Telco Customer Churn
目录
- 项目来源
- 一、研究背景
- 二、研究问题
- 三、查看数据
- 四、数据清洗
-
- 4.1缺失值处理
- 4.2重复值处理
- 4.3数据类型转换
- 4.4异常值处理
- 五、EDA及可视化分析
-
- 5.1查看流失用户占比
- 5.2用户个人属性分析
- 5.3服务属性分析
- 5.4行为属性分析
- 5.5小结
- 六、构建预测模型
-
- 6.1特征离散化
- 6.2特征编码
- 6.3样本不均衡处理
- 七、结论和建议
项目来源
kaggle上的电信用户流失预测问题
电信用户流失数据集共7043条记录,21个字段。其中包括20个输入特征以及1个目标特征。分别如下表所示:
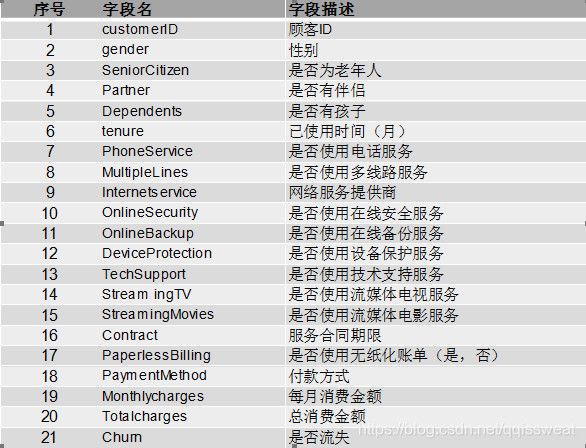
——————————————————以下是具体的数据分析内容———————————————————
一、研究背景
关于用户留存有这样一个观点,如果将用户流失率降低5%,公司利润将提升25%-85%。如今高居不下的获客成本让电信运营商遭遇“天花板”,甚至陷入获客难的窘境。随着市场饱和度上升,电信运营商亟待解决增加用户黏性,延长用户生命周期的问题。因此,电信用户流失分析与预测至关重要。做好“用户流失预测分析”可以:
1、降低营销成本。老生常谈,“新客户开发成本”是“老客户维护成本”的5倍。
2、获得更好的用户体验。并不是所有的增值服务都可以有效留住客户。
3、获得更高的销售回报。可以识别价格敏感型客户和非价格敏感性客户。
二、研究问题
1、顾客为什么会流失。(因果分析)对于这一问题我们可以分为两个维度进行考虑。首先是产品维度,即“公司提供的服务令人不满意”导致用户流失;其次是用户个人属性维度,如随着年龄的增长老年人对电话服务的需求降低导致其流失等原因。
2、具有什么样的行为特征说明了顾客有流失的倾向。(相关性分析)用户对于公司提供的产品服务所表现出的行为背后往往代表用户对于公司,对于产品的态度,从而可以在一定程度上预示顾客的去留。
3、对顾客是否会流失进行预测。
三、查看数据
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC,LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from xgboost import XGBClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
import warnings
warnings.filterwarnings('ignore')
导入数据
df=pd.read_csv('F:/kaggle/Telco_Customer_Churn-master/WA_Fn-UseC_-Telco-Customer-Churn.csv')
查看数据集信息
# 查看数据集大小
df.shape
(7043, 21)
# 查看前10条数据
pd.set_option('display.max_columns',None)
df.head(10)
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | Yes | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | No | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | Yes | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | No | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
| 5 | 9305-CDSKC | Female | 0 | No | No | 8 | Yes | Yes | Fiber optic | No | No | Yes | No | Yes | Yes | Month-to-month | Yes | Electronic check | 99.65 | 820.5 | Yes |
| 6 | 1452-KIOVK | Male | 0 | No | Yes | 22 | Yes | Yes | Fiber optic | No | Yes | No | No | Yes | No | Month-to-month | Yes | Credit card (automatic) | 89.10 | 1949.4 | No |
