【今日CV 计算机视觉论文速览 第119期】Wed, 22 May 2019
今日CS.CV 计算机视觉论文速览
Wed, 22 May 2019
Totally 39 papers
?上期速览✈更多精彩请移步主页

Interesting:
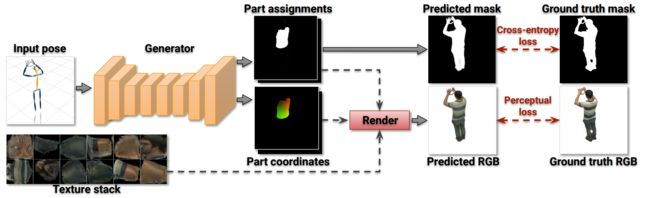
?全人体的渲染模型, 估计模型表面精确的材质信息,生成新视角和新动作的人体图像。(from 三星 斯科尔科夫Skolkovo理工)
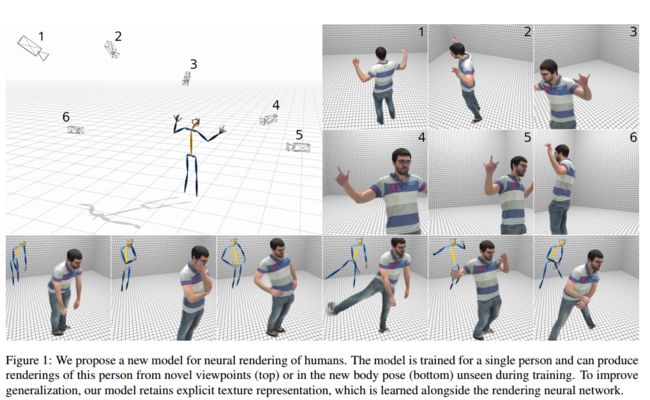
模型框架:
数据集:http://www.cs.cmu.edu/~hanbyulj/panoptic-studio/ICCV2015_SMC.pdf https://www.cs.cmu.edu/~hanbyulj/panoptic-studio/
code:https://saic-violet.github.io/texturedavatar/
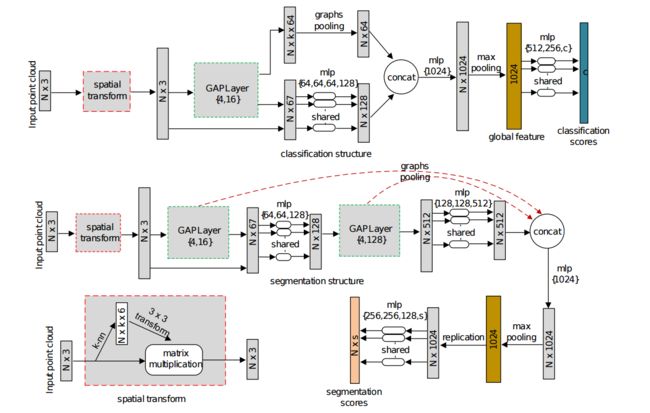
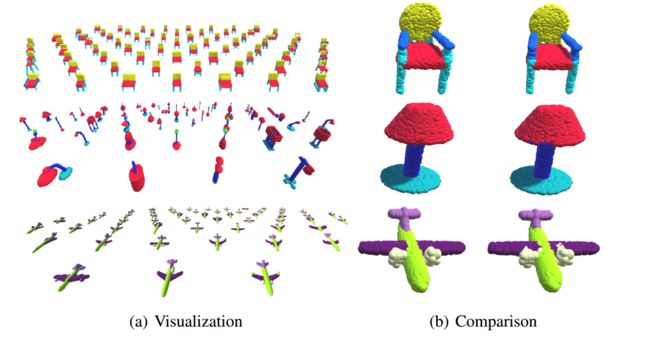
?GAPNet基于图注意力的点神经网络用于局域特征探索, 非欧空间中探索点云的语义特征充满挑战,局域特征用于上下文理解和注意力机制目前还没有深入研究。这篇论文中研究人员将多层感知机实现的嵌入图注意力机制来学习局域特征。GAP(Graph Attention Point)层用于学习每个点的注意力特征,随后利用多头机制探索特征,最后利用注意力池化层来捕捉重要信号。在ModleNet40和ShapeNet上取得了很好的语义分割结果。(from Cranfield University克兰菲尔德大学 英国)
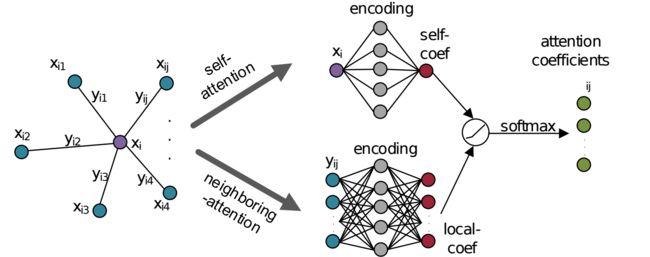
GAP层:
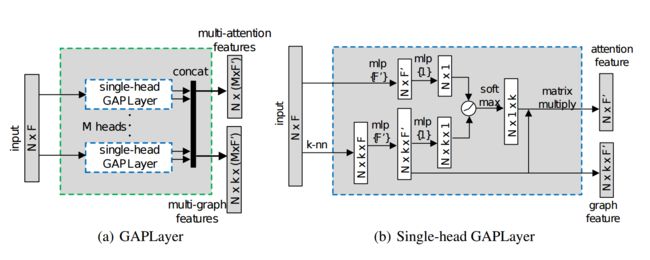
GAP模型架构:
结果如下图所示:
?VOICED,基于视觉惯性里程计的深度补偿,提出了一种利用视觉里程计的稀疏深度图和相机位置估计深度的方法。首先构建平面架构来推断稠密深度。 (from UCLA Vision Lab)

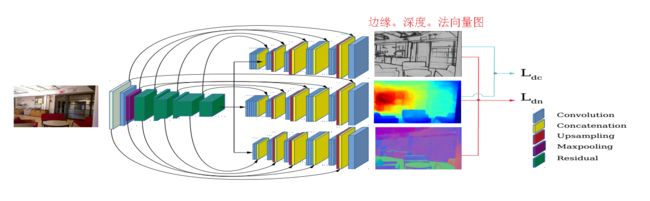
?SharpNet基于单目深度估计的快速遮挡轮廓恢复, 提出了一种单图像深度估计的有效算法,并聚焦于遮挡轮廓的重建。(from Université de Bordeaux波尔多)
结果:
室内渲染数据集:dataset:http://openaccess.thecvf.com/content_cvpr_2017/papers/Zhang_Physically-Based_Rendering_for_CVPR_2017_paper.pdf,
渲染流程:https://github.com/yindaz/pbrs https://www.pbrt.org/ 引擎mitsuba,文档
室内三维家装建模:https://planner5d.com/
室外合成数据集:SYNTHIA
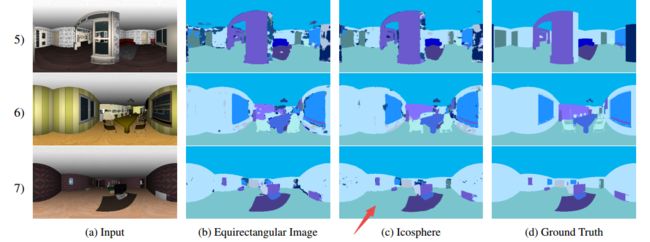
?基于平面测地线近似的球面卷积图像分割, (from 北卡 教堂山)
Daily Computer Vision Papers
| Textured Neural Avatars Authors Aliaksandra Shysheya Samsung AI Center, Skolkovo Institute of Science and Technology , Egor Zakharov Samsung AI Center, Skolkovo Institute of Science and Technology , Kara Ali Aliev Samsung AI Center , Renat Bashirov Samsung AI Center , Egor Burkov Samsung AI Center, Skolkovo Institute of Science and Technology , Karim Iskakov Samsung AI Center , Aleksei Ivakhnenko Samsung AI Center , Yury Malkov Samsung AI Center , Igor Pasechnik Samsung AI Center , Dmitry Ulyanov Samsung AI Center, Skolkovo Institute of Science and Technology , Alexander Vakhitov Samsung AI Center, Skolkovo Institute of Science and Technology , Victor Lempitsky Samsung AI Center, Skolkovo Institute of Science and Technology 我们提出了一种用于学习全身神经化身的系统,即深度网络,其产生用于改变身体姿势和摄像机位置的人的全身渲染。我们的系统采用经典图形管道和最近的深度学习方法之间的中间路径,这些方法使用图像到图像转换生成人类图像。特别地,我们的系统估计模型表面的显式二维纹理图。同时,它避免了3D中的显式形状建模。相反,在测试时,系统使用完全卷积网络直接映射身体特征点的配置w.r.t.相机到图像帧中各个像素的2D纹理坐标。我们表明,这样的系统能够学习生成逼真的渲染,同时在用3D姿势和前景蒙版注释的视频上进行训练。我们还证明,与使用直接图像到图像转换的系统相比,维护显式纹理表示有助于我们的系统实现更好的泛化。 |
