在上篇《基于Segment Routing技术构建新一代骨干网:智能、可靠、可调度(一)》中提到了UCloud数据中心野蛮式增长给MAN网络和骨干网带来了极大挑战以及UCloud骨干网1.0、2.0的演进路线、SR技术部分原理介绍。本文将重点介绍UCloud如何通过Segment Routing技术改进控制面和转发面,实现智能、可靠、可调度的新一代骨干网。
新一代骨干网架构
设计目标:
- 控制器智能计算路径和头端自动计算路径:控制器实时收集转发设备状态信息,响应转发节点路径计算请求和路径下发。
- 全场景接入,实现灵活组网:支持用户本地专线、互联网线路混合接入方式,实现用户灵活组网。
- 多维度SLA路径规划:满足多业务不同路径转发需求,确保关键业务的优先级和服务质量。
- 降低专线成本,提高整体专线利用率:废除骨干网2.0中的VXLAN技术,缩减包头开销,降低专线成本;通过智能流量调度合理规划专线容量。
- 流量可视化,按需调度:通过telemetry和netflow技术实现骨干网流量可视化,针对部分“热点流量”和“噪声流量”进行按需调度。
整体架构如下:

新一代骨干网主要包括三大组件:智能控制器、骨干边界转发PE、接入侧转发CPE&VPE:
控制器:对全网转发PE、CPE、VPE等设备进行统一的资源管理、信息收集、配置下发,监控告警以及路径计算规划,实现全网资源的统一调度和管理。
骨干网边界:全网PE和RR组成SR-TE骨干网核心层,用于实现多路径转发,流量调度;骨干网边界对外主要接入CPE、M-Core、VPE&VCPE等设备。
接入侧边界:接入侧分为三种设备类型:CPE、M-Core、VPE&VCPE。
CPE:主要用于接入本地专线客户;
M-Core:公有云MAN网络核心,实现各城域网接入骨干网;
VPE:通过Internet或者4G/5G网络接入用户分支机构的VCPE设备,提供用户混合组网能力。
近年来,云数据中心SDN网络设计思路大行其道,其主要思想是转控分离,转控分离好处不用多说,当然也有其弊端;SDN数据中心网络中的控制面故障有太多血的教训,控制面故障带来的转发面影响也是重大的;毕竟转发面才是真正承载客户业务的地方,所以我们在设计新一代骨干网时需要考虑控制器故障时,如何保持转发层面的独立可用性。
接下来将介绍基于SR技术骨干网的控制面和转发面的设计实现原理。
控制面设计
新一代骨干网的控制面主要包括两个方面:
一、智能控制器;
二、 SR-TE骨干网路由设计控制面。
01、智能控制器
控制器的主要架构设计如下:
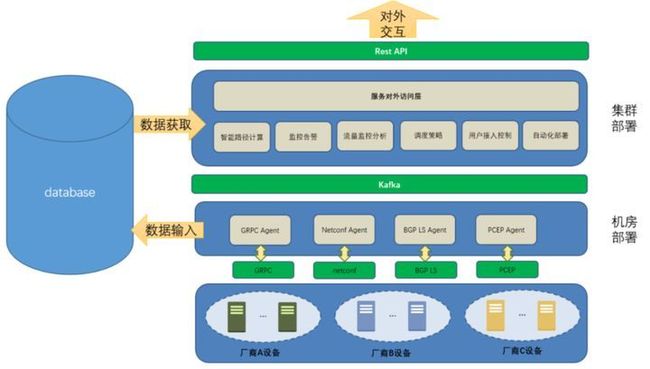
整个控制器的目标为实现一致的配置下发与可扩展的调度策略。基于设备全球部署的特点以及网络并非百分之百稳定的前提,该系统采用了数据层跨地域部署,同时为了兼顾正常情况下控制器的快速响应,控制节点采用了分机房的集群部署方式来保证业务的可靠性与高效的调度能力;上层控制系统通过BGP-LS、Telemetry技术采集转发链路状态信息,收集到数据库,之后对采集到的数据进行分析处理,最后通过netconf和PCEP方式下发配置和智能计算路径。
其中数据采集主要包括:
- 基本的IGP拓扑信息(节点、链路、IGP度量值)
- BGP EPE(Egress peer Engineering)信息
- SR信息(SRGB、Prefix-SID、Adj-SID、Anycast-SID等)
