Python基础入门:从0完成一个数据分析实战—阿里云天池 Task 4
精灵宝可梦数据集分析
不知不觉已经学到最后一天了,今天的任务是进行一个新手数据分析。其实每个人对于学习都是有着自己的经验和方法的,10天的学习还是有提升的,最主要的还是隐约找到了消失了很久的方向感。
我想这也是学习的目的之一,说什么为职业生涯奠基础就算了,这么大岁数不扯了,能把学到的的知识运用到实践中,才是学习的最佳效果。
数据集下载
链接: link.
数据集介绍
-
本数据涵盖了从第一代到第七代共801只宝可梦小精灵的信息。数据特征上包含了基础的能力值,对于其他属性的克制能力,身高,体重,种类等等。
-
字段名解释
| 名称 | 中文解释 |
|---|---|
| name | 宝可梦的英文名 |
| japanese_name | 宝可梦的日文名 |
| pokedex_number | 宝可梦图鉴ID |
| percentage_male | 宝可梦为男性的比率(空白为无性别属性) |
| type1 | 宝可梦的主属性 |
| type2 | 宝可梦的副属性 |
| classification | 宝可梦的精灵类型 |
| height_m | 宝可梦的身高 |
| weight_kg | 宝可梦的体重 |
| capture_rate | 宝可梦的捕捉几率 |
| baseeggsteps | 宝可梦的孵化阶段 |
| abilities | 宝可梦的能力 |
| experience_growth | 宝可梦的成长经历 |
| base_happiness | 宝可梦活跃指数 |
| against_? | 18项定向攻击的伤害指数 |
| hp | 宝可梦的血量 |
| attack | 基础攻击属性 |
| defense | 基础防御属性 |
| sp_attack | 特殊攻击属性 |
| sp_defense | 特殊防御属性 |
| speed | 基础速度属性 |
| generation | 第几代 |
| is_legendary | 是否为传奇宝可梦 |
相关分析
# 引用相关库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv("pokemon.csv")
# 查看数据
df.head()
# 查看索引、数据类型和内存信息
df.info()
'''
RangeIndex: 801 entries, 0 to 800
Data columns (total 41 columns):
abilities 801 non-null object
against_bug 801 non-null float64
against_dark 801 non-null float64
against_dragon 801 non-null float64
against_electric 801 non-null float64
against_fairy 801 non-null float64
against_fight 801 non-null float64
against_fire 801 non-null float64
against_flying 801 non-null float64
against_ghost 801 non-null float64
against_grass 801 non-null float64
against_ground 801 non-null float64
against_ice 801 non-null float64
against_normal 801 non-null float64
against_poison 801 non-null float64
against_psychic 801 non-null float64
against_rock 801 non-null float64
against_steel 801 non-null float64
against_water 801 non-null float64
attack 801 non-null int64
base_egg_steps 801 non-null int64
base_happiness 801 non-null int64
base_total 801 non-null int64
capture_rate 801 non-null object
classfication 801 non-null object
defense 801 non-null int64
experience_growth 801 non-null int64
height_m 781 non-null float64
hp 801 non-null int64
japanese_name 801 non-null object
name 801 non-null object
percentage_male 703 non-null float64
pokedex_number 801 non-null int64
sp_attack 801 non-null int64
sp_defense 801 non-null int64
speed 801 non-null int64
type1 801 non-null object
type2 417 non-null object
weight_kg 781 non-null float64
generation 801 non-null int64
is_legendary 801 non-null int64
dtypes: float64(21), int64(13), object(7)
memory usage: 256.6+ KB
'''
# 计算出每个特征有多少百分比是缺失的
percent_missing = df.isnull().sum() * 100 / len(df)
missing_value_df = pd.DataFrame({
'column_name': df.columns,
'percent_missing': percent_missing
})
missing_value_df.sort_values(by='percent_missing', ascending=False).head(10)
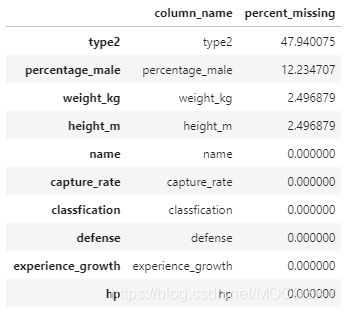
- 如数据所示,通过排序共有4个字段有缺失,
type2最高,48%的宝可梦无副属性。
# 查看各代口袋妖怪的数量
df['generation'].value_counts().sort_values(ascending=False).plot.bar()

- 数量最多的是在第5代,最少的是在第6代。
# 查看每个系口袋妖怪的数量
df['type1'].value_counts().sort_values(ascending=True).plot.barh()

- 水系宝可梦最多,飞行系最少,虽然没亲身玩过,不过一般物以稀为贵的定律是逃不过的。
# 相关性热力图分析
plt.subplots(figsize=(20,15))
ax = plt.axes()
ax.set_title("Correlation Heatmap")
corr = df.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)

attack和height_m为正相关,说明宝可梦的身高越高,其基础攻击力越强。
# 对宝可梦的血量,攻击力,防御力,特攻,特防,速度
interested = ['hp','attack','defense','sp_attack','sp_defense','speed']
sns.pairplot(df[interested])

- 到大部分都是成正比例的,一个值的提高往往会拉高另外一个值。
# 通过相关性分析heatmap分析五个基础属性
plt.subplots(figsize=(10,8))
ax = plt.axes()
ax.set_title("Correlation Heatmap")
corr = df[interested].corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values,
annot=True, fmt="f",cmap="YlGnBu")

# 特征类型转化,增加“种族值”特征
for c in interested:
df[c] = df[c].astype(float)
df = df.assign(total_stats = df[interested].sum(axis=1))
df[df.total_stats >= 525].shape # (167, 42)
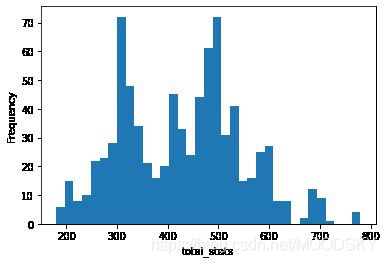
total_stats代表了这个新的特征,用直方图可以看看种族值的分布是什么样的。
# 种族值分布
total_stats = df.total_stats
plt.hist(total_stats,bins=35)
plt.xlabel('total_stats')
plt.ylabel('Frequency')
# 不同属性的种族值分布
plt.subplots(figsize=(20,12))
ax = sns.violinplot(x="type1", y="total_stats",
data=df, palette="muted")

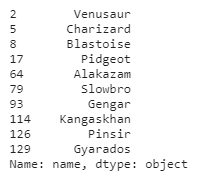
# 种族值大于570的,但是不是神兽的
df[(df.total_stats >= 570) & (df.is_legendary == 0)]['name'].head(10)
其他有意思的分析
sns.jointplot("base_egg_steps", "experience_growth", data=df, size=5, ratio=3, color="g")

sns.jointplot("attack", "hp", data=df, kind="kde")

# 双系宝可梦数量统计
plt.subplots(figsize=(10, 10))
sns.heatmap(
df[df['type2']!='None'].groupby(['type1', 'type2']).size().unstack(),
linewidths=1,
annot=True,
cmap="Blues"
)
plt.xticks(rotation=35)
plt.show()