| Toward Learning a Unified Many-to-Many Mapping for Diverse Image Translation Authors Wenju Xu, Shawn Keshmiri, Guanghui Wang 图像到图像的翻译,通过学习的一对一映射将输入图像转换到不同的域,近年来取得了令人瞩目的成功。翻译的成功主要依靠网络架构来保留结构信息,同时通过对抗训练在像素级略微修改外观。虽然这些网络能够学习映射,但是翻译的图像是可预测的而不排除。更期望通过引入不确定性使用图像到图像转换来使它们多样化,即,除了与输入图像的一般相似性之外,所生成的图像保持颜色和纹理变化的可能性,并且这发生在目标域和源域中。 。为此,我们提出了一种新颖的基于生成对抗网络GAN的模型,注入导入,以学习多对多的映射。在该模型中,输入图像与潜在变量组合,潜在变量包括域特定属性和非特定随机变量。域特定属性指示翻译的目标域,而非特定随机变化将不确定性引入模型。提出了一个统一的框架来重新组合这两个部分,并在每个领域获得不同的世代。大量实验表明,对于具有挑战性的图像到图像转换任务而言,不同世代具有高质量,其中没有训练数据集的配对信息退出。定量和定性结果均证明了InjectionGAN优于现有技术方法的优越性能。 |
| RIU-Net: Embarrassingly simple semantic segmentation of 3D LiDAR point cloud Authors Pierre Biasutti, Aur lie Bugeau, Jean Fran ois Aujol, Mathieu Br dif 本文提出了RIU Net for Range Image U Net,一种流行的语义分割网络适用于3D LiDAR点云的语义分割。通过利用传感器的拓扑结构,将点云变成2D范围图像。然后将该图像用作U网的输入。这种架构已经证明了其对医学图像语义分割任务的效率。我们建议演示它如何也可以用于3D LiDAR点云的精确语义分割。我们的模型是根据KITTI 3D物体检测数据集构建的范围图像进行训练的。实验表明RIU Net尽管非常简单,但仍优于基于距离图像的方法。最后,我们证明了这种架构能够在单个GPU上以90fps运行,从而可以在机器人等低计算能力系统上进行部署。 |
| Task Decomposition and Synchronization for Semantic Biomedical Image Segmentation Authors Xuhua Ren, Lichi Zhang, Sahar Ahmad, Dong Nie, Fan Yang, Lei Xiang, Qian Wang, Dinggang Shen 语义分割对于生物医学图像分析非常重要。最近的许多工作主要集中在将完全卷积网络FCN架构与复杂的卷积实现和深度监督相结合。在本文中,我们建议将单个分割任务分解为三个后续子任务,包括1个像素的图像分割,2个图像内对象的类标签的预测,以及图像所属的场景的3个分类。虽然这三个子任务经过训练以优化其不同感知级别的个体丢失函数,但我们建议让它们通过任务任务上下文集合进行交互。此外,我们提出了一种新颖的同步正则化,以惩罚像素分段输出和类预测任务之间的偏差。这些有效的规则化有助于FCN全面地利用上下文信息并获得准确的语义分割,即使在许多生物医学应用中用于训练的图像的数量可能是有限的。我们已成功将我们的框架应用于三种不同的2D 3D医学图像数据集,包括机器人场景分割挑战18 ROBOT18,脑肿瘤分割挑战18 BRATS18和视网膜眼底青光眼挑战REFUGE18。我们在所有三个挑战中都取得了顶级绩效。 |
| Lightweight Network Architecture for Real-Time Action Recognition Authors Alexander Kozlov, Vadim Andronov, Yana Gritsenko 在这项工作中,我们提出了一种新的人类行为识别方法,称为视频变换器网络VTN。它利用计算机视觉和自然语言处理的最新进展,并将其应用于视频理解。所提出的方法允许我们创建轻量级CNN模型,仅使用RGB单色摄像机和通用CPU即可实现高精度和实时速度。此外,我们解释了如何通过从具有不同模态的多个模型中提取到单个模型中来提高准确性。我们与最先进的方法进行了比较,并表明我们的方法与着名的动作识别数据集中的大多数方法相当。我们使用现代推理框架对模型的推理时间进行基准测试,并认为我们的方法在速度准确性权衡方面与其他方法相比,在CPU上以56 FPS运行。模型和培训代码可用。 |
| GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature of Point Cloud Authors Can Chen, Luca Zanotti Fragonara, Antonios Tsourdos 由于其在非欧几里德空间中的不规则和稀疏结构,在点云上利用细粒度语义特征仍然具有挑战性。在现有的研究中,PointNet提供了一种有效且有前途的方法,可以直接在无序3D点云上学习形状特征,并且已经实现了竞争性能。但是,不考虑有助于更好的情境学习的局部特征。同时,注意机制通过参与相邻节点来显示在基于图的数据上捕获节点表示的效率。在本文中,我们提出了一种新的点云神经网络,称为GAPNet,通过在堆叠的多层感知器MLP层中嵌入图形注意机制来学习局部几何表示。首先,我们介绍一个GAPLayer,通过突出显示邻域的不同注意力来学习每个点的注意力特征。其次,为了利用足够的特征,采用多头机制以允许GAPLayer从独立头部聚合不同的特征。第三,我们提出了一个覆盖邻居的注意力集中层,以捕获旨在增强网络健壮性的本地签名。最后,GAPNet将堆叠的MLP层应用于注意特征和局部特征,以完全提取局部几何结构。建议的GAPNet架构在ModelNet40和ShapeNet零件数据集上进行测试,并在形状分类和零件分割任务中实现最先进的性能。 |