- TE链路属性(TE度量、链路延迟度量、颜色亲和属性等)
- SR Policy信息(头端、端点、颜色、Segment列表、BSID等)
Netconf和PCEP主要用于配置下发和路径计算:
- 头端向控制器请求路径计算;控制器针对收到路径计算请求进行路径计算
- 头端从控制器学到路径,控制器通过PCEP向头端传递路径信息
- 头端向控制器报告其本地的SR Policy
实现能力如下:
- 快速的故障响应:由于内部自定义的算法需求,在线路或者节点出现问题时,需要重新计算整张拓扑,以避开故障链路;
- 快速实现手动故障域隔离:借助架构的优势,实现所有流量在线路级别与节点级别的隔离;
- 快速自定义调优路径:可以根据客户的需求快速将客户流量引导到任意路径上,保证客户各类路径需求;
- 客户流量秒级实时监控:可监控流级别的客户故障,并实现故障情况下的路径保护;
02、SR-TE骨干网控制面
为了实现用户L2和L3接入场景需求,在骨干网规划设计了基于MP-BGP的L3VPN和BGP-EVPN的L2VPN,下面来做一个简单的介绍。
MP-BGP
新一代基于SR技术的骨干网采用了MPLS-VPN的技术特性,大致需要如下组件:
- 首先需要在MPLS VPN Backbone内采用一个IGP(IS-IS)来打通核心骨干网络的内部路由;
- PE上创建VRF实例,与不同的VRF客户对接,VPN实例关联RD及RT值,并且将相应的端口添加到对应的VRF实例;
- PE上基于VRF实例运行PE-CPE&VPE、M-Core间的路由协议,从CPE&VPE、M-Core学习到站点内的VRF路由;
- PE与RR之间,建立MP-IBGP连接,PE将自己从CE处学习到的路由导入到MP-IBGP形成VPNv4的前缀并传递给对端PE,并且也将对端PE发送过来的VPNv4前缀导入到本地相应的VRF实例中;
- 为了让数据能够穿越MPLS VPN Backbone,所有的核心PE激活MPLS及SR功能。
在传统的MPLS-VPN技术的基础上,摒弃LDP,启用SR功能来分配公网标签,内层标签继续由运行MP-BGP协议的PE设备来分配。
BGP-EVPN
在MPLS网络中实现用户L2场景的接入需求,有很多解决方案比如VPLS,但是传统的VPLS还是有很多问题,比如:不提供 All-Active 双归接入,PE流量泛洪可能导致环路风险以及重复数据帧。
为了解决VPLS的问题,我们在新一代骨干网架构中采用了BGP-EVPN协议作为L2网络的控制面;EVPN网络和BGP/MPLS IP VPN的网络结构相似,为了实现各个站点(Site)之间的互通,骨干网上的PE设备建立EVPN实例并接入各个站点的CE设备,同时各个PE之间建立EVPN邻居关系;由于EVPN网络与BGP/MPLS IP VPN网络的不同之处在于各个站点内是二层网络,因此PE从各个CE学习到的是MAC地址而不是路由,PE通过EVPN特有的路由类型将自己从CE学习到MAC地址转发到其它Site。
BGP-EVPN有三个比较重要的概念:
1、EVPN Instance (EVI) :EVPN是一种虚拟私有网络,在一套物理设备上可以有多个同时存在的EVPN实例,每个实例独立存在。每个EVI连接了一组或者多组用户网络,构成一个或者多个跨地域的二层网络。
