sklearn聚类算法Kmeans
sklearn聚类算法Kmeans
菜菜的sklearn学习笔记
文章目录
- sklearn聚类算法Kmeans
-
- 概述
- 案例
-
- 数据生成
- 聚类
-
- 类的质心
- 聚类的评估
- 可视化
- 分成4类会怎么样
概述
聚类算法是一种无监督学习算法,也就是说它不需要标签,只需要大量的特征就可以把数据集聚类,然后聚类在自己给他贴标签。 这里Kmeans的具体原理不作详述。
案例
数据生成
通过sklearn自带的make_blobs函数可以生成聚类所需的数据集,注意,所生成的数据集是几个分簇。
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1],marker='o',s=8)
plt.show()

上面是聚类前的图像,其中X是一个二维数组,每行有一个点的横坐标和纵坐标,y是已经给好的分类,是一个一维的数组,代表不同数据所在的簇。,下图是实际按不同簇分开的数据

聚类
聚类依然是通过
- 类的实例化
- fit()函数
- 可以直接同
.labels_或.fit_predict得到分类结果
from sklearn.cluster import KMeans
cluster = KMeans(n_clusters = 3, random_state = 0)
cluster = cluster.fit(X)
y_pred = cluster.labels_
#y_pred = cluster.fit_predict(X)
所得到的y_pred是一个一维矩阵,包含了每一个点对应的类分类,分别为0,1,2
类的质心
centroid = cluster.cluster_centers_
centroid == [[-7.09306648, -8.10994454], [-1.54234022, 4.43517599], [-8.0862351 , -3.5179868 ]]代表所分三类的质心。可以说这个点的特征最能代表这一个分类
聚类的评估
Inertia指每个样本点到其中心点的距离之和
inertia = cluster.inertia_
但似乎对于某些细长的类来说表现显然不太好,所以用轮廓系数来评估。
from sklearn.metrics import silhouette_score
silhouette_score(X,y_pred)
可视化
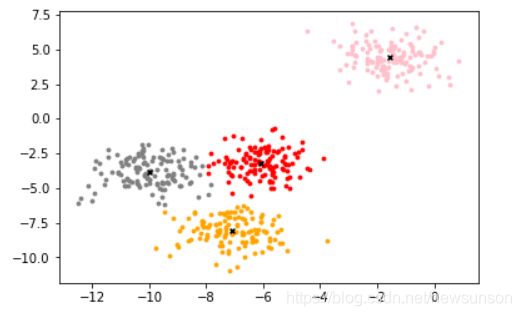
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(3):
ax1.scatter(X[y_pred==i, 0], X[y_pred==i, 1]
,marker='o'
,s=8
,c=color[i]
)
ax1.scatter(centroid[:,0],centroid[:,1]
,marker="x"
,s=15
,c="black")
plt.show()
那几个黑叉叉就是质心

分成4类会怎么样
会更合理