cs213n课程笔记
文章目录
- 一、计算神经网络(P1)
-
- 1 激活函数
-
- 实际操作:
- 2 数据预处理
- 3 权重初始化
- 4 批标准化
- 二、训练神经网络(P2)
-
- 1.梯度下降
-
- 实际使用
- 2.避免过拟合
- 3.正则化
-
-
- Training:Add random noise
- Testing: Marginalize over the noise
-
- 4.超参数调节
- 三、实践CNN
-
- 卷积转为矩阵运算(im2col)
- 图像卷积看作是信号中的频谱函数相乘
- 加速矩阵乘法O(n^3)
- 四、迁移学习
-
- Case Studys
- Also...
- 五、卷积神经网络案例
-
- AlexNet
- ZFNet
- VGG
- GoogLeNet
-
- InCeptionV1
- InCeptionV2V3
- ResNet
- 对比神经网络
- SENet
- Squeeze Net
- Improving ResNets...
-
- ResNeXt
- FractalNet
- DenseNet
- MobileNets, ShuffleNet
- Meta-learning
- 六、循环神经网络
-
- LSTM
-
- 避免梯度消失
- GRU
- Image Captioning
- NAS
- Attention
- 七、目标检测和分割
-
- 目标检测
-
- R-CNN
- Fast R-CNN
- Faster R-CNN
- 物体分割
-
- Mask R-CNN
- YOLO 系列
- 八、视频
-
- C3D: The VGG of 3D CNNs
- Separating Motion and Apperance: Two-Stream Networks
- Modeling long-term temporal structure
-
- Recurrent CNN
- 序列处理的几种方法优缺点对比
- Spatio-Temporal Self-Attention (Nonlocal Block)
- Inflating 2D Networks to 3D (I3D)
- Visualizing Video Models
- Treating time and space differently: SlowFast Networks
- Temporal Action Localization
- Spatio-Temporal Dection
- Recap: Video Models
一、计算神经网络(P1)
- Activation Functions:(ReLU)
- Data Processing(images: subtract mean)
- Weight Initialization (use Xavir/He init)
- Batch Normalizaition
1 激活函数
- Sigmoid 的饱和性导致梯度消失
- Sigmoid 导致所有的权重同向增大减小,导致zig(锯齿形) zag(急转)的更新方向
- exp()计算复杂度高,过大会越界
- tanh 避免了zig zag
- ReLU 不会饱和,计算简单收敛快,但会神经元死亡
实际操作:
- 使用ReLU,注意学习率
- 试一试Leaky ReLU/Maxou/ELU
- 试一试 tanh 但不要期待太多
- 不要用sigmoid
2 数据预处理
- 标准化,PCA白化(第一主成分方向即方差最大的方向,和第二主成分方向即与第一主成分正交的方向投影到坐标轴上,此时协方差矩阵为对角矩阵去相关了,再归一化,协方差矩阵为单位阵),ZCA白化(PCA白化基础上,再投影回原坐标系的方向);使各维度的梯度更新更平均
3 权重初始化
- Xavier /z wer/初始化,标准正态分布的基础上/np.sqrt(Din),即对感受野进行惩罚,Xavier初始化假设x,w都关于0对称,对于ReLU激活失效
- Kaiming 初始化(针对ReLU激活函数),标准正态分布的基础上 * np.sqrt(2/Din);
- 想让输入方差=输出方差:
- W服从正态分布,w ~ Normal(2, 2/d)
- W服从均匀分布,w ~ Uniform(sqrt(-6/d), sqrt(6/d))
- 想让输入方差=输出方差:
4 批标准化
- 放在非线性激活函数之前
- 加快收敛
- 改善梯度(远离饱和区)
- 可以使用大学习率(不必担心大学习率导致的梯度爆炸)
- 对初始化不敏感(废话)
- 起到正则化的作用
- 训练和测试的BN层是不一样的
- 训练:标准化每一个特征,再重参数化
- 测试:训练时的总均值代替 mini-batch 均值;训练时的总方差代替 mini-batch 方差
二、训练神经网络(P2)
- 优化训练误差
- 优化算法
- 学习率调整
- 优化测试误差
- 正则化
- 超参数选择
1.梯度下降
- SGD 随机梯度下降:在梯度较大的方向上发生震荡,陷入鞍点
- SGD + Momentum, 方向平滑,冲劲大会过头