2、Ethernet Segment(ESI):EVPN技术为PE与某一CE的连接定义唯一的标识ESI(Ethernet Segment Identifier),连接同一CE的多个PE上的ESI值是相同,连接不同CE的ESI值不同。PE之间进行路由传播时,路由中会携带ESI值使PE间可以感知到连接同一CE的其它PE设备。
3、ET(EthernetTag):每个EVI可以构成一个或者多个二层网络。当EVI包含了多个二层网络时,通过Ethernet Tag来区分这些二层网络。如果我们把二层网络看成是广播域的话(Broadcast Domain),那么ET就是用来区分不同广播域的。
为了不同站点之间可以相互学习对方的MAC信息,因此EVPN在BGP协议的基础上定义了一种新的NLRI(Network Layer Reachability Information,网络层可达信息),被称为EVPN NLRI。EVPN NLRI中包含如下几种常用的EVPN路由类型:

相比较VPLS,EVPN的优势如下:
1、集成 L2 和 L3 VPN服务;
2、 类似L3VPN的原理和可扩展性和控制性;
3、支持双归接入,解决容灾和ECMP问题;
4、 可选择 MPLS,VXLAN作为数据平面;
5、对等PE自动发现, 冗余组自动感应。
BGP-LS
BGP-LS用于收集转发设备的链路状态信息以及标签信息,具体规划如下:
1、所有PE和RR建立BGP-LS邻居,PE将各自的链路信息、标签信息以及SR Policy状态传递给RR;
2、RR与控制器建立BGP-LS邻居,将IGP的链路状态信息转换后上报控制器。
转发面设计
01、骨干网核心层
骨干网PE设备之间运行ISIS-L2,并开启SR功能,规划Node-SID、Adj-SID、Anycast-SID;PE基于环回口与RR建立MP-IBGP邻居关系,传递各站点VPNv4路由,实现L3VPN用户业务转发;同时PE采用BGP EVPN作为Overlay路由协议,基于环回口地址建立域内BGP EVPN 邻居关系,采用SR-TE隧道封装用户二层数据,实现L2VPN用户业务通过SR-TE转发。
一般分为SR-BE和SR-TE:
SR-BE由两层标签组成:内层标签为标识用户的VPN标签,外层标签为SR分配的公网标签;
SR-TE由多层标签组成:内层标签为标识用户的VPN标签,外层标签为SR-TE标签,一般由设备头端计算或者通过控制器下发的标签栈;
L2用户通过查找MAC/IP route来实现标签封装,L3用户通过查找VRF中的私网路由来实现标签封装。
02、骨干网边界层
骨干网PE与CPE&VPE以及公有云的M-Core运行EBGP收发用户路由,通过BGP实现数据转发;CPE和VPE与接入用户CE以及VCPE运行EBGP;特别需要注意的是VPE与VCPE是通过Internet建立的BGP,所以需要通过IPsec协议进行数据加密。
介绍完整个骨干网的架构设计后,我们将分别针对骨干网的智能、可靠、可调度三大特性进行剖析。
新一代骨干网三大特性
01、智能
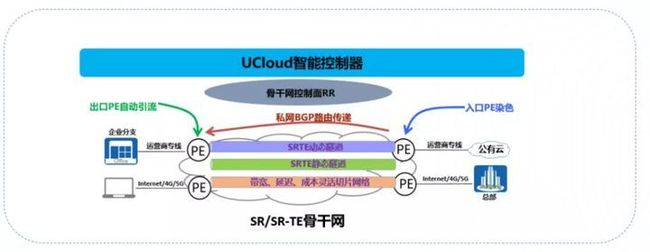
- 控制器统一编排业务场景:
1、分支网络设备自动化部署,实现控制器自动计算路径和流量统一调度以及业务编排;
2、控制器通过BGP-LS等收集网络拓扑、SR-TE信息以及SR Policy信息,并根据业务需求进行路径计算,然后通过BGP-SR-TE/PCEP等协议将SR Policy下发到头端节点。
