抖音品质建设 - iOS启动优化《实战篇》
前言
启动是 App 给用户的第一印象,启动越慢,用户流失的概率就越高,良好的启动速度是用户体验不可缺少的一环。启动优化涉及到的知识点非常多,面也很广,一篇文章难以包含全部,所以拆分成两部分:原理和实战,本文是实战篇。
原理篇:抖音品质建设-iOS 启动优化《原理篇》
如何做启动优化?
文章的正式内容开始之前,大家可以思考下,如果自己去做启动优化的,会如何去开展?
这其实是一个比较大的问题,遇到类似情况,我们都可以去把大问题拆解成几个小的问题:
线上用户究竟启动状况如何?
如何去找到可以优化的点?
做完优化之后,如何保持?
有没有一些成熟的经验可以借鉴,业界都是怎么做的?
对应着本文的三大模块:监控,工具和最佳实践。
监控
启动埋点
既然要监控,那么就要能够在代码里获取到启动时长。启动的起点大家采用的方案都一样:进程创建的时间。
启动的终点对应用户感知到的 Launch Image 消失的第一帧,抖音采用的方案如下:
iOS 12 及以下:root viewController 的 viewDidAppear
iOS 13+:applicationDidBecomeActive
Apple 官方的统计方式是第一个 CA::Transaction::commit,但对应的实现在系统框架内部,抖音的方式已经非常接近这个点了。
分阶段
只有一个启动耗时的埋点在排查线上问题的时候显然是不够的,可以通过分阶段和单点埋点结合,下面是这是目前抖音的监控方案:

+load、initializer 的调用顺序和链接顺序有关,链接顺序默认按照 CocoaPod 的 Pod 命名升序排列,所以取一个命名为 AAA 开头既可以让某个 +load、initializer 第一个被执行。
无侵入监控
公司的 APM 团队提供了一种无侵入的启动监控方案,方案将启动流程拆分成几个粒度比较粗的与业务无关的阶段:进程创建,最早的 +load,didFinishLuanching 开始和首屏首次绘制完成。
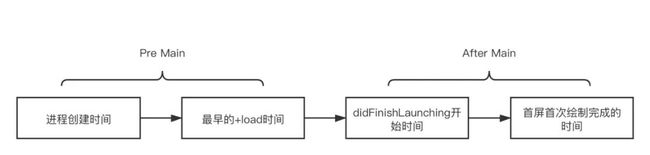
前三个时间点无侵入获取较为简单
进程创建:通过
sysctl系统调用拿到进程创建的时间戳最早的 +load:和上面的分阶段监控一样,通过 AAA 为前缀命名 Pod,让 +load 第一个被执行
didFinishLaunching:监控 SDK 初始化一般在启动的很早期,用监控 SDK 的初始化时间作为 didFinishLaunching 的时间
首屏渲染完成时间我们希望和 MetricKit 对齐,即获取到 CA::Transaction::commit()方法被调用的时间。
通过 Runloop 源码分析和线下调试,我们发现 CA::Transaction::commit(),CFRunLoopPerformBlock,kCFRunLoopBeforeTimers 这三个时机的顺序从早到晚依次是:

可以通过在 didFinishLaunch 中向 Runloop 注册 block 或者 BeforeTimer 的 Observer 来获取上图中两个时间点的回调,代码如下:
//注册block
CFRunLoopRef mainRunloop = [[NSRunLoop mainRunLoop] getCFRunLoop];
CFRunLoopPerformBlock(mainRunloop,NSDefaultRunLoopMode,^(){
NSTimeInterval stamp = [[NSDate date] timeIntervalSince1970];
NSLog(@"runloop block launch end:%f",stamp);
});
//注册kCFRunLoopBeforeTimers回调
CFRunLoopRef mainRunloop = [[NSRunLoop mainRunLoop] getCFRunLoop];
CFRunLoopActivity activities = kCFRunLoopAllActivities;
CFRunLoopObserverRef observer = CFRunLoopObserverCreateWithHandler(kCFAllocatorDefault, activities, YES, 0, ^(CFRunLoopObserverRef observer, CFRunLoopActivity activity) {
if (activity == kCFRunLoopBeforeTimers) {
NSTimeInterval stamp = [[NSDate date] timeIntervalSince1970];
NSLog(@"runloop beforetimers launch end:%f",stamp);
CFRunLoopRemoveObserver(mainRunloop, observer, kCFRunLoopCommonModes);
}
});
CFRunLoopAddObserver(mainRunloop, observer, kCFRunLoopCommonModes);
经过实测,我们最后选择的无侵入获取首屏渲染方案是:
iOS13(含)以上的系统采用
runloop中注册一个kCFRunLoopBeforeTimers的回调获取到的 App 首屏渲染完成的时机更准确。iOS13 以下的系统采用
CFRunLoopPerformBlock方法注入 block 获取到的 App 首屏渲染完成的时机更准确。
监控周期

App 的生命周期可以分为三个阶段:研发,灰度和线上,不同阶段监控的目的和方式都不一样。
研发阶段
研发阶段的监控主要目的是防止劣化,对应着会有线下的自动化监控,通过实际的启动性能测试来尽早地发现和解决问题,抖音的线下自动化监控流程图如下:
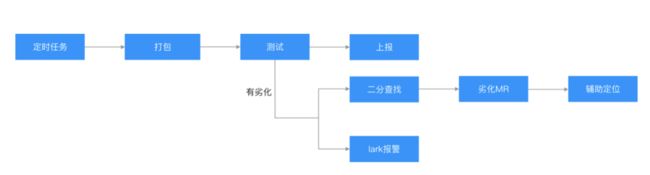
由定时任务触发,先 release 模式下打包,接着跑一次自动化测试,测试完毕后会上报测试结果,方便通过看板来跟踪整体的变化趋势。
如果发现有劣化,会先发一条报警信息,接着通过二分查找的方式找到对应的劣化 MR,然后自动跑火焰图和 Instrument 来辅助定位问题。
那么如何保证测试的结果是稳定可靠的呢?
答案就是控制变量:
关闭 iCloud & 不登录 AppleID & 飞行模式
风扇降温,且用 MFI 认证数据线
重启手机和开始下一次测试之前静置一段时间
多次测量取平均值 & 计算方差
Mock 启动过程中的 AB 变量
实践下来,我们发现 iPhone 8 的稳定性最好,其次是 iPhone X,iPhone 6 的稳定性很差。
除了自动化测试,在研发流程上还可以加一些准入,来防止启动劣化,这些准入包括
新增动态库
新增 +load 和静态初始化
新增启动任务 Code Review
不建议做细粒度的 Code Review,除非对相关业务很了解,否则一般肉眼看不出会不会有劣化。
线上 & 灰度
灰度和线上的策略是相似的,主要看的是大盘数据和配置报警,大盘监控和报警和公司的基建有很大关系,如果没有对应基建 Xcode MetricKit 本身也可以看到启动耗时:打开 Xcode -> Window -> Origanizer -> Launch Time
大盘数据本身是统计学的,会有些统计学的规律:
发版本的前几天启动速度比较慢,这是因为 iOS 13 后更新 App 的第一次启动要创建启动闭包,这个过程是比较慢的
新版本发布会导致老版本 pct50 变慢,因为性能差的设备升级速度慢,导致老版本性能差设备比例变高
采样率调整会影响 pct50,比如某些地区的 iPhone 6 比例较高,如果这些地区采样率提高会导致大盘性能差的设备比例提高。
基于这些背景,我们一般会通过控制变量的方式:拆地区,机型,版本,有时候甚至要根据时间看启动耗时的趋势。
工具
完成了监控之后,我们需要找到一些可以优化的点,就需要用到工具。主要包括两大类:Instrument 和自研。
Time Profiler
Time Profiler 是大家日常性能分析中用的比较多的工具,通常会选择一个时间段,然后聚合分析调用栈的耗时。但Time Profiler 其实只适合粗粒度的分析,为什么这么说呢?我们来看下它的实现原理:
默认 Time Profiler 会 1ms 采样一次,只采集在运行线程的调用栈,最后以统计学的方式汇总。比如下图中的 5 次采样中,method3 都没有采样到,所以最后聚合到的栈里就看不到 method3。所以 Time Profiler 中的看到的时间,并不是代码实际执行的时间,而是栈在采样统计中出现的时间。
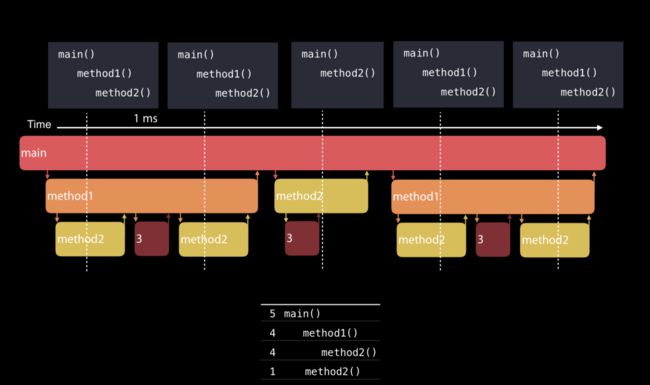
Time Profiler 支持一些额外的配置,如果统计出来的时间和实际的时间相差比较多,可以尝试开启:
High Frequency,降低采样的时间间隔
Record Kernel Callstacks,记录内核的调用栈
Record Waiting Thread,记录被 block 的线程
System Trace
既然 Time Profiler 支持粗粒度的分析,那么有没有什么精细化的分析工具呢?答案就是 System Trace。
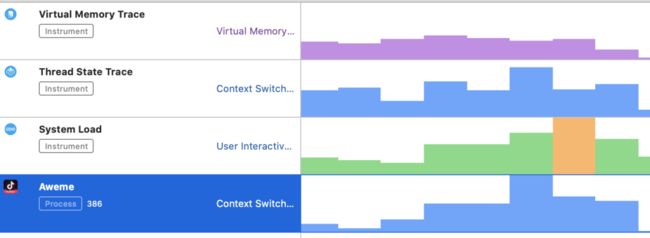
既然要精细化分析,那么我们就需要标记出一小段时间,可以用 Point of interest 来标记。除此之外,System Trace 分析虚拟内存和线程状态都很管用:
Virtual Memory:主要关注 Page In这个事件,因为启动路径上有很多次 Page In,且相对耗时
Thread State:主要关注挂起和抢占两个状态,记住主线程不是一直在运行的
System Load 线程有优先级,高优先级的线程不应该超过系统核心数量
os_signpost
os_signpost 是 iOS 12 推出的用于在 instruments 里标记时间段的 API,性能非常高,可以认为对启动无影响。结合最开始讲的分阶段监控,我们可以在 Instrument 把启动划分成多个阶段,和其他模板一起分析具体问题:

结合 swizzle,os_signpost 可以发挥出意想不到的效果,比如 hook 所有的 load 方法,来分析对应耗时,又比如 hook UIImage 对应方法,来统计启动路径上用到的图片加载耗时。
其他 Instrument 模板
除了这些,还有几个模板是比较常用的:
Static Initializer:分析 C++ 静态初始化
App Launch:Xcode 11 后新出的模板,可以认为是 Time Profiler + System Trace
Custom Instrument:自定义 Instrument,最简单是用 os_signpost 作为模板的数据源,自己做一些简单的定制化展示,具体可参考 WWDC 的相关 Session。
火焰图
火焰图用来分析时间相关的性能瓶颈非常有用,可以直接把业务代码的耗时绘制出来。此外,火焰图可以自动化生成然后 diff,所以可以用于自动化归因。
火焰图有两种常见实现方式
hook objc_msgSend
编译期插桩
本质上都是在方法的开始和末尾打两个点,就知道这个方法的耗时,然后转换成 Chrome 的标准的 json 格式就可以分析了。注意就算用 mmap 来写文件,仍然会有一些误差,所以找到的问题并不一定是问题,需要二次确认。
最佳实践
整体思路
优化的整体思路其实就四步:
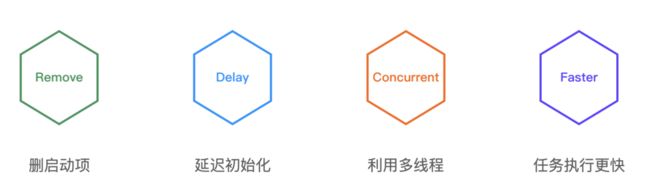
删掉启动项,最直接
如果不能删除,尝试延迟,延迟包括第一次访问以及启动结束后找个合适的时间预热
不能延迟的可以尝试并发,利用好多核多线程
如果并发也不行,可以尝试让代码执行更快
这块会以 Main 函数做分界线,看下 Main 函数前后的优化方案;接着介绍如何优化 Page In;最后讲解一些非常规的优化方案,这些方案对架构的要求比较高。
Main 之前
Main 函数之前的启动流程如下:
加载 dyld
创建启动闭包(更新 App/重启手机需要)
加载动态库
Bind & Rebase & Runtime 初始化
+load 和静态初始化

动态库
减少动态库数量可以加减少启动闭包创建和加载动态库阶段的耗时,官方建议动态库数量小于 6 个。
推荐的方式是动态库转静态库,因为还能额外减少包大小。另外一个方式是合并动态库,但实践下来可操作性不大。最后一点要提的是,不要链接那些用不到的库(包括系统),因为会拖慢创建闭包的速度。
下线代码
下线代码可以减少 Rebase & Bind & Runtime 初始化的耗时。那么如何找到用不到的代码,然后把这些代码下线呢?可以分为静态扫描和线上统计两种方式。
最简单的静态扫描是基于 AppCode,但是项目大了之后 AppCode 的索引速度非常慢,另外的一种静态扫描是基于 Mach-O 的:
_objc_selrefs和_objc_classrefs存储了引用到的 sel 和 class__objc_classlist存储了所有的 sel 和 class
二者做个差集就知道那些类/sel 用不到,但objc 支持运行时调用,删除之前还要在二次确认。
还有一种统计无用代码的方式是用线上的数据统计,主流的方案有三种:
ViewConteroller 渗透率,hook 对应的声明周期方法即可统计
Class 渗透率,遍历运行时的所有类,通过 Objective C Runtime 的标志位判断类是否被访问
行级渗透率,需要用编译期插桩,对包大小和执行速度均有损。
前两种是 ROI 较高的方案,绝大多数时候 Class 级别的渗透率足够了。
+load 迁移
+load 除了方法本身的耗时,还会引起大量 Page In,另外 +load 的存在对 App 稳定性也是冲击,因为 Crash 了捕获不到。
举个例子,很多 DI 的容器需要把协议绑定到类,所以需要在启动的早期(+load)里注册:
+ (void)load
{
[DICenter bindClass:IMPClass toProtocol:@protocol(SomeProcotol)]
}
本质上只要知道协议和类的对应关系即可,利用 clang attribute,这个过程可以迁移到编译期:
typedef struct{
const char * cls;
const char * protocol;
}_di_pair;
#if DEBUG
#define DI_SERVICE(PROTOCOL_NAME,CLASS_NAME)\
__used static Class _DI_VALID_METHOD(void){\
return [CLASS_NAME class];\
}\
__attribute((used, p(_DI_SEGMENT "," _DI_SECTION ))) static _di_pair _DI_UNIQUE_VAR = \
{\
_TO_STRING(CLASS_NAME),\
_TO_STRING(PROTOCOL_NAME),\
};\
#else
__attribute((used, p(_DI_SEGMENT "," _DI_SECTION ))) static _di_pair _DI_UNIQUE_VAR = \
{\
_TO_STRING(CLASS_NAME),\
_TO_STRING(PROTOCOL_NAME),\
};\
#endif
原理很简单:宏提供接口,编译期把类名和协议名写到二进制的指定段里,运行时把这个关系读出来就知道协议是绑定到哪个类了。
有同学会注意到有个无用的方法_DI_VALID_METHOD ,这个方法只在 debug 模式下存在,为了让编译器保证类型安全。
静态初始化迁移
静态初始化和 +load 方法一样也会引起大量 Page In,一般来自 C++代码,比如网络或者特效的库。另外有些静态初始化是通过头文件引入进来的,可以通过预处理来确认。
几个典型的迁移思路:
std:string 转换成 const char *
静态变量移动到方法内部,因为方法内部的静态变量会在方法第一次调用的时候初始化
//Bad
namespace {
static const std::string bucket[] = {"apples", "pears", "meerkats"};
}
const std::string GetBucketThing(int i) {
return bucket[i];
}
//Good
std::string GetBucketThing(int i) {
static const std::string bucket[] = {"apples", "pears", "meerkats"};
return bucket[i];
}
Main 之后
启动器
启动是需要一个框架来管控的,抖音采用了轻量级的中心式方案:
有个启动任务的配置仓,里面只包含启动任务的顺序和线程
业务仓实现协议 BootTask,表明这是个启动任务
启动任务的执行流程如下:
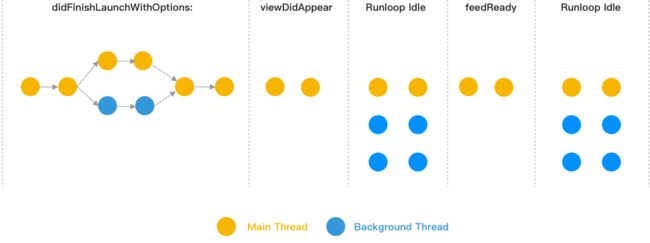
为什么需要启动器呢?