| RASNet: Segmentation for Tracking Surgical Instruments in Surgical Videos Using Refined Attention Segmentation Network Authors Zhen Liang Ni, Gui Bin Bian, Xiao Liang Xie, Zeng Guang Hou, Xiao Hu Zhou, Yan Jie Zhou 用于跟踪手术器械的分割在机器人辅助手术中起重要作用。手术器械的分割有助于捕获用于跟踪的准确空间信息。在本文中,提出了一种新颖的网络,精确注意力分割网络,以同时分割手术器械并识别其类别。使用在分割中流行的U形网络。与以往的工作不同,采用注意模块帮助网络关注关键区域,提高分割精度。为了解决类不平衡问题,将交叉熵损失和Jaccard指数的对数的加权和用作损失函数。此外,我们的网络采用转移学习。编码器在ImageNet上经过预先培训。来自MICCAI EndoVis Challenge 2017的数据集用于评估我们的网络。基于该数据集,我们的网络实现了最先进的性能94.65平均骰子和90.33平均IOU。 |
| Activity Recognition and Prediction in Real Homes Authors Flavia Dias Casagrande, Evi Zouganeli 在本文中,我们使用二进制传感器数据或深度视频数据介绍了在实际家庭中活动识别和预测的工作。我们提供现场试验并设置收集和存储数据,我们的方法和我们当前的结果。我们使用概率方法和长短期记忆LSTM网络比较预测下一个二进制传感器事件的准确性,包括提高预测准确性的时间信息,以及使用一个LSTM模型预测下一个传感器事件及其平均发生时间。我们调查公寓之间的转移学习,并表明可以使用其他公寓的数据预先培训模型,并在新公寓中立即获得良好的准确性。此外,我们使用来自七个公寓的低分辨率深度视频数据来展示活动识别的初步结果,并通过使用相对简单的处理方法对四个活动进行无运动,站立,坐下和电视交互的分类,其中我们应用无限脉冲响应IIR滤波器用于在将帧馈送到卷积LSTM网络之前从帧中提取运动以进行分类。 |
| Fonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification Authors Vinay Uday Prabhu, Sanghyun Han, Dian Ang Yap, Mihail Douhaniaris, Preethi Seshadri, John Whaley 在本文中,我们提出了种子增强训练转移SAT框架,其中包含使用可自由获得的开放字体文件数据集的具有不同数字系统的语言的合成种子图像数据集生成过程。然后增加图像的种子数据集以创建纯合成训练数据集,该数据集反过来用于训练深度神经网络并测试所持有的现实世界手写数字数据集,跨越五个印度语脚本,卡纳达语,泰米尔语,古吉拉特语,马拉雅拉姆语,和梵文我们通过训练寻找GAN BGAN的边界来定性地展示这种方法的功效,该边界寻求以五种语言生成逼真的数字图像,并且还通过测试在真实世界数据集上的合成数据上训练的CNN来定量地展示。这不仅建立了字体数据集世界和转移学习之间的有趣联系,而且还提供了在任何脚本中进行通用数字分类的方法。 |
| Variational Hetero-Encoder Randomized Generative Adversarial Networks for Joint Image-Text Modeling Authors Hao Zhang, Bo Chen, Long Tian, Zhengjue Wang, Mingyuan Zhou 对于双向联合图像文本建模,我们开发了变分异构编码器VHE随机生成对抗网络GAN,其将概率文本解码器,概率图像编码器和GAN集成到一致的端到端多模态学习框架中。 VHE随机化GAN VHE GAN对图像进行编码以解码其相关文本,并将变分后验作为随机源馈送到GAN图像生成器中。我们将三个现成的模块(包括深度主题模型,梯形结构图像编码器和StackGAN)插入到已经实现竞争性能的VHE GAN中。这进一步推动了VHE光栅扫描GAN的发展,该GAN不仅以多尺度低到高分辨率的方式生成照片真实图像,而且还生成分层语义粗到精细的时尚。通过捕获分层语义和视觉概念并将其与端到端训练相关联,VHE光栅扫描GAN在各种图像文本多模态学习和生成任务中实现了最先进的性能。提供PyTorch代码。 |
| Neurons Activation Visualization and Information Theoretic Analysis Authors Longwei Wang, Peijie Chen 了解深度神经网络的内部工作机制DNN对于研究人员设计和改善DNN的性能至关重要。在这项工作中,利用熵分析来研究完全连接的DNN层的神经元激活行为。每层的激活模式的熵可以提供用于评估网络模型准确度的性能度量。该研究基于训练有素的网络模型进行。通过输入单个类的图像来分析完全连接层的浅层和深层的激活模式。研究发现,对于训练有素的深度神经网络模型,神经元激活模式的熵随着层的深度单调减小。也就是说,随着完全连接层的深度,神经元激活模式变得越来越稳定。完全连接的层的熵模式还可以提供关于需要多少完全连接的层以保证模型的准确性的指导。这项研究为DNN的分析提供了新的视角,展示了一些有趣的结果。 |
