class test {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("java");
all.add("python");
all.add("javaScript");
all.add("php");
Stream<String> stream = all.stream();
System.out.println(stream.filter((e)->e.contains("java")).collect(Collectors.toList())); // filter 断言型函数式接口
}
}
收集完的数据依然属于List 集合, 所以可以直接用 List 接收
Stream 接口里有两个重要的操作方法:
- 设置的取出最大内容:
public Streamlimit(long maxSize) - 跳过的数据量:
public Streamskip(long n)
package com.beyond.nothing;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class test {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<>();
all.add("java");
all.add("python");
all.add("javaScript");
all.add("php");
all.add("jsp");
all.add("html");
all.add("sso");
all.add("nginx");
Stream<String> stream = all.stream();
List<String> list = stream.skip(2).limit(2)
.map((s)->s.toUpperCase()) // map 接的是函数式接口
.collect(Collectors.toList()); // 部分数据量操作
System.out.println(list);
}
}
如果要对数据进行分析有可能需要进行分页的操作形式, 而且使用map()函数还可以进行一些简单的数据处理操作.
MapReduce 基础模型
MapReduce 是整个 Stream的核心所在, 之前的所有的操作都是做了一个 MapReduce的衬托, 对于 MapReduce的操作由两个阶段所组成:
- map() 指的是针对于数据进行先期的操作处理, 例如: 做一些简单的数学运算
- reduce() 是进行数据的统计分析
范例: 编写一个简单的数据统计操作
定义一个订单类:
class Order{
private String title;
private double price;
private int amount;
public Order(String title, double price, int amount) {
this.title = title;
this.price = price;
this.amount = amount;
}
public String getTitle() {
return title;
}
public double getPrice() {
return price;
}
public int getAmount() {
return amount;
}
}
随后在 List 集合里面保存这些订单信息. 肯定会有多个订单信息存在.
范例: 实现订单信息的保存, 随后进行一个总量的统计
package com.beyond.nothing;
import org.omg.CORBA.ORB;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
class Order{
private String title;
private double price;
private int amount;
public Order(String title, double price, int amount) {
this.title = title;
this.price = price;
this.amount = amount;
}
public String getTitle() {
return title;
}
public double getPrice() {
return price;
}
public int getAmount() {
return amount;
}
}
public class test {
public static void main(String[] args) throws Exception {
List<Order> all = new ArrayList<>();
all.add(new Order("手机", 1999.00, 20));
all.add(new Order("笔记本电脑", 7999.00, 50));
all.add(new Order("Java 开发", 79.00, 20000));
all.add(new Order("铅笔", 1.80, 203000));
Double allPrice = all.stream().map((obj) -> obj.getPrice() * obj.getAmount()).reduce((sum, x) -> x + sum).get();
System.out.println(allPrice);
}
}
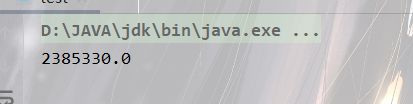
为了进一步观察更加丰富的处理操作, 可以在做一些数据的统计分析, 对于当前的操作, 如果要进行数量的统计, 其结果应该是 double 型数据. 在Stream 接口里面就提供有一个 map 结果变为 double 型的操作.
- 统计分析:
public DoubleStream mapToDouble(ToDoubleFunction mapper)
此时返回的是一个 DoubleStream 接口的对象, 这里面就可以完成我们的统计的操作, 其方法如下:
- 统计方法:
public DoubleSummaryStatistics summaryStatistics()
package com.beyond.nothing;
import org.omg.CORBA.ORB;
import java.util.ArrayList;
import java.util.DoubleSummaryStatistics;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
class Order{
private String title;
private double price;
private int amount;
public Order(String title, double price, int amount) {
this.title = title;
this.price = price;
this.amount = amount;
}
public String getTitle() {
return title;
}
public double getPrice() {
return price;
}
public int getAmount() {
return amount;
}
}
public class test {
public static void main(String[] args) throws Exception {
List<Order> all = new ArrayList<>();
all.add(new Order("手机", 1999.00, 20));
all.add(new Order("笔记本电脑", 7999.00, 50));
all.add(new Order("Java 开发", 79.00, 20000));
all.add(new Order("铅笔", 1.80, 203000));
DoubleSummaryStatistics dss = all.stream().mapToDouble((obj) -> obj.getPrice() * obj.getAmount())
.summaryStatistics();
System.out.println("总量: " + dss.getCount());
System.out.println("平均值: " + dss.getAverage());
System.out.println("最大: " + dss.getMax());
System.out.println("最小: " + dss.getMin());
System.out.println("总和: " + dss.getSum());
}
}
利用 Lambda 表达式的确可以简化不少的程序代码.