cayley的图数据库的使用之自我笔记
由于工作原因,学了两天cayley的图数据库,现把使用经验总结如下:
以下都是基于widnows环境进行的调试
1 安装
Go语言平台的安装(略,自行百度解决)
Cayley下载https://github.com/cayleygraph/cayley/releases
2. 使用
安装完成之后,你会看到一个【cayley.exe】的文件,它就是我们要用的程序了。
1. 初始化数据库
初始化数据库要用到的命令是 init ,你可以使用两种方式初始化,一种是命令行,一种是配置文件。
我们先来看命令行的形式:
- leveldb : cayley.exe init --db=leveldb --dbpath=tmp/testdb —— 你存储数据的目录就是【tmp/testdb】,它会在这个目录下,建立leveldb数据库;
- bolt : cayley.exe init --db=bolt --dbpath=tmp/testdb —— 你存储数据的文件名是【tmp/testdb】,它会在【tmp】目录下,创建一个叫做【testdb】的bolt数据库文件;
- mongo : cayley.exe init --db=mongo --dbpath=”
: ” —— HOSTNAME和PORT指向你的Mongo实例。
启动mongod
windows
- D:\mongodb\Server\4.0\bin\mongod.exe --dbpath D:\mongodb\data\db
Linux:
./mongod --dbpath=/data/mongodb &
sudo su – //切到root
外网可以访问:
./mongod --dbpath=/data/mongodb --bind_ip_all
初始化
cayley.exe init -d mongo -a "127.0.0.1:27017"
cayley.exe init -d mongo -a "127.0.0.1:27017"
Linux:
./cayley init -d mongo -a "127.0.0.1:27017"
cayley init -d mongo -a "
加载:只能本机访问
cayley.exe http --db=mongo --dbpath="127.0.0.1:27017"
Linux:
启动:
./cayley http --host=0.0.0.0:64210 --db=mongo --dbpath="127.0.0.1:27017" &
cayley.exe http --host=0.0.0.0:64210 -c cayley_example.yml
./cayley http--host=0.0.0.0:64210-c cayley_example.yml
Mongodb 清库
./mongo 进入命令提示符状态
./mongo
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
runoob 0.000GB
接下来我们切换到数据库 runoob:
> use runoob
switched to db runoob
>
执行删除命令:
> db.dropDatabase()
{ "dropped" : "runoob", "ok" : 1 }
最后,我们再通过 show dbs 命令数据库是否删除成功:
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
初始化mongodb库:
./cayley init -d mongo -a "127.0.0.1:27017"
Cayley初始化
- mysql: 此处亲测用的此方法
启动连接mysql数据库,并初始化表结构
cayley.exe init --db=mysql --dbpath="root:root@tcp(localhost:3306)/cayley"
加载mysql数据库
cayley.exe http --db=mysql --dbpath="root:root@tcp(localhost:3306)/cayley"
linux
curl -d 'g.V().Out().All()' 'http://127.0.0.1:64210/api/v1/query/gizmo'
2. 数据的操作(用的http方式)
增:
删:
查:
改:api没有提供,可用:先删除后增加的方式处理
3 数据及api说明
在使用之前,我们先来看一看,cayley里的数据,是什么样的。比如以【data/testdata.nq】为例:
1
2
3
4
5
6
7
8
9
10
11
它是由一条条四元组构成,其中第一个叫subject(主语),第二个叫predicate(谓语),第三个叫object(宾语),第四个叫Label(可选),以.结尾。subject和object会转换成有向图的顶点,predicate就是边。label的用法我查了google group,意思是说,你可以在一个数据库里,存多个图,用label来区分不同的图,但是我没有找到关于它的用法。
这张图的关系如下:
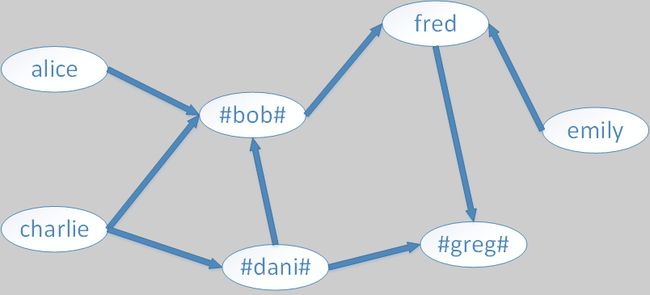
其中箭头指明了follows的关系,而#括起来的人名表示,这些人有status为cool_person。
下来我们来看对cayley数据库的增删查:
增
1 cayley> :a
subject
predicate object label .
比如我要添加一个人叫“leon”,他关注了“alice”,并且他也是一个“cool_person”,那么输入这样的命令即可:
1 cayley> :a leon follows alice .
2 cayley> :a leon status cool_person .