| Automatic Long-Term Deception Detection in Group Interaction Videos Authors Chongyang Bai, Maksim Bolonkin, Judee Burgoon, Chao Chen, Norah Dunbar, Bharat Singh, V. S. Subrahmanian, Zhe Wu 大多数关于自动欺骗检测的工作ADD在视频中有两个限制,它侧重于一个人的视频,而它侧重于一个或两分钟视频中的单一欺骗行为。在本文中,我们提出了一个新的ADD框架,它在组环境中捕获长期欺骗。我们在着名的抵抗游戏中研究欺骗行为,如黑手党和狼人,其中包括5 8名玩家,其中2 3名是间谍。间谍通常在整个游戏中具有欺骗性,通常为30分钟,以保持身份隐藏。我们开发了一个集合预测模型来识别抵抗视频中的间谍。我们表明,低级别和高级别视频分析的功能不足,但结合我们称之为LiarRank的新功能,可以产生最佳效果。我们在全自动设置中实现超过0.70的AUC。我们的演示可以在 |
| VOICED: Depth Completion from Inertial Odometry and Vision Authors Alex Wong, Xiaohan Fei, Stefano Soatto 我们描述了一种使用视觉惯性测距系统估计相机运动和稀疏深度的密集深度的方法。与使用激光雷达或结构光传感器的点云的其他场景不同,我们有几百到几千点,不足以通知场景的拓扑。我们的方法首先构造场景的分段平面脚手架,然后使用它来使用图像以及稀疏点来推断密集深度。我们使用预测交叉模态标准,类似于自我监督,测量跨时间的光度一致性,向前后向姿势一致性以及与稀疏点云的几何兼容性。我们还推出了第一个视觉惯性深度数据集,我们希望这将进一步探索结合视觉和惯性传感器的互补优势。为了将我们的方法与先前的工作进行比较,我们采用无监督的KITTI深度完成基准,并在其上显示最先进的性能。 |
| ROI Regularization for Semi-supervised and Supervised Learning Authors Hiroshi Kaizuka, Yasuhiro Nagasaki, Ryo Sako 我们提出ROI正则化ROIreg作为图像分类的半监督学习方法。 ROIreg关注于在将未标记的数据样本x输入卷积神经网络CNN时获得的后验概率分布g x的最大概率。 ROIreg将x的像素集划分为多个块,并针对每个块评估其对最大概率的贡献。通过用随机图像替换具有相对小的贡献度的块来生成掩蔽数据样本x ROI。然后,ROIreg训练CNN,使得g x ROI不会从g x尽可能多地改变。因此,可以说ROIreg更加细化了CNN的分类能力。另一方面,Virtual Adverserial Training VAT是一种优秀的半监督学习方法,通过在g x变化最大的方向上扰动x来生成数据样本x VAT。然后,VAT训练CNN,使g x VAT尽可能不从g x变化。因此,增值税可以说是改善CNN弱点的一种方法。因此,ROIreg和VAT具有互补的培训效果。事实上,VAT和ROIreg的组合改善了单独使用VAT或ROIreg时获得的结果。这种组合还改善了有或没有数据增加的SVHN和没有数据增强的CIFAR 10的现有技术水平。我们还提出了一种称为ROI增强ROIaug的方法,作为将ROIreg应用于监督学习中的数据增强的方法。但是,那里使用的评估函数与标准交叉熵不同。 ROIaug提高了SVHN和CIFAR 10监督学习的性能。最后,当不属于分类的数据样本包含在未标记数据中时,我们调查VAT和VAT ROIreg的性能下降。 |
| War: Detecting adversarial examples by pre-processing input data Authors Hua Wang, Jie Wang, Zhaoxia Yin 深度神经网络DNN在图像分类和语音识别等许多领域都表现出了卓越的性能。然而,DNN图像分类器容易受到来自对抗性示例的干扰,这最终导致神经网络模型的错误分类输出。在此基础上,本文提出了一种基于War WebP压缩的方法,并通过调整大小来检测对抗实例。该方法以WebP压缩为核心,首先对输入图像执行WebP压缩,然后适当调整压缩图像的大小,使对抗示例的标签发生变化,从而检测对抗图像的存在。实验结果表明,与HGD方法相比,该方法能有效抵抗IFGSM,DeepFool和CW攻击,识别精度提高10以上,对抗实例的检测成功率比特征压缩高5倍。方法。本文方法可以有效地减少对抗图像中的小噪声干扰,并根据样本标记的变化准确地检测对抗实例,同时保证原始样本识别的准确性。 |
| Dilated Spatial Generative Adversarial Networks for Ergodic Image Generation Authors Cyprien Ruffino LITIS, INSA Rouen Normandie, NU , Romain H rault DocApp LITIS , Eric Laloy SCK CEN , Gilles Gasso LITIS 最近,由于对抗性学习,生成模型得到了新的关注。生成对抗网络由样本生成模型和能够区分真实样本和合成样本的辨别模型组成。结合用于鉴别器的卷积和用于生成器层的de卷积,它们特别适合于图像生成,尤其是自然场景的图像生成。但是,完全连接的层的存在会在生成的图像中添加全局依赖性。对于输入噪声的小局部变化,这可能导致所生成的样本的高度和全局变化。在这项工作中,我们建议使用基于完全卷积网络的架构,包括扩展层,专门设计用于生成全局遍历图像的架构,即没有全局依赖性的图像。进行的实验表明,这些架构非常适合生成自然纹理,如地质结构。 |
