PUF模拟及逻辑回归和CMA-ES建模攻击
PUF模拟及机器学习建模攻击
机器学习
1. 什么是机器学习?
机器通过分析大量数据来进行学习。比如说,不需要通过编程来识别猫或人脸,它们可以通过使用图片来进行训练,从而归纳和识别特定的目标。2. 机器学习和人工智能的关系
机器学习是一种重在寻找数据中的模式并使用这些模式来做出预测的研究和算法的门类。机器学习是人工智能领域的一部分,并且和知识发现与数据挖掘有所交集。可参阅《 一文读懂机器学习、数据科学、人工智能、深度学习和统计学之间的区别 》。3. 机器学习的工作方式
①选择数据:将你的数据分成三组:训练数据、验证数据和测试数据②模型数据:使用训练数据来构建使用相关特征的模型
③验证模型:使用你的验证数据接入你的模型
④测试模型:使用你的测试数据检查被验证的模型的表现
⑤使用模型:使用完全训练好的模型在新数据上做预测
⑥调优模型:使用更多数据、不同的特征或调整过的参数来提升算法的性能表现
4. 机器学习所处的位置
①传统编程:软件工程师编写程序来解决问题。首先存在一些数据→为了解决一个问题,软件工程师编写一个流程来告诉机器应该怎样做→计算机遵照这一流程执行,然后得出结果②统计学:分析师比较变量之间的关系
③机器学习:数据科学家使用训练数据集来教计算机应该怎么做,然后系统执行该任务。首先存在大数据→机器会学习使用训练数据集来进行分类,调节特定的算法来实现目标分类→该计算机可学习识别数据中的关系、趋势和模式
④智能应用:智能应用使用人工智能所得到的结果,如图是一个精准农业的应用案例示意,该应用基于无人机所收集到的数据
5. 机器学习的实际应用
机器学习有很多应用场景,这里给出了一些示例,你会怎么使用它?快速三维地图测绘和建模:要建造一架铁路桥, PwC 的数据科学家和领域专家将机器学习应用到了无人机收集到的数据上。这种组合实现了工作成功中的精准监控和快速反馈。
增强分析以降低风险:为了检测内部交易, PwC 将机器学习和其它分析技术结合了起来,从而开发了更为全面的用户概况,并且获得了对复杂可疑行为的更深度了解。
预测表现最佳的目标: PwC 使用机器学习和其它分析方法来评估 Melbourne Cup 赛场上不同赛马的潜力。
机器学习的演化
几十年来,人工智能研究者的各个「部落」一直以来都在彼此争夺主导权,参阅机器之心文章《 华盛顿大学教授 Pedro Domingos:机器学习领域五大流派(附演讲 ppt) 》。现在是这些部落联合起来的时候了吗?他们也可能不得不这样做,因为合作和算法融合是实现真正通用人工智能(AGI)的唯一方式。这里给出了机器学习方法的演化之路以及未来的可能模样。扩展阅读《 深度 | 深度学习与神经网络全局概览:核心技术的发展历程 》。1. 五大流派
①符号主义:使用符号、规则和逻辑来表征知识和进行逻辑推理,最喜欢的算法是:规则和决策树②贝叶斯派:获取发生的可能性来进行概率推理,最喜欢的算法是:朴素贝叶斯或马尔可夫
③联结主义:使用概率矩阵和加权神经元来动态地识别和归纳模式,最喜欢的算法是:神经网络
④进化主义:生成变化,然后为特定目标获取其中最优的,最喜欢的算法是:遗传算法
⑤Analogizer:根据约束条件来优化函数(尽可能走到更高,但同时不要离开道路),最喜欢的算法是:支持向量机
2. 演化的阶段
1980 年代主导流派:符号主义
架构:服务器或大型机
主导理论:知识工程
基本决策逻辑:决策支持系统,实用性有限
1990 年代到 2000 年
主导流派:贝叶斯
架构:小型服务器集群
主导理论:概率论
分类:可扩展的比较或对比,对许多任务都足够好了
2010 年代早期到中期
主导流派:联结主义
架构:大型服务器农场
主导理论:神经科学和概率
识别:更加精准的图像和声音识别、翻译、情绪分析等
3. 这些流派有望合作,并将各自的方法融合到一起
2010 年代末期
主导流派:联结主义 +符号主义
架构:许多云
主导理论:记忆神经网络、大规模集成、基于知识的推理
简单的问答:范围狭窄的、领域特定的知识共享
2020 年代+
主导流派:联结主义 +符号主义+贝叶斯+……
架构:云计算和雾计算
主导理论:感知的时候有网络,推理和工作的时候有规则
简单感知、推理和行动:有限制的自动化或人机交互
2040 年代+
主导流派:算法融合
架构:无处不在的服务器
主导理论:最佳组合的元学习
感知和响应:基于通过多种学习方式获得的知识或经验采取行动或做出回答
机器学习的算法
你应该使用哪种机器学习算法?这在很大程度上依赖于可用数据的性质和数量以及每一个特定用例中你的训练目标。不要使用最复杂的算法,除非其结果值得付出昂贵的开销和资源。这里给出了一些最常见的算法,按使用简单程度排序。更多内容可参阅机器之心的文章《 机器学习算法集锦:从贝叶斯到深度学习及各自优缺点 》和《 经验之谈:如何为你的机器学习问题选择合适的算法? 》1. 决策树(Decision Tree):在进行逐步应答过程中,典型的决策树分析会使用分层变量或决策节点,例如,可将一个给定用户分类成信用可靠或不可靠。
优点:擅长对人、地点、事物的一系列不同特征、品质、特性进行评估
场景举例:基于规则的信用评估、赛马结果预测
扩展阅读:《 教程 | 从头开始:用Python实现决策树算法 》、《 想了解概率图模型?你要先理解图论的基本定义与形式 》
2. 支持向量机(Support Vector Machine):基于超平面(hyperplane),支持向量机可以对数据群进行分类。
优点:支持向量机擅长在变量 X 与其它变量之间进行二元分类操作,无论其关系是否是线性的
