基于LSTM的中文文本多分类实战(详细注释)
使用深度学习中的LSTM(Long Short-Term Memory)长短期记忆网络,来尝试一下中文文本多分类,LSTM它是一种时间循环神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
数据集
ChineseNlpCorpus的online_shopping_10_cats
10 个类别,共 6 万多条评论数据,正、负向评论各约 3 万条,包括书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店
代码
本人没有怎么使用过pandas,注释可能会比较啰嗦
查看数据
import pandas as pd
df = pd.read_csv('文件路径')#将逗号分隔值(csv)文件读取到DataFrame中
df=df[['cat','review']] #id为该评论所属类别 review为评论具体内容
print("数据总量: %d ." % len(df))
df.sample(10)#对数据集进行抽样查看

查看并清洗空值
print("在 cat 列中总共有 %d 个空值." % df['cat'].isnull().sum())#查看cat列的空值
print("在 review 列中总共有 %d 个空值." % df['review'].isnull().sum())
df[df.isnull().values==True]#isnull返回一个布尔数组
df = df[pd.notnull(df['review'])]#保留非null的review
查看数据分布
前言:DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。类似于matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matlab也可以用cell存放多类型数据),DataFrame的单元格可以存放数值、字符串等,这和excel表很像。同时DataFrame可以设置列名columns与行名index,可以通过像matlab一样通过位置获取数据也可以通过列名和行名定位
d = {
'cat':df['cat'].value_counts().index, 'count': df['cat'].value_counts()}#使用字典方法创建dataframe
df_cat = pd.DataFrame(data=d).reset_index(drop=True)#数据清洗时,会将带空值的行删除,此时DataFrame或Series类型的数据不再是连续的索引,可以使用reset_index()重置索引。
df_cat#查看重建完的dataframe

数据预处理
将cat类转换成id,这样便于以后的分类模型的训练。
factorize函数可以将Series中的标称型数据映射称为一组数字,相同的标称型映射为相同的数字。factorize函数的返回值是一个tuple(元组),元组中包含两个元素。第一个元素是一个array,其中的元素是标称型元素映射为的数字;第二个元素是Index类型,其中的元素是所有标称型元素,没有重复。
df['cat_id'] = df['cat'].factorize()[0]
cat_id_df = df[['cat', 'cat_id']].drop_duplicates().sort_values('cat_id').reset_index(drop=True)
cat_to_id = dict(cat_id_df.values)
id_to_cat = dict(cat_id_df[['cat_id', 'cat']].values)
df.sample(10)
 进行去符号以及去停用词操作
进行去符号以及去停用词操作
中文停用词txt文件下载
import re
import jieba as jb
def remove_punctuation(line):#使用正则表达式来过滤各种标点符号
line = str(line)
if line.strip()=='':
return ''
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")
line = rule.sub('',line)
return line
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
stopwords = stopwordslist("停用词txt文件路径")
df['clean_review'] = df['review'].apply(remove_punctuation)
#df是pandas的series的数据结构,
df['cut_review'] = df['clean_review'].apply(lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stopwords]))
df.head()
 LSTM建模
LSTM建模
- 我们要将cut_review数据进行向量化处理,我们要将每条cut_review转换成一个整数序列的向量
- 设置最频繁使用的50000个词
- 设置每条 cut_review最大的词语数为250个(超过的将会被截去,不足的将会被补0)
注:计算机在处理语言文字时,是无法理解文字的含义,通常会把一个词(中文单个字或者词组认为是一个词)转化为一个正整数,于是一个文本就变成了一个序列。而tokenizer的核心任务就是做这个事情。
import tokenizer
from keras.preprocessing.text import Tokenizer
# 设置最频繁使用的50000个词
MAX_NB_WORDS = 50000
# 每条cut_review最大的长度
MAX_SEQUENCE_LENGTH = 250
# 设置Embeddingceng层的维度
EMBEDDING_DIM = 100
#num_words: 保留的最大词数,根据词频计算,保留前num_word - 1个
tokenizer = Tokenizer(num_words=MAX_NB_WORDS, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~', lower=True)
#fit_on_texts(用以训练的已分过词的文本列表)
tokenizer.fit_on_texts(df['cut_review'].values)
word_index = tokenizer.word_index
print('共有 %s 个不相同的词语.' % len(word_index)

from keras.preprocessing.sequence import pad_sequences
X = tokenizer.texts_to_sequences(df['cut_review'].values)
#经过上一步操作后,X为整数构成的两层嵌套list
X = pad_sequences(X, maxlen=MAX_SEQUENCE_LENGTH)
#经过上步操作后,此时X变成了numpy.ndarray
#多类标签的onehot展开
Y = pd.get_dummies(df['cat_id']).values
print(X.shape)
print(Y.shape)