| Vehicle Shape and Color Classification Using Convolutional Neural Network Authors Mohamed Nafzi, Michael Brauckmann, Tobias Glasmachers 本文提出了一种基于制作模型和颜色分类的车辆重新识别模块。它可以被自动车辆监视AVS或视频数据的快速分析使用。必须解决与该主题相关的许多问题。为了促进和加快这一主题的进展,我们将提出收集和标记大规模数据集的方法。我们在训练中使用了更深入的神经网络。他们表现出良好的分类准确性。我们在受控和视频数据集上显示制作模型和颜色分类的结果。我们借助于开发的应用程序演示了基于制作模型和颜色分类的视频图像上的车辆识别。这项工作部分由赠款资助。 |
| Machine learning approach for segmenting glands in colon histology images using local intensity and texture features Authors Rupali Khatun, Soumick Chatterjee 结肠癌是最常见的癌症类型之一。该治疗计划取决于癌症的等级或阶段。结肠癌分级的前提条件之一是分割组织的腺体结构。手动分割方法非常耗时,并且会给患者带来生命危险。该项目的主要目标是帮助病理学家准确检测结肠癌。在本文中,作者提出了一种使用局部强度和纹理特征在结肠组织学中自动分割腺体的算法。在这里,数据集图像被裁剪成具有不同窗口大小的补丁并且获取这些补丁的强度,并且还计算基于纹理的特征。随机森林分类器已被用于将此补丁分类为不同的标签。提出了一种分层方式的多级随机森林技术。该解决方案快速,准确,并且非常适用于临床设置。 |
| Skin Cancer Recognition using Deep Residual Network Authors Brij Rokad, Dr. Sureshkumar Nagarajan 技术的进步使人们能够从世界各地访问互联网。但到目前为止,偏远地区的医疗保健服务很少。该提议的解决方案旨在弥合专科医生和患者之间的差距。该原型将能够从手机或任何其他相机捕获的图像中检测皮肤癌。网络部署在云服务器端处理上,以获得更准确的结果。 Deep Residual学习模型已被用于预测服务器端的癌症概率.ResNet有三个参数层。每一层都有卷积神经网络,批量标准化,Maxpool和ReLU。目前,该模型在ISIC 2017挑战中达到了77的准确度。 |
| Improving Head Pose Estimation with a Combined Loss and Bounding Box Margin Adjustment Authors Mingzhen Shao, Zhun Sun, Mete Ozay, Takayuki Okatani 我们解决了从RGB图像估计人头部姿势的问题。有线电视新闻网的使用有助于显着提高近期作品的准确性。然而,我们表明,以下两种方法尽管简单,但可以通过适当调整检测到的面部的边界框边缘来进一步改进,以及ii选择损失函数。我们表明,这两种方法的集成在标准基准数据集中实现了野外头部姿态估计的新技术水平。 |
| 3D Dense Separated Convolution Module for Volumetric Image Analysis Authors Lei Qu, Changfeng Wu, Liang Zou 随着深度学习的蓬勃发展,3D卷积神经网络因其令人印象深刻的3D上下文挖掘能力而成为体积图像分析中的流行选择。然而,3D卷积核将引入可训练参数量的显着增加。考虑到训练数据通常在生物医学任务中受到限制,必须在模型大小和其代表性能力之间进行权衡。为了解决这个问题,在本文中,我们提出了一种新颖的3D密集分离卷积3D DSC模块来取代原始的3D卷积核。 3D DSC模块由一系列密集连接的1D滤波器构成。将3D内核分解为1D滤波器通过以拓扑约束的方式去除3D内核的冗余来降低过度拟合的风险,同时提供用于深化网络的基础设施。通过在一维滤波器之间进一步引入非线性层和密集连接,可以在保持紧凑架构的同时显着改善网络的代表性功率。我们展示了3D DSC在体积图像分类和分割方面的优越性,这是生物医学图像计算中经常遇到的两个具有挑战性的任务。 |
| TopoResNet: A hybrid deep learning architecture and its application to skin lesion classification Authors Yu Min Chung, Chuan Shen Hu, Austin Lawson, Clifford Smyth 皮肤癌是美国最常见的癌症之一。随着技术的进步,皮肤病变的算法诊断变得越来越重要。在本文中,我们开发了用于在给定的皮肤病变图像中分割皮肤的实际患病区域的算法,以及用于对给定图像中描绘的不同类型的皮肤病变进行分类的算法。所使用的算法的核心基于持久同源性,代数拓扑技术是拓扑数据分析TDA的上升领域的一部分。分割算法利用与持久同源性相似的概念来捕获分割区域的稳健性。对于分类,我们从持久性图设计两个拓扑特征族,我们称之为em持久性统计PS和em持久性曲线PC,并使用线性支持向量机作为分类器。我们还将这些拓扑特征PS和PC组合到ResNet 101模型中,我们将其称为Top TopResNet 101,结果表明PS和PC在两次折叠中有效,提高了分类性能并稳定了训练过程。虽然卷积特征是CNN模型中最重要的学习目标,但是图像的全局信息可能在训练过程中丢失。由于拓扑特征是全局提取的,因此我们的结果表明拓扑特征的全局属性为机器学习模型提供了额外的信息。 |
| VGG Fine-tuning for Cooking State Recognition Authors Juan Wilches 家用机器人需要实现的一项重要任务是识别食品成分的状态,以便他们可以继续烹饪。该项目重点关注用于物体识别的深度卷积神经网络CNN的VGG视觉几何组架构的微调算法。该算法旨在识别图像数据集的十一种不同成分烹饪状态。对原始VGG模型进行了调整和培训,以对食物状态进行适当分类。该模型使用Imagenet权重进行初始化。进行不同的实验以找到提供最佳性能的模型参数。在更改VGG模型的几个参数后,验证集的准确度为76.7,测试集76.6。 |