场景举例:新闻分类、手写识别。
扩展阅读:《 干货 | 详解支持向量机(附学习资源) 》
3. 回归(Regression):回归可以勾画出因变量与一个或多个因变量之间的状态关系。在这个例子中,将垃圾邮件和非垃圾邮件进行了区分。
优点:回归可用于识别变量之间的连续关系,即便这个关系不是非常明显
场景举例:路面交通流量分析、邮件过滤
4. 朴素贝叶斯分类(Naive Bayes Classification):朴素贝叶斯分类器用于计算可能条件的分支概率。每个独立的特征都是「朴素」或条件独立的,因此它们不会影响别的对象。 例如,在一个装有共 5 个黄色和红色小球的罐子里,连续拿到两个黄色小球的概率是多少?从图中最上方分支可见,前后抓取两个黄色小球的概率为 1/10。朴素贝叶斯分类器可以计算多个特征的联合条件概率。
优点:对于在小数据集上有显著特征的相关对象,朴素贝叶斯方法可对其进行快速分类
场景举例:情感分析、消费者分类
5. 隐马尔可夫模型(Hidden Markov model): 显马尔可夫过程是完全确定性的——一个给定的状态经常会伴随另一个状态。交通信号灯就是一个例子。相反,隐马尔可夫模型通过分析可见数据来计算隐藏状态的发生。随后,借助隐藏状态分析,隐马尔可夫模型可以估计可能的未来观察模式。在本例中,高或低气压的概率(这是隐藏状态)可用于预测晴天、雨天、多云天的概率。
优点:容许数据的变化性,适用于识别( recognition)和预测操作
场景举例:面部表情分析、气象预测
6. 随机森林(Random forest):随机森林算法通过使用多个带有随机选取的数据子集的树(tree)改善了决策树的精确性。本例在基因表达层面上考察了大量与乳腺癌复发相关的基因,并计算出复发风险。
优点:随机森林方法被证明对大规模数据集和存在大量且有时不相关特征的项( item)来说很有用
场景举例:用户流失分析、风险评估
扩展阅读:《 教程 | 从头开始:用 Python 实现随机森林算法 》
7. 循环神经网络(Recurrent neural network):在任意神经网络中,每个神经元都通过 1 个或多个隐藏层来将很多输入转换成单个输出。循环神经网络(RNN)会将值进一步逐层传递,让逐层学习成为可能。换句话说,RNN 存在某种形式的记忆,允许先前的输出去影响后面的输入。
优点:循环神经网络在存在大量有序信息时具有预测能力
场景举例:图像分类与字幕添加、政治情感分析
8. 长短期记忆(Long short-term memory,LSTM)与门控循环单元神经网络(gated recurrent unit nerual network):早期的 RNN 形式是会存在损耗的。尽管这些早期循环神经网络只允许留存少量的早期信息,新近的长短期记忆(LSTM)与门控循环单元(GRU)神经网络都有长期与短期的记忆。换句话说,这些新近的 RNN 拥有更好的控制记忆的能力,允许保留早先的值或是当有必要处理很多系列步骤时重置这些值,这避免了「梯度衰减」或逐层传递的值的最终 degradation。LSTM 与 GRU 网络使得我们可以使用被称为「门(gate)」的记忆模块或结构来控制记忆,这种门可以在合适的时候传递或重置值。
优点:长短期记忆和门控循环单元神经网络具备与其它循环神经网络一样的优点,但因为它们有更好的记忆能力,所以更常被使用
场景举例:自然语言处理、翻译
扩展阅读:《 深度 | LSTM 和递归网络基础教程 》和《 干货 | 图解 LSTM 神经网络架构及其 11 种变体(附论文) 》
9. 卷积神经网络(convolutional neural network):卷积是指来自后续层的权重的融合,可用于标记输出层。
优点:当存在非常大型的数据集、大量特征和复杂的分类任务时,卷积神经网络是非常有用的
场景举例:图像识别、文本转语音、药物发现
扩展阅读:《专栏 | 卷积神经网络简介》、《从入门到精通:卷积神经网络初学者指南》和《解析深度卷积神经网络的 14 种设计模式》
PUF

模拟与机器学习建模攻击过程
1. 在电脑上安装tensorflow,注意需要使用python3.5.x,其余版本的可能会出现问题,详细过程参照
https://blog.csdn.net/lxy_2011/article/details/79181990
2. 对PUF工作过程进行分析,使用python和给出的时间延迟表格,计算出训练集和测试集。
命令: python3 traindataset.py
python3 testdataset.py
3. 使用逻辑回归算法,编程实现,并使用上述过程中生成的训练集对模型进行训练。
命令: python3 logical.py
在这个过程中,直接在训练的同时代入测试集对模型进行测试,测试其准确率。
命令: python3 logical.py
可以看到,这个过程虽然比较缓慢,但是还是成功了的,并且准确率不低。


继续进行建模攻击,这里使用的是CMA- ES模型,在实现过SVM后,才发现这个什么协方差自适应策略的难度比起支持向量机简直就是天和地。查阅了一些资料,发现python是可以使用一个cma包的,只需要在github下载或者直接使用“python -m pip install cma”就可以,参考https://pypi.org/project/cma/
但是,看了半天还是没研究出个所以然,并且发现对于这个问题来说还是有一些问题,于是选择自己根据CMA-ES的算法设计编程出一个模型,于是,历时悠久,想要自己构建一个CMA-ES算法,结果毫无疑问是失败了的...
