Blink文档阅读笔记(3):aggregation 聚合的语法 group window,over window
系列文章目录
Blink文档阅读笔记(1):DDL与DML
Blink文档阅读笔记(2):Query语句
Blink文档阅读笔记(3):aggregation 聚合的语法 group window,over window
文章目录
- 系列文章目录
- AGGREGATIONS
-
- Group Aggregation
- Group Window Aggregation
-
- 滚动窗口
- 滑动窗口
- 会话窗口
- Over Window Aggregation
-
- Rows over window
- Range over window
AGGREGATIONS
blink 支持三种类型(语法)的聚合,分别是 Group Aggregation, Group Window Aggregation, Over Window Aggregation。具体的语法参考文档
https://yuque.antfin-inc.com/rtcompute/doc/sql-query-group-by
https://help.aliyun.com/document_detail/62510.html?spm=a2c4g.11186623.6.770.52a8303dvKHpp3
Group Aggregation
Group Aggregation 是一种在无限流上的聚合,由于没有窗口,是无限大窗口上的聚合,所以计算模式是每到达一条数据就会增量计算一次,并发出更新后的结果。
具体语法和sql的group by没区别,这里不展开说了。
Group Window Aggregation
是一种在窗口上的聚合。区别于上文的 Group Aggregation,Group Window Aggregation 是每个窗口结束发出一条结果数据(无early fire时),有点类似 micro batch。 最常见的是几种时间窗口,如 TUMBLE(滚动窗口), HOP(滑动窗口), SESSION(会话窗口)。例如有用户想统计在过去的1分钟内有多少用户点击了某个的网页。在这种情况下,我们可以定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
具体语法:
滚动窗口
INSERT INTO tumble_output
SELECT
TUMBLE_START(ts, INTERVAL '1' MINUTE),
TUMBLE_END(ts, INTERVAL '1' MINUTE),
username,
COUNT(click_url)
FROM window_input
GROUP BY TUMBLE(ts, INTERVAL '1' MINUTE), username
滑动窗口
INSERT INTO tumble_output
SELECT
HOP_START(ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE),
HOP_END(ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE),
username,
COUNT(click_url)
FROM window_input
GROUP BY HOP(ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE), username
会话窗口
INSERT INTO tumble_output
SELECT
SESSION_START(ts, INTERVAL '30' SECOND),
SESSION_END(ts, INTERVAL '30' SECOND),
username,
COUNT(click_url)
FROM window_input
GROUP BY SESSION(ts, INTERVAL '30' SECOND), username
Over Window Aggregation
Over Window Aggregation 是传统数据库中一个非常常用的统计聚合功能。Over Window Aggregation 区别于上面两种 Aggregation 的最核心的区别是 Over Window Aggregation 从语义上保障了对每个输入都有一个输出,因此常被用于ranking,moving average等场景。
具体语法:
Rows over window
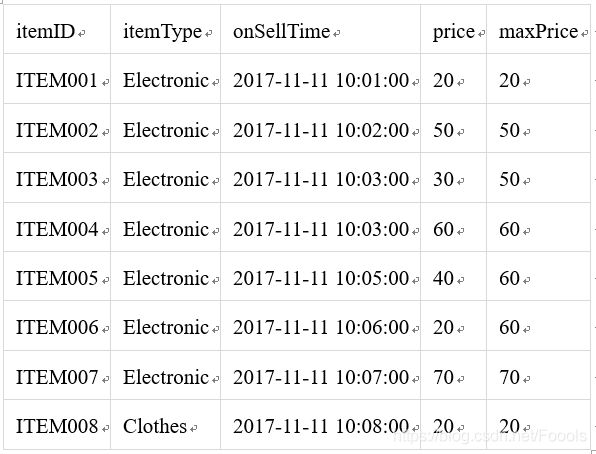
以Bounded ROWS OVER Window场景示例,假设有一张天猫商品上架表,有商品ID,商品类型,商品上架时间,商品价格,假设我们求比当前商品上架之前同类的3个商品中的最高价格。
测试数据:
DDL:
CREATE TABLE tmall_item(
itemID VARCHAR,
itemType VARCHAR,
onSellTime TIMESTAMP,
price DOUBLE
WATERMARK onSellTime FOR onSellTime as withOffset(onSellTime, 0)
)
WITH (
type = 'sls',
...
) ;
SELECT
itemID,
itemType,
onSellTime,
price,
MAX(price) OVER (
PARTITION BY itemType
ORDER BY onSellTime
ROWS BETWEEN 2 preceding AND CURRENT ROW) AS maxPrice
FROM tmall_item
结果:
Range over window
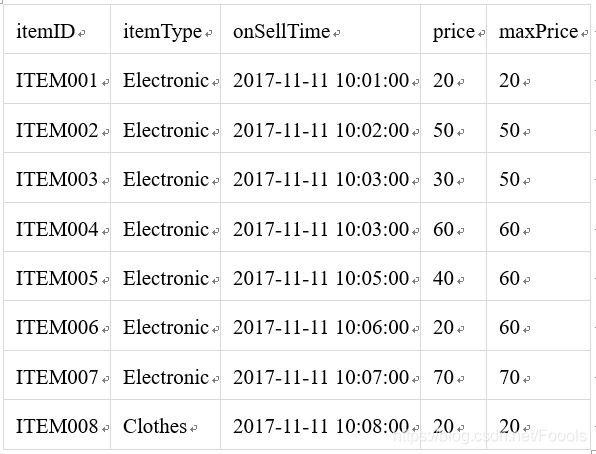
以Bounded RANGE OVER Window场景示例,假设有一张天猫商品上架表,有商品ID,商品类型,商品上架时间,商品价格,假设我们求比当前商品上架时间早2分钟的同类商品中的最高价格。
测试数据:
DDL:
CREATE TABLE tmall_item(
itemID VARCHAR,
itemType VARCHAR,
onSellTime TIMESTAMP,
price DOUBLE
WATERMARK onSellTime FOR onSellTime as withOffset(onSellTime, 0)
)
WITH (
type = 'sls',
...
) ;
SELECT
itemID,
itemType,
onSellTime,
price,
MAX(price) OVER (
PARTITION BY itemType
ORDER BY onSellTime
RANGE BETWEEN INTERVAL '2' MINUTE preceding AND CURRENT ROW) AS maxPrice
FROM tmall_item
结果:
