python xpath循环_用Python来爬虫?文科生也学得会!
前段时间想看下最近几年的阅读清单,萌生了用Python写爬虫程序的想法,于是就有了这篇文章。
起因
两周前,一位同学问小央,平时有没有写过技术类博客。小央大言不惭,随口就说下次可以尝试。
这不,自己挖的坑,哭也得填上。正巧,最近要统计自己的阅读记录,一个个看多费劲呀,如果能写个爬虫程序,自动化获取数据,岂不美哉。
一瓶不响半瓶晃荡,技术渣小央,刚有点小成绩的时候,就忍不住的要分享给小白们了。
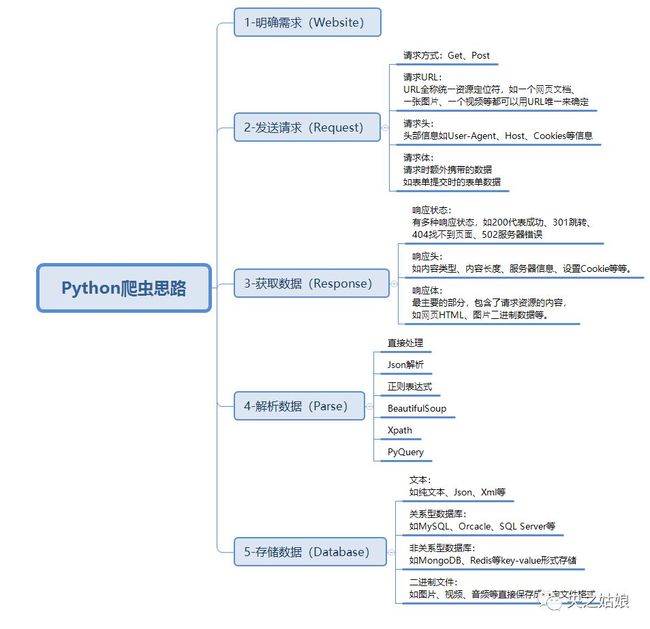
一、爬虫思路
爬虫是指请求网站并获取数据的自动化程序,又称网页蜘蛛或网络机器,最常用领域是搜索引擎,它的基本流程是明确需求-发送请求-获取数据-解析数据-存储数据。
网页之所以能够被爬取,主要是有以下三大特征:
网页都有唯一的URL(统一资源定位符,也就是网址)进行定位
网页都使用HTML(定位超文本标记语言)来描述页面信息
网页都使用HTTP/HTTPS(超文本传输协议)协议来传输HTML数据
因此,只要我们能确定需要爬取的网页 URL地址,通过 HTTP/HTTPS协议来获取对应的 HTML页面,就能提取 HTML页面里有用的数据。
在工具的选择上,任何支持网络通信的语言都可以写爬虫,比如 c++、 java、 go、 node等,而 python则是用的最多最广的,并且也诞生了很多优秀的库和框架,如 scrapy、 BeautifulSoup 、 pyquery、 Mechanize等。
BeautifulSoup是一个非常流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的便捷接口。
但是在解析速度上不如 Lxml模块,因为后者是用C语言编写,其中 Xpath可用来在 XML文档中对元素和属性进行遍历。
综上,我们本次爬取工具选择 Python,使用的包有 requests、 Lxml、 xlwt、 xlrd,分别用于模拟账户登录、爬取网页信息和操作 Excel进行数据存储等。
二、实战解析
1. 模拟账户登录
因为要爬取个人账户下的读书列表,我们首先要让 Python创建用户会话,用于在跨请求时保存Cookie值,实现从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开。
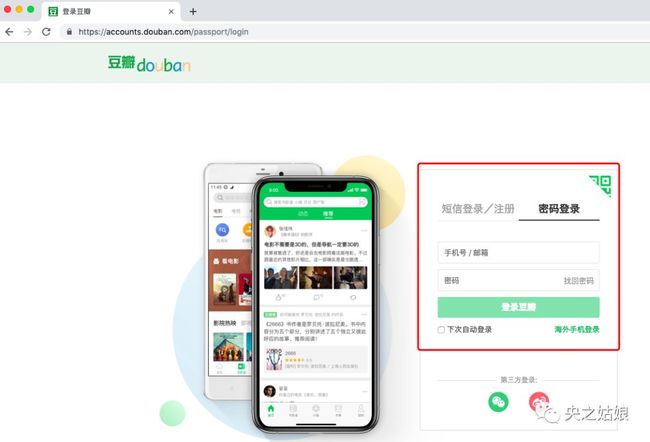
其次要处理请求头 Header,发送附带账户名和密码的 POST请求,并获取登陆后的 Cookie值,保存在会话里。
登陆进去之后,我们就可以长驱直入进行爬虫了;否则,它就会因请求不合法报错。
代码示例