- Nesterov Momentum:动量基础上Look ahead,先向速度方向前进,再向梯度方向前进
- AdaGrad: 惩罚梯度较大的方向,惩罚项为历史梯度的平方和,到最后更新幅度越来越小
- RMSProp:AdaGrad基础上,加入关于时间的衰减因子
- Adam:第一动量(Momentum)+第二动量(AdaGrad/RMSProp)
- Start with large learing rate and decay as over time
梯度下降是First-Order Optimization
若考虑Second-Order,与二阶导数的相关量(曲率,物理中的法向加速度)
广义相对论:在引力场中,时空的性质是由物体的“质量”分布决定的,物体“质量”的分布状况使时空性质变得不均匀,引起了时空的弯曲。因为一个物体有质量就会对时空造成弯曲,而你可以认为有了速度,有质量的物体变得更重了,时空弯曲的曲率就更大了。
二阶优化能更快收敛:牛顿法中,找一阶导数=0的位置,需要对一阶导数再求导,再迭代优化
\

但是海森的逆矩阵计算复杂,一般不用;
而使用BGFS(Quasi-Newton拟牛顿法,更新海森矩阵而O(n2)而不求逆运算O(n3)),L-BGFS(Limited memory BGFS,不储存完整的海森矩阵的逆)
推导:
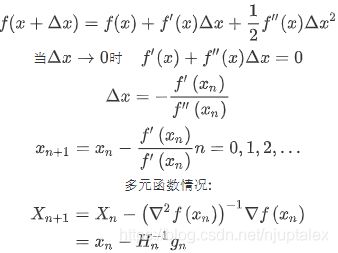
实际使用
- 用Adam,often works ok even with constant learning rate
- SGD+Momentum 可以比Adam表现的更好,但是需要多调节LR
- 若能承担复杂的计算量,使用 L-BFGS
2.避免过拟合
- Always do early stopping
- 模型集成(Enjoy 2% extra performance):checkpoint 集成(训练过程中不同时刻的集成);周期性增大学习率跳出局部最优点,训练出多种不同参数,再集成;
- L1和L2正则化
- Dropout达到多模型融合的效果,每次迭代都相当于一个子模型;让一些神经元单独决策,少受其他神经元的影响
3.正则化
Training:Add random noise
Testing: Marginalize over the noise
- Dropout
- Batch Normalization
- Data Augumentation
- DropConnect
- Fractional Max Pooling
- Cutout
- Mixup
- Consider Dropout for large fully connected layer
- Batch normalization and data augumentation almost always a good idea
- Try cutout and mixup especially for samall datasets
4.超参数调节
- 检查初始的loss是否正常
- 首先在小数据集上过拟合
- 寻找LR使得loss继续下降
- Coarse grid,训练1-5epoch
- Refine grid,train longer
- 观察loss曲线
三、实践CNN
参数量小,计算量小,更好的非线性表示能力
- 大卷积核换成多个小型卷积核
- 1*1卷积核用来降维和升维
- 多个长方形卷积核
卷积转为矩阵运算(im2col)
卷积核Conv weights: D filters, each K * K * C
拉成 D * (K^2 * C) 的矩阵(行向量)
Feature map: H * W * C
拉成(K^2 * C) * N(列向量)
矩阵点乘:D * N results reshape to output tensor
卷积核向量 * 感受野向量
图像卷积看作是信号中的频谱函数相乘
卷积理论:两个函数的卷积=两个函数傅里叶变换之后逐元素乘积
傅里叶变换:任何信号都可以由多个不同频率不同幅度的正弦信号累加而成,实现时域信号向频域信号的转换
卷积核可以看作是滤波器(低通模糊图像,高通提取边缘),提取图像不同频率的特征
图像看作二维信号,频域中高频的地方是像素明暗变化剧烈的地方
时域卷积=频域相乘:
- 分别计算卷积核和输入图像的FFT(快速傅里叶变换向频域转换)
- 计算逐元素乘积(存在0元素,则实现了滤波效果)
- 计算傅里叶逆变换
加速矩阵乘法O(n^3)
- Stassen 算法 O(N^2.81)
- Lavin & Gray 对3*3卷积的矩阵乘法的优化,在VGG上有2-3倍速度的提升
四、迁移学习
针对不同场景别随便迁移,预训练模型:特征抽取作为特定任务的Backbone
| 差异小的数据集 | 差异大的数据集 | |
|---|---|---|
| 数据量小 | 改动线性分类层 | trouble |
| 数据量大 | 多往前训练几层 | 往前训练更多层 |
Case Studys
- AlexNet: 2012冠军 Hinton团队 多伦多大学
- VGG: 2014亚军 VGG16 和VGG19 牛津大学
