性能竞赛优秀项目 | 以「点」窥面,PointGet 性能优化分享
作者介绍:
彭笳鑫,杭州帷幄匠心研发工程师。他们的队伍稳如狗的 HelloKitty 在性能竞赛中斩获二等奖,本文将通过他们的参赛项目,介绍如何用 PointGet 作为突破口,来提升查询的吞吐量与查询的性能。
在分布式数据库 TiDB 中如何更好的提高查询的吞吐量和提升查询的性能一直是一个难题。PointGet 虽小,但我们可以从 PointGet 中窥探出TIDB的特性变迁。PointGet 由于查询方式固定,所以就被剥离出来抽象成了一条特殊的 Plan,这样可以更准确的去做相应的优化,后面会细讲。为了更好的从整体流程和针对优化方面学习 TiDB,我们特意挑选了 PointGet 来作为突破口来优化上述提到的性能,这样就可以站在巨人的肩膀上专门去优化 TiDB 抽象出来的 PointGet 相关的逻辑,更加 focus 在有意义和创造力的地方。
我们团队有三位队友和一位顾问,从比赛一开始顾问就直接电话沟通了一下我们各自对于这个赛题的想法和观点。我们提出了很多没有基于现实情况的假设,顾问指出了很多我这边臆测的问题点,也为后面定位问题和解决问题提供了非常良好的帮助。我们也参加了 TiDB 在 B 站的 Talent 计划,根据视频的内容也对现有的 TiDB 有了更加深入的理解,更好的支撑了我们对于完成这个赛题的信心。
什么是 PointGet?
PointGet 是一个简单的点查,展示 SQL 如下
SELECT * FROM user WHERE id = 1;
PointGet 的执行流程
本文先把 TiDB 官方的流程图贴在下方,这样更好的能让大家对整体的 SQL 流程有个感知。图中客户端发起请求,TiDB 的服务端接收到对应的数据包,服务端 Parse、Valid 等步骤生成 AST,接着通过逻辑优化和物理优化生产对应的执行计划,接着通过对应的执行算子去执行对应的 Plan,接着通过 RPC 去访问 TiKV 获取对应的数据。
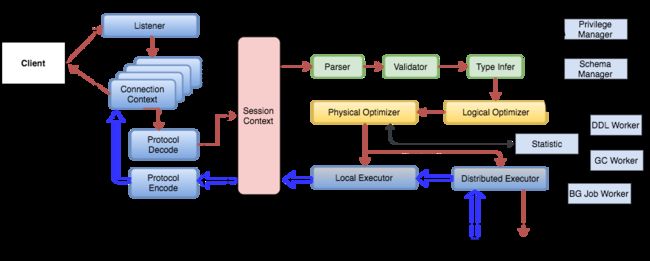
SQL 查询流程
上图的流程图我们可以看出来,PointGet 有这自己的 PointGet Plan 和 PointGet Executor,接着是跟上面的流程是一样的。
以上的情况我们可以发现可以优化点如下:
-
PointGet 是一个非常简单的点查,基本可以理解为一个查询一个结果;
-
PointGet 是一个点查操作,配合 lock 的特性可以大大增加可靠性和稳定性;
-
无论几次 query 都会访问 TiKV,第一次查询可以访问 TiKV,后面的查询可以直接复用以前查询的结果。
调研和设计优化 PointGet 问题点的解决方案
面对以上优化点,我们设计一个方案来解决上面提到的问题,这个方案涉及到了 DDL 和 DML 相关模块,DML 流程图展示如下:

上图简化了很多流程,最直接的就是在 executor 和 tikv 中增加了一层 cache,这个做法的直接效益是将数据从TIKV层返回移到TIDB层返回,减少一层网络开销。同时,数据从 cache 里面返回比从磁盘返回的速度更快。
我们接下来将讨论如何保障出现 DDL 的时候,Cache 数据更新的及时性以及 Cache 的内存管理问题。
TIDB 中 Cache 更新的及时性和内存管理问题
Cache 需要通过 TiDB 中的 Lock 特性来保证数据的一致性,Lock 非常贴合 PointGet 的 Query 要求,加锁的时候,数可以直接 Store 到 Memory 当中,Release 的时候可以直接删除对应的 Cache。完成上述设计后,我们发现添加对 Cache 管理这个特性会引来如下问题:
-
如果有多个 TiDB,DDL 的时候如何保证查询结果的一致性?
-
如果查询的表数据过大,缓存的 cache 会不会直接造成 TiDB 的 OOM?
-
引入新的代码是否符合社区的发展方向?