| 7 | 6713-OKOMC | Female | 0 | No | No | 10 | No | No phone service | DSL | Yes | No | No | No | No | No | Month-to-month | No | Mailed check | 29.75 | 301.9 | No |
| 8 | 7892-POOKP | Female | 0 | Yes | No | 28 | Yes | Yes | Fiber optic | No | No | Yes | Yes | Yes | Yes | Month-to-month | Yes | Electronic check | 104.80 | 3046.05 | Yes |
| 9 | 6388-TABGU | Male | 0 | No | Yes | 62 | Yes | No | DSL | Yes | Yes | No | No | No | No | One year | No | Bank transfer (automatic) | 56.15 | 3487.95 | No |
# 查看数据类型
df.info()
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
customerID 7043 non-null object
gender 7043 non-null object
SeniorCitizen 7043 non-null int64
Partner 7043 non-null object
Dependents 7043 non-null object
tenure 7043 non-null int64
PhoneService 7043 non-null object
MultipleLines 7043 non-null object
InternetService 7043 non-null object
OnlineSecurity 7043 non-null object
OnlineBackup 7043 non-null object
DeviceProtection 7043 non-null object
TechSupport 7043 non-null object
StreamingTV 7043 non-null object
StreamingMovies 7043 non-null object
Contract 7043 non-null object
PaperlessBilling 7043 non-null object
PaymentMethod 7043 non-null object
MonthlyCharges 7043 non-null float64
TotalCharges 7043 non-null object
Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
四、数据清洗
4.1缺失值处理
df.isnull().sum()
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 0
Churn 0
dtype: int64
4.2重复值处理
df.duplicated().sum()
0
4.3数据类型转换
"TotalCharages"总费用应该跟“MonthlyCharges”是同一个类型–float64。故需将"TotalCharages"由“object”转换成“float64”,且需要再次查看“缺失值”。
# df['TotalCharges'].astype('float64')
# 此处用“astype”转化数据类型报错 ValueError: could not convert string to float:
检查发现“TotalCharges”(总金额)列有11个用户数据为空值。
df.TotalCharges.value_counts()
11
20.2 11
19.75 9
20.05 8
19.9 8
..
167.2 1
4300.8 1
2998 1
4860.35 1
1127.35 1
Name: TotalCharges, Length: 6531, dtype: int64
经过观察,发现这11个用户‘tenure’(入网时长)为0,推测是当月新入网用户。
根据一般经验,用户即使在注册的当月流失,也需缴纳当月费用。因此将这11个用户入网时长改为1,将总消费额填充为月消费额,符合实际情况。