- GoogleNet: 2014冠军 Inception模块 谷歌
- ResNet: 2015冠军 残差模块 何凯明团队 MSRA
- LeNet:1998 CNN开山之作 纽约大学
Also…
- SENet:2017冠军,SE模块,Momenta+牛津 胡杰团队
- NiN(Network in Network):1*1卷积,Global Average Pooling
- Wide ResNet:增加残差块中卷积核的数量(宽度)
- ResNeXT:ResNet+Inception
- DenseNet:2017CVPR 最佳论文 Dense模块
- FractalNet:分形网络
- MobileNets:Group卷积和Depthwise Separable卷积
- NASNet:2018 神经架构搜索 强化学习 谷歌大脑
- SqueezeNet:斯坦福/伯克利 firemodule 压缩参数量
How transferable are features in deep nerual networks? NIPS 14
五、卷积神经网络案例
AlexNet
ImageNet classification with deep convolutional Neural Networks Krizhevsky et al. 2012
- 8 层
- 使用ReLU,比Sigmoid效率高上很多
- 使用Local Response Normalization 局部响应归一化;作用在同层中相邻的通道之间,VGG论文指出没啥意义,徒增计算量
- 使用不重叠的最大池化,认为这样可以防止过拟合,后来都不这么做了,进一步说明浅层网络的超参调节策略不能迁移到深层网络中
- 为了防止过拟合,使用数据增强手段:原本图像+PCA主成分向量X随机数向量,翻转,随机裁剪,平移变换,颜色光照变换
- 防止过拟合:dropout 0.5, 测试阶段失活一般神经元,测试阶段使用所有的神经元,但是将神经元的输出乘以0.5
- minibatch size 128,按一批的平均梯度进行更新
- SGD Momentum 0.9
- 卷积层的偏置项为1,鼓励ReLU进行正向激活,其他层bias为0,weights都为N(0,0.01)
- Learning rate 1e-2, reduced by 10
- L1 weight decay 5e-4;
- 7 CNN ensembles
ZFNet
Visualizing and Understanding Convolutional Networks Zeiler and Fergus 2013
- 8 层,改进AlexNet,更小的步长和卷积核,认识到的特征更细节并且有更少的"dead" features
- Deconvolution
- 反池化:记住最大池化时的最大值对应位置,还原至相应位置,其他位置为0
- 反激活:x=max(0,x)
- 转置卷积
- 找到验证集中激活最大的9张图片,并反池化反卷积重构到原始层。发现越深的层认识到的特征越细节
- 训练过程特征演化可视化:浅层认识的粗特征很快就收敛,而深层认识到的细特征多轮之后才逐渐收敛
- 平移,缩放,旋转敏感性分析:得到的第一层特征与原始输入之间的欧式距离:第一层微小变化带来显著影响,第七层微小变化带来线性影响
- 局部遮挡敏感性分析:找到第五层激活值最大的那个Feature Map,原图中移动遮挡块,记下不同位置时Feature Map,并叠加起来,制作热力图
- 相关性遮挡分析:对于不同的狗,都遮右眼,看delta(原始激活值-遮住的激活值)的MeanSD;遮住狗眼睛时,第五层delta小:说明此时网络认识到不同狗脸中狗眼睛是相关的;随机遮:第五层delta大,第七层delta小,说明深层网络认识到的特征越细节更倾向于关注语义特征
- 模型迁移泛化分析
- 各层特征有效性分析:取出不同层的Feature,用SVM分类,发现越深,越准
VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition Simonyan and Zisserman 2014
- VGG-16, VGG-19
- Small Filters 3✖3, 与7✖7的感受野相同
- 占用内存过大
- fc7 features 可以用在其他场景
GoogLeNet
InCeptionV1
Going Deeper with Convolutions (Inception V1)
非常好的一篇文章
- Introduction 中就说了GoogleNet只有5 million 参数,12倍小于AlexNet,还更加准确。提出不要一味追求精度,还要考虑设备上部署的效率;
启发:Network in network: 1 卷积,Global Average Pooling 取代全连接层;以及《Provable Bounds for Learning some deep representations》 用稀疏分散的网络取代以前庞大密集臃肿的网络
-
Related Work中首先提到启发来源,池化层虽然丢失空间像素精确,但是可以用来做定位和目标检测