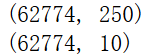
准备训练集和测试集
from sklearn.model_selection import train_test_split
#拆分训练集和测试集,X为被划分样本的特征集,Y为被划分样本的标签
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.10, random_state = 42)
print(X_train.shape,Y_train.shape)
print(X_test.shape,Y_test.shape)

定义一个LSTM的序列模型
前言:
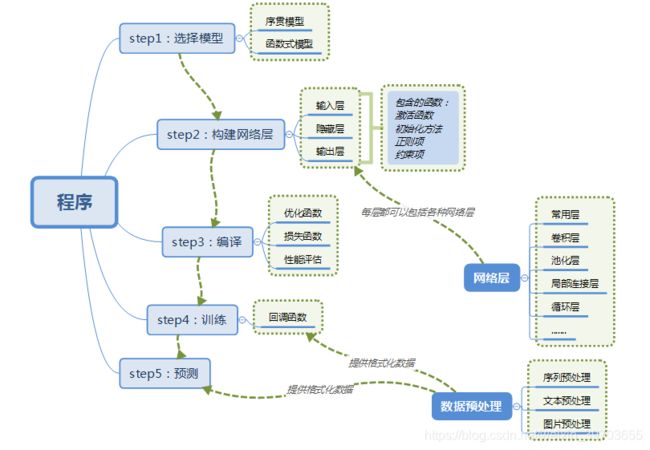 以上是Keras搭建神经网络的流程图
以上是Keras搭建神经网络的流程图
- 序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
- 模型的第一次是嵌入层(Embedding),它使用长度为100的向量来表示每一个词语
- SpatialDropout1D层在训练中每次更新时, 将输入单元的按比率随机设置为 0.2, 这有助于防止过拟合
- LSTM层包含100个记忆单元 输出层为包含10个分类的全连接层
- 由于是多分类,所以激活函数设置为’softmax’
- 由于是多分类, 所以损失函数为分类交叉熵categorical_crossentropy
model = Sequential()
model.add(Embedding(MAX_NB_WORDS, EMBEDDING_DIM, input_length=X.shape[1]))
model.add(SpatialDropout1D(0.2))#dropout会随机独立地将部分元素置零,而SpatialDropout1D会随机地对某个特定的纬度全部置零
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(10, activation='softmax'))#输出层包含10个分类的全连接层,激活函数设置为softmax
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
定义好LSTM模型以后,我们要开始训练数据:
-
设置5个训练周期
-
batch_size为64
from keras.callbacks import EarlyStopping
epochs = 5
batch_size = 64 #指定梯度下降时每个batch包含的样本数
#callbacks(list),其中元素是keras.callbacks.Callback的对象。这个list的回调函数将在训练过程中的适当时机被调用
#validation_split指定训练集中百分之十的数据作为验证集
history = model.fit(X_train, Y_train, epochs=epochs, batch_size=batch_size,validation_split=0.1,
callbacks=[EarlyStopping(monitor='val_loss', patience=3, min_delta=0.0001)])

import matplotlib.pyplot as plt
plt.title('Loss')
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
 训练集上的loss越来越小,且测试集上的loss基本保持在一个稳定的范围。模型大概率陷入过拟合
训练集上的loss越来越小,且测试集上的loss基本保持在一个稳定的范围。模型大概率陷入过拟合
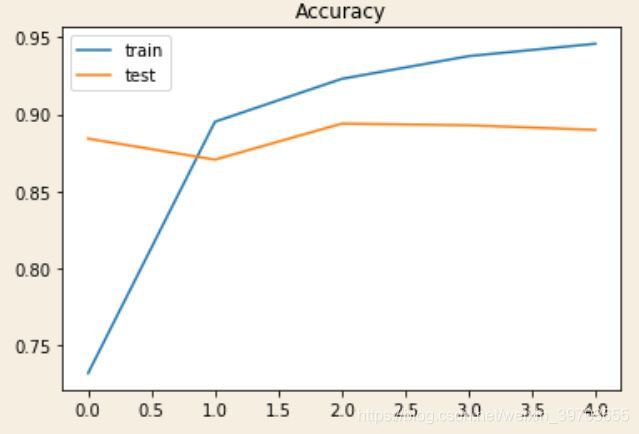
plt.title('Accuracy')
plt.plot(history.history['accuracy'], label='train')
plt.plot(history.history['val_accuracy'], label='test')
plt.legend()
plt.show()