全局并发调度:比如 AB 任务并发,C 任务等待 AB 执行完毕,框架调度还能减少线程数量和控制优先级
延迟执行:提供一些时机,业务可以做预热性质的初始化
精细化监控:所有任务的耗时都能监控到,线下自动化监控也能受益
管控:启动任务的顺序调整,新增/删除都能通过 Code Review 管控
三方 SDK
有些三方 SDK 的启动耗时很高,比如 Fabric,抖音下线了 Fabric 后启动速度 pct50 快了 70ms 左右。
除了下线,很多 SDK 是可以延迟的,比如分享和登录的 SDK。此外,在接入 SDK 之前可以先评估下对启动性能的影响,如果影响较大是可以反馈给 SDK 的提供方去修改的,尤其是付费的 SDK,他们其实很愿意配合做一些修改。
高频次方法
有些方法的单个耗时不高,但是在启动路径上会调用很多次的,这种累计起来的耗时也不低,比如读 Info.plist 里面的配置:
+ (NSString *)plistChannel
{
return [[[NSBundle mainBundle] infoDictionary] objectForKey:@"CHANNEL_NAME"];
}
修改的方式很简单,加一层内存缓存即可,这种问题在 TimeProfiler 里时间段选长一些往往就能看出来。
锁
锁之所以会影响启动时间,是因为有时候子线程先持有了锁,主线程就需要等待子线程锁释放。还要警惕系统会有很多隐藏的全局锁,比如 dyld 和 Runtime。举个例子:
下图是 UIImage imageNamed 引起的主线程 block:
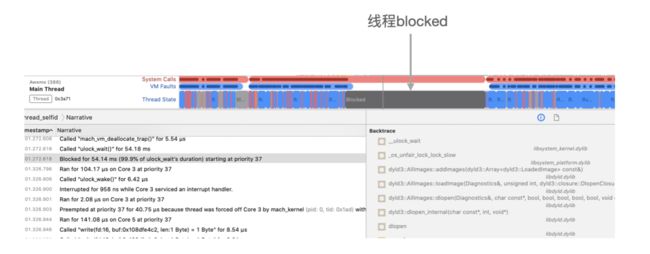
通过右侧的堆栈能看到,imageNamed 触发了 dlopen,dlopen 会等待 dyld 的全局锁。通过 System Trace 的 Thread State Event,可以找到线程被 blocked 的下一个事件,这个事件表明了线程重新可以运行,原因就是其他线程释放了锁:
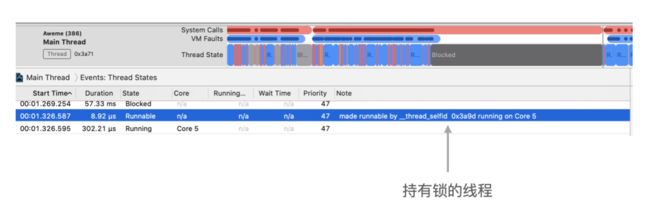
接下来通过分析后台线程这个时间在做什么,就知道为什么会持有锁,如何优化了。
线程数量
线程的数量和优先级都会影响启动时间。可以通过设置 QoS 来配置优先级,两个高优的 QoS 是 User Interactive/Initiated,启动的时候,需要主线程等待的子线程任务都应该设置成高优的。
高优的线程数量不应该多于 CPU 核心数量,可以通过 System Trace 的 System Load 来分析这种情况。
/GCD
dispatch_queue_attr_t attr = dispatch_queue_attr_make_with_qos_class(DISPATCH_QUEUE_SERIAL, QOS_CLASS_UTILITY, -1);
dispatch_queue_t queue = dispatch_queue_create("com.custom.utility.queue", attr);
//NSOperationQueue
operationQueue.qualityOfService = NSQualityOfServiceUtility
线程的数量也会影响启动时间,但 iOS 中是不太好全局管控线程的,比如二/三方库要起后台线程就不太好管控,不过业务上的线程可以通过启动任务管控。
线程多没关系,只要同时并发执行的不多就好,大家可以利用 System Trace 来看看上下文切换耗时,确认线程数量是否是启动的瓶颈。
图片
启动难免会用到很多图,有没有办法优化图片加载的耗时呢?