《Overfeat: Integrated recognition, localization and detection using convolutional networks》
《Robust object recognition with cortex-like mechanisms》处理多尺度的输入(不同尺度的卷积核),类似Inception 模块
接着,提到了目标检测:《 Rich feature hierarchies for accurate object detection and semantic segmentation》首先找出候选区域,再对每个候选区域使用CNN来识别类别。 -
Motivation and high level considerations:增加深度和宽度,Inception 模块在利用现有模型的基础上,又实现了稀疏性减少计算;如果作为RCNN的基模型,对于定位和目标检测都很有用处
-
Architectural Details:设计思想是用密集模块来近似出局部最优稀疏结构;越靠近前面的层越提取局部信息,越靠近后面越提取大范围信息,所以嵌入到两层之间的Inception模块大的小的感受野都需要有;
使用1卷积的理由:受到embedding用低维dense向量代替高维稀疏向量启发,同时希望降维后向量能够不要那么密集压缩便于计算处理,采用1卷积,既可以降维又可以减少计算;
various scales visual information simultaneously processed and then aggregated -
GoogLeNet:GAP代替全连接层好处一,便于fine-tune迁移学习,好处二,提升了0.6%的Top-1准确度;浅层特征其实也有了一定的区分度,所以作者在4a和4b后面添加辅助分类器,计算两个辅助Loss,测试阶段去除辅助分类器。
L = L 最 后 + 0.3 L 辅 1 + 0.3 L 辅 2 L=L_{最后} + 0.3 L_{辅1} + 0.3 L_{辅2} L=L最后+0.3L辅1+0.3L辅2
-
Training Methodology: asynchronous stochastic gradient descent 异步随机梯度下降(因为数据并行输入);
调参玄学:dropout和learning rate,数据增强:裁剪为原图的8%-100%, 长宽比例调节至3/4-4/3之间,光度变换(Some improvements on deep convolutional neural network based image classification),等概率使用bilinear, area, nearest neighbor and cubic插值方法。 -
用于分类任务:一张图裁剪并镜像成144个patch输入,对144个softmax结果取平均得到预测类别;采用7个模型训练好的模型进行集成;比base降低了3.45%的Top5 Error
-
用于物体检测任务:如果算法给出的框分类正确且与正确标签的框的交并比(jaccard index)大于0.5则预测正确,同一类别的所有分类结果可以统计Confusion Matrix,算法评估使用mAP(每个类别不同阈值下PR曲线围成的面积=AP,不同类别的平均AP=mAP);
使用《Segmentation as selective search for object recognition.》Selective search 方法,使用《Scalable object detection using deep neural networks》multi-box predications 减少无用的候选框
没有使用框回归和,之间对候选框分类
使用Inception模型作为分类器
- 22 层
- Inception 模块
- 1×1卷积
- 降维
- 减少参数量和运算量
- 增加模型深度提高非线性表达能力
- GAP, 每一个通道求平均,不用FC,减少了参数量
- 可以利用GAP之后的值,配合最后FC的weights,制作Class Activation Map,用于关键信息定位
InCeptionV2V3
Rethinking the Inception Architecture for Computer Vision(Inception V2 V3)
-
Introduction 中提到的前沿应用
- RCNN (Object detection)
- Segmentation (全卷积网络)
- human pose estimation (Deeppose)
- video classification (李飞飞 CVPR2014)
- object tracking (NIPS 2013)
- superresolution (何凯明 ECCV2014,TPAMI2015)
-
General Design Principles
- 原则一:避免representation bottlenecks: 过度降维;feature map 的长宽应该随网络加深逐渐减小