再回头对cma包进行分析,发现可以结合逻辑回归与cma包里的cma-es策略函数进行建模,这里由于cma包中对于建模变量的局限性,需要对这个策略函数进行修改。
具体修改过程不赘述,在分析策略函数中的算法时,参照下面伪代码进行分析并修改:

结合在改包的过程中遇到的训练时间过长的情况,我将训练集的长度设置为4000组,测试集设置为10000组,改完测试时先假设PUF的位数为8位(此处的python代码也包含了训练集的生成代码,可以通过设置参数限制生成的集合位数)进行测试,输入命令与结果如下,可以看到此处准确率为100%,先不下定论,继续看下面64位的训练:
命令:python3 PUFAttackSimulation.py
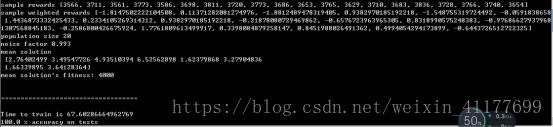
下面将参数设置为64,即实现实验要求的攻击,耗时约两个小时,命令与结果如下图:
命令:python3 PUFAttackSimulation.py
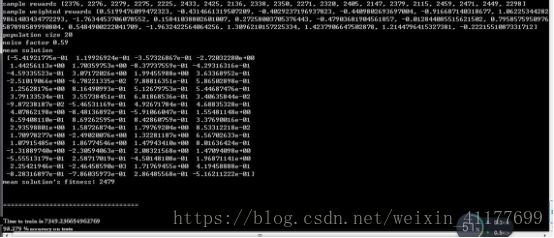
可以看到,攻击基本实现,虽然耗时较长,并且训练集较少,但是准确率达到了98.279%,还是符合题目要求的,这也说明了一个问题,在训练集少的情况下,机器学习建模的准确率相对来说是稍低的,当然这个问题很显而易见,另外一个问题就是,同样的建模策略,对于8位的PUF,准确率竟然会是100%,这也反映了一定的偶然性与算法可能存在的问题,这也说明,PUF的长度,其实是越长越难以被攻击的。
附录:
分两部分——CMA-ES模型代码下载地址 逻辑回归建模
逻辑回归建模相关代码
#logicak.py
from __future__ import print_function, division
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
from sklearn.ensemble import RandomForestRegressor
import sklearn.preprocessing as preprocessing
from numpy import array
from sklearn.model_selection import train_test_split
#tensorflow 实现 Logistic Regression
#读取数据
x_test = pd.read_csv("testdatasetin.csv", header=None) # 测试集特征
x_train = pd.read_csv("traindatasetin.csv", header=None) # 训练集特征
y_train = pd.read_csv("traindatasetout.csv", header=None) # 训练集标签
y_test = pd.read_csv("testdatasetout.csv", header=None) # 测试集标签
y_train = tf.concat([1 - y_train, y_train], 1)
y_test = tf.concat([1 - y_test, y_test], 1)
#参数定义
learning_rate = 0.05 # 学习率
training_epochs = 300 # 训练迭代次数
batch_size = 100 # 分页的每页大小(后面训练采用了批量处理的方法)
display_step = 15 # 何时打印到屏幕的参量
n_samples = x_train.shape[0] # sample_num 训练样本数量
n_features = x_train.shape[1] # feature_num 特征数量 256
n_class = 2
#变量定义
x = tf.placeholder(tf.float32, [None, n_features])
y = tf.placeholder(tf.float32, [None, n_class])
#权重定义
W = tf.Variable(tf.zeros([n_features, n_class]), name="weight")
b = tf.Variable(tf.zeros([n_class]), name="bias")
#y=x*w+b 线性
pred = tf.matmul(x, W) + b
#准确率
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#损失
cost = tf.reduce_sum(
tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
#优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
#初始化
init = tf.global_variables_initializer()
#ax1 = plt.subplot(211)
#ax1.set_ylabel("train_accuracy")
#ax2 = plt.subplot(211, sharex=ax1)
#ax2.set_ylabel("Cost")
#ax2.set_xlabel("Epoch")
#ax3 = plt.subplot(212,sharex=ax1)
#ax3.set_ylabel("test_accuracy")
#plt.setp(ax1.get_xticklabels(), visible=False)
train_accuracy = []
test_accuracy = []
avg_cost = []
#训练
with tf.Session() as sess:
sess.run(init)
for epoch in range(training_epochs):
#avg_cost = 0
total_batch = int(n_samples / batch_size)
for i in range(total_batch):
_, c = sess.run([optimizer, cost],
feed_dict={x: x_train[i * batch_size: (i + 1) * batch_size],
y: y_train[i * batch_size: (i + 1) * batch_size, :].eval()})
train_accuracy.append(accuracy.eval(
{x: x_train, y: y_train.eval()}))
#ax2.plot(epoch+1, avg_cost, 'c.')