删
1 cayley> :d subject predicate object .
比如我刚才添加的“leon”,现在他不想关注“alice”了,那么这样就可以删除刚才建立的关系了:
1 cayley> :d leon follows alice .
查
对于查询,cayley提供了两种查询语言,一种是类似于JavaScript的语言,一种是简化的MQL。这里我选用类JavaScript的查询语言。因为它的文档相对完整一些。我会通过介绍对象的方式,把查询方法逐一阐述。
1. graph 对象,简写为 g ,它的存在是唯一的,由它来产生 query 对象,进而返回各种查询结果。它可执行的方法如下所示:
graph.Vertex([nodeId],[nodeId]…) 简写为 g.V
参数:nodeId(可选):一个字符串,或者字符串列表,代表了查询的起始节点
返回:query 对象
从给定的顶点(集)开始一个查询路径,如果没有参数,则认为是图中所有的顶点。
举例:
1 // 我想看目前图中所有的顶点
2 g.V().All()
3 // 我想获得alice这个节点
4 g.V(“alice”).GetLimit(1)
其中All()方法是query对象的方法,用它可以遍历query对象中,所有的数据。GetLimit(number)也是query对象的方法,它获得迭代集里限定数目的数据。
graph.Morphism() 简写为 g.M()
无参数
返回:path 对象
创建一个态射path对象,它本身是不能被查询的,它定义了一类路径映射,可以存储到变量里,在别的查询语句里使用。具体使用之后介绍。主要是和 path.Follow(),path.FollowR()配合使用。
2. path 对象,它是query对象的父类对象。
path对象由 g.V() 和 g.M() 创建,其中 g.V() 创建了query对象,它是path对象的子类。
我们的查询,主要就是使用这个对象,下面以【testdata.nq】里的数据为例,介绍一下都有哪些查询方法。
path.Out([predicatePath],[tags])
参数:predicatePath(可选)下列其中之一
空或者undifined:所有从这个节点出去的predicate。
一个字符串:从这个节点出去的predicate名字。
字符串列表:从这个节点出去的多个predicate名字。
一个query path对象:
tags(可选)下列其中之一
空或者undifined:没有tags
一个字符串:向输出集使用的指明predicate的标签
字符串列表:添加多个tags
这个方法从path对象开始,通过predicate指向其他objects,也就是要查询的数据。
举例:
1 // 查看charlie follows了谁。结果是 bob and dani
2 g.V("charlie").Out("follows")
3 // 查看alice follows的人,他们又follows了谁。结果是 fred
4 g.V("alice").Out("follows").Out("follows")
5 // 从dani出去的路径都指向了哪里。 结果是 bob, greg 和 cool_person
6 g.V("dani").Out()
7 // 找到所有dani通过follows和status指向的节点。
8 // 结果是 bob, greg 和 cool_person
9 g.V("dani").Out(["follows", "status"])
10 // 找到所有dani通过status指向的节点,并加上tag。
11 // 结果是 {"id": cool_person, "pred": "status"}
12 g.V("dani").Out(g.V("status"), "pred")
g.V("andy").Out(g.V("isHave"), "pred").All()
{"result":[{"id":"andy is good","pred":"isHave"},{"id":"andy like girl","pred":"isHave"}]}
path.In([predicatePath],[tags])
和path.Out()用法想同,只不过path.In()查询的是入度,path.Out()查询的是出度。
path.Both([predicatePath],[tags])
用法同上,既查询入度也查询出度。项目文档里说目前这个方法的效率相对来说比较低,因为它是通过Or方法实现的。但是在需要的情况下,还是很有用的。
path.Is(node,[node..])
参数:node:一个或者多个node。
过滤出所有指向参数节点的路径。
举例:
1 // 从图中所有节点出发,找到follows指向bob的路径
2 // 结果显示三个路径指向bob (来自 alice, charlie and dani)
3 g.V().Out("follows").Is("bob")
path.Has(predicate,object)
参数:predicate:指明predicate,也就是哪类路径。
object:指向的节点
过滤出所有通过predicate指向object的节点
举例:
1 // 从所有节点开始,找到谁follows了bob。结果是 alice, charlie and dani
2 g.V().Has("follows", "bob")
3 // follows charlie的人之中,哪些人follows了fred。结果是 bob
4 g.V("charlie").Out("follows").Has("follows", "fred")\
Tagging
path.Tag(tag) 简写为 path.As
参数:tag:为结果集的key赋予一个字符串。
为了保存你的工作,或者了解路径是怎么到达终点的,cayley提供了tags。
举例:
1 // 从所有节点开始,把他们保存到“start”中,找到所有有status的predicate,并返回结果
2 // 结果是 {"id": "cool_person", "start": "bob"}, {"id": "cool_person", "start": "greg"}, {"id": "cool_person", "start": "dani"}
3 g.V().Tag("start").Out("status")
path.Back(tag)
参数:tag:要跳回的在query里保存的之前的tag名
举例:
1 // 从所有节点出发,把它们保存到“start”中,找到有status的predicate的连接,然后跳回到“start”中,看看有谁follows了他们,返回结果
2 // 结果是:
3 // {"id": "alice", "start": "bob"},
4 // {"id": "charlie", "start": "bob"},
5 // {"id": "dani", "start": "bob"},
6 // {"id": "charlie", "start": "dani"},
7 // {"id": "dani", "start": "greg"}
8 g.V().Tag("start").Out("status").Back("start").In("follows")
path.Save(predicate,tag)
参数:predicate:predicate名
tag:一个tag名用来保存object节点
从当前节点开始作为subject,把它通过predicate连接的节点保存在key为tag指向的value里。
举例:
1 // 从 dani 和 bob 开始,查看他们follows了谁,并把结果保存在 “target”中
2 // 结果:
3 // {"id" : "dani", "target": "bob" },
4 // {"id" : "dani", "target": "greg" },
5 // {"id" : "bob", "target": "fred" },
6 g.V("dani", "bob").Save("follows", "target")
----------------------------------------------------------------------------------------------------------------------------------------------------------
Joining
path.Intersect(query) 简写为 path.And
path.Union(query) 简写为 path.Or
path.Except(query) 简写为 path.Difference
这三个放到一起,就是比较两个path对象中,取交集的数据、取并集的数据和取差集的数据。
参数都只有query对象。
举例:
1 var cFollows = g.V("charlie").Out("follows")
2 var dFollows = g.V("dani").Out("follows")
3 // 1. Intersect
4 // charlie follows的人 (bob and dani) 和 dani follows的人 (bob and greg) -- 返回 bob
5 cFollows.Intersect(dFollows)
6 // 或者相同的方式
7 g.V("charlie").Out("follows").And(g.V("dani").Out("follows"))
8 // 2. Union
9 // charlie (bob and dani) 或 dani (bob and greg) follows的人 -- 返回 bob (来自 charlie), bob (来自 dani), dani and greg.
10 cFollows.Union(dFollows)
g.V("charlie").Out("follows").Union(g.V("dani").Out("follows")).All()
11 // 3. Except
12 // 从charlie follows的人中,去掉dani follows的人-- 返回 dani
13 cFollows.Except(dFollows)
14 // 或者相同的方式
15 g.V("charlie").Out("follows").Except(g.V("dani").Out("follows"))
使用 Morphisms
path.Follow(morphism)
path.FollowR(morphism)
这两个放到一起,因为它们都用到了morphism path对象。
参数:morphism:一个态射路径。
有了graph.morphism,我们可以准备一个可复用的path。
Follow是从morphism定义的路径,顺序查找节点,而FollowR是逆序查找节点的。
举例:
1 friendOfFriend = g.Morphism().Out("follows").Out("follows")
2 // 定义一个morphism为:从给定节点出发,它follows的节点所follows的节点。
3 // 查找charlie follows的人所follows的人里,谁的有status为cool_person
4 // 结果为 bob 和 greg
5 g.V("charlie").Follow(friendOfFriend).Has("status", "cool_person")
g.V("charlie").Follow(g.Morphism().Out("follows").Out("follows")).Has("status", "cool_person")
6 // 从所有节点出发,找到谁follows的人里,follows了status为cool_person的人
7 // 结果:emily,bob,charlie(来自 bob),charlie(来自greg)
8 g.V().Has("status", "cool_person").FollowR(friendOfFriend)
g.V().Has("status", "cool_person").FollowR(g.Morphism().Out("follows").Out("follows"))
关于Query对象
query.All()
没有参数,返回值任意。执行结果是query里所有的数据。
query.GetLimit(size)
参数是size,和All()方法一样, 只不过加上了返回结果数量的限制。
query.ToArray()
没有参数,返回一个Array。
query.ToValue()
没有参数,返回一个字符串。和ToArray()方法一样,但是只返回一个结果,就像Limit(1)
query.TagArray()
和ToArray()一样,只不过返回的不是string数组,而是一个键值对数组。
query.TagValue()
和ToValue()一样,返回一个只包含一个tag-to-string的map。
query.ForEach(callback),query.ForEach(limit,callbaack) 简写为 query.Map
略。
查询需要的api
查宾语
g.V("100001").Out(“姓名”).All() 输出:张三
返回年龄出去的第一级节点。不包括关系。
查主语
g.V('张三').In('姓名').All() 输出:100001
图数据库建模规则
主语:员工id 100001
谓语关系: 姓名
值: 张三