用 Asset 管理图片而不是直接放在 bundle 里。Asset 会在编译期做优化,让加载的时候更快,此外在 Asset 中加载图片是要比 Bundle 快的,因为 UIImage imageNamed 要遍历 Bundle 才能找到图。加载 Asset 中图的耗时主要在在第一次张图,因为要建立索引,可以通过把启动的图放到一个小的 Asset 里来减少这部分耗时。
每次创建 UIImage 都需要 IO,在首帧渲染的时候会解码。所以可以通过提前子线程预加载(创建 UIImage)来优化这部分耗时。
如下图,启动只有到了比较晚的阶段“RootWindow 创建”和“首帧渲染”才会用到图片,所以可以在启动的早期开预加载的子线程启动任务。

Fishhook
fishhook 是一个用来 hook C 函数的库,但这个库的第一次调用耗时很高,最好不要带到线上。Fishhook 是按照下图的方式遍历 Mach-O 的多个段来找函数指针和函数符号名的映射关系,带来的副作用就是要大量的 Page In,对于大型 App 来说在 iPhone X 冷启耗时 200ms+。
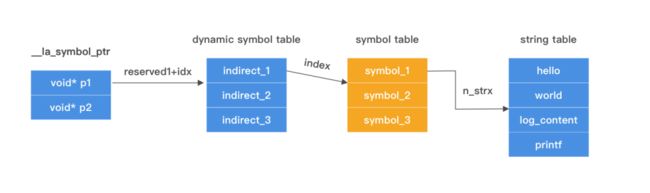
如果不得不用 fishhook,请在子线程调用,且不要在在_dyld_register_func_for_add_image直接调用 fishhook。因为这个方法会持有 dyld 的一个全局互斥锁,主线程在启动的时候系统库经常会调用 dlsym 和 dlopen,其内部也需要这个锁,造成上文提到的子线程阻塞主线程。
首帧渲染
不同 App 的业务形态不同,首帧渲染优化方式也相差的比较多,几个常见的优化点:
LottieView:lottie 是 airbnb 用来做 AE 动画的库,但是加载动画的 json 和读图是比较慢的,可以先显示一帧静态图,启动结束后再开始动画,或者子线程预先把图和 json 设置到 lottie cache 里
Lazy 初始化 View:不要先创建设置成 hidden,这是很不好的习惯
AutoLayout:AutoLayout 的耗时也是比较高的,但这块往往历史包袱比较重,可以评估 ROI 看看要不要改成 frame
Loading 动画:App 一般都会有个 loading 动画表示加载中,这个动画最好不要用 gif,线下测量一个 60 帧的 gif 加载耗时接近 70ms
其他 Tips
启动优化里有一些需要注意的 Tips:
不要删除tmp/com.apple.dyld目录,因为这个目录下存储着 iOS 13+的启动闭包,如果删除了下次启动会重新创建,创建闭包的过程是很慢的。接下来是 IO 优化,常见的方式是用 mmap 让 IO 更快一些,也可以在启动的早期预加载数据。
还有一些 iPhone 6 上耗时会明显增加的点:
WebView User Agent:第一次在启动时获取,之后缓存,每次启动结束后刷新
KeyChain:可以延迟获取或者预加载
VolumeView:建议直接删掉
iPhone 6 是个分水岭,性能会断崖式下跌,可以在 iPhone 6 上下掉部分用户交互来换取核心体验(记得 AB 验证)。
Page In 耗时
启动路径上会触发大量 Page In,有没有办法优化这部分耗时呢?
段重命名
App Store 会对上传的 App 的 TEXT 段加密,在发生 Page In 的时候会解密,解密的过程是很耗时的。既然会 TEXT 段加密,那么直接的思路就是把 TEXT 段中的内容移动到其它段,ld 也有个参数 rename_p 支持重命名:
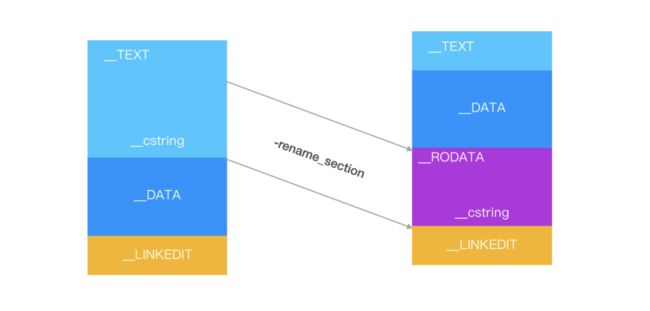
抖音重命名方案:
"-Wl,-rename_p,__TEXT,__cstring,__RODATA,__cstring",
"-Wl,-rename_p,__TEXT,__const,__RODATA,__const",
"-Wl,-rename_p,__TEXT,__gcc_except_tab,__RODATA,__gcc_except_tab",
"-Wl,-rename_p,__TEXT,__objc_methname,__RODATA,__objc_methname",
"-Wl,-rename_p,__TEXT,__objc_classname,__RODATA,__objc_classname",
"-Wl,-rename_p,__TEXT,__objc_methtype,__RODATA,__objc_methtype"
这个优化方式在 iOS 13 下有效,因为 iOS 13 优化了解密流程,Page In 的时候不需要解密了,这是 iOS 13 启动速度变快的原因之一。
二进制重排
既然启动的路径上会触发大量的 Page In,那么有没有什么办法优化呢?