- 原则二:Higher representations are easier to process locally within a network 特征越多,收敛越快,相互独立的特征越多,区分度越大
- 原则三:spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power
- 原则四:平衡width,depth
-
Facterizing Convolutions with Large Filter Size
- 大卷积替换成多层小卷积,只要提供相同大小的感受野就行了 ---- 减少了参数量
- Spatial Factorization into Asymmetric Convolutions: n x n --> 1 x n & n x 1
-
Auxiliary Classifiers
V1认为辅助分类器让浅层也学习到特征,辅助分类器能在浅层注入梯度,防止梯度消失;
这篇文章认为辅助分类器不能帮助模型更快收敛;辅助分类器只是起到了正则化的作用,所以这篇文章改为BN和Dropout来做正则化
-
Efficient Grid Size Reduction
原本方法:先池化再卷积违反原则一(过度降维浅层丢失信息),先升维再池化(计算量增加)都很expensive
高效下采样:
池化和卷积并行的Inception模块 ;加深——两条路径做卷积(卷积分解),一条路径做池化,再沿channel摞在一起
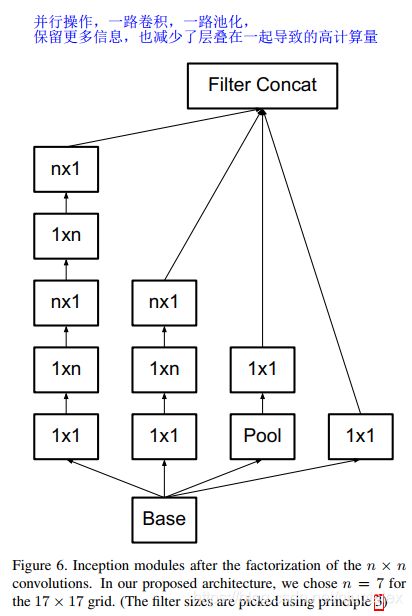
扩展滤波器组:加宽——用在模型的最深处,符合原则二:相互独立的特征越多,区分度越大,在最后分类层之前生成高维稀疏特征
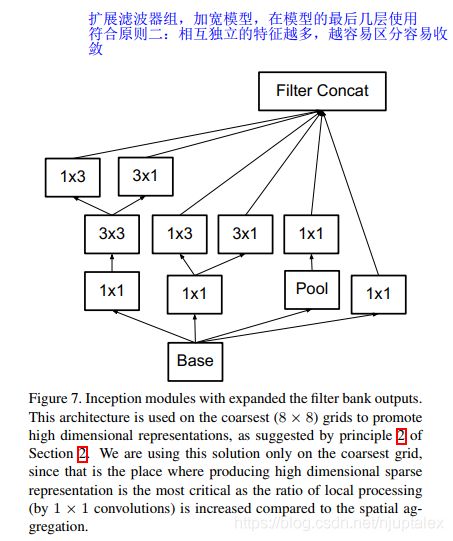
-
Inception-V2
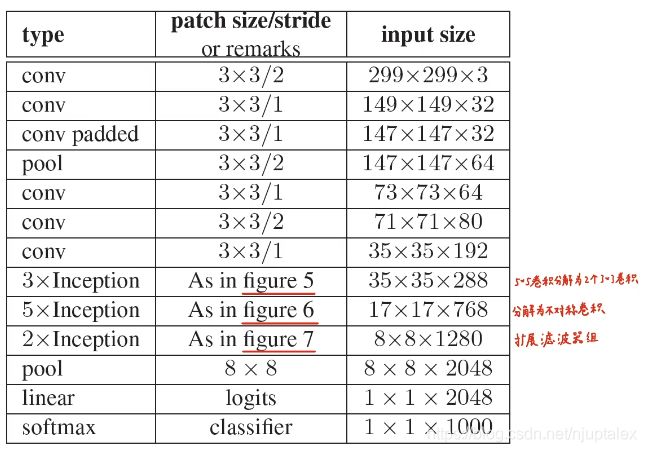
-
正则化之——标签平滑(LSR,Label Smooth Regulerzation)
因为交叉熵损失的原因,让label更趋近于softmax之后的分布(0.33,0.9,0.33,0.33),而不是独热编码(0,1,0,0)
防止过拟合:如果按照独热编码,网络就会尽可能让softmax之后的数为(0.0001,0.99999,0.00001,0.0000)那么在前一层得到的值就变成了(0.0001,正无穷,0.00001,0.00001)过于偏向正确标签
Hiton “When Does Label Smoothing Help?”
知识蒸馏(KD):通过引入teacher(复杂模型),诱导student(简单模型)的训练;
- 与GoogleNet的关系:
FITNETS:Hints for Thin Deep Nets【ICLR2015】
deep是DNN主要的功效来源,之前的工作都是用较浅的网络作为student net,这篇文章的主题是如何mimic一个更深但是比较小的网络。
使用的方法直觉上来讲也是直接的:既然网络很深直接训练会很困难,那就通过在中间层加入loss的方法,通过学习teacher中间层feature map来transfer中间层表达的知识,文章中把这个方法叫做Hint-based Training。(Inception V1 采用了该方法)
Knowledge Distillation in Generations: More Tolerant Teachers Educate Better Students【AAAI2019】
硬标签会导致模型产生过拟合现象,soft label对于模型的泛化能力有所帮助
常用的标签处理策略:label smoothing regularization(lsr)**(Inception V2 采用了该方法)**和confidence penalty(CP)两种方法,但其缺点是考虑了所有的类。本文提出了一个更合理的方法,没有计算所有类的额外损失,而是挑选了几个具有最高置信度分数的类。
teacher的loss中加入一个约束:min置信度Top1的标签的和其余K-1个标签平均值之间的gap
训练student的时候,用teacher 的soft label 和 hard label 融合
论文中实验在CIFAR-100和ILSVRC2012分类数据集上**涨点3%~8%**不等
-
ResNet
Very Deep networks using residual connections He et.al 2015
- 152 层
- BN after every CONV layer
- Xavier 2/initialization; 不改变ReLU输出输出的数据分布
- SGD + Momentum:0.9
- Learning rate 0.1
- mini batch: 256
- weight decay: 1e-5
- 没用dropout
对比神经网络
An Analysis of Deep Nerual Network Models for Practical Applications 2017
