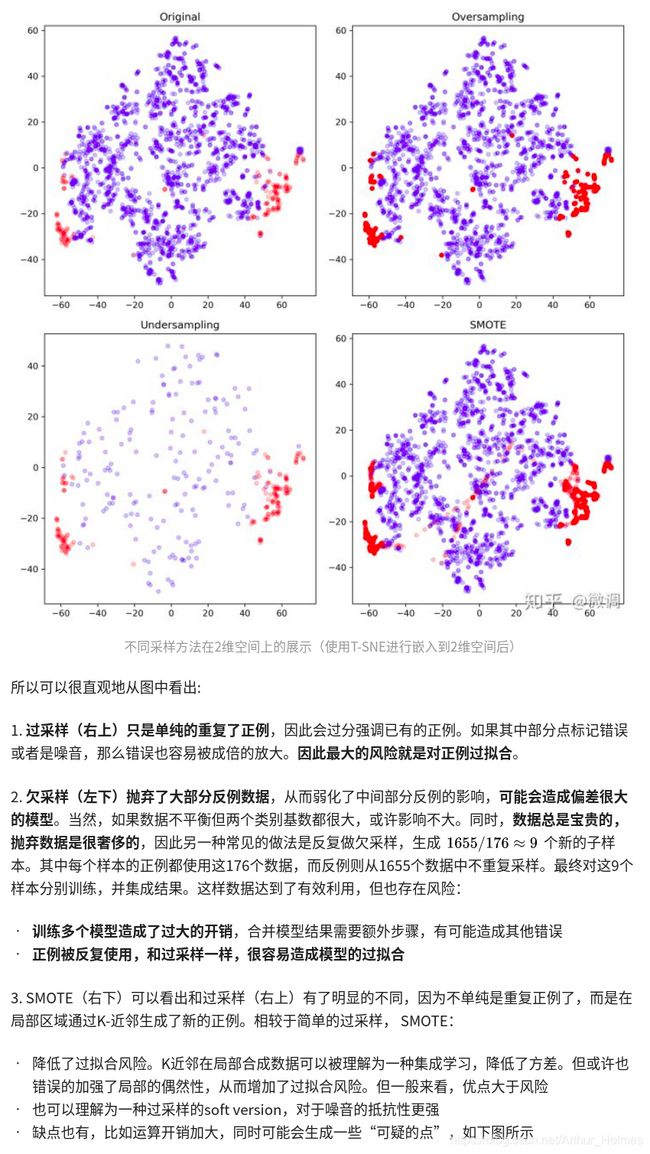
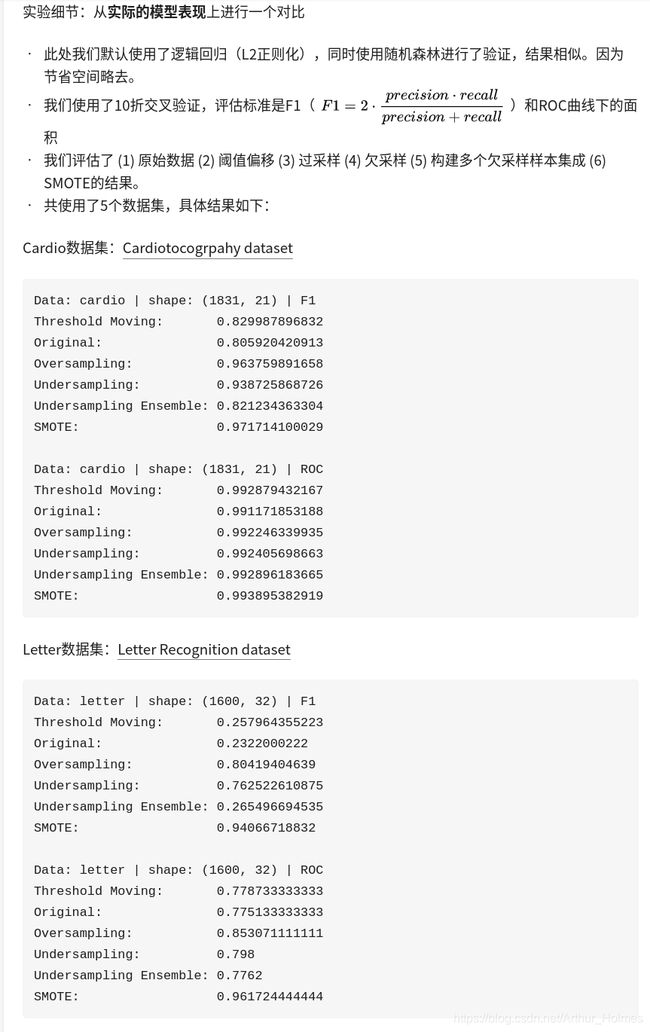
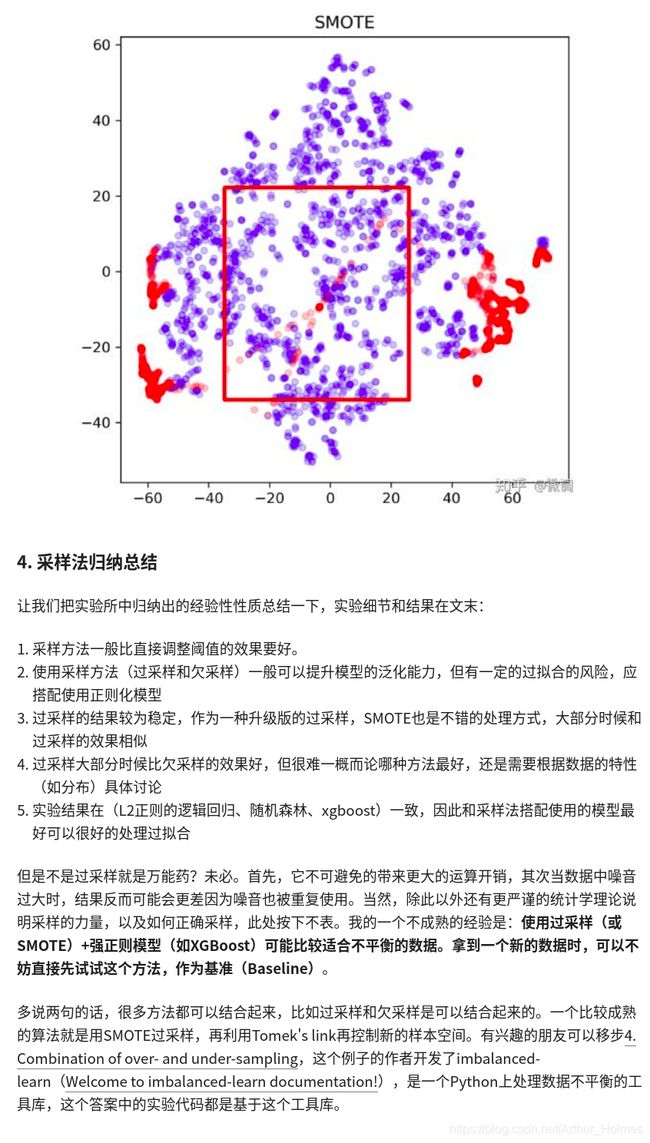
oversample 过采样方法 SMOTE ——欠采样(undersampling)和过采样(oversampling)会对模型带来怎样的影响
针对样本不平衡的监督学习问题,我们可能会用到一些抽样的方法来弥补数据上的不平衡。
import pandas as pd
#导入此解决方案中重要的模块SMOTE用来生成oversample样本
from imblearn.over_sampling import SMOTE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
#读取数据,然后划分特征和结果集
credit_cards=pd.read_csv('creditcard.csv')
#获取credit_cards表中列的名称
columns=credit_cards.columns
#删除最后一列,即class列
features_columns=columns.delete(len(columns)-1)
#获取除class列以外的所有特征列
features=credit_cards[features_columns]
#获取class列
labels=credit_cards['Class']
#划分原始数据训练集和测试集用于oversample模型生成
features_train, features_test, labels_train, labels_test = train_test_split(features,
labels,
test_size=0.3,
random_state=0)
#利用SMOTE创造新的数据集
#初始化SMOTE 模型
oversampler=SMOTE(random_state=0)
#使用SMOTE模型,创造新的数据集
os_features,os_labels=oversampler.fit_sample(features_train,labels_train)
#切分新生成的数据集
os_features_train, os_features_test, os_labels_train, os_labels_test = train_test_split(os_features,
os_labels,
test_size=0.2,
#看看新构造的oversample数据集中0,1分布情况
os_count_classes = pd.value_counts(os_labels, sort = True).sort_index()
os_count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")

os_features_train = pd.DataFrame(os_features_train)
os_labels_train = pd.DataFrame(os_labels_train)
#计算出best_c惩罚项之后
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(os_features_train,os_labels_train.values.ravel())
y_pred = lr.predict(features_test.values)
# 计算混淆矩阵
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 绘制混淆矩阵图
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()

SMOTE通过找近邻,然后生成一个新的随机位于近邻点和初始点之间的一个新点

https://www.zhihu.com/question/269698662