# 将总消费额填充为月消费额
df.loc[df['TotalCharges']==' ','TotalCharges']=df.loc[df['TotalCharges']==' ','MonthlyCharges']
#查看是否替换成功
print(df[df['tenure']==0][['tenure','MonthlyCharges','TotalCharges']])
tenure MonthlyCharges TotalCharges
488 0 52.55 52.55
753 0 20.25 20.25
936 0 80.85 80.85
1082 0 25.75 25.75
1340 0 56.05 56.05
3331 0 19.85 19.85
3826 0 25.35 25.35
4380 0 20.00 20
5218 0 19.70 19.7
6670 0 73.35 73.35
6754 0 61.90 61.9
# 将‘tenure’入网时长从0修改为1
df.loc[:,'tenure'].replace(to_replace=0,value=1,inplace=True)
#将TotalCharges数据类型转换为浮点型
df['TotalCharges']= pd.to_numeric(df['TotalCharges'])
print(df['TotalCharges'].dtypes)
float64
4.4异常值处理
# 获取数据类型的描述统计信息
df.describe()
| SeniorCitizen | tenure | MonthlyCharges | TotalCharges | |
|---|---|---|---|---|
| count | 7043.000000 | 7043.000000 | 7043.000000 | 7043.000000 |
| mean | 0.162147 | 32.372710 | 64.761692 | 2279.798992 |
| std | 0.368612 | 24.557454 | 30.090047 | 2266.730170 |
| min | 0.000000 | 1.000000 | 18.250000 | 18.800000 |
| 25% | 0.000000 | 9.000000 | 35.500000 | 398.550000 |
| 50% | 0.000000 | 29.000000 | 70.350000 | 1394.550000 |
| 75% | 0.000000 | 55.000000 | 89.850000 | 3786.600000 |
| max | 1.000000 | 72.000000 | 118.750000 | 8684.800000 |
#使用箱线图查看数据异常值
df1=df.copy()
scaler=StandardScaler(copy=False)
df1[['tenure','MonthlyCharges','TotalCharges']]=scaler.fit_transform(df1[['tenure','MonthlyCharges','TotalCharges']])
plt.figure(figsize=(8,4))
sns.boxplot(data=df1[['tenure','MonthlyCharges','TotalCharges']])
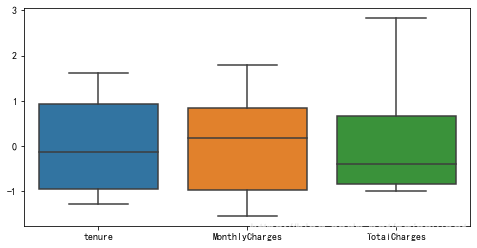
由以上结果可以看出,在三个变量中不存在明显的异常值。
五、EDA及可视化分析
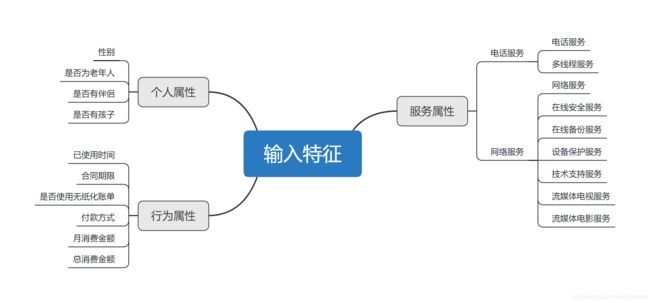
根据研究问题,我将所有输入特征分成了三个维度:用户个人属性、用户行为属性,服务属性,如下图所示,分别对他们进行分析。
5.1查看流失用户占比
plt.figure(figsize=(8,6))
plt.pie(df['Churn'].value_counts(),labels=df['Churn'].value_counts().index,autopct='%1.2f%%',explode=(0.1,0))
plt.title('Churn(Yes/No) Ratio')
Text(0.5, 1.0, 'Churn(Yes/No) Ratio')
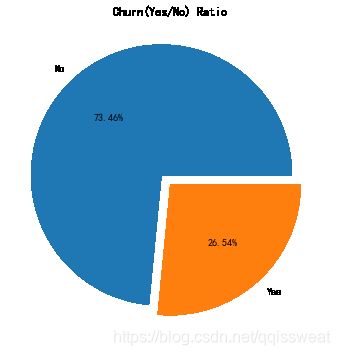
流失用户样本占比26.54%,留存用户样本占比73.5%,属于不平衡数据集。