SENet
Squeeze-and-Excitation Networks (SENet)
- 接在其他模型的后面,自适应训练每个通道Feature Map的权重
Squeeze Net
Squeeze Net: AlexNet-level Accuracy With 50✖ Fewer Parameters and < 0.5Mb Model Size
- 1 降维,再一路1,一路3,合并
- 权重合并量化哈夫曼编码,模型裁剪
Improving ResNets…
ResNeXt
- 并行化更多的Res结构
FractalNet
FractalNet: Ultra-Deep Neural Networks without Residuals Larsson et al. 2017
DenseNet
Densely Connected Convolutional Networks huang et al. 2017
MobileNets, ShuffleNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Applications Howard et al.2017
- 每个通道用单独的卷积核卷积,再用1卷积提取跨层特征,大大减少参数量和运算量
- 车辆,行人目标 SSD+MobileNet
Meta-learning
Meta-learning: Learning to learn network architectures
Neural Architecture Search with Reinforcement Learning (NAS)
- RNN作为控制器,每一层的参数对应RNN序列
- 以概率p在搜索空间中选择一个网络架构,训练得到准确率作为奖赏R,计算概率p的梯度,传回到RNN控制器中
- 增加好模型的似然概率,降低坏模型的似然概率
- 先在小数据上训练,再迁移到大数据上
六、循环神经网络
- Vanilla RNN 简单但是效果不是很好,会梯度消失或者梯度爆炸
- 一般都是使用LSTM和GRU
- Exploding 使用gradient clipping, Vanishing 使用additive interactions(LSTM)
- 更好更简单的结构是研究热点
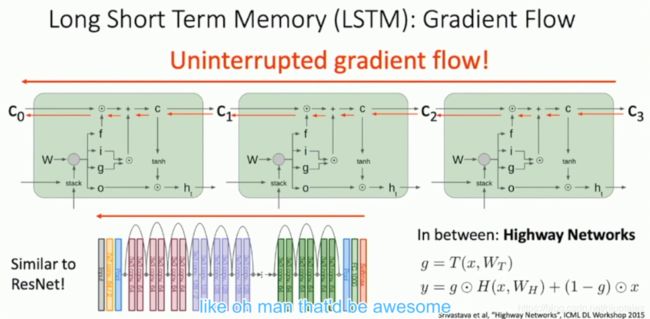
LSTM
输入:当前输入,短期记忆,长期记忆
输出:当前输出,短期记忆,长期记忆
长期记忆乘以一个sigmoid的结果(遗忘一些东西);加上sigmodi的结果和tanh的结果(加上一些记忆)
短期记忆:(短期记忆+当前输入)乘上第一套权重,经过simoid遗忘门,供给一个0-1之间的遗忘系数给长期记忆;(短期记忆+当前输入)乘上第二套权重,经过一个sigmoid,(短期记忆+当前输入)乘上第三套权重经过一个tanh,以上两者相乘,给长期记忆供给一些新的记忆;
新的短期记忆(当前记忆单元的输出值):(短期记忆+当前输入)乘上第四套权重经过一个sigmoid,长期记忆经过一个tanh,以上两者相乘得到新的短期记忆,同时共给下一层和作为当前层的输出。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z4j3h96a-1602579943887)(cs213n课程笔记 .assets/image-20200910200440937.png)]
避免梯度消失
与ResNet对比,长期记忆乘上一个0.x值,加上新的记忆,给到下一层的长期记忆,不论如何都会有值
Res模块:当前输入乘上一套权重,ReLU之后,加上当前输出,给到下一层
GRU
Gated Recurrent Unit
Learning phrase representations using RNN encoder-decoder for statistical machine translation, 2014
Image Captioning
输入图片,经过CNN得到特征向量,输入到RNN第一个hidden unit
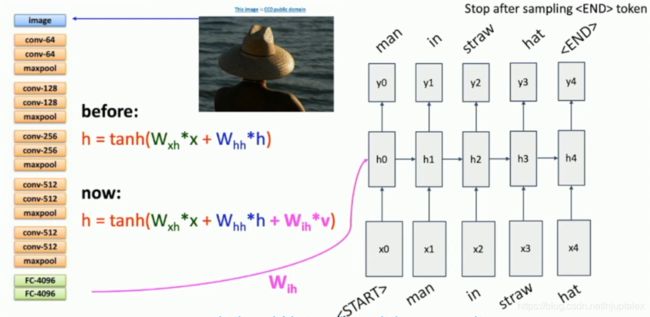
测试时,输入图片和
NAS
RNN Architectures: Neural Achitectures Search
Zoph and Le, " Neural Achitectures Search with reinforence learning" ICLR 2017
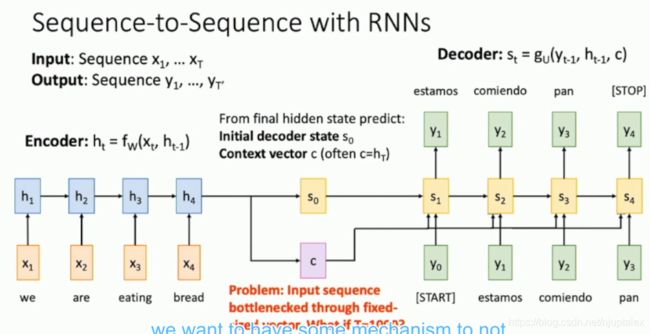
Attention
Sequence --> LSTM(Encoder) --> LSTM(Decoder) --> Sequence
Sutskever et al. “Sequence to Sequence Learning with Neural Networks” NIPS 2014
用于机器翻译任务
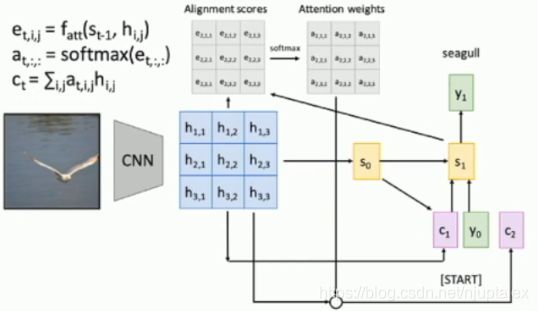
机器翻译中的Attention机制