其中比较麻烦的是第一个问题,我们通过调研发现,TiDB 是实现了 Google 的一篇论文来管理 schema 变更的状态。基于这个特性,在某个 TIDB(TIDB Owner)做 DDL 操作后,其他 TiDB(TiDB worker)也会做相同的 DLL 操作,所以我们在解锁表的时候就可以清空所有 TiDB 里面的缓存,这样就不会出现不同 TiDB 里面的数据不一致的情况,比较优雅地解决了数据一致性的问题。
针对第二个 OOM 问题,原本打算实现一套 LRU 来做内存的管理和淘汰,但是根据 mentor 的提醒,我们调研了 MemDB 的底层逻辑代码。MemDB 是基于红黑树实现的,有优异的写入和读取特性。同时,MemDB 有专人维护同时也有着内存限制,不会由于用户的乱查询导致内存的飙升,规避了把服务器搞挂的风险,所以 Cache 以 MemDB 为底层的内存存储结构是一个符合社区未来发展方向的方案。
性能测试
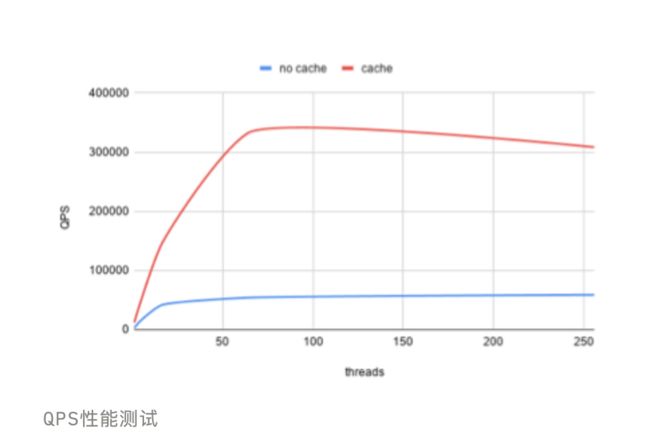
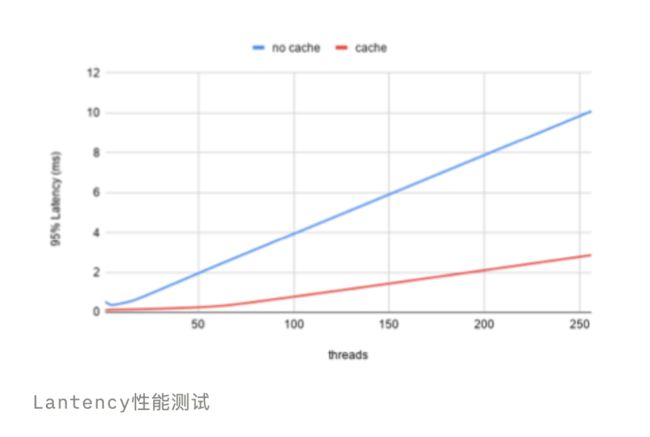
我们可以很明显的发现,增加了 Cache 的处理能力和 p95 的响应能力更加的优秀,QPS 上面有些许的下降是由于 Cache 的数据过多导致超过了分配的内存上限有重新分配了一个新对象,后期可以增加一个 LRU 的话就会更加完美。
额外发现
在我们做 benchmark 的时候,发现了表即使是在 lock 状态,update 等语句也可以正常执行,这并不符合 lock 的语义。我们当天整理了一下问题并且提出了 issue,PingCAP 的官方很及时的做出了响应,并且在接下来的几天内就解决了问题并且增加了对应的测试用例,非常具有及时性,值得点赞。
总结
在本次性能挑战大赛中,我们了解了 SQL 的一生和如何保证多个 TiDB 内数据一致,这非常有助于我们深入了解分布式数据库的内在。
同时,我们在为 TiDB 这样的大型开源项目贡献力量的时候,并不希望给 TiDB 引入有问题的代码,对于提交的代码会通过各种用例去测试他的健壮性,这也有助于提升我们编写可靠代码的能力。
特别感谢:
本抱着学习 TiDB 的心态参加了 B 站的学习视频,跟着课程提交了几次 PR,忽然发现PingCAP 还提供了竞赛并且每个赛题都会配置相应的 mentor,这是学习并且熟悉 TiDB 的好机会,衷心感谢 PingCAP 给大家提供了这么有价值的机会。在这次 2 个月的长跑中也要感谢 Reviewers(crazycs520,breeswish,jackysp,coocood 等)不遗余力的意见和建议,还有帅鹏(jackysp)的悉心指导,帮助我们把控方向。也感谢金泽和卓群提供了一些难点的建议。非常感谢各位运营小伙伴(汽水等)的提醒和帮助让我们这次顺利的"享受"了这次竞赛,体验很赞。