5.2用户个人属性分析
个人属性包括性别、是否为老年人、是否有伴侣、是否有孩子。
fig=plt.figure(figsize=(6,4))
sns.countplot(x="gender",hue="Churn",data=df,hue_order=['No','Yes'])
plt.xlabel("gender")
plt.title("Churn by gender")
plt.legend(fontsize=12)
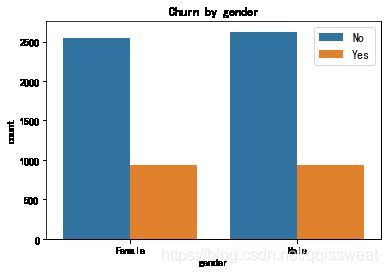
男性与女性用户之间的客户流失量基本无差异,说明性别对流失率影响几乎可以忽略。
fig=plt.figure(figsize=(6,4))
sns.countplot(x="SeniorCitizen",hue="Churn",data=df,hue_order=['No','Yes'])
plt.xlabel("SeniorCitizen")
plt.title("Churn by SeniorCitizen")
plt.legend(fontsize=12)
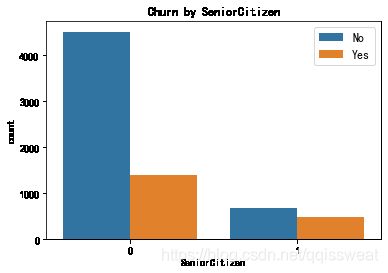
老年人群体的流失率明显高于一般群体,可以判断顾客是否为老年人与其流失的可能具有关联性。
items=["Partner","Dependents"]
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,4))
for i,item in enumerate(items):
plt.subplot(1,2,(i+1))
ax=sns.countplot(x=item,hue="Churn",data=df,hue_order=['No','Yes'],order=["Yes","No"])
plt.xlabel(str(item))
plt.title("Churn"+' '+'by'+' '+str(item))
plt.legend(fontsize=10)
i+=1
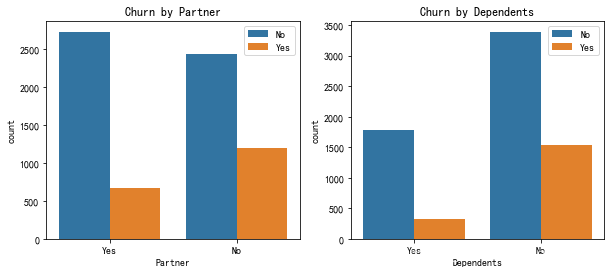
可以看出有伴侣的用户流失占比低于无伴侣用户;
有孩子的用户较少,且有孩子的用户流失占比低于无孩子用户。
5.3服务属性分析
对于本例的电信公司而言,其主要的产品可以分为电话服务和网络服务两类。然后在这两类服务基础上提供一些附加服务,包括多线程服务、在线安全服务、在线备份服务、设备保护服务、技术支持服务、流媒体电视服务、流媒体电影服务。
df['churn_rate'] = df['Churn'].replace("No", 0).replace("Yes", 1)
items=["PhoneService","InternetService"]
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,4))
for i,item in enumerate(items):
plt.subplot(1,2,(i+1))
ax=sns.barplot(x=item,y="churn_rate",data=df)
plt.rcParams.update({
'font.size': 14})
plt.xlabel(str(item))
plt.ylabel("Churn Rate")
plt.title("Churn By "+str(item))
i+=1
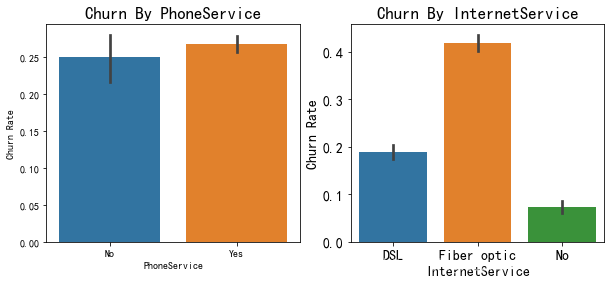
由图一可以看出是否开通电话服务对用户流失影响不大;
在第二幅图中,开通网络服务的用户的流失率明显高于没有开通网络服务的顾客,尤其是采用光纤网络技术(Fiber optic)的用户,流失率超过40%。推断这项服务存在一定的问题,是急需改进的一项服务。
针对网络服务,我们可以进一步探讨拥有其他的附加服务是否会影响了用户的流失情况。
items=["OnlineSecurity","OnlineBackup","DeviceProtection","TechSupport","StreamingTV", "StreamingMovies"]
fig,axes=plt.subplots(nrows=2,ncols=3,figsize=(16,10))
for i,item in enumerate(items):
plt.subplot(2,3,(i+1))