- 头端自动算路和自动引流:
1、分布式控制面,防止控制器故障带来的整网瘫痪影响,支持头端自动引流,废除复杂的策略引流机制;
2、头端节点利用IGP携带的SR-TE信息和IGP链路状态信息、SR标签信息等组成SR-TE数据库,然后基于CSPF算法按照Cost、带宽、时延、SRLG和不相交路径等约束条件计算满足条件的路径,并安装相应的SR Policy指导数据包转发。
- 基于业务场景对网络灵活切片:
根据业务的SLA要求,可以规划新的网络转发平面,可以将时延敏感型的业务调度到基于延迟切片的网络转发平面。
如下为现网当前规划的两个网络切片转发平面:

- 毫秒级拓扑收敛、链路重算、路径下发:线路故障场景下控制器可以做到毫秒级的拓扑收敛、故障链路重算以及备份路径下发;
- 流级别路径展示:实现基于数据流级别的路径查询和展示。
02、可靠

- 全球核心节点专线组网:节点之间提供运营商级的专线资源,SLA可达99.99%;
- 双PE节点 Anycast-SID保护:地域级的双PE配置Anycast-SID标签,实现路径的ECMP和快速容灾收敛;
- Ti-LFA无环路径保护:100%覆盖故障场景,50ms内完成备份路径切换;
- SR-TE主备路径保护:SR-TE路径中规划主备Segment-List,实现路径转发高可用;
- SR-TE路径快速逃生:SR-TE故障场景下可以一键切换到SR-BE转发路径(IGP最短路径转发);
- Internet级骨干网备份:为了保障新一代骨干网的高可靠性,在每个地域的PE设备旁路上两台公网路由器,规划了一张1:1的Internet骨干网,当某地域专线故障时可以自动切换到Internet线路上;同时使用Flex-Algo技术基于Internet级骨干网规划出一张公网转发平面用于日常管理流量引流。
03、可调度
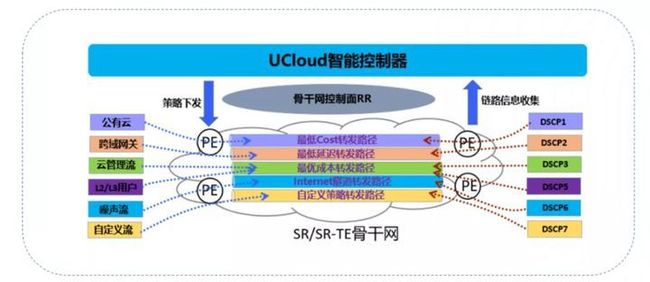
- 根据五元组,识别并定义应用,支持Per-destination、Per-Flow调度;
- 跨域之间根据应用业务分类定义多条不同类型SR-TE隧道;
- 每种类型隧道定义主备路径,支持SR-TE一键逃生;
- 通过灵活算法定义Delay、带宽、TCO(链路成本)、公网隧道等多种网络切片平面;
- 智能控制器支持自动下发、自动计算、自动调整、自动引流和自动调度。
当前根据业务需求规划了如下几种骨干网调度策略:
IGP:最低开销转发,ISIS接口的cost根据点到点之间专线物理距离延迟*100得到;
Delay:最低延迟转发,ISIS接口配置PM功能,动态探测点到点之间实际延迟;
TCO:最优成本转发,控制器根据每条专线的实际成本计算出最优成本路径;
FM:自定义转发,控制器根据业务临时需求下发需求路径;
FBN:公网隧道转发,每个地域之间提供公网VPN线路,提供备份转发路径。
SR Policy中基于Color定义两种引流方式:
1、Per-Destination引流模板:Color在某种程度上将网络和业务进行了解耦,业务方可以通过Color来描述更复杂的业务诉求,SR-TE通过Color进行业务关联。
2、Per-Flow引流模板:通过DSCP标记业务,或者ACL进行流分类映射到Service-Class等级,Service-Class关联Color进行业务引流。
