7、python元组&字典——旺仔
python:元组&字典
- 1、数据结构简介
- 2、元组tuple
-
- 2.1、元组简介
- 2.2、元组的表达形式及创建
- 2.3、拆包
- 3、字典dict
-
- 3.1、字典简介
- 3.2、字典创建
- 3.3、字典的修改(增删改查)
-
- 3.3.1、len()
- 3.3.2、in 与 not in
- 3.3.3、获取值
- 3.3.4、修改字典
- 3.3.5、dict.setdefault添加key-value
- 3.3.6、dict.update()
- 3.3.7、del 关键字删除
- 3.3.8、dict.popitem()随机删除
- 3.3.9、dict.pop 删除
- 3.3.10、清空字典
- 3.4、字典的遍历
- 4、深拷贝和浅拷贝
-
- 4.1、什么是深拷贝和浅拷贝?
- 4.2、实际操作
- 5、课后作业
-
- 5.1、第一题
- 5.2、第二题
- 6、附加(个人练习题——字典)
-
- 统计1000个随机数中重复的数字
- 旺仔注:

1、数据结构简介
- 数据结构(Data Structures)基本上人如其名——它们只是一种结构,能够将一些数据聚合 在一起。换句话说,它们是用来存储一系列相关数据的集合。
- Python中有四种内置的数据结构——列表(List)、元组(Tuple)、字典(Dictionary)和集合(Set)
- 列表在上一章博客。本章博客中将介绍元组(Tuple)、字典(Dictionary)。
2、元组tuple
2.1、元组简介
元组用于将多个对象保存到一起,近似看作列表,但是元组不能提供列表类广泛的功能,
元组类似于字符串,不可变,不能修改元组。指定项目时,给他们加上括号,并在括号内部使用逗号进行分隔。
- 元组表现形式tuple
- 元组是一个不可变序列(一般当我们希望数据不改变时,我们使用元组,其他情况下基本都用列表)
- 使用()创建元素
- 元组不是空元组至少有一个 逗号(,) 当元组不是空元组时括号可以省略
- 元组解包指将元组当中的每一个元素都赋值给一个变量
2.2、元组的表达形式及创建
- 元组内的数据是不可变话的,不可更改的, 在不希望数据发生改变的时候我们就用元组,其余的情况都用列表
# 元组的表达形式 () tuple
tuple1 = (1, 2, 3, 4, 5)
print(tuple1, type(tuple1))
# 运行结果 》》》(1, 2, 3, 4, 5)
print(tuple1[2])
# 运行结果 》》》3
print(tuple1[2::])
# 运行结果 》》》(3, 4, 5)
# 如果元组不是一个空元祖,那么它必须得有一个逗号
tuple2 = 6,
tuple3 = (6)
print(tuple2, type(tuple2))
# 运行结果 》》》(6,)
print(tuple3, type(tuple3))
# 运行结果 》》》6
如上所示,元组的使用方法基本上和列表相似,但是列表的增删改查在这里只能用查,除了一些通用的方法,其他的列表操作都不适合元组,比如切片的使用就可以,但是列表的append和remove等方法就不可用。并且在创建元组时必须用(),然后还要至少加上一个,(逗号)。
2.3、拆包
- 拆包的时候如果有*, 那么有且只能有一个*, *接受参数之后,结果是用一个列表来放置的、
实际用法:
- 元组的拆包
tuple4 = (1, 2, 3, 4)
*a, b, c = tuple4
print(a, b, c)
# 运行结果 》》》[1, 2] 3 4
a, *b, c = tuple4
print(a, b, c)
# 运行结果 》》》1 [2, 3] 4
a, b, *c = tuple4
print(a, b, c)
# 运行结果 》》》1 2 [3, 4]
- 字符串的拆包
a = 'abcde'
b, *c= a
print(b, c)
# 运行结果 》》》a ['b', 'c', 'd', 'e']
*b, c= a
print(b, c)
# 运行结果 》》》['a', 'b', 'c', 'd'] e
- 列表的拆包
list1 = [1, 2, 3, 4, 5]
a, *b = list1
print(a, b)
# 运行结果 》》》1 [2, 3, 4, 5]
*a, b = list1
print(a, b)
# 运行结果 》》》[1, 2, 3, 4] 5
3、字典dict
3.1、字典简介
字典:mapping 映射关系 key:value 一个字典中, 每一个key都是唯一的,我们只需要通过key就可以查找到我们需要的数据, key-value我们称之为键值对,也可以称呼它为一项item
将键值(Keys)与值(Values)联系到一起,键值必须是唯一的,成对的键值和值之间用冒号分割,每一对键值对使用逗号区分,全部由一对花括号括起。字典中的键值对不会以人为方式进行排序,只能在使用它们之前自行进行排序
3.2、字典创建
- 空字典的创建
dict1 = {}
print(dict1, type(dict1))
# 运行结果 》》》{}
- 字典赋值创建
dict2 = {
'姓名': '旺仔',
'年龄': 21,
'性别': '男',
'爱好': 'python'
}
print(dict2, type(dict2))
# 运行结果 》》》{'姓名': '旺仔', '年龄': 21, '性别': '男', '爱好': 'python'}
# 当字典中的key有重复的时候,后面的key-value会替换前面的
dict2 = {
'姓名': '旺仔',
'年龄': 21,
'性别': '男',
'爱好': 'python',
'爱好': '爬虫'
}
print(dict2, type(dict2))
# 运行结果 》》》{'姓名': '旺仔', '年龄': 21, '性别': '男', '爱好': '爬虫'}
- 使用dict类去创建字典
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
print(dict1, type(dict1))
# 运行结果 》》》{'姓名': '旺仔', '年龄': 21, '性别': '男'}
- dict双值子序列创建字典
dict2 = dict([('姓名', '旺仔'), ('年龄', 21), ('性别', '男')])
print(dict2, type(dict2))
# 运行结果 》》》{'姓名': '旺仔', '年龄': 21, '性别': '男'}
这里我们介绍一下什么是双值子序列, 首先我们看一下双值序列 ,
如列表[1, 2]就是双值序列,
再看一下什么是子序列,字符串'a'就可以作为一个子序列,
之后再看一下我们这里的双值子序列[(1, 2), (3, 4)]
简单一点来说呢,这个就是序列之间的嵌套,例如上面的列表与元组嵌套
3.3、字典的修改(增删改查)
3.3.1、len()
# len()
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
print(len(dict1))
# 运行结果 》》》3
3.3.2、in 与 not in
# in not in 检测的是key
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
print('姓名' in dict1)
# 运行结果 》》》True
print(21 in dict1)
# 运行结果 》》》False
3.3.3、获取值
# 使用key获取value dict[key] 如果不存在key则会报错
# dict.get(key) 不存在key不会报错
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
print(dict1.get('爱好'))
# 运行结果 》》》None
# print(dict1.dict['爱好']) 这样用就会报错
3.3.4、修改字典
# dict[key] = value
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
dict1['姓名'] = '大白'
print(dict1)
# 运行结果 》》》{'姓名': '大白', '年龄': 21, '性别': '男'}
3.3.5、dict.setdefault添加key-value
# 如果这个key已经存在于字典中,则返回value,不会对字典有影响,
# 如果不存在,则向字典中添加这个key,并设置value
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
result = dict1.setdefault('姓名', '大白')
print(result)
print(dict1)
# 运行结果 》》》
旺仔
{'姓名': '旺仔', '年龄': 21, '性别': '男'}
result = dict1.setdefault('爱好', 'python')
print(result)
print(dict1)
# 运行结果 》》》
python
{'姓名': '旺仔', '年龄': 21, '性别': '男', '爱好': 'python'}
3.3.6、dict.update()
# dict.update() 将其他字典中的key—value添加到当前字典中
d1 = {'男': 1}
d2 = {'女': 2}
d1.update(d2)
print(d1)
# 运行结果 》》》{'男': 1, '女': 2}
3.3.7、del 关键字删除
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
del dict1['姓名']
print(dict1)
# 运行结果 》》》{'年龄': 21, '性别': '男'}
3.3.8、dict.popitem()随机删除
# dict.popitem() 随机删除一个键值对,一般都会删除最后一个, 有一个返回值,就是你删除的对象,结果是一个元组
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
result = dict1.popitem()
print(result)
print(dict1)
# 运行结果 》》》
('性别', '男')
{'姓名': '旺仔', '年龄': 21}
3.3.9、dict.pop 删除
# dict.pop(key,[default]) 根据key来删除键值对, 返回值就是你删除key对应的value
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
result = dict1.pop('性别')
print(result)
print(dict1)
# 运行结果 》》》
男
{'姓名': '旺仔', '年龄': 21}
result = dict1.pop('爱好', '你删除的这个不存在')
print(result)
print(dict1)
# 运行结果 》》》
你删除的这个不存在
{'姓名': '旺仔', '年龄': 21}
3.3.10、清空字典
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
# dict.clear() 清空字典
dict1.clear()
print(dict1)
# 运行结果 》》》{}
3.4、字典的遍历
遍历这个概念在上一章的for循环中也提到过,当时是说列表可以当成遍历来使用,咱们这里的字典也同样可以哦,接下来我们讲讲字典如何遍历。
- 遍历的规则如下:
for i(迭代变量) in 序列(遍历的规则):
循环体
- 通过key来遍历 dict.keys()
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
for k in dict1.keys():
print(dict1[k])
# 运行结果 》》》
旺仔
21
男
- 通过value来遍历 dict.values()
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
for v in dict1.values():
print(v)
# 运行结果 》》》
旺仔
21
男
- 通过一项来进行遍历 dict.items()
dict1 = dict(姓名='旺仔',年龄=21,性别='男')
for k, v in dict1.items():
print(k, '=', v)
# 运行结果 》》》
姓名 = 旺仔
年龄 = 21
性别 = 男
4、深拷贝和浅拷贝
4.1、什么是深拷贝和浅拷贝?
- 都先作为做拷贝的对象必须是可变类型,如列表,字典
- 深拷贝
深拷贝主要是将另一个对象的属性值拷贝过来之后,另一个对象的属性值并不受到影响,因为此时它自己在堆中开辟了自己的内存区域,不受外界干扰。
深拷贝是在引用方面不同,深拷贝就是创建一个新的和原始字段的内容相同的字段,是两个一样大的数据段,所以两者的引用是不同的,之后的新对象中的引用型字段发生改变,不会引起原始对象中的字段发生改变。
- 浅拷贝
浅拷贝主要拷贝的是对象的引用值,当改变对象的值,另一个对象的值也会发生变化。
浅拷贝是将原始对象中的数据型字段拷贝到新对象中去,将引用型字段的“引用”复制到新对象中去,不把“引用的对象”复制进去,所以原始对象和新对象引用同一对象,新对象中的引用型字段发生变化会导致原始对象中的对应字段也发生变化。
- 总结一下
深拷贝主要是将另一个对象完全复制一遍,开辟自己的内容区域,即使更改也与原本的对象没有如何关系。
浅拷贝主要拷贝的是对象的引用值,就是把他的地址拿过来,自然而然随着值的更改,原对象的值也会更改。
4.2、实际操作
- 浅拷贝
import copy
dict1 = {'1': 1, '2': 2}
dict2 = {'1': 1, '2': 2}
print(id(dict1), id(dict2))
# 运行结果 》》》1588506094688 1588506094760
dict1 = {'1': 1, '2': 2, 'list1': [1, 2, 3, {'name': [12, 23]}]}
dict2 = copy.copy(dict1)
print(id(dict1), id(dict2))
# 运行结果 》》》1588507018296 1588506094688
dict2 = dict1.copy()
print(id(dict1['list1']), id(dict2['list1']))
# 运行结果 》》》1588508504648 1588508504648
浅拷贝只能对第一层的数据进行拷贝,如果,第一层的数据也是个可变类型,那么浅拷贝无法将这个数据重新拷贝一份形成新的id
- 深拷贝
import copy
dict1 = {'1': 1, '2': 2, 'list1': [1, 2, 3, {'name': [12, 23]}]}
dict3 = copy.deepcopy(dict1)
print(id(dict1), id(dict3))
# 运行结果 》》》1588508590368 1588508590944
print(id(dict1['list1']), id(dict3['list1']))
# 运行结果 》》》1588508505736 1588508505672
深拷贝则可以对所有的数据全部进行拷贝,形成一个新的id
注:运用目前的知识对拷贝解释起来比较麻烦,这里博主为大家寻找了一篇关于拷贝运用的博客,感兴趣的朋友可以去了解一下,博客链接
5、课后作业

5.1、第一题
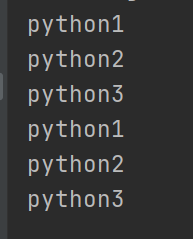
- a = {“name”:“123”,“data”:{“result”:[{“src”:“python1”},{“src”:“python2”},{“src”:“python3”}]}} 找到python1/python2/python3
# 第一种方法
a = {"name":"123",
"data":{"result":[{"src":"python1"},
{"src":"python2"},
{"src":"python3"}]}}
for i in range(3):
print(a["data"]["result"][i]["src"])
# 第二种方法
for i in a["data"]["result"]:
print(i["src"])
-
运行结果如下:
-
知识点运用及编写思路:
本题乍一看感觉a字典好复杂,仔细分析一下a字典就是4层嵌套,字典套字典套列表套字典,只要注意一下那个是key,那个是value就很简单了,写在一行肯难分辨,但是改一下就应该好理解多了:
看明白那个是key,那个是value之后就可以开写了。
首先第一种方法就是用一个最简单的3次循环,然后每次循环都输出一个值,就是直接找到我们需要寻找的3个python
第二种方法是使用了列表的遍历,直接找到result,这个result对应的key值就是一个列表[{'src': 'python1'}, {'src': 'python2'}, {'src': 'python3'}],这时我们的迭代变量 i 就是列表中的3个元素,也就是每次循环都是一个字典,再进行输出之后我们就也可以得到一样的效果。

5.2、第二题
- 有如下值列表[11,22,33,44,55,66,77,88,99,90], 将所有大于66的值保存至字典的第一个key的值中,将小于66值保存至第二个key的值中。
# 第一种方法
a = [11,22,33,44,55,66,77,88,99,90]
b = []
c = []
for i in a:
if i > 66:
b.append(i)
else:
c.append(i)
dic={'key1':b,'key2':c}
print(dic)
# 第二种方法
a = [11,22,33,44,55,66,77,88,99,90]
b = []
a.sort(reverse=False)
for i in range(10):
if a[0]<=66:
b.append(a[0])
a.remove(a[0])
else:
break
dic={'key1':a,'key2':b}
print(dic)
-
运行结果如下:

-
知识点运用及编写思路:
这题我使用了2种方法,也是2种思路。
第一种方法是,用for循环,使用列表a进行遍历,判断列表中所有的数,大于66的就用append方法添加到列表b,反之则添加到列表c。最后都赋值给字典dic,输出就达到了我们想要的效果。
第二种方法与第一种类似,先给列表a排序一下,只要判断小于等于66的数,判断成功就将其用append添加到列表b,再将判断的数从列表中用append删除,失败则直接弹出循环。最后也是赋值,输出,也能达到相同效果。
6、附加(个人练习题——字典)
统计1000个随机数中重复的数字
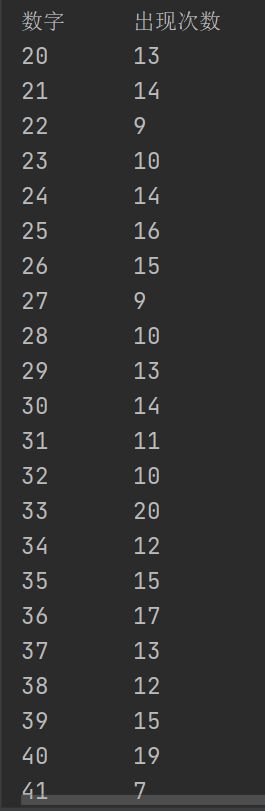
# 统计1000个随机数中重复的数字
# 题目:数字重复统计:
# 1)随机生成1000个整数;
# 2)数字范围[20,100];
# 3)升序输出所有不同的数字及其每个数字重复的次数
import random
a=[] #定义一个空列表
for i in range(1000): #生成1000个随机数放到列表中
a.append(random.randint(20,100)) #随机数范围在20-100之间
#对生成的1000个数进行排序,然后加到字典中
a.sort(reverse=False)
b={} #使用字典的key记录数字,value记录次数
for j in a: #遍历排序好的列表
if j in b:
b[j] +=1 #key存在,则更新value值
else:
b[j]=1 #在空字典b中添加新key—value的键值对
print('数字\t\t出现次数') #使用\t横向制表符
for i in b:
print('%d\t\t%d' %(i,b[i]))
- 运行结果如下:(截取了部分,感兴趣的朋友可以自己尝试一下)

旺仔注:
1、时间不能增添一个人的生命,然而珍惜光阴却可使生命变得更有价值。——卢瑟·伯班克
2、 时间最不偏私,给任何人都是二十四小时,时间也最偏私,给任何人都不是二十四小时。——赫胥黎
3.、复杂的劳动包含着需要耗费或多或少的辛劳、时间和金钱去获得的技巧和知识的运用。——恩格斯