| SharpNet: Fast and Accurate Recovery of Occluding Contours in Monocular Depth Estimation Authors Micha l Ramamonjisoa, Vincent Lepetit 我们介绍SharpNet,一种预测输入彩色图像的精确深度图的方法,特别注意遮挡轮廓的重建。遮挡轮廓是对象识别的重要提示,以及虚拟对象在增强现实中的真实集成,但是众所周知,它们也难以准确地重建。例如,它们是基于立体的重建方法的挑战,因为遮挡轮廓周围的点仅在一个图像中可见。受最近引入正常估计以改进深度预测的方法的启发,我们引入了一个新术语,它约束深度和遮挡轮廓预测。由于沿着遮挡轮廓的像素完美精度很难获得地面实况深度,我们使用合成图像进行训练,然后对实际数据进行微调。我们在具有挑战性的NYUv2深度数据集上展示了我们的方法,并证明我们的方法在遮挡轮廓方面优于现有技术,同时与其他图像的最佳方法相当。沿着遮挡轮廓的精度实际上优于基于结构光的深度相机获得的地面实况。我们通过引入基于NYUv2 Depth的新基准来评估单眼重建中的遮挡轮廓,这是我们的第二个贡献。 |
| Marginalized Average Attentional Network for Weakly-Supervised Learning Authors Yuan Yuan, Yueming Lyu, Xi Shen, Ivor W. Tsang, Dit Yan Yeung 在弱监督时间动作定位中,由于对最显着区域的过高估计,以前的工作未能为每个整个动作定位密集和整体区域。为了缓解这个问题,我们提出了边缘化的平均注意网络MAAN,以原则方式抑制最显着区域的主导响应。 MAAN采用新颖的边缘化平均聚合MAA模块,并以端到端的方式学习一组潜在的判别概率。 MAA根据一组潜在的判别概率从视频片段特征中采样多个子集,并对所有平均子集特征进行预期。从理论上讲,我们证明具有学习潜在判别概率的MAA模块成功地减少了最显着区域与其他区域之间响应的差异。因此,MAAN能够生成更好的类激活序列并识别视频中的密集和整体动作区域。此外,我们提出了一种快速算法,以降低从O 2 T到O T 2构建MAA的复杂性。对两个大型视频数据集的大量实验表明,我们的MAAN在弱监督时间动作定位上实现了卓越的性能 |
| Online Signature Verification Based on Writer Specific Feature Selection and Fuzzy Similarity Measure Authors Chandra Sekhar V, Prerana Mukherjee, D.S. Guru, Viswanath Pulabaigari 在线签名验证OSV是一种广泛使用的生物识别属性,用于数字取证中的用户行为特征验证。在本文中,由于个体内部变异性较大,提出了一种基于区间符号表示的OSV新方法和基于作者特定参数选择的模糊相似性度量。基于使用训练签名样本在参数固定阶段期间获得的最小等错误率EER来选择两个参数,即写入者特定接受阈值和用于验证写入者的最佳特征集。这与OSV的当前技术不同,OSV主要是与编写者无关的,其中选择了一组共同的特征和接受阈值。为了证明我们系统的稳健性,我们用四个标准数据集详尽评估了我们的系统,即MCYT 100 DB1,MCYT 330 DB2,SUSIG Visual corpus和SVC 2004 Task2。实验结果证实了与许多最近和现有技术的OSV模型相比,通过实现更低的错误率,基于模糊相似性度量的写入者依赖参数选择对OSV的有效性。 |
| Contrast Enhancement of Medical X-Ray Image Using Morphological Operators with Optimal Structuring Element Authors Rafsanjany Kushol, Md. Nishat Raihan, Md Sirajus Salekin, A. B. M. Ashikur Rahman 为了指导手术和医疗,X射线图像已经被每个现代医疗保健组织和医院的医生使用。借助于X射线成像技术,医生在骨骼系统领域的评估过程和疾病识别可以更快更有效地进行,因为它们可以无痛地描绘骨骼结构。本文提出了一种使用形态学算子的有效对比度增强技术,这将有助于更清晰地显示重要的骨段和软组织。利用大礼帽和底帽变换来增强图像,其中计算梯度大小值以自动选择结构化元素SE大小。对不同X射线成像数据库的实验评估显示了我们的方法的有效性,该方法对于一些现有的图像增强技术也产生相对更好的输出。 |
| Mesh-based Camera Pairs Selection and Occlusion-Aware Masking for Mesh Refinement Authors Andrea Romanoni, Matteo Matteucci 在将深度图融合到空间的体积表示中之后,许多多视图立体算法提取场景的3D网格模型。由于这种表示的可扩展性有限,估计的模型不能捕获场景的精细细节。因此,通常应用网格细化算法,其通过将3D模型引起的光度误差最小化为成对的相机来提高网格分辨率和精度。这些对的选择显着影响细化的质量,并且通常依赖于属于表面的稀疏3D点。相反,在本文中,为了提高对选择的质量,我们在细化之前利用3D模型来计算五个度量场景覆盖,相互图像重叠,图像分辨率,相机视差和新的对称项。为了提高细化鲁棒性,我们还提出了一种管理遮挡的显式方法,这可能会对光度误差的计算产生负面影响。所提出的方法在计算相似性度量及其梯度时考虑模型的深度。我们在公开可用的数据集上定量和定性地验证了我们针对最新重建方法的方法。 |