# 1. 创建session对象,可以保存Cookie值
ssion = requests.session()
# 2. 处理 headers
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
headers={ 'User-Agent':user_agent}
# 3. 需要登录的用户名和密码
data = { "email":"豆瓣账户名XX", "password":"豆瓣密码XX"}
# 4. 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里
ssion.post("https://www.douban.com/accounts/login", data = data)
respon=ssion.get(url,headers=headers)
2. 分析网页结构
进入读书页面,右键选择“检查”,可以看到如下界面:当鼠标定位在某一行代码时,就会选中左侧对应模块。
所有图书内容的标签,存放在一个类名为 id="content"的div盒子, class="subject-item"的li盒子。
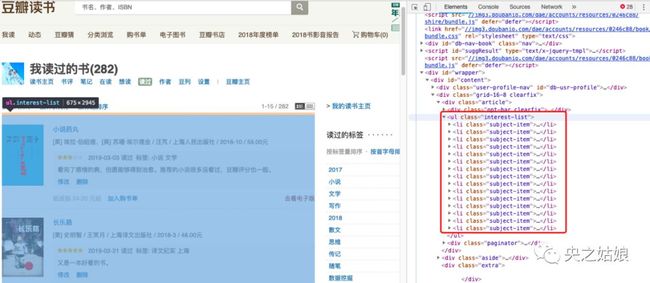
同样方法,我们也可以找到书名、作者、出版社、何时读过、评论信息,分别对应哪些标签。
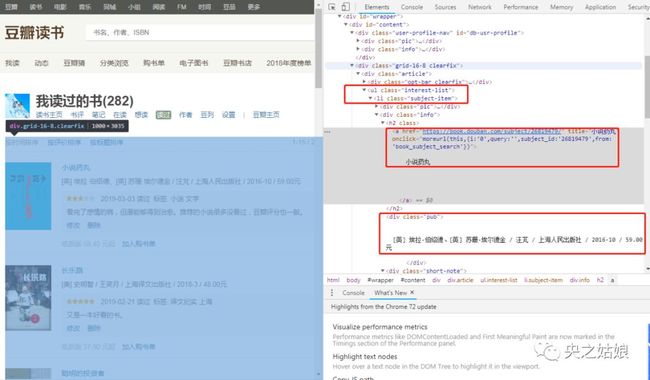
最终,我们通过CSS路径提取来提取对应标签数据。
代码示例
#因为每页有15本书,所以这里做了个循环
for tr in trs:
i = 1
while i <= 15:
data = []
title = tr.xpath("./ul/li["+str(i)+"]/div[2]/h2/a/text()")
info = tr.xpath('./ul/li['+str(i)+']/div[2]/div[1]/text()')
date = tr.xpath('./ul/li['+str(i)+']/div[2]/div[2]/div[1]/span[2]/text()')
comment = tr.xpath('./ul/li['+str(i)+']/div[2]/div[2]/p/text()')
3. 自动翻页,循环爬取
因为要爬取历史读书清单,当爬完一页的时候,需要程序能够实现自动翻页功能。
一种方法是让它自动点击下一页,但这个学习成本有点高,吃力不讨好;另一种方法,就是寻找网页之间的规律,做个循环即可。
以央之姑娘的豆瓣账户为例:很容易发现网页之间的区别仅在于start值不同,第一页的 start=0,第二页 start=15,以此类推,最后一页,即19页的 start=(19-1)*15=270.
