论文解析:Membership Inference Attacks Against Machine Learning Models(一看即懂)
论文解析:Membership Inference Attacks Against Machine Learning Models(一看即懂,超详细版本)
摘要:这篇文章致力于探索机器学习模型如何泄露训练集中的信息,专注于基本的成员推理攻击,即给出一个机器学习模型和一条记录,判断该样本是否被用作训练集中的一部分。
我们对“机器学习即服务(machine learning as a service)”提供商(如Google和Amazon)训练的分类模型进行了经验评估。利用真实的数据集和分类任务,包括从隐私角度看其成员关系敏感的医院出院数据集,我们表明这些模型可能容易受到成员推断攻击。然后我们调查影响这种泄漏的因素并评估缓解策略。
主要问题
我们研究这个问题在最困难的设定条件下,即竞争者对于模型的查询仅限于给出input,返回模型的output(黑盒子问题),在训练集和模型结构位置的情况下,我们面临的最大问题就是如何训练attacker模型,因此本论文提出了影子模型,通过影子模型对attacker进行训练。
由于初次阅读本论文可能会对影子模型的作用产生疑惑,所以小编先将论文的整体训练思路和实验过程进行总结,方便理解。
论文思路总结
1.通过构造的训练数据训练影子模型(和目标模型类似的功能)(针对目标模型的每一类标签构造一个影子模型,影子模型越多,attacker越准确)
2.再通过attacker对影子模型进行infer来训练attacker(区分影子模型的输出是否在影子模型的数据集之中)
3.最后再用attacker来infer目标模型(区分目标模型的输出是否在目标模型的训练集之中)
论文实验过程简单流程图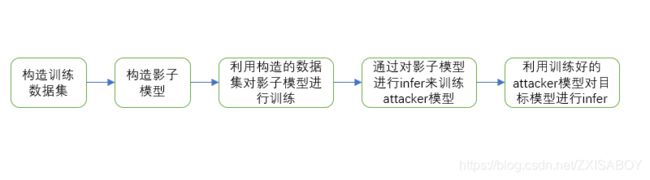
成员推理攻击

**推理依据:**机器学习模型在训练的数据上的行为与它们第一次“看到”的数据的行为不同。
黑盒设置中的成员推断攻击。攻击者使用数据记录查询目标模型,并获得模型对该记录的预测。预测是记录属于某个类的概率向量,每个类一个。这个预测向量和目标记录的标签一起传递给攻击模型,由攻击模型推断记录是否在目标模型的训练数据集中。
为影子模型生成训练数据集
为了训练影子模型,攻击者需要类似于目标模型训练数据的训练数据。我们开发了几种生成此类数据的方法。
1.Model-based synthesis
**基本思想:**直觉上,由目标模型以高置信度分类的记录应该在统计上与目标的训练数据集相似,从而为影子模型提供良好的素材。
合成过程分为两个阶段:(1)使用爬山算法搜索可能的数据记录空间,以高置信度找到目标模型分类的输入;(2)从这些记录中提取合成数据。在这个过程合成记录之后,攻击者可以重复它,直到影子模型的训练数据集已满。

2.Statistics-based synthesis
攻击者可能有一些关于从中提取目标模型训练数据的总体的统计信息。例如,攻击可以预先知道不同特征的边缘分布。在我们的实验中,我们通过独立地从每个特征的边缘分布中取样来生成影子模型的合成训练记录。由此产生的攻击模型非常有效。
3.Noisy real data
攻击者可以访问一些与目标模型的训练数据相似的数据,可以将其视为“噪声”版本。在我们对位置数据集的实验中,我们通过翻转10%或20%随机选择特征的值来模拟这一点,然后在产生的噪声数据集上训练影子模型。这种情况下,目标和影子模型的训练数据不是从完全相同的总体中采样,或者以不同的方式取样。
影子模型的训练
**基本思想:**影子训练技术背后的主要思想是使用相同的服务在相对相似的数据记录上训练的相似模型的行为方式相似。
.
每一类样本构造一个影子模型,影子模型越多,训练出来的attacker模型越准确
attacker模型的训练

