Flink/Blink 原理漫谈(五)流式计算的持续查询实现 详解
系列文章目录
Flink/Blink 原理漫谈(零)运行时的组件
Flink/Blink 原理漫谈(一)时间,watermark详解
Flink/Blink 原理漫谈(二)流表对偶性和distinct详解
Flink/Blink 原理漫谈(三)state 有状态计算机制 详解
Flink/Blink 原理漫谈(四)window机制详解
Flink/Blink 原理漫谈(五)流式计算的持续查询实现 详解
Flink/Blink 原理漫谈(六)容错机制(fault tolerance)详解
文章目录
- 系列文章目录
- 持续查询
-
- 静态查询和动态查询的关系
- 持续查询的实现
-
- 增量计算:
- APPEND ONLY场景
- UPDATE 场景
-
- 无PK的Append Only 场景
- 有PK的Update 场景
- Blink store
-
- 双流join中遇到的append only的问题
- Blink Sink
持续查询
静态查询和动态查询的关系
传统数据库表我们这里叫Static table,是指在查询的那一刻数据库表的内容不再变化了,查询进行一次计算完成之后表的变化也与本次查询无关了,我们将在Static Table 上面的查询叫做静态查询。连续查询发生在流计算上面,流表对偶性中我们提到过Dynamic Table,连续查询是作用在Dynamic table上面的,永远不会结束的,随着表内容的变化计算在不断的进行着。
在语义上 持续查询 中的每一次查询计算的触发都是一次静态查询(相对于当时查询的时间点), 在实现上 Blink会利用上一次查询结果+当前记录 以增量的方式完成查询计算。Blink上面的持续查询内部实现是增量处理,随着时间的推移,每条数据的到来实时处理当前的那一条记录,不会再处理曾经来过的历史记录!!
持续查询的实现
一句话概括就是,在一个动态表上不断地进行查询,并且将结果用增量计算的方式进行存储。
下面进行增加计算的介绍。
增量计算:
在持续查询的计算过程中,Blink采用增量计算的方式,也就是每次计算都会将计算结果存储到state中,下一条事件到来的时候利用上次计算的结果和当前的事件进行聚合计算。

APPEND ONLY场景
统计订单数量和总金额的场景,订单表本身是一个append only的数据源(假设没有更新,截止到2018.5.14日,blink内部支持的数据源都是append only的),在持续查询过程中经过count(id),sum(amount)统计计算之后产生的动态表也是append only的,种场景blink内部只需要进行aggregate function的聚合统计计算就可以
用人话解释就是,这种类型的场景,数据只是进行一个类似累加的过程,它只会单调递增,不会存在回撤,取消这种操作。

UPDATE 场景
这部分文档中写的很好,下面搬运一下:
无PK的Append Only 场景
在实际的业务场景中,我们只需要进行简单的数据统计,然后就将统计结果写入的业务的数据存储系统里面,比如上面统计订单数量和总金额的场景,订单表本身是一个append only的数据源(假设没有更新,截止到2018.5.14日,blink内部支持的数据源都是append only的),在持续查询过程中经过count(id),sum(amount)统计计算之后产生的动态表也是append only的,种场景blink内部只需要进行aggregate function的聚合统计计算就可以,如下:

有PK的Update 场景
现在我们将上面的订单场景稍微变化一下,在数据表上面我们将金额字段amount,变为地区字段region,数据如下:
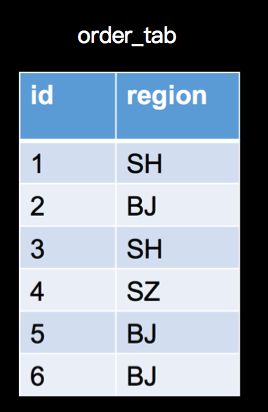
查询统计的变为,在计算具有相同订单数量的地区数量;查询SQL如下:
CREATE TABLE order_tab(
id BIGINT,
region VARCHAR
) WITH (
type='xxx'
);
CREATE TABLE region_count_sink(
order_cnt BIGINT,
region_cnt BIGINT,
PRIMARY KEY(order_cnt) -- 主键
) WITH (
type = 'print'
);
-- 按地区分组计算每个地区的订单数量
CREATE VIEW order_count_view AS
SELECT
region, count(id) AS order_cnt
FROM order_tab
GROUP BY region;
-- 按订单数量分组统计具有相同订单数量的地区数量
INSERT INTO region_count_sink
SELECT
order_cnt,
count(region) as region_cnt
FROM order_count_view
GROUP BY order_cnt;
上面查询SQL的代码结构如下:

上面SQL中我们发现有两层查询计算逻辑,第一个查询计算逻辑是与SOURCE向连的按地区统计订单数量的分组统计,第二个查询计算逻辑是在第一个查询产出的动态表上面进行按订单数量统计地区数量的分组统计,我们一层一层分析。
错误处理
• 第一层分析:SELECT region, count(id) AS order_cnt FROM order_tab GROUP BY region;
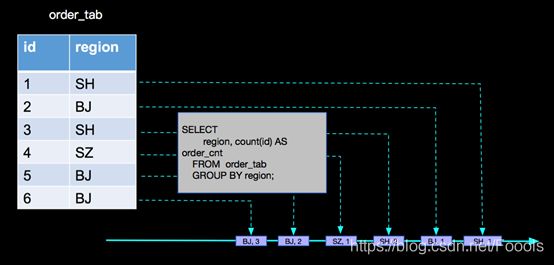 第二层分析:SELECT order_cnt, count(region) as region_cnt FROM order_count_view GROUP BY order_cnt;
第二层分析:SELECT order_cnt, count(region) as region_cnt FROM order_count_view GROUP BY order_cnt;
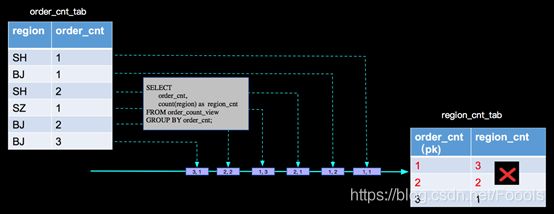
按照第一层分析的结果,再分析第二层产出的结果,我们分析的过程是对的,但是最终写到sink表的计算结果是错误,那我们错在哪里了呢?
其实当 (SH,2)这条记录来的时候,以前来过的(SH, 1)已经是脏数据了,当(BJ, 2)来的时候,已经参与过计算的(BJ, 1)也变成脏数据了,同样当(BJ, 3)来的时候,(BJ, 2)也是脏数据了,上面的分析,没有处理脏数据进而导致最终结果的错误。那么blink内部是如何正确处理的呢?
正确处理
• 第一层分析:SELECT region, count(id) AS order_cnt FROM order_tab GROUP BY region;

第二层分析:SELECT order_cnt, count(region) as region_cnt FROM order_count_view GROUP BY order_cnt;