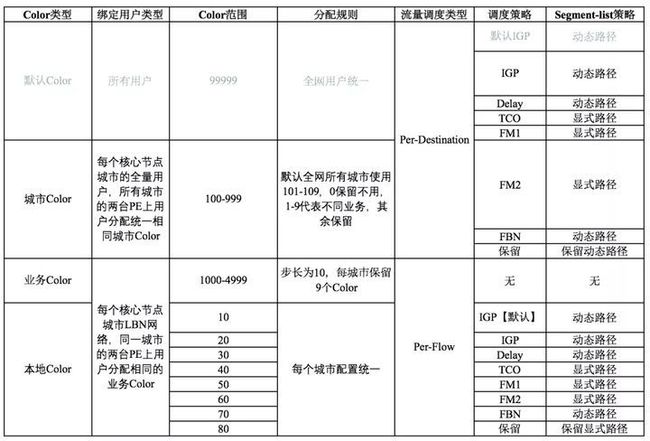
Color资源规划
Color属性在SR-TE中标记路由,用于头端节点进行灵活引流;新一代骨干网络设计的流量调度中定义四种Color类型:
默认Color:每个城市节点的用户路由必须携带的Color值,用于引流默认隧道转发【预埋保留】。
城市Color:每个城市每用户VRF路由必须携带的Color值,用于全局流量调度使用【每个城市默认分配9种相同Color分别关联到不同的业务】。
业务Color:在Per-flow(基于流分类调度)场景中使用,每个城市的MAN网络和用户私网路由标记使用,全局引流作用。
本地Color:在Per-flow(基于流分类调度)场景中结合自用Color使用,映射Service-Class服务等级,关联到业务模板。
Color分配规则
最佳实践方案
下面以流调度为例来介绍UCloud骨干网业务基于SR技术结合的最佳实践方案。
Per-Flow场景下业务模板/Color与Service-Class服务等级关联

1.Per-Flow流量调度规划每个城市分配一个业务Color,MAN网络路由在PE设备上标记各城市业务Color;
2.每个头端节点PE上定义8种调度策略,对应于不同的业务模板,其中2个业务模板保留;业务模板与Color、Service-Class定义标准的映射关系;
3.点到点的城市之间默认支持2条FM自定义策略(自定义隧道策略);
4.IGP、Delay使用动态SR Policy,其它隧道采用静态SR Policy策略;
5.Per-Flow 场景下的endpoint地址支持Anycast-SID,头端的一台PE到末端两台城市的PE只需要定义一条SR Policy即可;
6.以20个核心城市为例,单个城市的PE Per-Flow的SR Policy数量为19*7=133条。
在规划中,UCloud基础网络团队根据公有云业务类型将业务进行分类,分类方法是对具体业务进行DSCP标记;然后数据包到了骨干网PE后再根据DSCP进行灵活引流。
业务模板与Service-Class服务等级映射:
我们将骨干网当作一个整体,这个整体的边界端口使用DSCP和ACL入Service-Class,下面明确定义下何为边界端口。
边界端口:
PE连接CPE&VPE、MAN网络侧的接口
DSCP入队方式:
骨干网边界端口默认信任接入侧用户的DSCP值,根据相应的DSCP入队到Service-Class服务
ACL入队方式:
1.在一些特殊场景下需要针对某些业务通过ACL分类后入队到Service-Class服务【业务本身无法携带DSCP】
2.每种隧道调度策略都可以通过ACL对流进行分类,然后入队到Service-Class
入队和转发流程:
1.在PE上配置流分类,按照业务等级,将不同的DSCP值映射到Service-Class(8种等级)
2.为隧道(Service-Class)配置对应的调度策略
3.业务流在PE设备上会先根据路由迭代看是否选择隧道(SR Policy),然后再去比对流的DSCP值是否和SR Policy中Service-Class映射设置一致,一致流将从对应隧道通过
4.业务流根据Service-Class中的调度策略进行流量转发
分类业务和SR-TE隧道映射关系如下:
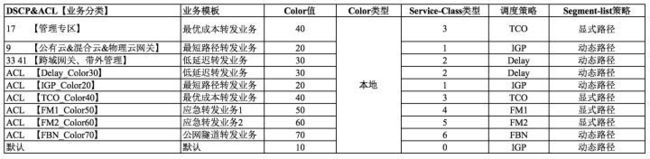