| PDH : Probabilistic deep hashing based on MAP estimation of Hamming distance Authors Yosuke Kaga, Masakazu Fujio, Kenta Takahashi, Tetsushi Ohki, Masakatsu Nishigaki 随着网络上图像的增长,已经积极地研究了能够实现高速图像检索的哈希。近年来,已经提出了基于深度神经网络的各种散列方法,并且实现了比其他散列方法更高的精度。在这些方法中,定义了哈希码的多个损失和神经网络的参数。它们生成哈希码,以最小化损失的加权和。因此,专家必须启发式地调整损失的权重,并且不能解释损失函数的概率最优性。为了在没有权重调整的情况下生成可解释的哈希码,我们理论上从图像的概率分布导出单个损失函数,其中没有用于哈希码的超参数。通过生成最小化该损失函数的哈希码,执行具有概率最优性的高度准确的图像检索。我们使用MNIST,CIFAR 10,SVHN评估散列的性能,并表明所提出的方法优于现有技术的散列方法。 |
| S-Flow GAN Authors Yakov Miron, Yona Coscas 这项工作提供了一种从语义标签贴图和模拟器边缘地图图像生成照片真实图像的新方法。我们以条件方式进行,我们训练生成对抗性网络GAN给定图像及其语义标签图以输出该场景的照片真实版本。 GAN的现有架构仍然缺乏照片真实性功能。我们通过嵌入边缘图来解决这个问题,并将生成器与边缘图图像作为先验图像呈现,这样可以在图像中生成高级细节。我们提供了一个模型,当给出一系列图像时,使用此生成器创建视觉上吸引人的视频。 |
| A novel algorithm for segmentation of leukocytes in peripheral blood Authors Haichao Cao, Hong Liu, Enmin Song 在检测贫血,白血病和其他血液疾病时,白细胞的数量和类型是必不可少的评估参数。然而,传统的白细胞计数方法不仅耗时而且容易出错。因此,引入了许多自动化方法来诊断医学图像。在背景,染色方法,染色程度,光照条件等可变条件下准确提取相关特征并计数细胞数仍然是困难的。因此,为了适应各种复杂情况,我们考虑RGB颜色空间,HSI颜色空间以及G,H和S成分的线性组合,并提出一种快速准确的外周血白细胞分割算法。 。首先,使用逐步平均法分离白细胞核。然后基于区间值模糊集,通过最小化模糊发散来分割白细胞的细胞质。接下来,使用凹凸迭代修复算法和候选掩模集的决策机制进行后处理。实验结果表明,该方法优于现有的非模糊集方法。在基于模糊集的方法中,区间值模糊集的表现略好于区间值直觉模糊集和直觉模糊集。 |
| Dual-branch residual network for lung nodule segmentation Authors Haichao Cao, Hong Liu, Enmin Song, Chih Cheng Hung, Guangzhi Ma, Xiangyang Xu, Renchao Jin, Jianguo Lu 计算机断层扫描CT图像中肺结节的准确分割对于肺癌分析和诊断至关重要。然而,由于肺结节的多样性以及结节与其周围环境之间视觉特征的相似性,结节的稳健分割成为一个具有挑战性的问题。在本研究中,我们提出了双分支残余网络数据库ResNet,它是一种数据驱动模型。我们的方法集成了两种新的方案来提高模型的泛化能力1所提出的模型可以同时捕获CT图像中不同结节的多视图和多尺度特征2我们结合了强度和卷积神经网络CNN的特征。我们提出了一种称为中心强度合并层CIP的合并方法,以提取该块的中心体素的强度特征,然后使用CNN来获得该块的中心体素的卷积特征。此外,我们设计了一个基于结节边界的加权采样策略,用于使用加权分数选择这些体素,以提高模型的准确性。所提出的方法已经在包含986个结节的LIDC数据集上进行了广泛的评估。实验结果表明,DB ResNet在数据集上实现了优异的分割性能,平均骰子得分为82.74。此外,我们将结果与同一数据集上的四位放射科医师的结果进行了比较。比较显示,我们的平均骰子评分比人类专家高0.49。这证明我们提出的方法与经验丰富的放射科医师一样好。 |
| Convolutions on Spherical Images Authors Marc Eder, Jan Michael Frahm 将卷积神经网络应用于球形图像需要特别考虑。我们期待数千年的制图地图投影工作,以提供工具来定义卷积运算的球形图像的最佳表示。我们提出了一种基于二十面体Snyder等面积ISEA投影的深球形图像推理的表示,一种投影到测地网格,并表明它大大超过了球形图像卷积的现有技术水平,将语义分割结果提高了12.6。 |
| A Bi-Directional Co-Design Approach to Enable Deep Learning on IoT Devices Authors Xiaofan Zhang, Cong Hao, Yuhong Li, Yao Chen, Jinjun Xiong, Wen mei Hwu, Deming Chen 为资源有限的物联网物联网设备开发深度学习模型具有挑战性,因为很难同时获得高质量的结果QoR,例如DNN模型推理准确性,以及服务质量QoS,例如推理延迟,吞吐量和功率消费。现有方法通常将DNN模型开发步骤与其在IoT设备上的部署分开,从而导致不理想的解决方案。在本文中,我们首先介绍了一些关于这种单独设计方法的有趣但反直觉的观察,并且凭经验证明了为什么它可能导致次优设计。在这些观察的启发下,我们提出了一种新颖实用的双向协同设计方法,即自下而上的DNN模型设计策略以及DNN加速器设计的自上而下流程。它可以在物联网设备上联合优化DNN模型及其部署配置,如FPGA所示。我们使用Pynq Z1嵌入式FPGA证明了所提出的协同设计方法在现实生活对象检测应用中的有效性。我们的方法获得了具有高精度IoU的QoR和具有高吞吐量FPS和高能效的QoS的现有技术结果。 |