找到这样的规律就很容易实现Python自动翻页功能,条条大路通罗马,适合自己的就是最好的。
代码示例
def getUrl(self):
i = 0
while i < 271:
url = ('https://book.douban.com/people/81099629/collect?start='+str(i)+'&sort=time&rating=all&filter=all&mode=grid')
self.spiderPage(url)
i += 15
4. 数据存储
数据存储有很多种方法,因为数据量不大,用Excel即可满足,具体方法就不在这里赘述了。
代码示例
def __init__(self):
self.f = xlwt.Workbook() # 创建工作薄
self.sheet1 = self.f.add_sheet(u'央之姑娘', cell_overwrite_ok=True) # 命名table
self.rowsTitle = [u'编号',u'书名', u'信息', u'读过日期', u'评论'] # 创建标题
for i in range(0, len(self.rowsTitle)):
# 最后一个参数设置样式
self.sheet1.write(0, i, self.rowsTitle[i], self.set_style('Times new Roman', 220, True))
# Excel保存位置
self.f.save('C://Users//DELL//央之姑娘.xlsx')
def set_style(self, name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name
font.bold = bold
font.colour_index = 2
font.height = height
style.font = font
return style
三、效果演示
前面讲了爬虫的原理和方法,那么接下来我们就展示一下具体效果:
以上就是本次分享的主要内容,因为是第一次爬虫,有借鉴前人经验,且尚有优化空间。
如果您有更好的方法欢迎交流探讨,如果您觉得内容还可以也欢迎转发推荐哦。
人生苦短,等你来玩ing~

附录:完整代码
from lxml import etree
import requests
import xlwt
import xlrd
class douban(object):
def __init__(self):
self.f = xlwt.Workbook() # 创建工作薄
self.sheet1 = self.f.add_sheet(u'央之姑娘', cell_overwrite_ok=True) # 命名table
self.rowsTitle = [u'编号',u'书名', u'信息', u'读过日期', u'评论'] # 创建标题
for i in range(0, len(self.rowsTitle)):
# 最后一个参数设置样式
self.sheet1.write(0, i, self.rowsTitle[i], self.set_style('Times new Roman', 220, True))
# Excel保存位置
self.f.save('C://Users//DELL//央之姑娘.xlsx')
def set_style(self, name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name
font.bold = bold
font.colour_index = 2
font.height = height
style.font = font
return style
def getUrl(self):
#自动翻页
'''
url = ('https://book.douban.com/people/81099629/collect?start=0&sort=time&rating=all&filter=all&mode=grid')
self.spiderPage(url)
'''
i = 0
while i < 271:
url = ('https://book.douban.com/people/81099629/collect?start='+str(i)+'&sort=time&rating=all&filter=all&mode=grid')
self.spiderPage(url)
i += 15
def spiderPage(self,url):
if url is None:
return None
try:
data=xlrd.open_workbook('C://Users//DELL//央之姑娘.xlsx')
table=data.sheets()[0]
rowCount=table.nrows#获取行数
# 1. 创建session对象,可以保存Cookie值
ssion = requests.session()
# 2. 处理 headers
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
headers={ 'User-Agent':user_agent}
# 3. 需要登录的用户名和密码
data = { "email":"豆瓣账户名XX", "password":"豆瓣密码XX"}
# 4. 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里
ssion.post("https://www.douban.com/accounts/login", data = data)
respon=ssion.get(url,headers=headers)
htmltext=respon.text
s = etree.HTML(htmltext)
trs = s.xpath('//*[@id="content"]/div[2]/div[1]')
m=0
for tr in trs:
i = 1
while i <= 15:
data = []
title = tr.xpath("./ul/li["+str(i)+"]/div[2]/h2/a/text()")
info = tr.xpath('./ul/li['+str(i)+']/div[2]/div[1]/text()')
date = tr.xpath('./ul/li['+str(i)+']/div[2]/div[2]/div[1]/span[2]/text()')
comment = tr.xpath('./ul/li['+str(i)+']/div[2]/div[2]/p/text()')
title=title[0] if title else ''
info=info[0] if info else ''
date=date[0] if date else ''
comment=comment[0] if comment else ''
data.append(rowCount+m)
data.append(title)
data.append(info)
data.append(date)
data.append(comment)
i += 1
for n in range(len(data)):
self.sheet1.write(rowCount+m,n,data[n])
m+=1
print(m)
print(title, info, date, comment)
finally:
self.f.save('C://Users//DELL//央之姑娘.xlsx')
if '_main_':
qn=douban()
qn.getUrl()