test_accuracy.append(accuracy.eval(
{x: x_test, y: y_test.eval()}))
avg_cost.append(c / total_batch)
#plt.plot(epoch + 1, avg_cost, 'co')
if (epoch + 1) % display_step == 0:
print("Epoch:", "%04d" % (epoch + 1), "cost=", c/total_batch)
print("Optimization Finished!")
print("Testing Accuracy:", accuracy.eval(
{x: x_test, y: y_test.eval()}))
plt.suptitle("learning rate=%f training epochs=%i sample_num=%i" % (
learning_rate, training_epochs, n_samples), size=14)
plt.plot(avg_cost)
plt.plot(train_accuracy)
plt.plot(test_accuracy)
plt.legend(['loss', 'train_accuracy', 'test_accuracy'])
plt.ylim(0., 1.5)
#plt.savefig('AC8.png', dpi=300)
plt.xlabel("Epochs")
plt.ylabel("Rate")
plt.show()
#testdataset.py
import tensorflow as tf
import csv
import random
import numpy as np
def shape(M):
return len(M), len(M[0])
out1 = open('testdatasetin.csv', 'w')
out2 = open('testdatasetout.csv', 'w')
csv_writer1 = csv.writer(out1)
csv_writer2 = csv.writer(out2)
csv_file = csv.reader(open('仿真Arbiter_PUF.csv', 'r'))
PUFdelay_np = []
PUFdelay = []
delay1 = 0
delay2 = 0
for i in csv_file:
PUFdelay.append(i)
PUFdelay_np = np.array(PUFdelay, dtype=float)
C_np = [([0] * 64) for i in range(4)]
C_np_csv = []
seed = "01"
counter1 = 0
counter11 = 0
#counter0 = 0
counter = 0
while counter != 1000:
for i in range(64):
binary = random.choice(seed)
if binary == "1":
delaymiddle = delay2
delay2 = delay1
delay1 = delaymiddle
delay1 += float(PUFdelay[1][i])
delay2 += float(PUFdelay[2][i])
C_np[0][i] = 0
C_np[3][i] = 0
counter1 += 1
if counter1 % 2 != 0:
C_np[1][i] = 1
C_np[2][i] = -1
if counter1 % 2 == 0:
C_np[1][i] = -1
C_np[2][i] = 1
if binary == "0":
delay1 += float(PUFdelay[0][i])
delay2 += float(PUFdelay[3][i])
C_np[1][i] = 0
C_np[2][i] = 0
#counter0 += 1
if counter1 % 2 != 0:
C_np[0][i] = -1
C_np[3][i] = 1
if counter1 % 2 == 0:
C_np[0][i] = 1
C_np[3][i] = -1
for i in range(4):
for j in range(64):
C_np_csv.append(C_np[i][j])
csv_writer1.writerow(C_np_csv)
if counter1 % 2 == 0:
if(delay1 > delay2):
csv_writer2.writerow("1")
else:
csv_writer2.writerow("0")
else:
if(delay1 <= delay2):
csv_writer2.writerow("1")
else:
csv_writer2.writerow("0")
counter1 = 0
delay1 = 0
delay2 = 0
C_np_csv = []
counter += 1
#traindataset.py
import tensorflow as tf
import csv
import random
import numpy as np
def shape(M):
return len(M), len(M[0])
out1 = open('traindatasetin.csv','w')
out2 = open('traindatasetout.csv','w')
csv_writer1 = csv.writer(out1)
csv_writer2 = csv.writer(out2)
csv_file = csv.reader(open('仿真Arbiter_PUF.csv','r'))
PUFdelay_np = []
PUFdelay = []
delay1 = 0
delay2 = 0
for i in csv_file:
PUFdelay.append(i)
PUFdelay_np = np.array(PUFdelay, dtype=float)
C_np = [([0] * 64) for i in range(4)]
C_np_csv = []
seed = "01"
counter1 = 0
#counter0 = 0
counter = 0
while counter != 2000:
for i in range(64):
binary = random.choice(seed)
if binary == "1":
delaymiddle = delay2
delay2 = delay1
delay1 = delaymiddle
delay1 += float(PUFdelay[1][i])
delay2 += float(PUFdelay[2][i])
C_np[0][i] = 0
C_np[3][i] = 0
counter1 += 1
if counter1 % 2 != 0:
C_np[1][i] = 1
C_np[2][i] = -1
if counter1 % 2 == 0:
C_np[1][i] = -1
C_np[2][i] = 1
if binary == "0":
delay1 += float(PUFdelay[0][i])
delay2 += float(PUFdelay[3][i])
C_np[1][i] = 0
C_np[2][i] = 0
#counter0 += 1
if counter1 % 2 != 0:
C_np[0][i] = -1
C_np[3][i] = 1
if counter1 % 2 == 0:
C_np[0][i] = 1
C_np[3][i] = -1
for i in range(4):
for j in range(64):
C_np_csv.append(C_np[i][j])
csv_writer1.writerow(C_np_csv)
if counter1 % 2 == 0:
if(delay1 > delay2):
csv_writer2.writerow("1")
else:
csv_writer2.writerow("0")
else:
if(delay1 <= delay2):
csv_writer2.writerow("1")
else:
csv_writer2.writerow("0")
counter1 = 0
delay1 = 0
delay2 = 0
C_np_csv = []
counter += 1
CMA-ES建模相关代码(含PUF模拟)
#PUFAttackSimulation.py
from ArbiterPUF import ArbiterPUF
from ArbiterPUFClone import ArbiterPUFClone, PUFClassifier
from numpy import shape
from CRP import CRP
import json
from pandas import DataFrame
from LogisticRegression import LogisticRegressionModel, LogisticRegressionCostFunction, RPROP
import random
from multiprocessing import Pool