实验的关键在于如何进行attacker的训练,因此本论文提出了影子模型技术,影子模型与目标模型具有相似的性质,通过构造的数据集对影子模型进行训练,然后利用训练好的影子模型对attacker模型进行训练。(具体流程如上图)
实验部分
训练集
CIFAR: CIFAR-10和CIFAR-100是用于评估图像识别算法的基准数据集。CIFAR-10:32x32的彩色图像,10个类别,每类6000张图,总共50000张训练图片和10000张测试图片。CIFAR-100有100个类别,每类600张图,其中500训练,100测试。本文实验中,对CIFAR-10,训练集大小分别设置为2500,5000,10000和15000;CIFAR-100则是4600,10520,19920和29540。
Purchases: Kaggle提供的数千人的shopping历史数据,每一个用户的记录包括其一年内的交易记录,包括产品名、店铺、数量和日期。本文采用了简化版本:197324条数据,每一条由600个二进制位构成,每一位表示是否购买了某一产品。将这些数据聚成多个类别,每一类表示一种购物风格。本文实验中的任务是给定一个600位的向量,判断其购物类别。实验中,类别总数分别设置为2,10,20,50,100。每次实验随机选择10000条数据作为目标模型的训练数据,其余的作为其测试数据和影子模型的训练数据。
Locations: 四方的check-in数据。包含11592个用户和119744个位置,共1136481条签到数据。经过处理后每条记录由446个二进制位组成。将所有数据聚类成30个类,实验中任务是给定向量,判断其所属类别。 随机选择了1600条数据作为目标模型的训练数据,其余的作为其测试数据和影子模型的训练数据。
**Texas hospital stays:**每条记录包含4组主要属性,包括受伤原因,诊断结果,治疗程序,和一些基因信息。
实验使用的数据包括67330条记录,每个记录由6170个二进制位组成。随机选择10000条数据作为目标模型的训练数据。
MNIST: 70000张32x32的手写图像数据,随机选择10000条数据作为目标模型的训练数据。
UCI Adult(Census Income): 48842条人口普查数据,每条记录由14个属性构成,包括年龄、性别,受教育程度、工作时长等。实验任务是判断一个人年收入是否超过50K刀。随机选择10000条数据作为目标模型的训练数据。
目标模型
Google Prediction API: 没有用户可调的参数,用户上传数据集,然后获得模型API。
Amazon ML: 不能选择模型类型,但是可以调节一部分参数。在本次实验中,改变训练数据的最大传递数量和L2正则项数量。
Neural networks: 使用Torch7和封装的nn包来构建神经网络
在CIFAR数据集上,训练了一个包含两个卷积层和最大池化层以及一个尺寸为128的全连接层和一个softmax层的CNN。激活函数为Tanh,学习率为0.001,学习率衰减为1 e − 07,训练的最大epochs为100。
在purchase训练了一个包含一个尺寸为128的隐藏层和一个softmax层的全连接神经网络。激活函数为Tanh,学习率为0.001,学习率衰减为1 e − 07,训练的最大epochs为200。
实验设置
目标和影子模型的训练集和测试集随机从数据集中选择,具有相同的尺寸,并不交叉(不同影子模型的数据集可以重叠)。
CIFAR数据集只训练本地神经网络。
purchase数据集训练了本地神经网络、Google以及Amazon的机器学习服务(这三个目标模型的相同的训练集)。
其他数据集只在Google或Amazon的机器学习服务上训练。
影子模型数量:CIFAR为100,purchase为20,Texas hospital stay 为10,location为60,MNIST为50,Adult为20。
攻击准确性评价
攻击者的目标是确定给定的记录是否是目标模型训练数据集的一部分。
我们通过从目标的训练和测试数据集中随机重组的记录来评估这种攻击。在我们的攻击评估中,我们使用相同大小的集合(即成员和非成员数目相等)来最大化推断的不确定性,因此基线精度为0.5。
使用Precision和Recall来评估攻击。大多数度量是按类报告的,因为攻击的准确度对于不同的类可以有很大的不同。
实验结果
具体实验结果和参数分析见原文
影响因素包括影子训练数据的影响,类的数目和每类训练数据的影响,过拟合的影响等,原文分析结果十分充分,可去原文中查看。
总结评价
本论文主要新颖的点在于影子模型的提出,以及训练,可以在未知目标模型训练数据集和目标模型结构的前提下,进行对attacker的训练,最终实现对目标模型的攻击。
本人小白一枚,水平有限,如有问题,欢迎讨论,感谢理解。