ax=sns.barplot(x=item,y="churn_rate",data=df,order=['Yes','No','No internet service'])
plt.rcParams.update({
'font.size': 12})
plt.xlabel(str(item))
plt.title("Churn By "+str(item))
i+=1
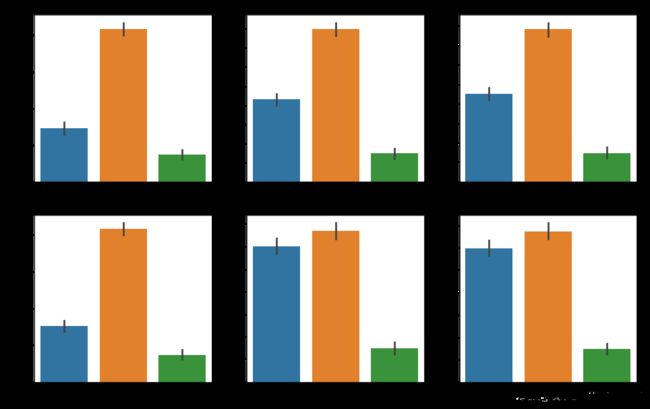
可以发现,使用网络服务的客户,如果继续付费开通网络安全、网络备份、设备保护、技术支持等附加性服务,会有效降低其流失的可能性。
由此我们可以知道,虽然该电信公司的基础网络服务具有一定的问题,但是通过附加服务的补充,可以有效降低因服务问题所带来的流失。
5.4行为属性分析
用户行为属性包括已使用时间、合同期限、付款方式、是否使用电子账单、月消费金额、总消费金额。
# Kernel density estimaton核密度估计
def kdeplot(feature,xlabel):
plt.figure(figsize=(8, 6))
plt.title("KDE for {0}".format(feature))
ax0 = sns.kdeplot(df[df['Churn'] == 'No'][feature], label= 'Churn: No', shade='True')
ax1 = sns.kdeplot(df[df['Churn'] == 'Yes'][feature], label= 'Churn: Yes',shade='True')
plt.xlabel(xlabel)
plt.rcParams.update({
'font.size': 16})
plt.legend(fontsize=12)
kdeplot('tenure','tenure')
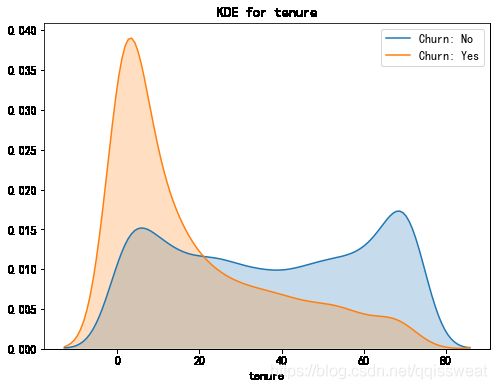
相对而言,使用年限越长的客户,流失的可能性就越小。
items=["Contract","PaperlessBilling"]
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(12,6))
for i,item in enumerate(items):
plt.subplot(1,2,(i+1))
ax=sns.barplot(x=item,y="churn_rate",data=df)
plt.rcParams.update({
'font.size': 14})
plt.title("Churn By "+str(item))
i+=1
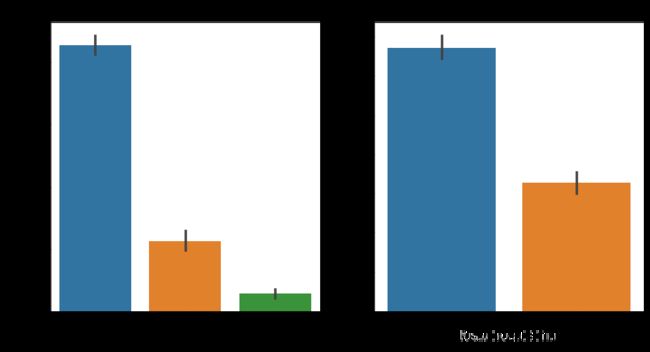
左图可以明显可以看出,签订合同方式对客户流失率影响为:按月签订 > 按一年签订 > 按两年签订,签订的合同期限越长,流失率越低;
右图表明使用无纸化账单的用户流失率高于不使用无纸化账单的用户,猜测其原因可能是用户看到账单后,容易对消费金额不满,进而导致用户流失。
plt.figure(figsize=(12, 6))
sns.barplot(x='PaymentMethod',y='churn_rate',data=df,order=['Electronic check','Mailed check','Bank transfer (automatic)','Credit card (automatic)'])
plt.rcParams.update({
'font.size': 12})
plt.title("Churn By PaymentMethod")
Text(0.5, 1.0, 'Churn By PaymentMethod')
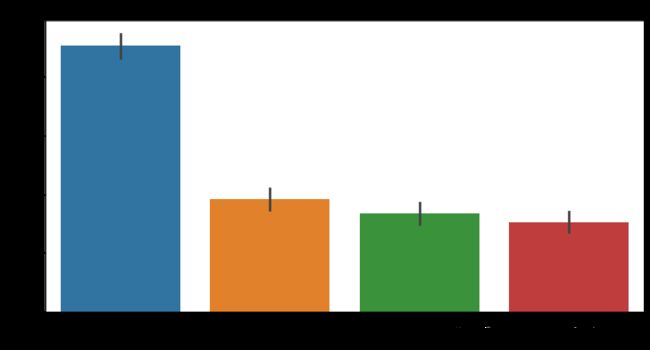
可以看出,在支付方式方面,采用电子支票支付的顾客的流失率明显高于其他支付方式的顾客,推测该方式的使用体验较为一般。
kdeplot('MonthlyCharges','MonthlyCharges')
kdeplot('TotalCharges','TotalCharges')
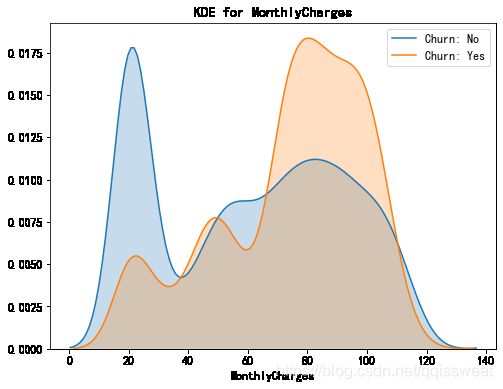
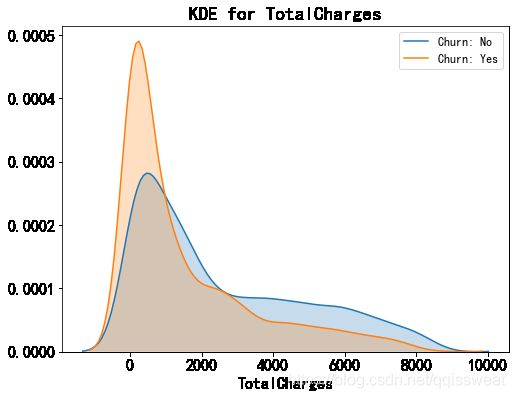
可以看出,月消费额大约在70-110之间用户流失率较高;
从长期来看,用户总消费越高,流失率越低,符合一般经验。
5.5小结
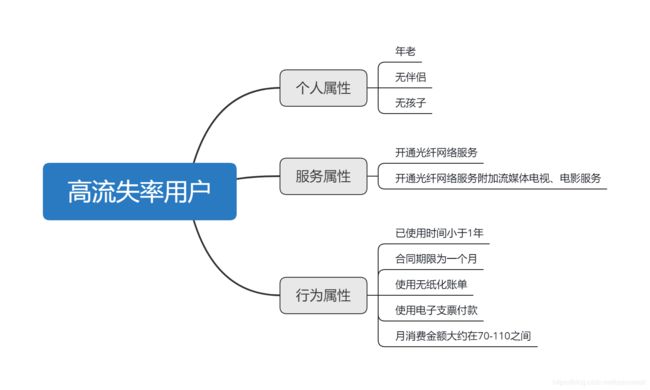