启动具有局部性特征,即只有少部分函数在启动的时候用到,这些函数在中的分布是零散的,所以 Page In 读入的数据利用率并不高。如果我们可以把启动用到的函数排列到二进制的连续区间,那么就可以减少 Page In 的次数,从而优化启动时间:
以下图为例,方法 1 和方法 3 是启动的时候用到的,为了执行对应的代码,就需要两次 Page In。假如我们把方法 1 和 3 排列到一起,那么只需要一次 Page In,从而提升启动速度。
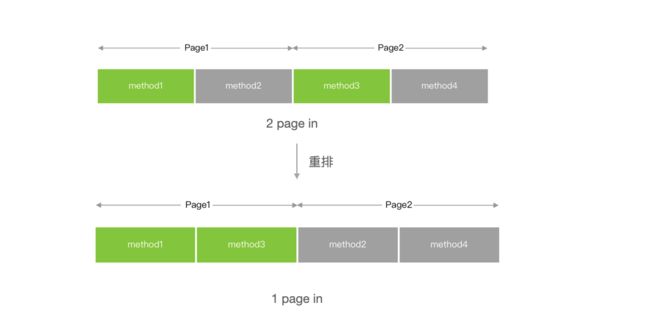
链接器 ld 有个参数-order_file 支持按照符号的方式排列二进制。获取启动时候用到的符号主流有两种方式:
抖音方案:静态扫描获取 +load 和 C++静态初始化,hook objc_msgSend 获取 Objective C 符号。
Facebook 方案:LLVM 函数插桩,灰度统计启动路径符号,用大多数用户的符号生成 order_file。
Facebook 的 LLVM 函数插桩是针对 order_file 定制,并且代码也是他们自己给 LLVM 开发的,目前已经合并到 LLVM 主分支了。

Facebook 的方案更精细化,生成的 order_file 是最优解,但是工程量很大。抖音的方案不需要源码编译,不需要对现有编译环境和流程改造,侵入性最小,缺点就是只能覆盖 90%左右的符号。
- 灰度是任何优化都要利用好的一个阶段,因为很多新的优化方案存在不确定性,需要先在灰度上验证。
非常规方案
动态库懒加载
最开始我们提到可以通过删代码的方式来减少代码量,那么有没有什么不减少代码总量,就可以减少启动时候要加载代码数量的方式呢?
答案就是动态库懒加载。
什么是懒加载的动态库呢?正常动态库都是会被主二进制直接或者间接链接的,那么这些动态库会在启动的时候加载。如果只打包进 App,不参与链接,那么启动的时候就不会自动加载,在运行时需要用到动态库里面的内容的时候,再手动懒加载。
懒加载动态库需要在编译期和运行时都进行改造,编译期的架构:
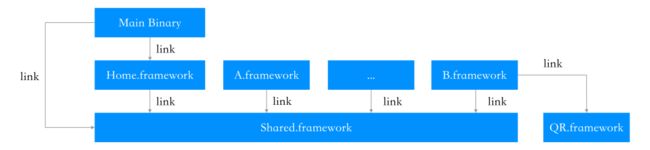
像 A.framework 等动态库是懒加载的,因为并没有参与主二进制的直接 or 间接链接。动态库之间一定会有一些共同的依赖,把这些依赖打包成 Shared.framework 解决公共依赖的问题。
运行时通过-[NSBundle load]来加载,本质上调用的是底层的 dlopen。那么什么时候触发动态库手动加载呢?