上面我们将有更新的事件进行打标的方式来处理脏数据,这样在blink内部计算的时候 算子会根据事件的打标来处理事件,在aggregate function中有两个对应的方法(retract和accumulate)来处理不同标识的事件,如上面用到的count AGG,内部实现如下:
def accumulate(acc: CountAccumulator): Unit = {
acc.f0 += 1L // acc.f0 存储记数
}
def retract(acc: CountAccumulator, value: Any): Unit = {
if (value != null) {
acc.f0 -= 1L //acc.f0 存储记数
}
}
blink内部这种为事件进行打标的机制叫做 retraction。retraction机制保障了在流上已经流转到下游的脏数据需要被撤回问题,进而保障了持续查询的正确语义。
补充:这种retraction机制在有些实时计算场景下反而会起到负面作用,举例来说group by
Window统计信息的时候,retract信息也会被统计在内,这时候就需要使用over窗口或其他方法来实现。
Blink store
目前在可以用于数据流驱动的Source Connector上面无法定义PK,而sink上是可以选择定义PK与否的,源表中无法定义primary key会导致一些问题,在下面有详细的介绍,而在sink中选择是否定义primary key也会导致不同的输出结果。
双流join中遇到的append only的问题
首先用大白话解释一下,在source上是没有primary key的,这时候遇到有数据更新,可能就在其中一条流的state中存下了很多垃圾信息,这些垃圾信息会被另一条流join在一起,这样的结果就是会输出很多垃圾信息,然后我们如果将join的条件做一个groupby操作,就可以杜绝这种情况。
上代码
CREATE TABLE inventory_tab(
product_id VARCHAR,
product_count BIGINT
) WITH (
type='tt'
) ;
CREATE TABLE sales_tab(
product_id VARCHAR,
sales_count BIGINT
) WITH (
type='tt'
) ;
CREATE TABLE join_sink(
product_id VARCHAR,
product_count BIGINT,
sales_count BIGINT,
PRIMARY KEY(product_id)
)WITH (
type = 'print'
) ;
CREATE VIEW join_view AS
SELECT
l.product_id,
l.product_count,
r.sales_count
FROM inventory_tab l
JOIN sales_tab r
ON l.product_id = r.product_id;
INSERT INTO join_sink
SELECT
product_id,
product_count,
sales_count
FROM join_view ;
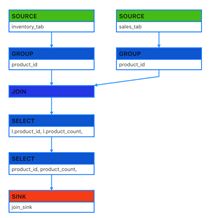
代码结构图如下:

双流JOIN的底层实现会将左(L)右®两面的数据都持久化到Blink的State中,当L流入一条事件,首先会持久化到LState,然后在和RState中存储的R中所有事件进行条件匹配,这样的逻辑如果R流product_id为P001的产品销售记录已经流入4条,L流的(P001, 48) 流入的时候会匹配4条事件流入下游(join_sink)。
上面的问题根本上我们要构建一张有PK的动态表,这样按照业务PK进行更新处理,我们可以在Source后面添加group by 操作生产一张有PK的动态表。如下:
CREATE TABLE inventory_tab(
product_id VARCHAR,
product_count BIGINT
) WITH (
type='tt'
) ;
CREATE TABLE sales_tab(
product_id VARCHAR,
sales_count BIGINT
) WITH (
type='tt'
) ;
CREATE VIEW inventory_view AS
SELECT
product_id,
LAST_VALUE(product_count) AS product_count
FROM inventory_tab
GROUP BY product_id;
CREATE VIEW sales_view AS
SELECT
product_id,
LAST_VALUE(sales_count) AS sales_count
FROM sales_tab
GROUP BY product_id;
CREATE TABLE join_sink(
product_id VARCHAR,
product_count BIGINT,
sales_count BIGINT,
PRIMARY KEY(product_id)
)WITH (
type = 'print'
) ;
CREATE VIEW join_view AS
SELECT
l.product_id,
l.product_count,
r.sales_count
FROM inventory_view l
JOIN sales_view r
ON l.product_id = r.product_id;
INSERT INTO join_sink
SELECT
product_id,
product_count,
sales_count
FROM join_view ;
代码结构图如下:
Blink Sink
在Blink上面可以根据实际外部存储的特点(是否支持PK)来在Blink内部的DDL中为Sink进行PK的定义。Blink中用户可感知的有两种:
• Append 模式 - 该模式用户在定义Sink的DDL时候不定义PK,在blink内部生成的所有只有INSERT语句
• Upsert 模式 - 该模式用户在定义Sink的DDL时候可以定义PK,在blink内部会根据事件打标(retract机制)生成INSERT/UPDATE和DELET 语句,其中如果定义了PK, UPDATE语句按PK进行更新,如果没有定义PK UPDATE会按整行更新