通过以上分析,在20个输入特征中,目前认为与客户流失关联性较大的指标包括16个:是否为老年人,是否有伴侣,是否有孩子,是否使用网络服务,以及在使用了网络服务的情况下是否使用在线安全、在线备份、设备保护、技术支持、流媒体电视、流媒体电影服务,已使用时间,合同期限,是否使用无纸化账单、付款方式,月消费金额、总消费金额。
可以得到较高流失率的人群特征,需要有针对性的对具有这些特征的人群进行运营,增加用户黏性,延长其生命周期价值。
六、构建预测模型
6.1特征离散化
离散化后的特征对异常数据有更强的鲁棒性,降低过拟合的风险,模型会更稳定,预测的效果也会更好。
df1=df.copy()
df1.drop(["customerID","gender","PhoneService","MultipleLines","churn_rate"],axis=1,inplace=True)
df1['tenure']=pd.qcut(df1['tenure'],6,labels=['1','2','3','4','5','6'])
df1['MonthlyCharges'].describe()
count 7043.000000
mean 64.761692
std 30.090047
min 18.250000
25% 35.500000
50% 70.350000
75% 89.850000
max 118.750000
Name: MonthlyCharges, dtype: float64
离散操作
18.25= 35.5 70.35 89.85= 离散操作: 18= 402 1397 3786 因为在用户开通网络服务的基础上,在线安全、网络备份、设备保护、技术支持等附加服务特征只需区分用户是否开通该项附加服务即可, 故可以将 6个特正中的“No internetserive” 并到 “No”里面,然后采用0-1变量进行编码 采用欠采样的方式进行处理 可以看到最终模型f1得分,最高分是“XGB”模型的0.83 最终我们选取xgb模型进行用户流失预测。由于没有预测数据集,选择最后10条数为例进行预测。 基于“XGB”模型输出特征重要性 根据以上分析,我们可以大致得到高流失率用户的特征: 针对上述结论,从业务角度给出相应建议: 用户方面:针对老年用户推出定制服务如家庭套餐、温暖套餐等,一方面可以加强与其它用户的关联度,另一方还可以有针对性的对特定用户提供个性化服务;针对无伴侣、无孩子用户推出单人狂欢套餐,我们可以根据单身人士常见的消遣方式:看综艺、刷短视频、看小说、玩游戏等,在套餐中增加这些福利。 服务方面:对于光纤用户和附加流媒体电视、电影服务用户,重点在于提升其网络体验、增值服务体验,一方面推动技术部门提升网络服务,另一方面对用户承诺免费网络升级和赠送电视、电影等资源包月服务以提升用户黏性。针对在线安全、在线备份、设备保护、技术支持等增值服务,应重点对开通了网络服务的用户进行推广介绍,如首月免费体验、冲话费赠送一个月免费体验机会等,引导用户开通相应服务。 行为方面:针对新注册用户,推送签订一年及以上期限合同可以享有的优惠活动如赠送礼品券,话费立减等以渡过用户流失高峰期。针对单月合同用户,建议推出年合同付费折扣活动,将月合同用户转化为年合同用户,提高用户在本平台的沉没成本,以达到更高的用户留存。 针对采用电子支票付款的用户,建议定向推送其它支付方式的优惠券,引导用户改变支付方式。优化电子账单展示方式,可以根据用户账单金额在给用户推送账单时同时推送下个月消费满多少减多少或可以直接使用的无门槛优惠券,以达到挽留即将流失用户的作用。 最后可以根据预测模型,构建一个高流失率的用户列表。通过理论分析结合用户调研推出一个最小可行化产品功能,并邀请种子用户进行试用。在小范围验证了产品可行性的基础上,后续再扩大产品覆盖范围。#用四分位数进行离散
df1['MonthlyCharges']=pd.qcut(df1['MonthlyCharges'],4,labels=['1','2','3','4'])
df1['TotalCharges'].describe()
count 7043.000000
mean 2279.798992
std 2266.730170
min 18.800000
25% 398.550000
50% 1394.550000
75% 3786.600000
max 8684.800000
Name: TotalCharges, dtype: float64
#用四分位数进行离散
df1['TotalCharges']=pd.qcut(df1['TotalCharges'],4,labels=['1','2','3','4'])