动态库可以分成两种:业务和功能。业务就是 UI 的入口,可以把动态库加载的逻辑收敛到路由内部,这样外部其实并不知道动态库是懒加载的,也能更好地容错。功能库(比如上图的 QR.framework)会有些不一样,因为没有 UI 等入口,需要功能库自己维护 Wrapper:
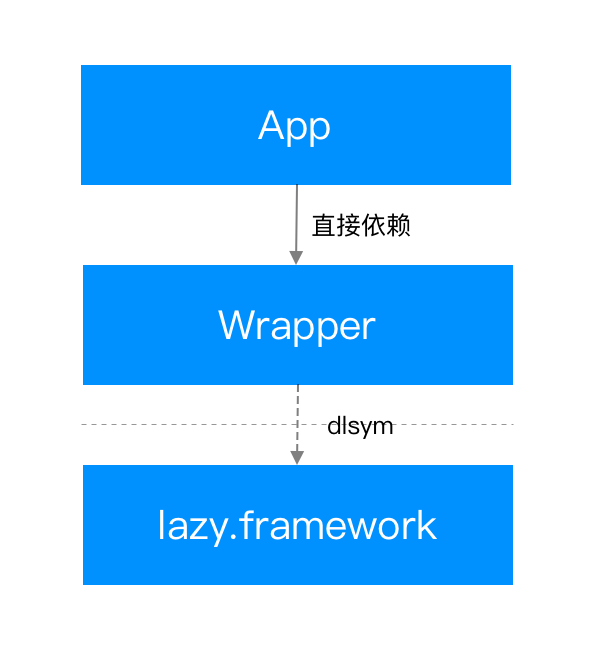
App 对 Wrapper 直接依赖,这样外部并不知道这个动态库是懒加载的
Wrapper 内部封装了动态调用逻辑,动态调用指的是通过 dlsym 等方式调用
动态库懒加载除了启动加载的代码减少,还能长期防止业务增加代码引起启动劣化,因为业务的初始化在第一次访问的时候完成的。
这个方案还有其他优点,比如动态库化后本地编译时间会大幅度降低,对其他性能指标也有好处,缺点是会牺牲一定程度的包大小,但可以用段压缩等方式优化懒加载的动态库来打平这部分损耗。
Background Fetch
Background Fetch 可以隔一段时间把 App 在后台启动,对于时间敏感的 App(比如新闻)可以在后台刷新数据,这样能够提高 Feed 加载的速度,进而提升用户体验。
那么,这种类似“后台保活”的机制,为什么能提高启动速度呢?我们来看一个典型的 case:
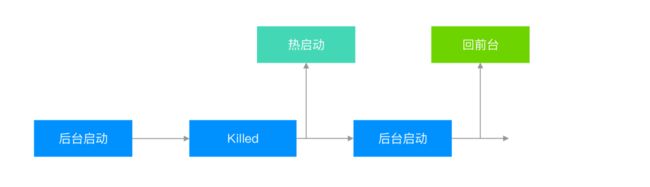
系统在后台启动 App
时间长因为内存等原因,后台的 App 被 kill 了
这时候用户立刻启动 App,那么这次启动就是一次热启动,因为缓存还在
又一次系统在后台启动 App
这次用户在 App 在后台的时候点了 App,那么这次启动就是一次后台回前台,因为 App 仍然活着
通过这两个典型的场景,可以看出来为什么 Background Fetch 能提高启动速度了:
提高热启动在冷启动的占比
后台启动回前台被定义为启动,因为用户的角度来说这就是一次启动
后台启动有一些要注意的点,比如日活,广告,甚至是 AB 进组逻辑都会受影响,需要做不少适配。往往需要启动器来支撑,因为正常启动在 didFinishLaunch 执行的任务,在后台启动的时候需要延迟到第一次回前台的时候再执行。
总结
最后提炼出几点我们认为在任何优化中都重要的:
白盒优化,知道为什么慢,优化的是哪部分。
线上数据都是优化的指南针,也是衡量优化效果的唯一方式,建议开 AB 实验,验证对业务上的影响。
不要忽略防劣化的建设,尤其是业务迭代迅速的团队,否则很有可能优化的速度赶不上劣化。
做长期的架构建设,良好的架构会长期为启动这些基础性能保驾护航。
加入我们
我们是负责抖音客户端基础能力研发和新技术探索的团队。我们在工程/业务架构,研发工具,编译系统等方向深耕,支撑业务快速迭代的同时,保证超大规模团队的研发效能和工程质量。在性能/稳定性等方面不断探索,努力为全球数亿用户提供最极致的基础体验。
如果你对技术充满热情,欢迎加入抖音基础技术团队,让我们共建亿级全民 App。目前我们在上海、北京、杭州、深圳均有招聘需求,内推可以联系邮箱: [email protected] ,邮件标题: 姓名 - 工作年限 - 抖音 - 基础技术 - iOS/Android 。

欢迎关注「 字节跳动技术团队 」
简历投递联系邮箱「 [email protected] 」
 点击阅读原文,快来加入我们吧!
点击阅读原文,快来加入我们吧!