from time import time
from Simplified_Arbiter_PUF import SimplifiedArbiterPUF
from ArbiterPUFFitnessMetric import ArbiterPUFFitnessMetric, XORArbiterPUFFitnessMetric
from CMAEvoultionStrategy import MyCMAEvolutionStrategy
from XORArbiterPUF import XORArbiterPUF
def generate_random_physical_characteristics_for_arbiter_puf(number_of_challenges):
# 4 delays for each stage to represent p, q, r & s delay
return [[random.random() for delay in range(4)] for challenge_stage in range(number_of_challenges)]
def generate_random_puf_challenge(puf_challenge_bit_length):
return [random.choice([-1, 1]) for challenge_bit in range(puf_challenge_bit_length)]
def create_puf_clone_training_set(puf_to_generate_crps_from, training_set_size):
training_set = []
for challenge in range(training_set_size):
random_challenge = generate_random_puf_challenge(puf_to_generate_crps_from.challenge_bits)
training_set.append(CRP(random_challenge, puf_to_generate_crps_from.get_response(random_challenge)))
return training_set
def does_clone_response_match_original(original_response, clone_response):
return original_response == clone_response
def save_training_set_to_json(training_set, output_file):
with open(output_file, 'w') as output_file:
json.dump([training_example.__dict__ for training_example in training_set], output_file, indent=4)
def get_test_results_of_puf_clone_against_original(clone_puf, original_puf, tests, pool):
results = pool.starmap(does_clone_response_match_original,
[(original_puf.get_response(test),
clone_puf.get_response(test)) for test in tests])
return sum(results)
def print_ml_accuracy(number_of_tests, tests_passed):
print((tests_passed / number_of_tests) * 100, '% accuracy on tests')
def generate_arbiter_clone_with_cmaes(bit_length, training_set):
puf_clone = SimplifiedArbiterPUF(get_random_vector(bit_length))
puf_clone.delay_vector = MyCMAEvolutionStrategy(puf_clone.challenge_bits,
ArbiterPUFFitnessMetric(training_set)).train(len(training_set))
return puf_clone
def get_random_vector(length):
return [random.random() for weight in range(length)]
def generate_arbiter_puf(bit_length):
return SimplifiedArbiterPUF(get_random_vector(bit_length))
def generate_xor_arbiter_puf(bit_length, number_of_xors):
return XORArbiterPUF([generate_arbiter_puf(bit_length) for puf in range(number_of_xors + 1)])
def puf_attack_sim():
# Original PUF to be cloned, has a randomly generated vector for input (physical characteristics) and a given challenge bit length (number of stages)
puf_challenge_bit_length = 64
original_puf = generate_arbiter_puf(puf_challenge_bit_length)
# create a training set of CRPs for the clone to train on
training_set_length = 4000
puf_clone_training_set = create_puf_clone_training_set(original_puf, training_set_length)
# save_training_set_to_json(puf_clone_training_set, 'ArbiterPUF_Training_Set.json')
# create clone PUF
start_time = time()
puf_clone = generate_arbiter_clone_with_cmaes(puf_challenge_bit_length, puf_clone_training_set)
training_time = time() - start_time
print("Time to train is", training_time)
# testing the clone to ensure it has the same output as the original puf
number_of_tests = 100000
pool = Pool()
tests_for_puf = pool.map(generate_random_puf_challenge,
[original_puf.challenge_bits for length in range(number_of_tests)])
print_ml_accuracy(number_of_tests,
get_test_results_of_puf_clone_against_original(puf_clone, original_puf, tests_for_puf, pool))
pool.close()
pool.join()
if __name__ == '__main__':
puf_attack_sim()
#XORArbiterPUF.py
from Simplified_Arbiter_PUF import SimplifiedArbiterPUF
from numpy import bitwise_xor
class XORArbiterPUF:
def __init__(self, arbiter_pufs):
assert len(arbiter_pufs) >= 2
self.arbiter_pufs = arbiter_pufs
self.challenge_bits = arbiter_pufs[0].challenge_bits
def get_response(self, challenge_vector):
responses = [arbiter_puf.get_response(challenge_vector) for arbiter_puf in self.arbiter_pufs]
xor_result = responses[0]
for next_puf_response in responses[1:]:
xor_result = bitwise_xor(xor_result, next_puf_response)
return xor_result
#Simplified_Arbiter_PUF.py.