6.2特征编码
df1.replace(to_replace='No internet service',value='No',inplace=True)
# 分类特征编码
df1['Churn']=df1['Churn'].map({
'Yes':1,'No':0})
df_object=['SeniorCitizen', 'Partner', 'Dependents',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport',
'StreamingTV', 'StreamingMovies', 'PaperlessBilling']
def labelencode(x):
df1[x] = LabelEncoder().fit_transform(df1[x])
for i in df_object:
labelencode(i)
#df1.head()
#数值特征编码
df1=pd.get_dummies(df1,columns=["tenure","Contract","InternetService","PaymentMethod","MonthlyCharges","TotalCharges"])
df1.head()
SeniorCitizen
Partner
Dependents
OnlineSecurity
OnlineBackup
DeviceProtection
TechSupport
StreamingTV
StreamingMovies
PaperlessBilling
Churn
tenure_1
tenure_2
tenure_3
tenure_4
tenure_5
tenure_6
Contract_Month-to-month
Contract_One year
Contract_Two year
InternetService_DSL
InternetService_Fiber optic
InternetService_No
PaymentMethod_Bank transfer (automatic)
PaymentMethod_Credit card (automatic)
PaymentMethod_Electronic check
PaymentMethod_Mailed check
MonthlyCharges_1
MonthlyCharges_2
MonthlyCharges_3
MonthlyCharges_4
TotalCharges_1
TotalCharges_2
TotalCharges_3
TotalCharges_4
0
0
1
0
0
1
0
0
0
0
1
0
1
0
0
0
0
0
1
0
0
1
0
0
0
0
1
0
1
0
0
0
1
0
0
0
1
0
0
0
1
0
1
0
0
0
0
0
0
0
0
1
0
0
0
1
0
1
0
0
0
0
0
1
0
1
0
0
0
0
1
0
2
0
0
0
1
1
0
0
0
0
1
1
1
0
0
0
0
0
1
0
0
1
0
0
0
0
0
1
0
1
0
0
1
0
0
0
3
0
0
0
1
0
1
1
0
0
0
0
0
0
0
1
0
0
0
1
0
1
0
0
1
0
0
0
0
1
0
0
0
0
1
0
4
0
0
0
0
0
0
0
0
0
1
1
1
0
0
0
0
0
1
0
0
0
1
0
0
0
1
0
0
0
1
0
1
0
0
0
df1.shape
(7043, 35)
6.3样本不均衡处理
df2=df1.copy()
df2.drop("Churn",axis=1,inplace=True)
from imblearn.over_sampling import SMOTE
model_smote=SMOTE()
x=df2
y=df1['Churn'].values
x,y=model_smote.fit_sample(x,y)
x=pd.DataFrame(x,columns=df2.columns)
#分拆训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=0)
Classifiers=[["Random Forest",RandomForestClassifier()],
["Support Vector Machine",SVC()],
["LogisticRegression",LogisticRegression()],