Bahdanau et al. “Neural machine translation by jointly learning to align and translation” ICLR 2015
Decoder 的每一个 timestep 都乘上一个系数 (Context Vector)
Image Captioning 中的Attention机制
Xu et al. “Neural Image Caption Generation with Visual Attention” ICMK 2015
每个卷积核对应一个Attention weights,与原始卷积叠加得到Decoder 的每一个 timestep 都乘上的系数(Context Vector)
X, Attedn, Y
"Show, attend, and tell"(Xu et al, /CML 2015)
Look at image, attend to image regions, produce question
"Ask, attend, and answer"(Xu and Saenko, ECCV 2016)
"Show, ask, attend, and answer"(Kazemi and Elqursh, 2017)
Read text of question, attend to image regions, produce answer
"Listen, attend, and spell"(Chan et al, ICASSP 2016)
Process raw audio, attend to audio regions while producing text
"Listen, attend, and walk"(Mei et al, AAA/ 2016)
Process text, attend to text regions, output navigation commands
Attention Layer 的种类还挺多:Attention Layer, Self-Attention Layer, Masked Self-Attention Layer, Multihead Self-Attention Layer

七、目标检测和分割
目标检测
属于回归问题,Loss一般是L2
评价指标:mAP
-
单目标检测
label : (x, y, width, heigh)
-
多目标检测
根据目标数量不同,不同图片的label维度不同;一般首先选框,再用CNN判断类别
- 选框策略:启发式(从小到大直到选择出一个尽可能小且能框住所有物品的框)
R-CNN
Region-Based CNN
选大概2000个框,分别CNN,判断各个框类别,选择一个候选框子集(top-K,对背景或者类别设置阈值,保留满足threshold的框)
Fast R-CNN
对于原图,用一个backbone模型的前半部分得到Image features(使用全卷积以使得到的低维feature map中目标的相对位置和原图一致)–> crop (低维feature map中的crop 操作 fast)–> resize features --> per-region network (backbone 模型的后半部分) --> category and box transform per region
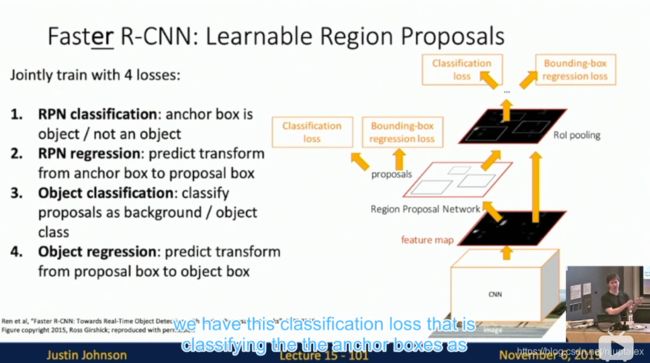
Faster R-CNN
Region propals computed by heuristic “Selective Search” algorithm on CPU. So let’s learn them with a CNN instead!
Insert Region Proposal Network (RPN) from features

联合训练4种Loss
人体姿态估计: label(14 个关节点的坐标(x,y))
物体分割
label(每个像素点对应一个类别)
全卷积网络(一般先降维,再升维)
Mask R-CNN
Attach a branch for mask prediction , 先多目标检测选框,再在框中做分割
YOLO 系列
八、视频
Raw Videos: long, high FPS
Training: Train model to classify short clips with low FPS
Testing: Test model on different clips and then average predictions
Early Fusion VS Late Fusion VS 3D CNN
- Single Frame model works well - always try this first
- 3D have improved a lot
C3D: The VGG of 3D CNNs
- 3 * 3 * 3 conv and 2 * 2 * 2 pooling