1、默认所有业务按照规划的DSCP和调度策略进行关联;
2、使用ACL实现特殊业务类型进行临时策略调度。
SR-TE流量工程案例
下面介绍一个SR-TE实际调度的案例分享:

- 业务流量背景
业务高峰时段基础网络收到香港-新加坡专线流量突发告警,智能流量分析系统发现突发流量为安全部门在广州与雅加达节点同步数据库。
- 调度前流量模型
正常情况下广州去往雅加达的流量通过IGP最短开销计算出的路径为:广州--->香港--->新加坡--->雅加达,由于香港-新加坡段为出海流量的中转点,所以经常会在高峰期出现链路拥塞情况。
- 传统流量调度方案
1、基于目标地址流量做逐跳PBR,将大流量业务调度到其它空闲链路转发;
2、基于目的地址的流量进行限速,保障链路带宽。
- 传统调度存在问题
1、逐跳配置策略路由,配置复杂,运维难度大;
2、粗暴的限速策略有损内部业务。
- SR-TE流量调度方案
Segment 列表对数据包在网络中的任意转发路径进行编码,可以避开拥塞链路,通过SR流量调度后的路径为:广州--->北京--->法兰克福--->新加坡--->雅加达。
- SR-TE流量调度优势
1、头端/控制器可以定义端到端转发路径,通过标签转发;
2、基于业务流进行灵活流量调度(目的地址+业务等级)。
未来演进
上文用很长的篇幅介绍了UCloud骨干网历史和新一代骨干网架构设计细节,其实当前基于公有云业务调度只能从MAN网络开始,还不支持从DCN内部开始调度;未来UCloud基础网络团队将设计基于Binding SID技术的公有云业务端到端的流量调度工程,大致规划如下:
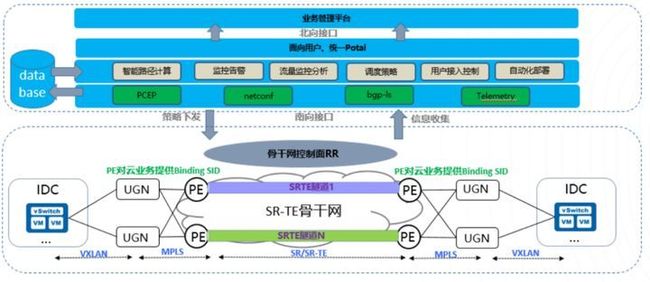
- 骨干网为每个城市的端到端SR-TE隧道分配一个Binding SID,用于数据中心云租户引流;
- 数据中心宿主机通过VXLAN将租户流量送到骨干网UGN(公有云跨域网关);
- UGN解封装VXLAN报文后,封装MPLS标签,内层标签用于区分租户,外层标签用于封装远端城市的Binding SID标签;
- PE设备收到带有目标城市的Binding SID后,自动引流进对应的SR-TE隧道进行转发;
- 对端PE收到报文后解封外层MPLS报文,然后转发给UGN,UGN根据内层标签和VXLAN的VNI的映射关系进行转换,最终通过IP转发至DCN的宿主机上。
总结
UCloud骨干网总体设计目标是智能、可靠、可调度,一方面通过全球专线资源将各Region公有云资源、用户资源打通;另一方面在接入侧支持本地线路+互联网线路接入,构建骨干网混合组网能力,从而形成了一张稳定且高性能的骨干网,为上层公有云业务、用户线下、线上资源开通提供可靠的传输网络,整体上来看骨干网是UCloud公有云网络体系中非常重要的一个组成部分。

UCloud基础网络团队在过去的一年重构新一代骨干网,使其具备了智能、可靠、可调度的能力,从而能够合理的规划专线资源,降低了专线成本,且骨干网整体性能得到极大提升。未来UCloud基础网络团队将会继续紧跟骨干网技术发展潮流,为整个公有云跨域产品提供智能、可靠、可调度的底层网络。
作者:唐玉柱,UCloud 高级网络架构师、UCloud新一代骨干网架构规划项目负责人。拥有丰富的数据中心、骨干网架构设计和运维经验;目前主要负责UCloud全球数据中心、骨干网架构设备选型、架构设计和规划。