["Naive Bayes",GaussianNB()],
["Decision Tree",DecisionTreeClassifier()],
["AdaBoostClassifier", AdaBoostClassifier()],
["GradientBoostingClassifier", GradientBoostingClassifier()],
["XGB", XGBClassifier()] ]
Classify_result=[]
names=[]
prediction=[]
for name,classifier in Classifiers:
classifier=classifier
classifier.fit(x_train,y_train)
y_pred=classifier.predict(x_test)
recall=recall_score(y_test,y_pred)
precision=precision_score(y_test,y_pred)
f1score = f1_score(y_test, y_pred)
class_eva=pd.DataFrame([recall,precision,f1score])
Classify_result.append(class_eva)
name=pd.Series(name)
names.append(name)
y_pred=pd.Series(y_pred)
prediction.append(y_pred)
names=pd.DataFrame(names)
names=names[0].tolist()
result=pd.concat(Classify_result,axis=1)
result.columns=names
result.index=["recall","precision","f1score"]
result
Random Forest
Support Vector Machine
LogisticRegression
Naive Bayes
Decision Tree
AdaBoostClassifier
GradientBoostingClassifier
XGB
recall
0.865854
0.872272
0.842105
0.830552
0.845956
0.813222
0.853659
0.878049
precision
0.799171
0.788741
0.799512
0.750145
0.773021
0.782099
0.772807
0.798599
f1score
0.831177
0.828406
0.820256
0.788303
0.807846
0.797357
0.811223
0.836441
model = XGBClassifier()
model.fit(x_train,y_train)
pred_id=df.customerID[-10:]
pred_x = df1.drop(['Churn'],axis=1).tail(10)
pred_y = model.predict(pred_x)
predDf = pd.DataFrame({
'customerID':pred_id, 'Churn':pred_y})
print(predDf)
customerID Churn
7033 9767-FFLEM 0
7034 0639-TSIQW 1
7035 8456-QDAVC 0
7036 7750-EYXWZ 0
7037 2569-WGERO 0
7038 6840-RESVB 0
7039 2234-XADUH 0
7040 4801-JZAZL 1
7041 8361-LTMKD 1
7042 3186-AJIEK 0
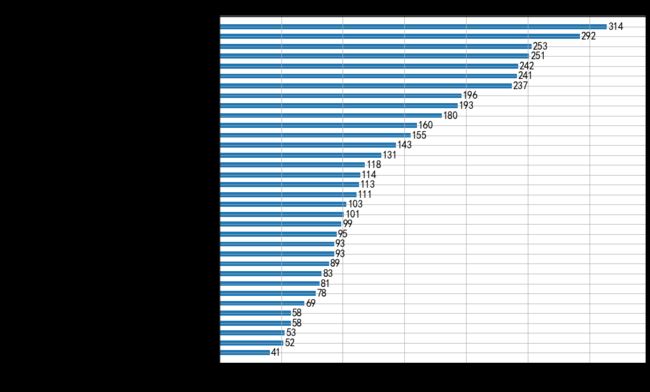
from xgboost import plot_importance
model_xgb= XGBClassifier()
model_xgb.fit(x_train,y_train)
plt.rcParams["figure.figsize"] = (12, 10)
plot_importance(model_xgb,height=0.5)
七、结论和建议
用户属性:老年,未婚、未育;
服务属性:开通光纤服务/光纤附加流媒体电视、电影服务;
行为属性:已使用时间小于一年,签订的合同期限较短,采用电子支票支付,使用电子账单,月消费金额约在70-110元之间;
其它属性对用户流失影响较小。