from numpy import sign, dot
import pandas
class SimplifiedArbiterPUF:
def __init__(self, delay_vector):
self.delay_vector = delay_vector
self.challenge_bits = len(
self.delay_vector) # Number of stages that can be configured for a given challenge in the circuit
def get_response(self, challenge_configuration):
# Challenge_configuration refers to the vector representing a binary input of chosen path for the electrical signal
# Return 0 if total delta is >= 0 else return 1
delay_delta = dot(self.delay_vector, challenge_configuration)
return int(sign(delay_delta))
#LogisticRegression.py
from CRP import CRP
from multiprocessing import Pool, Queue, Process
from numpy.ma import dot, sum
from numpy import ndindex, sign, float_power
from math import e, exp
from time import time
class LogisticRegressionModel:
def __init__(self, probability_vector, constant_bias=0):
self.probability_vector = probability_vector
self.constant_bias = constant_bias
def get_output_probability(self, input_vector):
sigmoid = lambda input: 1 / (1 + float_power(e, input))
dot_product_of_input_and_probability = dot(input_vector, self.probability_vector)
probability = sigmoid(dot_product_of_input_and_probability)
return probability
class LogisticRegressionCostFunction:
def __init__(self, logistic_regression_model):
self.logistic_regression_model = logistic_regression_model
def get_sum_of_squared_errors_without_multiprocessing(self, training_examples, weight_index):
return sum([self.get_squared_error(training_example.response,
self.logistic_regression_model.get_output_probability(
training_example.challenge),
training_example.challenge[weight_index])
for training_example in training_examples])
def get_derivative_of_cost_function_without_multiprocessing(self, training_examples, weight_index):
return self.minus_one_over_length_of_training_examples(training_examples) * \
self.get_sum_of_squared_errors_without_multiprocessing(training_examples, weight_index)
def get_squared_error(self, training_response, model_response, input):
return (model_response - training_response) * input
def get_derivative_of_cost_function_with_multiprocessing(self, training_examples, weight_index, pool):
return self.minus_one_over_length_of_training_examples(training_examples) * \
self.get_sum_of_squared_errors_with_multiprocessing(training_examples, weight_index, pool)
def get_sum_of_squared_errors_with_multiprocessing(self, training_examples, weight_index, pool):
sum_of_squared_errors = pool.starmap(self.get_squared_error_multiprocessing,
[(training_example, weight_index)
for training_example in training_examples])
return sum(sum_of_squared_errors)
def get_squared_error_multiprocessing(self, training_example, weight_index):
return (self.logistic_regression_model.get_output_probability(training_example.challenge)
- training_example.response) * training_example.challenge[weight_index]
def minus_one_over_length_of_training_examples(self, training_examples):
return -(1 / len(training_examples))
class RPROP:
def __init__(self, epoch=300, default_step_size=0.1, error_tolerance_threshold=5.0):
self.min_step_size = 1 * exp(-6)
self.max_step_size = 50
self.default_step_size = default_step_size
self.step_size_increase_factor = 1.2
self.step_size_decrease_factor = 0.5
self.epoch = epoch
self.error_tolerance_threshold = error_tolerance_threshold
def train_model_irprop_minus_without_multiprocessing(self, model_to_train, cost_function, network_weights,
training_set):
step_size, weight_gradients_on_previous_iteration, weight_indexes = self.get_initial_variables(network_weights)
for iteration in range(self.epoch):
print("Starting epoch", iteration)
for weight_index in weight_indexes:
gradient_on_current_iteration = \
cost_function.get_derivative_of_cost_function_without_multiprocessing(training_set, weight_index)
gradient_product = self.get_gradient_product(gradient_on_current_iteration,
weight_gradients_on_previous_iteration[weight_index])
step_size[weight_index] = self.get_new_step_size(gradient_product, step_size[weight_index])
gradient_on_current_iteration = self.get_new_gradient_with_gradient_product(
gradient_on_current_iteration,
gradient_product)
network_weights[weight_index] = self.update_weight_with_step_size(network_weights[weight_index],
gradient_on_current_iteration,
step_size[weight_index])
weight_gradients_on_previous_iteration[weight_index] = gradient_on_current_iteration
print(network_weights, "\n")
return network_weights
def get_initial_variables(self, network_weights):
step_size = [self.default_step_size for weight_step_size in range(len(network_weights))]
weight_gradients_on_previous_iteration = [0.0 for value in range(len(network_weights))]
weight_indexes = list(range(len(network_weights)))
return step_size, weight_gradients_on_previous_iteration, weight_indexes
def train_model_irprop_minus_with_multiprocessing(self, model_to_train, cost_function, network_weights,
training_set):
step_size, weight_gradients_on_previous_iteration, weight_indexes = self.get_initial_variables(network_weights)
pool = Pool()
for epoch in range(self.epoch):
print("Starting epoch", epoch)
for weight_index in weight_indexes:
weight_gradient_on_current_iteration = \
cost_function.get_derivative_of_cost_function_with_multiprocessing(training_set, weight_index, pool)
gradient_product = self.get_gradient_product(weight_gradient_on_current_iteration,
weight_gradients_on_previous_iteration[weight_index])