| Improved Optical Flow for Gesture-based Human-robot Interaction Authors Jen Yen Chang, Antonio Tejero de Pablos, Tatsuya Harada 手势交互是与机器人通信的自然方式,可以替代语音。手势识别方法利用光流来理解人体运动。然而,虽然准确的光流估计,即传统方法在运行时方面是昂贵的,但是快速估计即深度学习方法的准确性可以得到改善。在本文中,我们提出了一种基于手势的人体机器人交互的管道,它使用一种新颖的光流估计方法,以实现提高的速度准确性权衡。我们的光流估计方法对先前基于深度学习的方法引入了四项改进,强大的特征提取器,对轮廓的关注,中途特征以及这三者的组合。这样可以更好地理解运动,并更精细地表现轮廓。为了评估我们的管道,我们生成了我们自己的数据集MIBURI,其中包含用于命令家庭服务机器人的手势。在我们的实验中,我们展示了我们的方法不仅可以改善光流估计,还可以改善手势识别,为实际的机器人应用提供更加真实的速度精度折衷。 |
| A Two-stage Classification Method for High-dimensional Data and Point Clouds Authors Xiaohao Cai, Raymond Chan, Xiaoyu Xie, Tieyong Zeng 高维数据分类是机器学习和成像科学的基本任务。在本文中,我们提出了一种两阶段多相半监督分类方法,用于分类高维数据和非结构化点云。首先,使用诸如标准支持向量机之类的模糊分类方法来生成热初始化。然后,我们应用一个名为SaT平滑和阈值的两阶段方法来改进分类。在第一阶段,实现无约束凸变分模型以净化和平滑初始化,接着是第二阶段,即将在阶段1获得的平滑分区投影到二进制分区。这两个阶段可以重复,最新结果作为新的初始化,以不断提高分类质量。我们证明了平滑阶段的凸模型具有独特的解决方案,可以通过专门设计的原始对偶算法求解,其收敛性得到保证。我们测试我们的方法并将其与几个基准数据集上的最新方法进行比较。实验结果清楚地表明,我们的方法在高维数据和点云的分类精度和计算速度方面都是优越的。 |
| Neighborhood Enlargement in Graph Neural Networks Authors Xinhan Di, Pengqian Yu, Mingchao Sun, Rui Bu 图神经网络GNN是用于图结构数据的表示学习和预测的有效框架。在GNN和变体的训练中应用邻域聚合方案,通过递归地聚合和变换相邻节点的表示来计算每个节点的表示。构建了各种GNNS和变体,并在节点和图形分类任务上实现了最先进的结果。然而,尽管在现有技术GNN模型中使用了共同邻域,但是对邻域聚合方案中邻域的属性几乎没有分析。在这里,我们分析图模型的节点,边和邻域的属性。我们的结果表征了现有技术GNN中使用的公共邻域的效率,并表明它对于节点的表示学习是不够的。我们提出一个简单的社区,可能更充足。我们在经验上验证了我们对许多图表分类基准的理论分析,并证明我们的方法在列出的基准上实现了最先进的性能。 url提供了实现代码 |
| Clustering with Similarity Preserving Authors Zhao Kang, Honghui Xu, Boyu Wang, Hongyuan Zhu, Zenglin Xu 基于图形的聚类在许多任务中表现出了很好的性能。基于图的方法的关键步骤是相似性图构造。通常,由于非线性的结合,核空间中的学习图可以增强聚类精度。然而,大多数现有的基于内核的图学习机制不是保持相似性,因此导致次优性能。为了克服这个缺点,我们提出了一种更具辨别力的图学习方法,它可以首次以自适应方式保持样本之间的成对相似性。具体而言,我们要求学习的图形接近核矩阵,其用作原始数据中的相似性的度量。此外,该结构被自适应地调整,使得图的连通分量的数量恰好等于簇的数量。最后,我们的方法统一了聚类和图形学习,它可以直接从图形本身获得聚类指标,而无需执行进一步的聚类步骤。在几个数据集中的单核和多核学习场景中检查了该方法的有效性。 |
| Multitask Learning of Temporal Connectionism in Convolutional Networks using a Joint Distribution Loss Function to Simultaneously Identify Tools and Phase in Surgical Videos Authors Shanka Subhra Mondal, Rachana Sathish, Debdoot Sheet 手术工作流程分析对于了解手术阶段的开始和持续以及跨手术和每个阶段的个体工具使用具有重要意义。它有利于临床质量控制和医院管理员了解手术计划。手术期间获得的视频通常可以用于此任务。目前,卷积神经网络CNN和递归神经网络RNN的组合通常被广泛用于视频分析,不仅限于手术视频。在本文中,我们提出了一个多任务学习框架,使用CNN,然后是双向长短期记忆Bi LSTM,以学习封装前向和后向时间依赖性。此外,指示与阶段相关联的工具集的联合分布被用作在学习期间的额外损失,以在任何预测中校正它们的共同发生。使用Cholec80数据集进行实验评估。我们报告工具和相位识别的平均精度mAP分数分别为0.99和0.86,与现场技术相比更高。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com