- The pretrained model on Sports-1M dataset was widely used as video feature extrator
- Problem: Too expensive conv operation
- AlexNet:0.7GFLOP
- VGG-16:13.6GFLOP
- C3D:39.5 GFLOP (2.9x VGG)
Separating Motion and Apperance: Two-Stream Networks
Simoyan and Zisserman “Two-stream convolutional networks for action recognition in videos”, NIPS 2014
Zisserman 大佬团队的
原图+光流(Optical Flow)图,early fusion, 分别使用convNets

Modeling long-term temporal structure
Donahue et al. “Long-term recurrent convolutional networks for visual recognition and description”, CVPR 2015
先用对每一帧用CNN提取,再用RNN串连 Feature Map,Good at long sequences
**Problem:**RNN计算费时不能并行
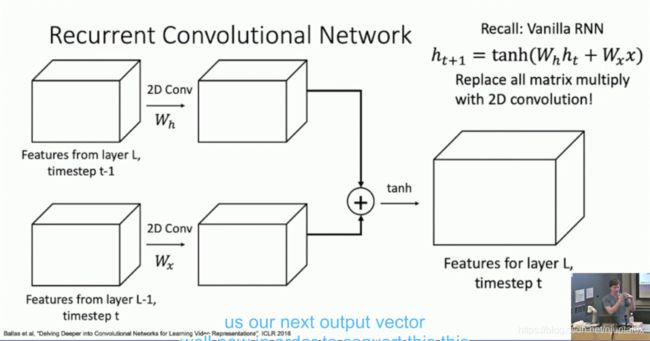
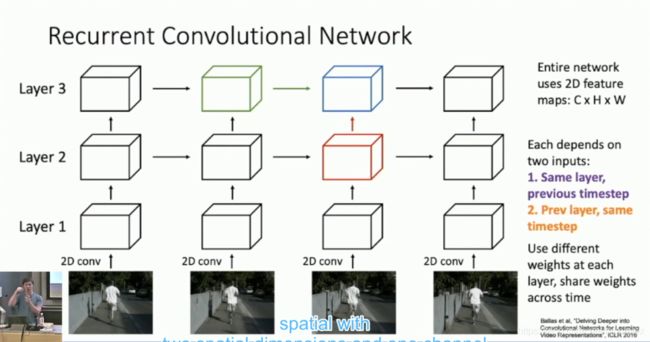
Recurrent CNN
Ballas et al. “Delving Deepper into Convolutional Networks for Learning Video Representations” ICLR 2016
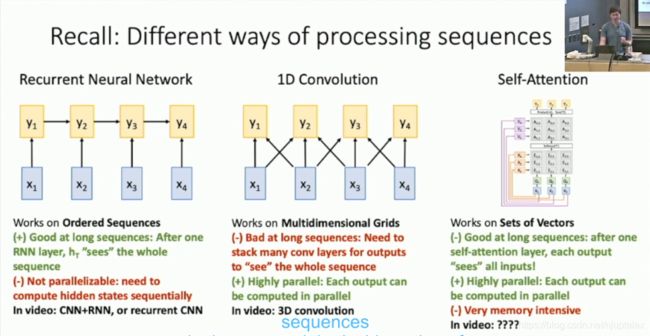
序列处理的几种方法优缺点对比
Spatio-Temporal Self-Attention (Nonlocal Block)
Wang et al. “Non-local neural networks” CVPR 2018
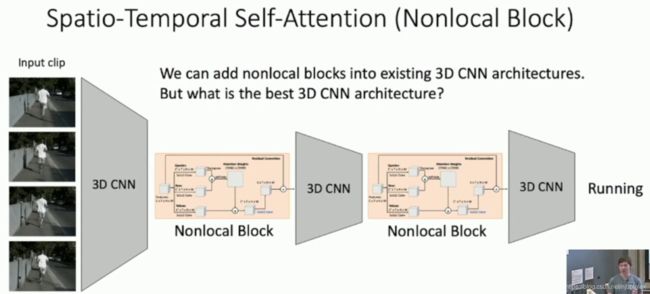
Inflating 2D Networks to 3D (I3D)
Carreira and Zisserman “Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset” CVPR 2017
这二作不是VGG的二作嘛?
- 提供了kinetics数据集
Visualizing Video Models
Feichtenhofer et al. “Deep Insights into Convolutional Networks for Video Recognition” IJCV 2019
Zisserman 这次是四作
添加一个term 鼓励平滑的光流,惩罚过快过慢的光流

可视化了Fast Motion 和 Slow Motion
Treating time and space differently: SlowFast Networks
Feichtenhofer et al. “SlowFast Networks for Video Recognition” ICCV 2019
-
Slow pathway: 选用low frame rate片段,经过大Channel,小Time 卷积
-
Fast pathway:同一个片段,但是使用high frame rate,经过小Channel,大TIme 卷积;Slow path的Channel x 1/8,TIme x 8,则两条路径的prediction维度相同
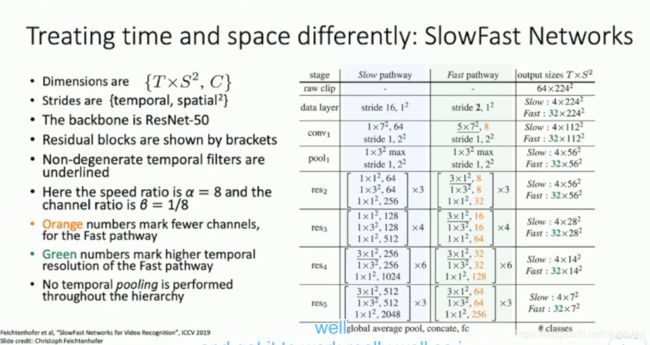
可以看到最后一层,Slowpath输出 C x T (2048 x 4),Fastpath输出 C x T (256 x 32) 维度相同
Temporal Action Localization
Chao et al, “Rethinking the Faster R-CNN Architecture for Temporal Action Localization” CVPR 2018

Spatio-Temporal Dection
Gu et al, “AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions” CVPR 2018
Recap: Video Models
- Single-frame CNN (Try this first!)
- Late fusion
- Early fusion
- 3D CNN / C3D
- Two-stream networks
- CNN+RNN
- Convolutional RNN
- Spatio-temporal self-attention
- SlowFast networks
- SoTA …