step_size[weight_index] = self.get_new_step_size(gradient_product, step_size[weight_index])
gradient_on_current_iteration = self.get_new_gradient_with_gradient_product(
weight_gradient_on_current_iteration,
gradient_product)
network_weights[weight_index] = self.update_weight_with_step_size(network_weights[weight_index],
gradient_on_current_iteration,
step_size[weight_index])
weight_gradients_on_previous_iteration[weight_index] = gradient_on_current_iteration
print(network_weights, "\n")
pool.close()
pool.join()
return network_weights
def get_new_gradient_with_gradient_product(self, current_weight_gradient, gradient_product):
return 0 if gradient_product < 0 else current_weight_gradient
def get_new_step_size(self, gradient_product, current_step_size):
if gradient_product > 0:
return self.get_increased_step_size(current_step_size)
elif gradient_product < 0:
return self.get_decreased_step_size(current_step_size)
else:
return current_step_size
def get_increased_step_size(self, current_step_size):
return min(current_step_size * self.step_size_increase_factor, self.max_step_size)
def get_decreased_step_size(self, current_step_size):
return max(current_step_size * self.step_size_decrease_factor, self.min_step_size)
def get_gradient_product(self, weight_gradient_on_current_iteration, weight_gradients_on_previous_iteration):
return weight_gradient_on_current_iteration * weight_gradients_on_previous_iteration
def update_weight_with_step_size(self, weight, weight_gradient, update_step_size):
return weight - sign(weight_gradient) * update_step_size
#CRP.py
class CRP:
def __init__(self, challenge, response):
self.challenge = challenge
self.response = response
#CMAEvoultionStrategy.py
from numpy import zeros, std, mean, append
from numpy.random import randn, standard_normal
from numpy.ma import dot
from multiprocessing import Pool
class MyCMAEvolutionStrategy:
def __init__(self, problem_shape, fitness_metric, sample_population_size=20):
self.problem_dimension = problem_shape
self.fitness_metric = fitness_metric
self.sample_population_size = sample_population_size
self.mean_solution = standard_normal(problem_shape) # initial guess
self.mean_solutions_fitness = self.get_mean_solutions_fitness()
self.noise_factor = 1
def train(self, fitness_requirement):
generation_index = 0
print("Original guesses fitness", self.mean_solutions_fitness)
print("\n")
while self.mean_solutions_fitness < fitness_requirement:
print("Generation", generation_index)
self.noise_factor = self.get_noise_factor(fitness_requirement)
noises = self.get_noises()
samples = noises + (self.mean_solution * self.noise_factor)
pool = Pool()
sample_rewards = pool.map(self.get_fitness_of_sample, [sample for sample in samples])
print("sample rewards", sample_rewards)
# rewards_including_means_reward = append(sample_rewards, self.mean_solutions_fitness)
mean_of_rewards = mean(sample_rewards)
standard_deviation_of_rewards = std(sample_rewards)
weighted_rewards = pool.starmap(self.get_weighted_reward,
([(sample_reward, mean_of_rewards, standard_deviation_of_rewards)
for sample_reward in sample_rewards]))
pool.close()
pool.join()
print("sample weighted rewards", weighted_rewards)
self.mean_solution += self.get_direction_to_head_towards(samples, weighted_rewards).transpose()
self.mean_solutions_fitness = self.get_mean_solutions_fitness()
print("population size", self.sample_population_size)
print("noise factor", self.noise_factor)
print("mean solution\n", self.mean_solution)
print("mean solution's fitness: %s" % (str(self.mean_solutions_fitness)))
print('\n\n===================================\n')
generation_index += 1
return self.mean_solution
def train_without_multiprocessing(self, fitness_requirement):
generation_index = 0
print("Original guesses fitness", self.mean_solutions_fitness)
print("\n")
while self.mean_solutions_fitness < fitness_requirement:
print("Generation", generation_index)
self.noise_factor = self.get_noise_factor(fitness_requirement)
noises = self.get_noises()
samples = noises + self.mean_solution
sample_rewards = self.get_fitness_of_samples(samples)
weighted_rewards = self.get_weighted_rewards(sample_rewards)
self.mean_solution += self.get_direction_to_head_towards(samples, weighted_rewards)
self.mean_solutions_fitness = self.get_mean_solutions_fitness()
print("population size", self.sample_population_size)
print("noise factor", self.noise_factor)
print("mean solution", self.mean_solution)
print("mean solution's fitness: %s" % (str(self.mean_solutions_fitness)))
print('\n\n===================================\n')
generation_index += 1
return self.mean_solution
def get_mean_solutions_fitness(self):
return self.fitness_metric.get_fitness(self.mean_solution)
def get_direction_to_head_towards(self, samples, weighted_rewards):
directions = samples - self.mean_solution
directions /= self.noise_factor
direction_to_head = dot(directions.transpose(), weighted_rewards) / self.sample_population_size
return direction_to_head
def get_noise_factor(self, fitness_requirement):
noise_factor = (self.mean_solutions_fitness / fitness_requirement)
return noise_factor
def get_fitness_of_samples(self, samples):
return [self.get_fitness_of_sample(sample) for sample in samples]
def get_fitness_of_sample(self, sample):
return self.fitness_metric.get_fitness(sample)
def get_weighted_rewards(self, samples_rewards):
weighted_rewards = (((samples_rewards - mean(samples_rewards))
/ std(samples_rewards))) # / (self.noise_factor * self.sample_population_size))
return weighted_rewards
def get_weighted_reward(self, sample_reward, mean_sample_reward, standard_deviation_of_rewards):
sample_weighed_reward = ((sample_reward - mean_sample_reward) / (
standard_deviation_of_rewards))
return sample_weighed_reward
def get_noises(self):
random_noises = [(standard_normal(self.problem_dimension) * self.noise_factor)
for sample in range(self.sample_population_size)]
return random_noises
#ArbiterPUFFitnessMetric.py
from numpy import count_nonzero
from Simplified_Arbiter_PUF import SimplifiedArbiterPUF
from XORArbiterPUF import XORArbiterPUF
class XORArbiterPUFFitnessMetric:
def __init__(self, training_set):
self.training_set = training_set
def get_fitness(self, candidate_vectors):
internal_pufs = [SimplifiedArbiterPUF(candidate_vector) for candidate_vector in candidate_vectors]
candidate_puf = XORArbiterPUF(internal_pufs)
hamming_distance = sum([count_nonzero(training_example.response - candidate_puf.get_response(training_example.challenge))
for training_example in self.training_set])
fitness = len(self.training_set) - hamming_distance
return fitness
class ArbiterPUFFitnessMetric:
def __init__(self, training_set):
self.training_set = training_set
def get_fitness(self, candidate_vector):
candidate_puf = SimplifiedArbiterPUF(candidate_vector)
hamming_distance = sum([count_nonzero(training_example.response - candidate_puf.get_response(training_example.challenge))
for training_example in self.training_set])
fitness = len(self.training_set) - hamming_distance
return fitness
#ArbiterPUFClone.py
from LogisticRegression import LogisticRegressionModel, RPROP, LogisticRegressionCostFunction
class ArbiterPUFClone:
def __init__(self, machine_learning_model, puf_classifier):
self.machine_learning_model = machine_learning_model
self.puf_probability_classifier = puf_classifier
def get_response(self, challenge):
probability_of_response_being_one = self.machine_learning_model.get_output_probability(challenge)
return self.puf_probability_classifier.get_classification_from_probability(probability_of_response_being_one)
def prepare_training_set_for_lr_training(self, training_set):
for crp in training_set:
if crp.challenge == -1:
crp.challenge = 0
if crp.response == -1:
crp.response = 0
return training_set
def train_machine_learning_model_without_multiprocessing(self, model_trainer, training_set, cost_function):
training_set = self.prepare_training_set_for_lr_training(training_set)
self.machine_learning_model.probability_vector = \
model_trainer.train_model_irprop_minus_without_multiprocessing(self.machine_learning_model,
cost_function,
self.machine_learning_model.probability_vector,
training_set)
def train_machine_learning_model_with_multiprocessing(self, model_trainer, training_set, cost_function):
training_set = self.prepare_training_set_for_lr_training(training_set)
self.machine_learning_model.probability_vector = \
model_trainer.train_model_irprop_minus_with_multiprocessing(self.machine_learning_model,
cost_function,
self.machine_learning_model.probability_vector,
training_set)
class PUFClassifier:
def __init__(self, decision_boundary=0.5):
self.decision_boundary = decision_boundary
def get_classification_from_probability(self, probability_of_output):
return 1 if probability_of_output >= self.decision_boundary else -1
#ArbiterPUF.py
from numpy.ma import dot
from numpy import sign
class ArbiterPUF:
'''
This model of an Arbiter PUF is based off the Arbiter Model presented in
Extracting Secret Keys from Integrated Circuits by Daihyun Lim
'''
def __init__(self, input_vector):
self.puf_delay_parameters = input_vector # 2D Vector to represent variances in circuit, defined with: p, r, s, q
self.challenge_bits = len(
self.puf_delay_parameters) # Number of stages that can be configured for a given challenge in the circuit
self.delay_vector = self.calculate_delay_vector()
def get_response(self, challenge_configuration):
# Challenge_configuration refers to the vector representing a binary input of chosen path for the electrical signal
# Return 0 if total delta is >= 0 else return 1
return int(sign(self.get_total_delay_vector_from_challenge(challenge_configuration)))
def get_total_delay_vector_from_challenge(self, challenge_configuration):
# Delta between top and bottom can be represented as the dot multiplication of the input vector and challenge configuration
return dot(self.delay_vector, challenge_configuration)
def calculate_delay_vector(self):
delay_vector = [self.get_alpha(0)]
# For all challenge bits except for the first and last bits
for stage_number, stage in enumerate(self.puf_delay_parameters[1: self.challenge_bits - 1]):
delay_vector.append(self.get_alpha(stage_number) + self.get_beta(stage_number - 1))
delay_vector.append(self.get_beta(self.challenge_bits - 1))
return delay_vector
def get_alpha(self, stage_number):
return (self.get_challenge_stage_delay(stage_number, 0) - self.get_challenge_stage_delay(stage_number, 3)
+ self.get_challenge_stage_delay(stage_number, 1) - self.get_challenge_stage_delay(stage_number, 2)) / 2
def get_beta(self, stage_number):
return (self.get_challenge_stage_delay(stage_number, 0) - self.get_challenge_stage_delay(stage_number, 3)
- self.get_challenge_stage_delay(stage_number, 1) + self.get_challenge_stage_delay(stage_number, 2)) / 2
def get_challenge_stage_delay(self, stage_number, delay_type):
return self.puf_delay_parameters[stage_number][delay_type]